6月12日、ルーティングをめぐる会話は「どのフロンティアモデルが最強か?」から「選んだモデルが消えたらどうする?」へ変わった。
Anthropicによると、2026年6月12日午後5時21分(米東部時間)に米政府から指示を受け、外国籍ユーザーによるFable 5およびMythos 5へのアクセス停止を求められたという。実務上の対応は容赦なかった。ほかのAnthropicモデルは提供を続けつつ、両モデルを全顧客向けに無効化したのだ(Anthropic)。同じ投稿でAnthropicは、報告された脱獄手法の根拠を精査した結果、実演された能力はほかの公開モデルからも「広く利用可能」だとし、OpenAIのGPT-5.5を名指ししている(Anthropic)。
これで開発者の問いは、やけに具体的になった。今日あなたのスタックからFable 5が消えたなら、Claude Opus 4.8へルーティングするのか、GPT-5.5へ切り替えるのか、それともプロバイダールーターを組んで、エージェントを単一エンドポイントに賭けるのをやめるのか。
私の答えはこうだ。既存のClaude CodeやAnthropic APIワークフローでは、Opus 4.8をClaudeネイティブなデフォルト代替先にする。ターミナルベンチ系のコーディング根拠やOpenAIエコシステムとの相性を重視するならGPT-5.5を使う。そして、そのワークロードが重要ならルーティングを入れる。単一モデルの停止でエージェントが止まるなら、バグはアーキテクチャにある。
実際にオフラインになったもの
Anthropicは「Claudeが落ちた」と言ったわけではない。Fable 5とMythos 5を全顧客向けに無効化し、「ほかのすべてのAnthropicモデル」は引き続き利用可能だと言った(Anthropic)。この違いは重要だ。
Fable 5は公開版のMythosクラスモデルだった。Mythos 5はより制限された版だ。Opus 4.8は今も稼働しており、Anthropicはこれを「本格的なコーディングとAIエージェント向けに作られたハイブリッド推論モデル」と位置づけ、1Mトークンのコンテキストウィンドウを持つとしている(Anthropic)。
この揉め事は、単なる政策ショーでもない。Anthropicの6月12日の声明によれば、政府側の懸念は、既知の軽微な脆弱性を少数見つけるために使われた限定的な脱獄手法に関するものだった。Anthropicは、ほかの公開モデルでもバイパスなしに同じ種類の問題を見つけられると主張している(Anthropic)。だからここでGPT-5.5が関係してくる。Anthropic自身が、問題視された能力の種類について比較対象として名指ししたからだ。
開発者にとって重要な事実はもっと単純だ。本番エージェントは、なぜアクセスが消えたかなど気にしない。見えているのは、失敗する呼び出し、消えたモデルID、劣化したワークフロー、そして「昨日まで動いていたツールがなぜ使えないのか」と聞いてくるユーザーだけだ。
能力と価格の表
冷静に比べるとこうなる。でっち上げのベンチマーク盛り合わせも、データのふりをした雰囲気論もなし。
