6 月 12 日之后,路由问题从“哪个前沿模型最强?”变成了“你选好的模型突然消失时怎么办?”
Anthropic 表示,它在 2026 年 6 月 12 日美东时间下午 5:21 收到一项美国政府指令,要求暂停外国公民访问 Fable 5 和 Mythos 5。它给出的实际处理很直接:对所有客户禁用这两个模型,同时保留其他 Anthropic 模型可用(Anthropic)。同一篇文章还说,Anthropic 复核了所称 jailbreak 的依据,发现演示中的能力在其他公开模型中“普遍可得”,并明确点名 OpenAI 的 GPT-5.5(Anthropic)。
这让开发者的问题变得异常具体。如果 Fable 5 今天从你的技术栈里消失了,你是路由到 Claude Opus 4.8,切到 GPT-5.5,还是搭一个 provider router,别再把你的 agent 押在一个 endpoint 上?
我的答案是:对于现有 Claude Code 和 Anthropic API 工作流,把 Opus 4.8 作为默认的 Claude 原生后备;当你需要更强的 terminal-bench 式编码证据,或者更契合 OpenAI 生态时,用 GPT-5.5;如果工作负载重要,就加上路由。如果一个模型宕掉就能让你的 agent 停摆,bug 在你的架构里。
到底是什么离线了
Anthropic 并没有说“Claude 挂了”。它说的是 Fable 5 和 Mythos 5 对所有客户禁用,而“所有其他 Anthropic 模型”仍然可用(Anthropic)。这个区别很重要。
Fable 5 是公开的 Mythos 级模型。Mythos 5 是限制更严格的版本。Opus 4.8 仍然在线,Anthropic 将它定位为“为严肃编码和 AI agents 打造的混合推理模型”,具备 1M-token 上下文窗口(Anthropic)。
这场争议也不只是政策表演。Anthropic 在 6 月 12 日的声明中说,政府担忧的是一种狭窄的 jailbreak,它被用于发现少量已知的轻微漏洞;Anthropic 则认为,其他公开模型无需 bypass 也能发现同一类问题(Anthropic)。这就是为什么 GPT-5.5 在这里相关。Anthropic 点名说它在争议所涉能力类别上具有可比性。
对开发者来说,关键事实更简单:你的生产 agent 不在乎访问为什么消失。它只会看到调用失败、模型 ID 缺失、工作流降级,以及用户追问为什么昨天还能用的工具今天不行了。
能力与价格表
下面是冷静版对比。没有凭空捏造的 benchmark 大杂烩,也没有把感觉伪装成数据。
| Model | 当前角色 | 输入价格 | 输出价格 | 上下文 | 有用且已验证的能力信号 |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Fable 5 不可用时最好的 Anthropic 后备 | $5 / 1M tokens | $25 / 1M tokens | 1M tokens | Anthropic 称它为严肃编码、agents 和长时间运行任务而构建;可在 Claude API、AWS、Google Cloud 和 Microsoft Foundry 中使用(Anthropic) |
| GPT-5.5 | 面向 coding agents 的强 OpenAI 替代方案 | $5 / 1M tokens | $30 / 1M tokens | API 中为 1M tokens | OpenAI 报告其在 SWE-Bench Pro Public 上为 58.6%,Terminal-Bench 2.0 上为 82.7%,CyberGym 上为 81.8%,Graphwalks BFS 1M F1 上为 45.4%(OpenAI) |
