June 12 changed the routing conversation from “Which frontier model is best?” to “What happens when the model you picked disappears?”
Anthropic says it received a U.S. government directive at 5:21pm ET on June 12, 2026, requiring suspension of Fable 5 and Mythos 5 access for foreign nationals. Its practical answer was blunt: disable both models for all customers, while keeping other Anthropic models available (Anthropic). The same post says Anthropic reviewed the reported jailbreak basis and found the demonstrated capability “widely available” from other public models, explicitly naming OpenAI’s GPT-5.5 (Anthropic).
That makes the developer question unusually concrete. If Fable 5 is gone from your stack today, do you route to Claude Opus 4.8, switch to GPT-5.5, or build a provider router and stop betting your agent on one endpoint?
My answer: use Opus 4.8 as the default Claude-native fallback for existing Claude Code and Anthropic API workflows, use GPT-5.5 when you want stronger terminal-bench style coding evidence or OpenAI ecosystem fit, and add routing if the workload matters. If a single model outage can stop your agent, the bug is in your architecture.
What Actually Went Offline
Anthropic did not say “Claude is down.” It said Fable 5 and Mythos 5 were disabled for all customers, while “all other Anthropic models” remain available (Anthropic). That distinction matters.
Fable 5 was the public Mythos-class model. Mythos 5 was the more restricted version. Opus 4.8 remains live, and Anthropic positions it as a “hybrid reasoning model built for serious coding and AI agents,” with a 1M-token context window (Anthropic).
The dispute is also not just policy theater. Anthropic’s June 12 statement says the government concern involved a narrow jailbreak used to find a small number of already-known minor vulnerabilities, and Anthropic argues that other public models can discover the same class of issues without a bypass (Anthropic). That is why GPT-5.5 is relevant here. Anthropic named it as comparable for the disputed capability class.
For developers, the key fact is simpler: your production agent does not care why access vanished. It only sees failed calls, missing model IDs, degraded workflows, and users asking why yesterday’s tool no longer works.
Capability and Price Table
Here is the sober comparison. No invented benchmark soup, no vibes pretending to be data.
| Model | Current role | Input price | Output price | Context | Useful verified capability signals |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Best Anthropic fallback when Fable 5 is unavailable | $5 / 1M tokens | $25 / 1M tokens | 1M tokens | Anthropic says it is built for serious coding, agents, and long-running tasks; available in Claude API, AWS, Google Cloud, and Microsoft Foundry (Anthropic) |