| Model | Current role | Input price | Output price | Context | Useful verified capability signals |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Fable 5が使えないときの最有力Anthropic代替先 | $5 / 1M tokens | $25 / 1M tokens | 1M tokens | Anthropicは、本格的なコーディング、エージェント、長時間タスク向けに作られているとしている。Claude API、AWS、Google Cloud、Microsoft Foundryで利用可能(Anthropic) |
| GPT-5.5 | コーディングエージェント向けの強力なOpenAI代替 | $5 / 1M tokens | $30 / 1M tokens | APIでは1M tokens | OpenAIは、SWE-Bench Pro Publicで58.6%、Terminal-Bench 2.0で82.7%、CyberGymで81.8%、Graphwalks BFS 1M F1で45.4%と報告している(OpenAI) |
| Claude Fable 5 | Claudeの最上位ルートとして望ましいが、現在Anthropic経由では利用不可 | $10 / 1M tokens list | $50 / 1M tokens list | 1M tokens | 6月12日の指示後、Anthropicにより全顧客向けに無効化(Anthropic) |
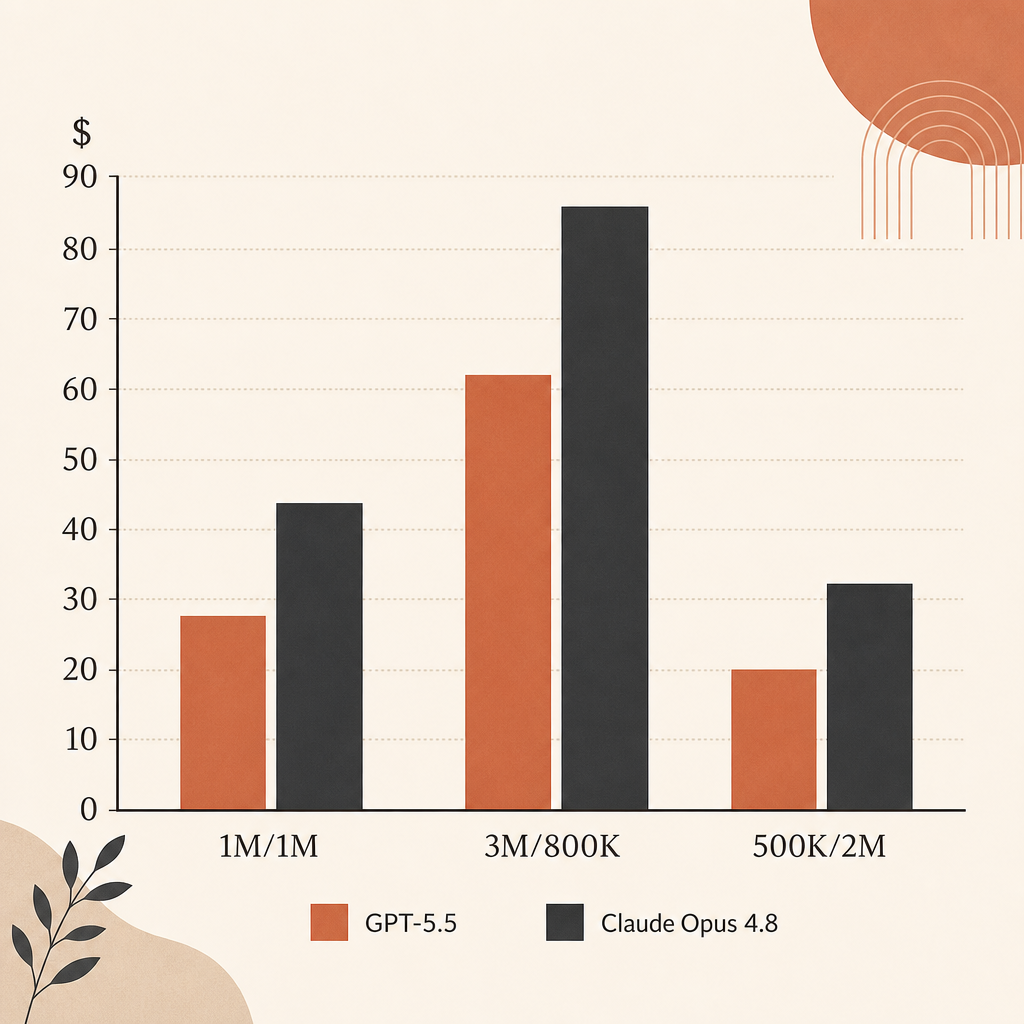
生の表示価格だけを見ると、出力が重いエージェント実行ではOpus 4.8のほうがGPT-5.5より安い。入力はどちらも$5/M。出力はOpus 4.8が$25/M、GPT-5.5が$30/Mだ。
現実的なエージェント料金の例をいくつか挙げる。
| Workload | Opus 4.8 | GPT-5.5 | Difference |
|---|---|---|---|
| 1M input, 1M output | $30 | $35 | GPT-5.5は16.7%高い |
| 3M input, 800K output | $35 | $39 | GPT-5.5は11.4%高い |
| 500K input, 2M output | $52.50 | $62.50 | GPT-5.5は19.0%高い |
だからといってOpusが常に勝つわけではない。一発で終えるモデルは、ループし、リトライし、リポジトリに触る前に5ページ分の計画を書く安価なモデルより、結果的に安くなることがある。Simon WillisonのFable 5デバッグ投稿をめぐるHNスレッドは、まさにこの分裂で埋まっている。「容赦なくプロアクティブ」な振る舞いを絶賛する開発者もいれば、無駄、トークン消費、小さな修正には過剰な自律機構だと見る開発者もいた(Hacker News)。
コミュニティの議論が正しく捉えていること
開発者の議論として最もまともなのは、「Claudeが良い」対「OpenAIが良い」ではない。制御の話だ。