| Claude Fable 5 | 首选的高端 Claude 路径,目前无法通过 Anthropic 使用 | $10 / 1M tokens 标价 | $50 / 1M tokens 标价 | 1M tokens | 在 6 月 12 日指令后,被 Anthropic 对所有客户禁用(Anthropic) |
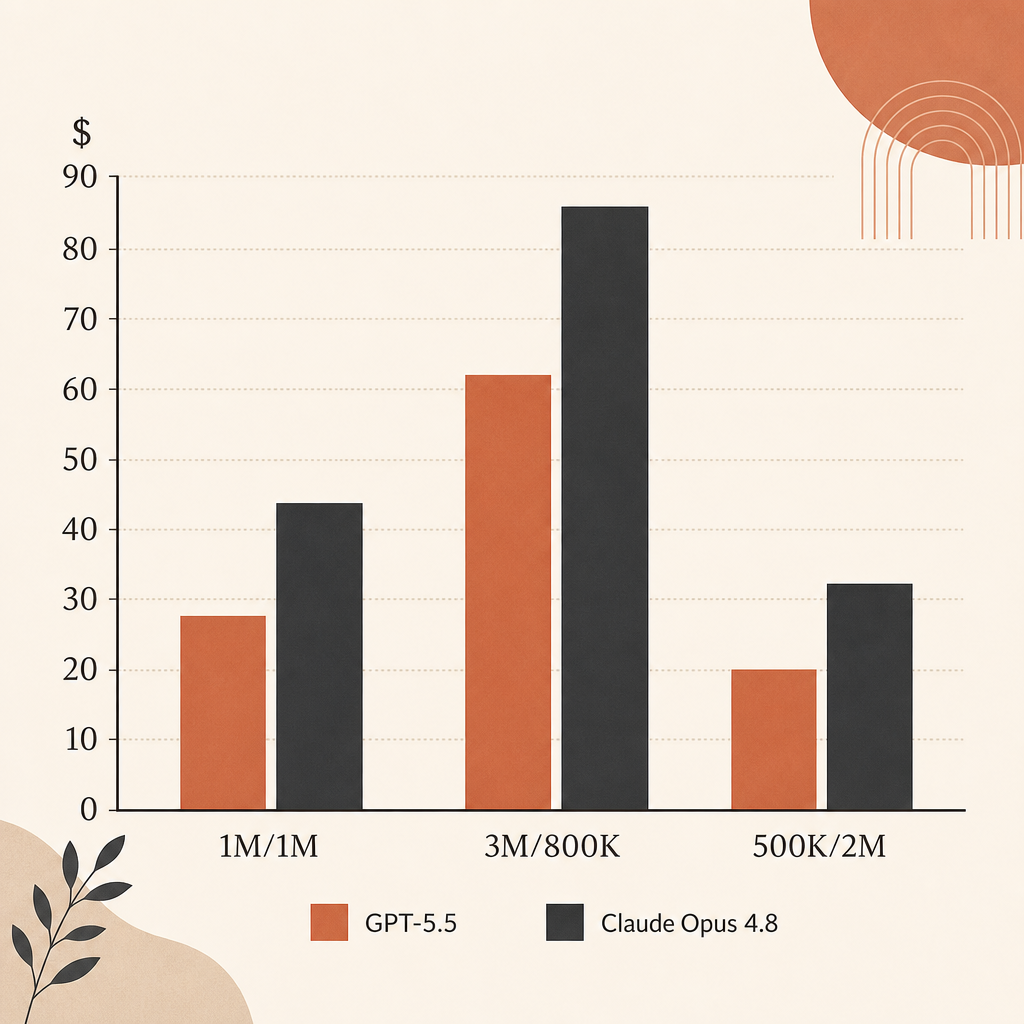
按原始标价看,输出较重的 agent 运行中,Opus 4.8 比 GPT-5.5 便宜。输入同为 $5/M。输出则是 Opus 4.8 的 $25/M,对比 GPT-5.5 的 $30/M。
几个现实中的 agent 账单:
| 工作负载 | Opus 4.8 | GPT-5.5 | 差异 |
|---|---|---|---|
| 1M 输入,1M 输出 | $30 | $35 | GPT-5.5 贵 16.7% |
| 3M 输入,800K 输出 | $35 | $39 | GPT-5.5 贵 11.4% |
| 500K 输入,2M 输出 | $52.50 | $62.50 | GPT-5.5 贵 19.0% |
这并不意味着 Opus 总是赢。一个一次就完成的模型,可能比一个更便宜但会循环、重试,或者在碰 repo 之前先写五页计划的模型更省钱。Simon Willison 关于 Fable 5 调试文章下面的 HN 讨论,正好充满了这种分歧:有些开发者喜欢那种“ relentlessly proactive ”的行为,另一些人看到的则是浪费、token 燃烧,以及为一个小修复引入过多自主机制(Hacker News)。
社区争论说对了什么
最好的开发者讨论并不是“Claude 好”对“OpenAI 好”。真正的问题是控制权。
Simon Willison 6 月 11 日的文章是最清楚的样本。他给 Claude Fable 5 一张截图,以及一句关于滚动条 bug 的提示。模型创建了本地复现页面,打开真实浏览器,通过 Quartz 使用 macOS window IDs,截屏,注入 JavaScript,跑了一个很小的 CORS server,测量 shadow DOM,然后在触发 guardrail 后交接给 Opus(Simon Willison)。他的成本追踪器估算,如果按全价计算,这次会话大约要花 $12.11。
那篇文章下面的 HN 讨论很有价值,因为它拒绝了虚假的共识。一派认为,这正是 agentic coding 应该有的样子:使用工具,对现实做验证,产出 artifacts。另一派认为,为了修一个 CSS 滚动条烧钱和开放 shell access 是错误的抽象,尤其当 agent 不在严格 sandbox 中运行时(Hacker News)。
Reddit 没那么整齐,但它捕捉到了运维上的痛点。在 r/ClaudeCode,开发者已经在尝试把类似 Fable 的行为提炼成给 Opus 4.8 用的 instruction files,分享 Fable5.md prompts、--append-system-prompt-file 想法,以及“让 Opus 更主动”的配方(Reddit)。在 r/cybersecurity 和 r/LocalLLaMA,讨论转向平台风险:如果一个前沿托管模型能一夜之间被下架,严肃团队是否应该更多依赖本地模型、多 provider routing,或者低一档的托管后备(Reddit, Reddit)。
