12 Haziran, yönlendirme tartışmasını “En iyi sınır modeli hangisi?” noktasından “Seçtiğin model bir anda ortadan kaybolursa ne olur?” noktasına taşıdı.
Anthropic, 12 Haziran 2026 saat 17:21 ET’de ABD hükümetinden, yabancı uyruklular için Fable 5 ve Mythos 5 erişiminin askıya alınmasını gerektiren bir talimat aldığını söylüyor. Pratik yanıtı gayet sertti: Diğer Anthropic modellerini erişilebilir tutarken iki modeli de tüm müşteriler için devre dışı bırakmak (Anthropic). Aynı gönderide Anthropic, bildirilen jailbreak gerekçesini incelediğini ve gösterilen kabiliyeti, OpenAI’ın GPT-5.5’ini açıkça isim vererek, diğer herkese açık modellerde de “yaygın olarak mevcut” bulduğunu söylüyor (Anthropic).
Bu da geliştirici sorusunu alışılmadık derecede somut hale getiriyor. Fable 5 bugün stack’inden çıktıysa Claude Opus 4.8’e mi yönlendirirsin, GPT-5.5’e mi geçersin, yoksa bir sağlayıcı yönlendiricisi kurup ajanını tek bir endpoint’e bağlama alışkanlığını bırakır mısın?
Benim cevabım: Mevcut Claude Code ve Anthropic API iş akışları için varsayılan Claude-yerel yedek olarak Opus 4.8’i kullan, daha güçlü terminal-bench tarzı kodlama kanıtı ya da OpenAI ekosistemi uyumu istediğinde GPT-5.5’i kullan, iş yükü önemliyse de yönlendirme ekle. Tek bir model kesintisi ajanını durdurabiliyorsa hata mimarindedir.
Gerçekte Ne Çevrimdışı Oldu
Anthropic “Claude kapalı” demedi. Fable 5 ve Mythos 5’in tüm müşteriler için devre dışı bırakıldığını, buna karşılık “diğer tüm Anthropic modellerinin” erişilebilir kaldığını söyledi (Anthropic). Bu ayrım önemli.
Fable 5, herkese açık Mythos sınıfı modeldi. Mythos 5 ise daha kısıtlı sürümdü. Opus 4.8 hâlâ canlı ve Anthropic onu 1M token bağlam penceresine sahip, “ciddi kodlama ve AI ajanları için geliştirilmiş hibrit akıl yürütme modeli” olarak konumlandırıyor (Anthropic).
Tartışma sadece politika tiyatrosu da değil. Anthropic’in 12 Haziran açıklamasına göre hükümetin endişesi, zaten bilinen az sayıdaki küçük güvenlik açığını bulmak için kullanılan dar kapsamlı bir jailbreak ile ilgiliydi; Anthropic ise diğer herkese açık modellerin de aynı tür sorunları bir bypass olmadan keşfedebileceğini savunuyor (Anthropic). GPT-5.5’in burada ilgili olmasının sebebi bu. Anthropic, tartışmalı kabiliyet sınıfı için onu karşılaştırılabilir model olarak bizzat adlandırdı.
Geliştiriciler için kilit gerçek daha basit: Üretimdeki ajanın erişimin neden kaybolduğunu umursamaz. Sadece başarısız çağrıları, eksik model ID’lerini, bozulan iş akışlarını ve dün çalışan aracın bugün neden çalışmadığını soran kullanıcıları görür.
Kabiliyet ve Fiyat Tablosu
İşte ayık karşılaştırma. Uydurma benchmark çorbası yok, veriymiş gibi davranan hisler yok.
