6월 12일 이후 라우팅 논의는 “어느 frontier model이 최고인가?”에서 “내가 고른 모델이 사라지면 어떻게 되는가?”로 바뀌었다.
Anthropic은 2026년 6월 12일 오후 5시 21분(ET), 외국 국적자의 Fable 5 및 Mythos 5 접근을 중단하라는 미국 정부 지시를 받았다고 밝혔다. 현실적인 대응은 단호했다. 다른 Anthropic 모델은 계속 제공하되, 두 모델은 모든 고객에게 비활성화한다는 것이었다 (Anthropic). 같은 글에서 Anthropic은 문제가 됐다는 jailbreak 근거를 검토했으며, 시연된 능력은 다른 공개 모델에서도 “widely available”하다고 밝혔다. OpenAI의 GPT-5.5를 명시적으로 언급하면서 말이다 (Anthropic).
그래서 개발자의 질문은 유난히 구체적이 됐다. 오늘 당신의 stack에서 Fable 5가 빠졌다면, Claude Opus 4.8로 route할 것인가, GPT-5.5로 갈아탈 것인가, 아니면 provider router를 만들고 agent를 단일 endpoint에 걸어두는 일을 그만둘 것인가?
내 답은 이렇다. 기존 Claude Code와 Anthropic API workflow에는 Opus 4.8을 기본 Claude-native fallback으로 쓰고, terminal-bench류 코딩 근거나 OpenAI ecosystem 적합성이 더 필요할 때는 GPT-5.5를 쓰고, workload가 중요하다면 routing을 추가하라. 단일 모델 장애가 agent를 멈출 수 있다면, 버그는 아키텍처에 있다.
실제로 오프라인이 된 것
Anthropic은 “Claude가 down됐다”고 말하지 않았다. Fable 5와 Mythos 5가 모든 고객에게 비활성화됐고, “all other Anthropic models”는 계속 제공된다고 말했다 (Anthropic). 이 차이는 중요하다.
Fable 5는 공개 Mythos-class 모델이었다. Mythos 5는 더 제한적인 버전이었다. Opus 4.8은 여전히 live 상태이며, Anthropic은 이를 1M-token context window를 갖춘 “serious coding and AI agents”용 hybrid reasoning model로 포지셔닝한다 (Anthropic).
이 논쟁은 단순한 정책 쇼도 아니다. Anthropic의 6월 12일 성명에 따르면, 정부 우려는 이미 알려진 소수의 경미한 취약점을 찾는 데 쓰인 좁은 jailbreak와 관련돼 있었다. Anthropic은 다른 공개 모델도 bypass 없이 같은 종류의 문제를 발견할 수 있다고 주장한다 (Anthropic). 그래서 여기서 GPT-5.5가 중요해진다. Anthropic이 논쟁이 된 capability class에서 비교 가능한 모델로 직접 이름을 댔기 때문이다.
개발자에게 핵심 사실은 더 단순하다. production agent는 접근이 왜 사라졌는지 신경 쓰지 않는다. agent가 보는 건 실패한 call, 사라진 model ID, 망가진 workflow, 그리고 어제 되던 도구가 왜 오늘 안 되냐고 묻는 사용자뿐이다.
Capability와 가격표
차분하게 비교하면 이렇다. 지어낸 benchmark 수프도 없고, data인 척하는 vibes도 없다.