很多帖子漏掉的现实答案是:不要试图靠“prompt”来摆脱 provider 风险。Prompts 可以让 Opus 的行为更像 Fable。它们不能让一个不可用的模型变得可用。
想保持 Claude 连续性,就用 Opus 4.8
当你的系统已经依赖 Claude 的 tool-use 风格、长上下文行为、Claude Code、Anthropic Messages API 语义,或 prompt caching 时,选 Claude Opus 4.8。
Opus 4.8 是干扰最小的后备方案。Anthropic 自己的 Opus 页面说,该模型以 claude-opus-4-8 提供,起价为输入 $5/M、输出 $25/M,支持最高节省 90% 的 prompt caching,也支持节省 50% 的 batch processing(Anthropic)。如果你围绕 Claude 的消息格式、system prompts、tool calls 或 CLAUDE.md 惯例搭建系统,留在 Claude 家族内部可以降低迁移风险。
适合用于:
- 大型代码库审查,需要模型记住大量文件和约定。
- 受益于 Claude 谨慎规划和自我检查的 agentic workflows。
- 已经使用 Claude Code,并希望低摩擦获得 Fable 5 后备的团队。
- 输出较重、GPT-5.5 的 $30/M 输出价格开始有感的任务。
- 能利用 prompt caching 的工作流。
弱点是 benchmark 清晰度。OpenAI 的 GPT-5.5 页面给了很多文本可读的 benchmark 数字。Anthropic 的 Opus 4.8 页面给的是定位、价格、上下文、合作伙伴引述,以及一段图片形式的 benchmark 区域,但页面文本里更少有容易审计的数字对比。如果你的采购流程需要一张命名 benchmark 分数表,GPT-5.5 更容易拿来辩护。
不过,如果问题是“Fable 没了,我的 Claude agent 现在该调用什么?”,先从 Opus 4.8 开始。
想要证据和 OpenAI 适配,就用 GPT-5.5
当你想要一个带公开 benchmark 数字的强编码模型、OpenAI API 兼容性,或者 Codex 集成时,选 GPT-5.5。
OpenAI 称,GPT-5.5 面向 API 开发者的价格为输入 $5/M、输出 $30/M,并具备 1M-token 上下文窗口(OpenAI)。它公开的编码和工具使用数字很强:Terminal-Bench 2.0 上 82.7%,SWE-Bench Pro Public 上 58.6%,MCP Atlas 上 75.3%,CyberGym 上 81.8%(OpenAI)。OpenAI 还根据其 Preparedness Framework 将 GPT-5.5 的网络与生物/化学能力归为 High,同时表示它没有达到 Critical cybersecurity capability level(OpenAI)。
适合用于:
- 终端密集型编码任务,且 Terminal-Bench 式表现能映射到你的工作负载。
- 交叉检查 Claude 方案,尤其是安全敏感或迁移较重的改动。
- 已经标准化使用 OpenAI Responses 或 Chat Completions 的团队。
- 在 agent routers 中,让 GPT-5.5 充当 reviewer、critic 或二次验证器。