| GPT-5.5 | Strong OpenAI alternative for coding agents | $5 / 1M tokens | $30 / 1M tokens | 1M tokens in API | OpenAI reports 58.6% on SWE-Bench Pro Public, 82.7% on Terminal-Bench 2.0, 81.8% on CyberGym, and 45.4% on Graphwalks BFS 1M F1 (OpenAI) |
| Claude Fable 5 | Preferred top-end Claude path, currently unavailable through Anthropic | $10 / 1M tokens list | $50 / 1M tokens list | 1M tokens | Disabled by Anthropic for all customers after the June 12 directive (Anthropic) |
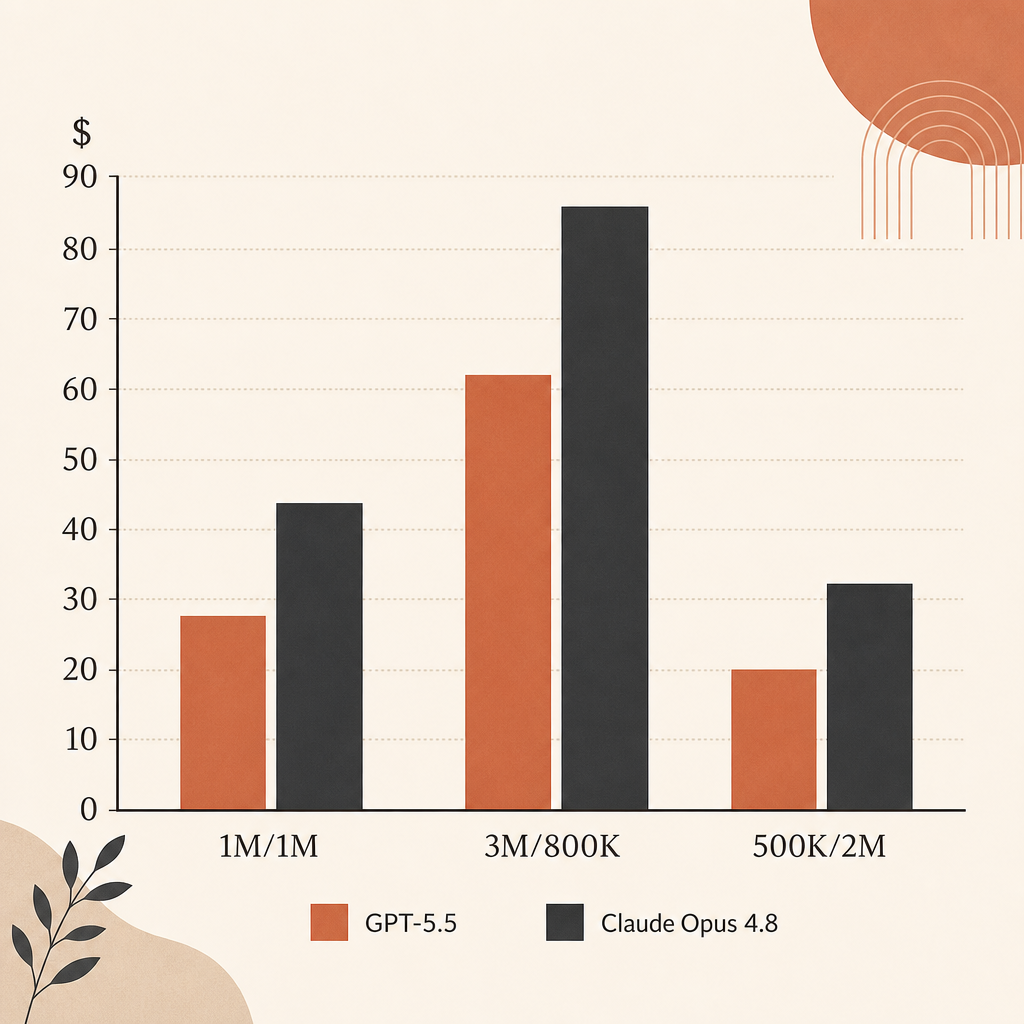
On raw list price, Opus 4.8 is cheaper than GPT-5.5 for output-heavy agent runs. Input is tied at $5/M. Output is $25/M for Opus 4.8 and $30/M for GPT-5.5.
A few realistic agent bills:
| Workload | Opus 4.8 | GPT-5.5 | Difference |
|---|---|---|---|
| 1M input, 1M output | $30 | $35 | GPT-5.5 costs 16.7% more |
| 3M input, 800K output | $35 | $39 | GPT-5.5 costs 11.4% more |
| 500K input, 2M output | $52.50 | $62.50 | GPT-5.5 costs 19.0% more |
That does not mean Opus always wins. A model that finishes in one pass can be cheaper than a cheaper model that loops, retries, or writes five pages of plan before touching the repo. The HN thread around Simon Willison’s Fable 5 debugging post is full of this exact split: some developers loved the “relentlessly proactive” behavior, others saw waste, token burn, and too much autonomous machinery for a small fix (Hacker News).
What the Community Debate Gets Right
The best developer discussion is not “Claude good” versus “OpenAI good.” It is about control.
Simon Willison’s June 11 writeup is the clearest artifact. He gave Claude Fable 5 a screenshot and one-line prompt about a scrollbar bug. The model built local repro pages, opened real browsers, used macOS window IDs through Quartz, captured screenshots, injected JavaScript, ran a tiny CORS server, measured the shadow DOM, then handed off to Opus after hitting a guardrail (Simon Willison). His cost tracker estimated the session would have cost about $12.11 at full price.
The HN thread under that post is useful because it rejects the fake consensus. One camp says this is exactly what agentic coding should be: use tools, verify against reality, produce artifacts. Another camp says burning dollars and shell access to fix a CSS scrollbar is the wrong abstraction, especially when the agent operates outside a tight sandbox (Hacker News).
Reddit is less tidy, but it captures the operational pain. In r/ClaudeCode, developers are already trying to distill Fable-like behavior into instruction files for Opus 4.8, sharing Fable5.md prompts, --append-system-prompt-file ideas, and “make Opus more proactive” recipes (Reddit). In r/cybersecurity and r/LocalLLaMA, the debate shifts to platform risk: if a frontier hosted model can be pulled overnight, should serious teams rely more on local models, multi-provider routing, or lower-tier hosted fallbacks (Reddit, Reddit).