Simon Willisonの6月11日の記事は、その最も分かりやすい記録だ。彼はClaude Fable 5に、スクロールバーのバグについてのスクリーンショットと一行のプロンプトを与えた。モデルはローカル再現ページを作り、本物のブラウザを開き、Quartz経由でmacOSのウィンドウIDを使い、スクリーンショットを撮り、JavaScriptを注入し、小さなCORSサーバーを走らせ、shadow DOMを測定し、ガードレールに当たったところでOpusへ引き継いだ(Simon Willison)。彼のコストトラッカーによれば、そのセッションは正規料金なら約$12.11だった。
その投稿下のHNスレッドが有用なのは、偽の合意を拒んでいるからだ。一方の陣営は、これこそエージェント型コーディングのあるべき姿だと言う。ツールを使い、現実に照らして検証し、成果物を出す。もう一方は、CSSスクロールバーを直すのにドルとシェルアクセスを燃やすのは抽象化として間違っている、と言う。特にエージェントが厳密なサンドボックス外で動くならなおさらだ(Hacker News)。
Redditはもう少し雑然としているが、運用上の痛みはよく表れている。r/ClaudeCodeでは、開発者たちがすでにFableっぽい挙動をOpus 4.8用の指示ファイルへ抽出しようとしており、Fable5.mdプロンプト、--append-system-prompt-file案、「Opusをもっとプロアクティブにする」レシピを共有している(Reddit)。r/cybersecurityやr/LocalLLaMAでは、議論はプラットフォームリスクへ移る。フロンティア級のホスト型モデルが一晩で引き剥がされるなら、真剣なチームはローカルモデル、マルチプロバイダールーティング、あるいは下位のホスト型フォールバックへもっと寄せるべきなのか、という話だ(Reddit, Reddit)。
多くのスレッドで欠けている実務的な答えはこれだ。プロバイダーリスクを「プロンプト」で乗り切ろうとするな。プロンプトでOpusをFableに近づけることはできる。だが、利用できないモデルを利用可能にはできない。
Claudeの継続性が欲しいならOpus 4.8を使う
システムがすでにClaudeのツール利用スタイル、長文コンテキストの挙動、Claude Code、Anthropic Messages APIのセマンティクス、あるいはプロンプトキャッシュに依存しているなら、Claude Opus 4.8を選ぶ。
Opus 4.8は最も混乱の少ない代替先だ。Anthropic自身のOpusページによると、このモデルはclaude-opus-4-8として利用でき、料金は入力$5/M、出力$25/Mからで、プロンプトキャッシュでは最大90%の節約、バッチ処理では50%の節約に対応している(Anthropic)。Claudeのメッセージ形式、システムプロンプト、ツール呼び出し、CLAUDE.md慣習を前提に作っているなら、Claudeファミリー内に留まるほうが移行リスクは低い。
向いている用途は次のとおり。
- 多数のファイルと規約をモデルに保持させる必要がある大規模コードベースレビュー。