| Model | 현재 역할 | Input price | Output price | Context | 검증된 유용한 capability signal |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Fable 5를 쓸 수 없을 때 최선의 Anthropic fallback | $5 / 1M tokens | $25 / 1M tokens | 1M tokens | Anthropic은 serious coding, agents, long-running tasks용으로 built됐다고 말한다; Claude API, AWS, Google Cloud, Microsoft Foundry에서 사용 가능 (Anthropic) |
| GPT-5.5 | coding agents를 위한 강력한 OpenAI 대안 | $5 / 1M tokens | $30 / 1M tokens | API에서 1M tokens | OpenAI는 SWE-Bench Pro Public 58.6%, Terminal-Bench 2.0 82.7%, CyberGym 81.8%, Graphwalks BFS 1M F1 45.4%를 보고했다 (OpenAI) |
| Claude Fable 5 | 선호되는 최상위 Claude 경로, 현재 Anthropic을 통해서는 사용 불가 | $10 / 1M tokens list | $50 / 1M tokens list | 1M tokens | 6월 12일 지시 이후 Anthropic이 모든 고객에게 비활성화 (Anthropic) |
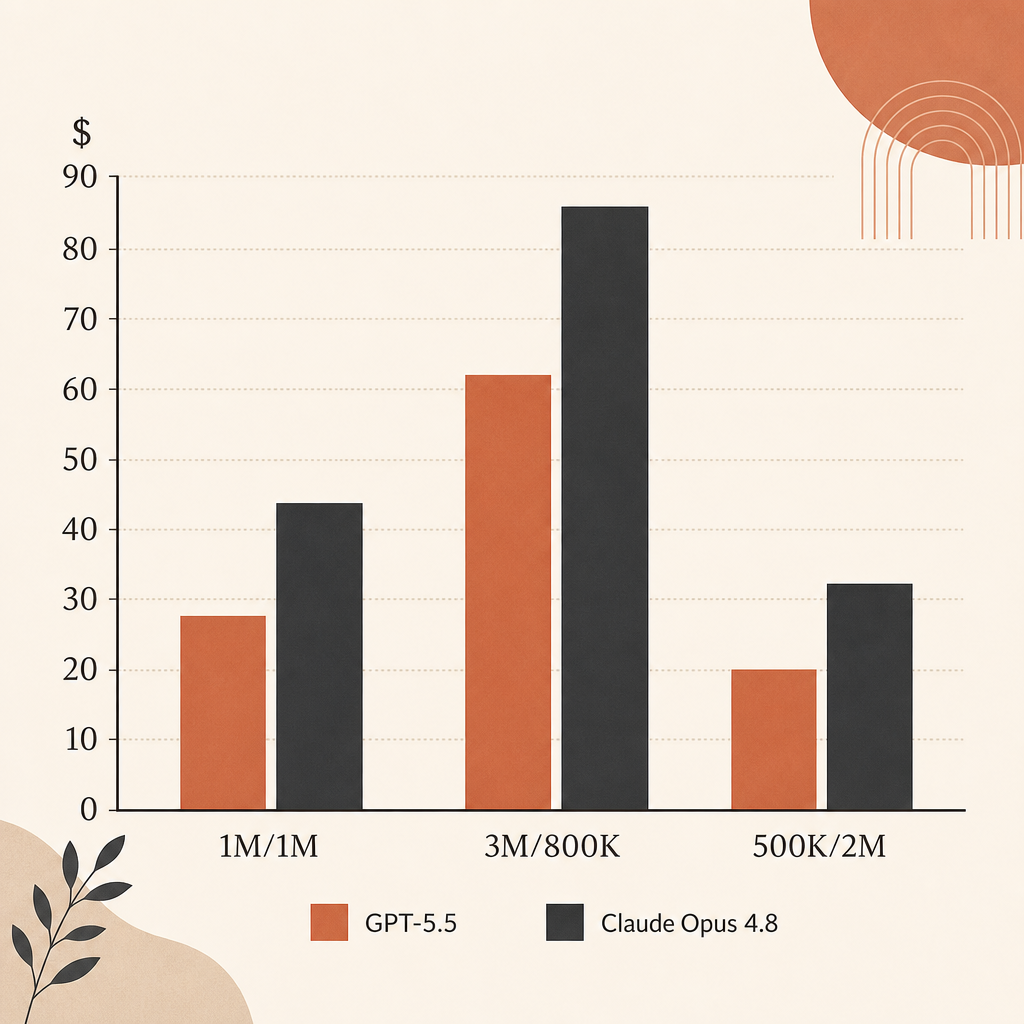
순수 list price만 보면, output-heavy agent run에서는 Opus 4.8이 GPT-5.5보다 싸다. Input은 $5/M로 같다. Output은 Opus 4.8이 $25/M, GPT-5.5가 $30/M이다.