The practical answer missing from many threads: do not try to “prompt” your way out of provider risk. Prompts can make Opus behave more like Fable. They cannot make an unavailable model available.
Use Opus 4.8 When You Want Claude Continuity
Pick Claude Opus 4.8 when your system already depends on Claude’s tool-use style, long-context behavior, Claude Code, Anthropic Messages API semantics, or prompt caching.
Opus 4.8 is the least disruptive fallback. Anthropic’s own Opus page says the model is available as claude-opus-4-8, starts at $5/M input and $25/M output, supports prompt caching savings up to 90%, and supports batch processing savings of 50% (Anthropic). If you built around Claude’s message format, system prompts, tool calls, or CLAUDE.md conventions, staying inside the Claude family reduces migration risk.
Use it for:
- Large codebase review where the model needs to hold many files and conventions.
- Agentic workflows that benefit from Claude’s cautious planning and self-checking.
- Teams already using Claude Code and wanting a low-friction Fable 5 fallback.
- Output-heavy jobs where GPT-5.5’s $30/M output price starts to matter.
- Workflows that can exploit prompt caching.
The weakness is benchmark clarity. OpenAI’s GPT-5.5 page gives a lot of text-readable benchmark numbers. Anthropic’s Opus 4.8 page gives positioning, pricing, context, partner quotes, and an image-based benchmark section, but fewer easily auditable numeric comparisons in page text. If your procurement process needs a table of named benchmark scores, GPT-5.5 is easier to defend.
Still, if the question is “What should my Claude agent call now that Fable is gone?”, start with Opus 4.8.
Use GPT-5.5 When You Want Evidence and OpenAI Fit
Pick GPT-5.5 when you want a strong coding model with public benchmark numbers, OpenAI API compatibility, or Codex integration.
OpenAI says GPT-5.5 is priced at $5/M input and $30/M output for API developers, with a 1M-token context window (OpenAI). Its published coding and tool numbers are strong: 82.7% on Terminal-Bench 2.0, 58.6% on SWE-Bench Pro Public, 75.3% on MCP Atlas, and 81.8% on CyberGym (OpenAI). OpenAI also classifies GPT-5.5 cyber and bio/chemical capabilities as High under its Preparedness Framework, while saying it did not reach Critical cybersecurity capability level (OpenAI).
Use it for:
- Terminal-heavy coding tasks where Terminal-Bench-style performance maps to your workload.
- Cross-checking Claude plans, especially security-sensitive or migration-heavy changes.
- Teams already standardized on OpenAI Responses or Chat Completions.
- Agent routers where GPT-5.5 acts as the reviewer, critic, or second-pass verifier.
- Cases where public numeric evals matter more than Claude workflow continuity.
The downside is cost on output-heavy runs. GPT-5.5 is not dramatically more expensive, but agent loops produce output. If your agent writes long plans, long diffs, long test logs, and long postmortems, that $5/M output delta shows up.
The Better Architecture: Route, Don’t Pray
Here is the selection guide I would actually ship:
- Default to Opus 4.8 for Claude-native coding agents.
- Route to GPT-5.5 for independent review, terminal-heavy tasks, and OpenAI-native stacks.
- Keep a Fable 5 path ready, but do not block production on it.
- Add budget caps, sandboxing, and per-task model policies.
- Log model, provider, token mix, fallback reason, and final human approval.
A provider router does not need to be fancy. Start with a policy file:
routes:
default_coding: claude-opus-4-8
critical_review: gpt-5.5
long_context_refactor: claude-opus-4-8
security_review: gpt-5.5
limits:
max_usd_per_task: 8
require_approval_over_usd: 3Then enforce it before the model call. The point is not to chase perfect automatic routing. The point is to avoid hard-coding business continuity to one model ID.