- Claudeの慎重な計画と自己チェックが効くエージェント型ワークフロー。
- すでにClaude Codeを使っており、摩擦の少ないFable 5代替先が欲しいチーム。
- GPT-5.5の$30/M出力価格が効いてくる出力重めのジョブ。
- プロンプトキャッシュを活用できるワークフロー。
弱点はベンチマークの明瞭さだ。OpenAIのGPT-5.5ページは、テキストで読めるベンチマーク数値を多く提示している。AnthropicのOpus 4.8ページは、位置づけ、価格、コンテキスト、パートナーコメント、画像ベースのベンチマーク欄を示しているが、ページ本文内で監査しやすい数値比較は少ない。調達プロセスで名前付きベンチマークスコアの表が必要なら、GPT-5.5のほうが説明しやすい。
それでも問いが「Fableが消えた今、自分のClaudeエージェントは何を呼ぶべきか?」なら、まずOpus 4.8から始めればいい。
根拠とOpenAI適合を求めるならGPT-5.5を使う
公開ベンチマーク数値のある強力なコーディングモデル、OpenAI API互換性、あるいはCodex統合が欲しいなら、GPT-5.5を選ぶ。
OpenAIによれば、GPT-5.5のAPI開発者向け価格は入力$5/M、出力$30/Mで、1Mトークンのコンテキストウィンドウを持つ(OpenAI)。公開されているコーディングとツール利用の数値は強い。Terminal-Bench 2.0で82.7%、SWE-Bench Pro Publicで58.6%、MCP Atlasで75.3%、CyberGymで81.8%だ(OpenAI)。OpenAIはまた、GPT-5.5のサイバーおよびバイオ/化学能力をPreparedness Framework上でHighに分類しつつ、サイバーセキュリティ能力はCriticalレベルには達していないとしている(OpenAI)。
向いている用途は次のとおり。
- Terminal-Bench風の性能が自分のワークロードに対応する、ターミナル中心のコーディングタスク。
- Claudeの計画のクロスチェック。特にセキュリティ上重要な変更や移行が重い変更。
- すでにOpenAI ResponsesまたはChat Completionsに標準化しているチーム。
- GPT-5.5をレビュー担当、批評担当、二段階目の検証役として使うエージェントルーター。
- Claudeワークフローの継続性より、公開された数値評価が重要なケース。
弱点は、出力が重い実行でのコストだ。GPT-5.5が劇的に高いわけではないが、エージェントのループは出力を生む。あなたのエージェントが長い計画、長いdiff、長いテストログ、長い事後分析を書くなら、その$5/Mの出力差は見えてくる。
より良いアーキテクチャ:祈るな、ルーティングしろ
私が実際に出荷する選択ガイドはこうだ。
- ClaudeネイティブなコーディングエージェントではOpus 4.8をデフォルトにする。
- 独立レビュー、ターミナル重めのタスク、OpenAIネイティブなスタックではGPT-5.5へルーティングする。
- Fable 5ルートは用意しておく。ただし本番をそれに依存させない。