- 公开数字评测比 Claude 工作流连续性更重要的场景。
缺点是输出较重时成本更高。GPT-5.5 并没有贵得离谱,但 agent loops 会产生输出。如果你的 agent 写长计划、长 diffs、长测试日志和长 postmortems,那每百万输出多 $5 的差额会显现出来。
更好的架构:Route, Don’t Pray
这是我真正会发到生产里的选择指南:
- Claude 原生 coding agents 默认使用 Opus 4.8。
- 对独立审查、终端密集任务和 OpenAI 原生技术栈,路由到 GPT-5.5。
- 保留 Fable 5 路径,但不要让生产环境依赖它才能运行。
- 加上预算上限、sandboxing 和按任务划分的模型策略。
- 记录模型、provider、token 结构、fallback 原因,以及最终人工批准。
provider router 不需要花哨。先从一个 policy file 开始:
routes:
default_coding: claude-opus-4-8
critical_review: gpt-5.5
long_context_refactor: claude-opus-4-8
security_review: gpt-5.5
limits:
max_usd_per_task: 8
require_approval_over_usd: 3然后在模型调用前强制执行。重点不是追求完美的自动路由。重点是别把业务连续性硬编码到一个 model ID 上。
如果你仍然想在可访问时使用 Fable 5,OneHop 是路由表里摩擦最低的路径。OneHop 将 Claude Fable 5 列为 anthropic/claude-fable-5,展示官方 $10/M 输入和 $50/M 输出标价,并宣传折扣价格,以及新账号无需绑卡即可获得 $10 免费额度(OneHop)。自然的模式是保持应用的 provider abstraction 稳定,然后替换 base URL。
对于 OpenAI-compatible clients:
from openai import OpenAI
client = OpenAI(
base_url="https://api.onehop.ai/v1",
api_key="ONEHOP_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-fable-5",
messages=[
{"role": "user", "content": "Review this migration plan for hidden failure modes."}
],
)
print(response.choices[0].message.content)当你明确想走 Fable 路线时,使用 OneHop 上的 Claude Fable 5。如果你要从零开始测试 provider routing,可以从 $10 免费额度开始。
最后的建议故意很无聊。如果 Fable 5 不可用,别花一周争论 Opus 4.8 和 GPT-5.5 谁的“性格”更好。把 Opus 4.8 放进 Claude fallback slot。把 GPT-5.5 放进 reviewer 和 OpenAI-native slot。在可用时,把 Fable 5 作为通过 OneHop 路由的选项保留。然后衡量你自己的任务:通过率、人工修改量、wall-clock time、token 成本和回滚次数。
这才是成年人做法。模型粉丝辩论很好玩。生产 agents 需要的是退出方案。