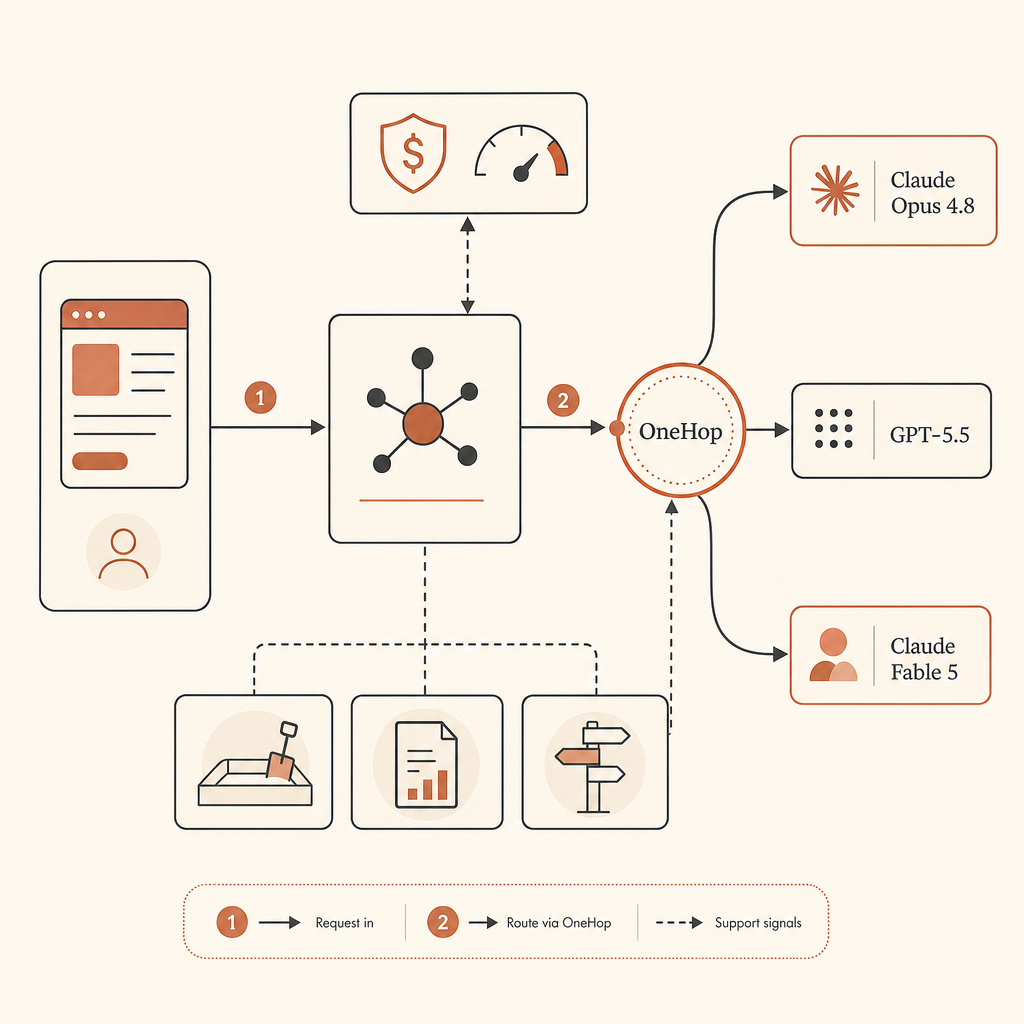
If you still want Fable 5 when access is available, OneHop is the lowest-friction path to keep in your routing table. OneHop lists Claude Fable 5 as anthropic/claude-fable-5, shows the official $10/M input and $50/M output list price, and advertises discounted pricing plus $10 free credit for new accounts with no card required (OneHop). The natural pattern is to keep your app’s provider abstraction stable and swap the base URL.
For OpenAI-compatible clients:
from openai import OpenAI
client = OpenAI(
base_url="https://api.onehop.ai/v1",
api_key="ONEHOP_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-fable-5",
messages=[
{"role": "user", "content": "Review this migration plan for hidden failure modes."}
],
)
print(response.choices[0].message.content)When you specifically want the Fable route, use Claude Fable 5 on OneHop. If you are testing provider routing from scratch, start with $10 free.
The final recommendation is intentionally boring. If Fable 5 is unavailable, do not spend the week arguing whether Opus 4.8 or GPT-5.5 has the better personality. Put Opus 4.8 in the Claude fallback slot. Put GPT-5.5 in the reviewer and OpenAI-native slot. Keep Fable 5 as a routed option through OneHop when available. Then measure your own tasks: pass rate, human edits, wall-clock time, token cost, and rollback count.
That is the adult move. Model fan debates are fun. Production agents need an exit plan.