현실적인 agent bill 몇 가지를 보면:
| Workload | Opus 4.8 | GPT-5.5 | Difference |
|---|---|---|---|
| 1M input, 1M output | $30 | $35 | GPT-5.5가 16.7% 더 비쌈 |
| 3M input, 800K output | $35 | $39 | GPT-5.5가 11.4% 더 비쌈 |
| 500K input, 2M output | $52.50 | $62.50 | GPT-5.5가 19.0% 더 비쌈 |
그렇다고 Opus가 항상 이긴다는 뜻은 아니다. 한 번에 끝내는 모델은, 더 싸지만 loop를 돌고 retry하고 repo를 만지기 전에 다섯 페이지짜리 계획을 쓰는 모델보다 오히려 저렴할 수 있다. Simon Willison의 Fable 5 debugging post를 둘러싼 HN thread는 바로 이 갈림길로 가득하다. 어떤 개발자들은 “relentlessly proactive”한 행동을 좋아했고, 다른 이들은 낭비, token burn, 작은 fix에 비해 과한 autonomous machinery라고 봤다 (Hacker News).
Community 논쟁이 맞히고 있는 것
가장 좋은 개발자 논의는 “Claude 좋다” 대 “OpenAI 좋다”가 아니다. control에 관한 이야기다.
Simon Willison의 6월 11일 글이 가장 선명한 사례다. 그는 Claude Fable 5에 scrollbar bug에 관한 screenshot과 한 줄짜리 prompt를 줬다. 모델은 local repro page를 만들고, 실제 browser를 열고, Quartz를 통해 macOS window ID를 사용하고, screenshot을 캡처하고, JavaScript를 주입하고, 작은 CORS server를 돌리고, shadow DOM을 측정한 뒤, guardrail에 걸리자 Opus로 handoff했다 (Simon Willison). 그의 cost tracker는 이 session이 정가 기준 약 $12.11 들었을 것으로 추산했다.
그 글 아래 HN thread가 유용한 이유는 가짜 합의를 거부하기 때문이다. 한쪽은 이것이 agentic coding이 마땅히 가야 할 방향이라고 말한다. tool을 쓰고, 현실에 대고 검증하고, artifact를 만들어내는 것. 다른 한쪽은 CSS scrollbar 하나를 고치려고 dollar와 shell access를 태우는 건 잘못된 abstraction이라고 말한다. 특히 agent가 빡빡한 sandbox 밖에서 움직일 때는 더 그렇다 (Hacker News).
Reddit은 덜 정돈돼 있지만, 운영상의 고통은 잘 잡아낸다. r/ClaudeCode에서는 개발자들이 이미 Fable-like behavior를 Opus 4.8용 instruction file로 distill하려고 시도하고 있다. Fable5.md prompt, --append-system-prompt-file 아이디어, “Opus를 더 proactive하게 만들기” 레시피를 공유하면서 말이다 (Reddit). r/cybersecurity와 r/LocalLLaMA에서는 논의가 platform risk로 옮겨간다. frontier hosted model이 하룻밤 사이에 내려갈 수 있다면, serious team은 local model, multi-provider routing, 또는 lower-tier hosted fallback에 더 의존해야 하는가 (Reddit, Reddit).
많은 thread에서 빠진 실용적인 답은 이것이다. provider risk를 prompt로 해결하려 들지 말라. prompt는 Opus가 Fable처럼 행동하게 만들 수 있다. 하지만 사용할 수 없는 모델을 사용할 수 있게 만들지는 못한다.
Claude Continuity가 필요하면 Opus 4.8을 써라
당신의 system이 이미 Claude의 tool-use style, long-context behavior, Claude Code, Anthropic Messages API semantics, 또는 prompt caching에 의존한다면 Claude Opus 4.8을 고르면 된다.
Opus 4.8은 가장 덜 disruptive한 fallback이다. Anthropic의 Opus page에 따르면 이 모델은 claude-opus-4-8로 제공되고, $5/M input 및 $25/M output부터 시작하며, prompt caching으로 최대 90% 절감, batch processing으로 50% 절감을 지원한다 (Anthropic). Claude의 message format, system prompt, tool call, 또는 CLAUDE.md convention을 중심으로 만들었다면 Claude family 안에 머무는 편이 migration risk를 줄인다.
다음에 써라:
- 모델이 많은 file과 convention을 잡고 있어야 하는 대규모 codebase review.
- Claude의 신중한 planning과 self-checking에서 이득을 보는 agentic workflow.
- 이미 Claude Code를 쓰고 있으며 friction 낮은 Fable 5 fallback을 원하는 team.