- 予算上限、サンドボックス、タスク別モデルポリシーを追加する。
- モデル、プロバイダー、トークン構成、フォールバック理由、最終的な人間の承認をログに残す。
プロバイダールーターは凝ったものでなくていい。まずはポリシーファイルから始める。
routes:
default_coding: claude-opus-4-8
critical_review: gpt-5.5
long_context_refactor: claude-opus-4-8
security_review: gpt-5.5
limits:
max_usd_per_task: 8
require_approval_over_usd: 3そしてモデル呼び出しの前にそれを強制する。狙いは完璧な自動ルーティングを追いかけることではない。ビジネス継続性を単一のモデルIDにハードコードしないことだ。
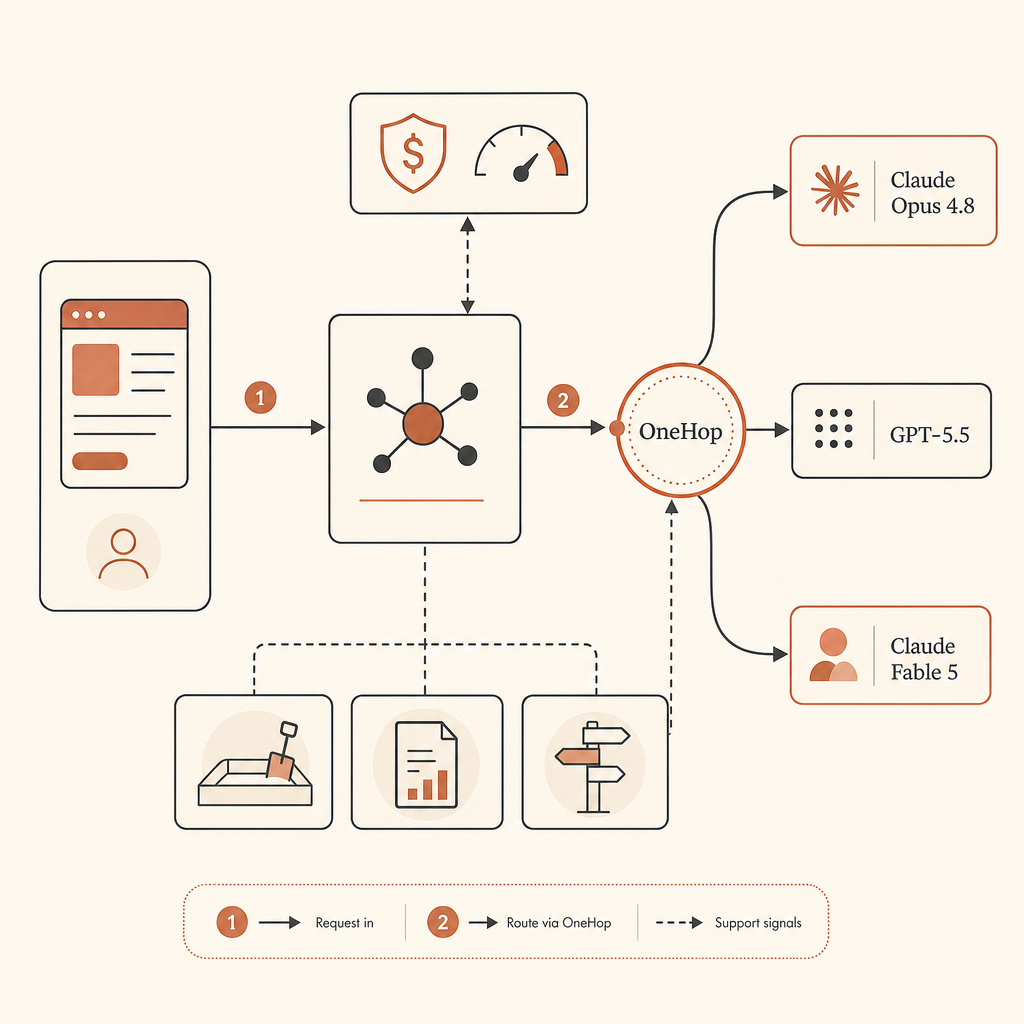
アクセス可能なときにそれでもFable 5を使いたいなら、ルーティングテーブルに入れておく最も摩擦の少ない経路はOneHopだ。OneHopはClaude Fable 5をanthropic/claude-fable-5として掲載し、公式の表示価格である入力$10/M、出力$50/Mを示しつつ、割引価格と、新規アカウント向けのカード不要$10無料クレジットをうたっている(OneHop)。自然なパターンは、アプリ側のプロバイダー抽象を安定させ、base URLを差し替えることだ。
OpenAI互換クライアントならこうなる。
from openai import OpenAI
client = OpenAI(
base_url="https://api.onehop.ai/v1",
api_key="ONEHOP_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-fable-5",
messages=[
{"role": "user", "content": "Review this migration plan for hidden failure modes."}
],
)
print(response.choices[0].message.content)Fableルートを明示的に使いたい場合は、Claude Fable 5 on OneHopを使えばいい。ゼロからプロバイダールーティングを試すなら、$10無料で始める。
最後の推奨は、意図的につまらないものにしている。Fable 5が使えないなら、Opus 4.8とGPT-5.5のどちらがより良い性格かを一週間議論するな。ClaudeのフォールバックスロットにはOpus 4.8を入れる。レビュー担当とOpenAIネイティブなスロットにはGPT-5.5を入れる。Fable 5は、利用可能なときにOneHop経由でルーティングできる選択肢として残す。そして自分たちのタスクで測る。成功率、人間の修正量、実時間、トークンコスト、ロールバック回数。
それが大人のやり方だ。モデルファン同士の議論は楽しい。本番エージェントに必要なのは、出口戦略である。