- GPT-5.5의 $30/M output price가 신경 쓰이기 시작하는 output-heavy job.
- prompt caching을 활용할 수 있는 workflow.
약점은 benchmark clarity다. OpenAI의 GPT-5.5 page는 text로 읽을 수 있는 benchmark number를 많이 제공한다. Anthropic의 Opus 4.8 page는 positioning, pricing, context, partner quote, image-based benchmark section은 제공하지만, page text에서 쉽게 audit할 수 있는 numeric comparison은 더 적다. procurement process가 named benchmark score 표를 요구한다면 GPT-5.5가 방어하기 더 쉽다.
그래도 질문이 “Fable이 사라졌는데 내 Claude agent가 이제 무엇을 call해야 하는가?”라면, Opus 4.8에서 시작하라.
Evidence와 OpenAI Fit이 필요하면 GPT-5.5를 써라
공개 benchmark number, OpenAI API compatibility, 또는 Codex integration이 있는 강력한 coding model을 원한다면 GPT-5.5를 고르면 된다.
OpenAI는 GPT-5.5가 API developer에게 $5/M input, $30/M output 가격이며, 1M-token context window를 제공한다고 말한다 (OpenAI). 공개된 coding 및 tool number는 강하다. Terminal-Bench 2.0 82.7%, SWE-Bench Pro Public 58.6%, MCP Atlas 75.3%, CyberGym 81.8%다 (OpenAI). OpenAI는 또한 GPT-5.5의 cyber 및 bio/chemical capability를 Preparedness Framework상 High로 분류하면서도, Critical cybersecurity capability level에는 도달하지 않았다고 밝혔다 (OpenAI).
다음에 써라:
- Terminal-Bench 스타일 성능이 workload와 맞닿아 있는 terminal-heavy coding task.
- Claude plan의 cross-check, 특히 security-sensitive 또는 migration-heavy change.
- 이미 OpenAI Responses나 Chat Completions로 표준화한 team.
- GPT-5.5가 reviewer, critic, second-pass verifier 역할을 하는 agent router.
- Claude workflow continuity보다 공개 numeric eval이 더 중요한 경우.
단점은 output-heavy run에서의 비용이다. GPT-5.5가 극적으로 비싼 건 아니다. 하지만 agent loop는 output을 만든다. agent가 긴 plan, 긴 diff, 긴 test log, 긴 postmortem을 쓴다면 $5/M output 차이는 눈에 띈다.
더 나은 아키텍처: 기도하지 말고 Route하라
내가 실제로 ship할 selection guide는 이렇다:
- Claude-native coding agent는 Opus 4.8을 default로 둔다.
- independent review, terminal-heavy task, OpenAI-native stack은 GPT-5.5로 route한다.
- Fable 5 경로는 준비해두되, production을 거기에 묶지 않는다.
- budget cap, sandboxing, per-task model policy를 추가한다.
- model, provider, token mix, fallback reason, final human approval을 log한다.
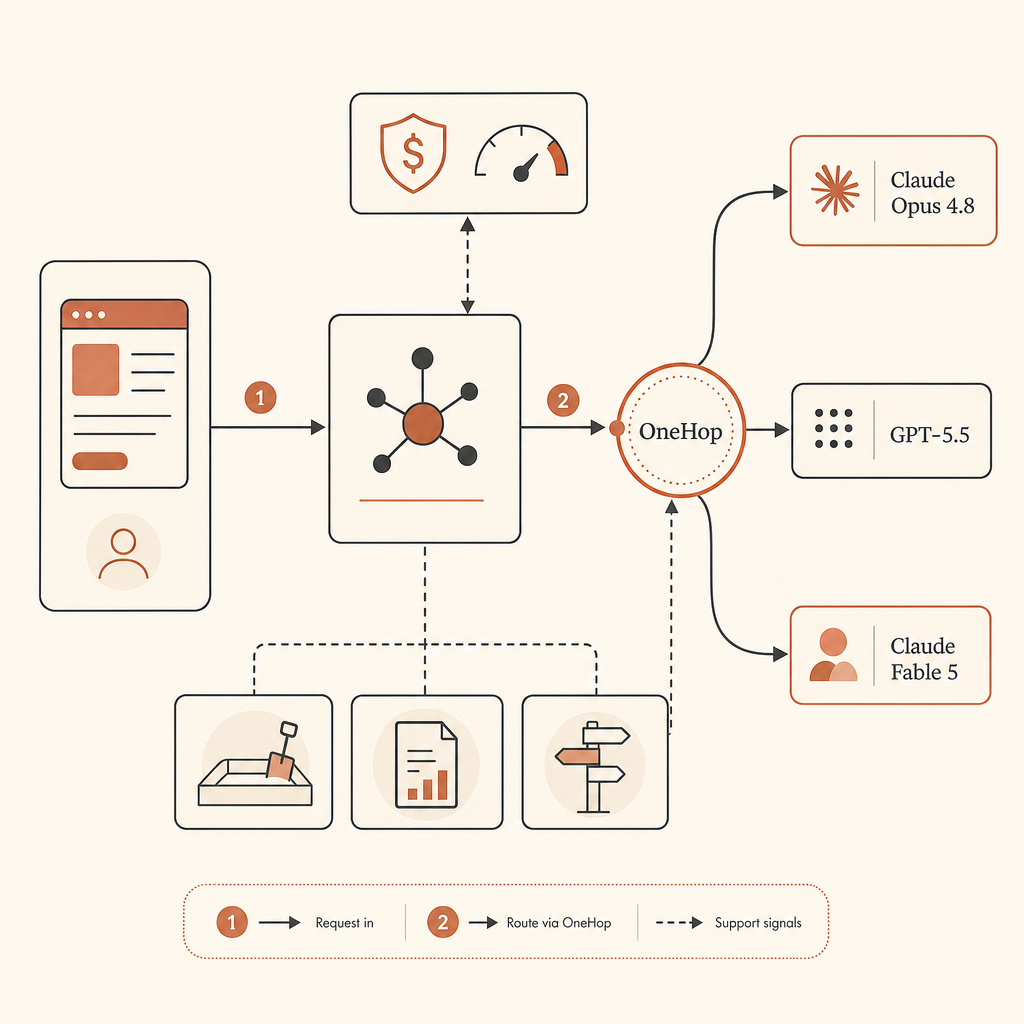
provider router가 거창할 필요는 없다. policy file부터 시작하라:
routes:
default_coding: claude-opus-4-8
critical_review: gpt-5.5
long_context_refactor: claude-opus-4-8
security_review: gpt-5.5
limits:
max_usd_per_task: 8
require_approval_over_usd: 3그다음 model call 전에 이를 enforce하라. 핵심은 완벽한 automatic routing을 쫓는 게 아니다. business continuity를 하나의 model ID에 hard-code하지 않는 것이다.
그래도 access가 가능할 때 Fable 5를 원한다면, OneHop은 routing table에 넣어둘 가장 friction 낮은 경로다. OneHop은 Claude Fable 5를 anthropic/claude-fable-5로 listed하고, 공식 $10/M input 및 $50/M output list price를 보여주며, discounted pricing과 카드 없이 신규 계정에 $10 free credit을 제공한다고 광고한다 (OneHop). 자연스러운 패턴은 app의 provider abstraction을 안정적으로 유지하고 base URL만 바꾸는 것이다.
OpenAI-compatible client에서는:
from openai import OpenAI
client = OpenAI(
base_url="https://api.onehop.ai/v1",
api_key="ONEHOP_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-fable-5",
messages=[
{"role": "user", "content": "Review this migration plan for hidden failure modes."}
],
)
print(response.choices[0].message.content)Fable route가 구체적으로 필요하다면 Claude Fable 5 on OneHop을 써라. provider routing을 처음부터 테스트한다면 $10 free로 시작하라.
최종 추천은 일부러 지루하게 했다. Fable 5를 쓸 수 없다면, Opus 4.8과 GPT-5.5 중 어느 쪽 personality가 더 나은지로 일주일을 쓰지 말라. Opus 4.8은 Claude fallback slot에 넣어라. GPT-5.5는 reviewer와 OpenAI-native slot에 넣어라. Fable 5는 가능할 때 OneHop을 통한 routed option으로 유지하라. 그리고 당신의 task에서 직접 측정하라. pass rate, human edits, wall-clock time, token cost, rollback count를.
그게 어른의 선택이다. 모델 팬 논쟁은 재미있다. production agent에는 exit plan이 필요하다.