| Model | Mevcut rol | Girdi fiyatı | Çıktı fiyatı | Bağlam | Faydalı doğrulanmış kabiliyet sinyalleri |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Fable 5 kullanılamadığında en iyi Anthropic yedeği | $5 / 1M token | $25 / 1M token | 1M token | Anthropic, ciddi kodlama, ajanlar ve uzun süren görevler için geliştirildiğini söylüyor; Claude API, AWS, Google Cloud ve Microsoft Foundry’de mevcut (Anthropic) |
| GPT-5.5 | Kodlama ajanları için güçlü OpenAI alternatifi | $5 / 1M token | $30 / 1M token | API’de 1M token | OpenAI; SWE-Bench Pro Public’te %58,6, Terminal-Bench 2.0’da %82,7, CyberGym’de %81,8 ve Graphwalks BFS 1M F1’de %45,4 bildirdi (OpenAI) |
| Claude Fable 5 | Tercih edilen üst seviye Claude yolu, şu anda Anthropic üzerinden kullanılamıyor | $10 / 1M token liste | $50 / 1M token liste | 1M token | 12 Haziran talimatından sonra Anthropic tarafından tüm müşteriler için devre dışı bırakıldı (Anthropic) |
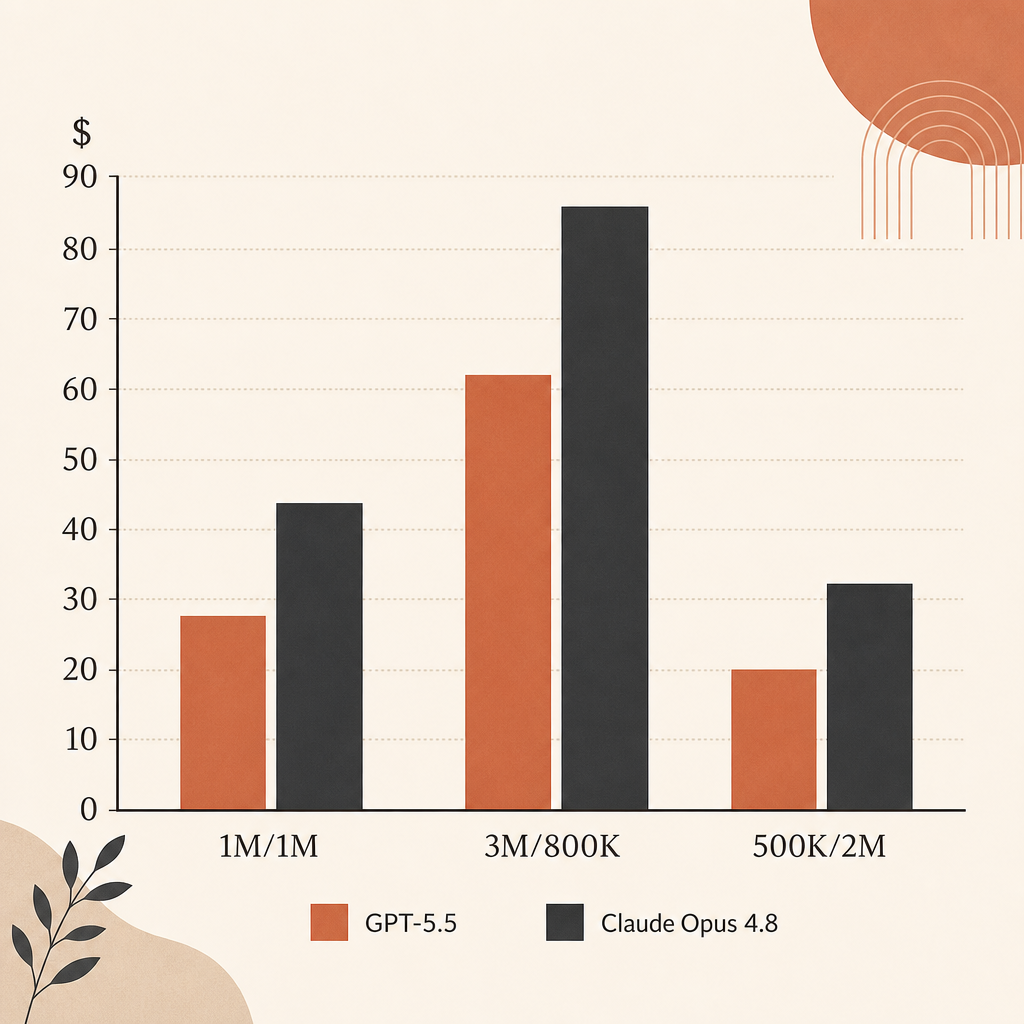
Ham liste fiyatında Opus 4.8, çıktısı ağır ajan çalıştırmalarında GPT-5.5’ten daha ucuz. Girdi $5/M ile eşit. Çıktı Opus 4.8 için $25/M, GPT-5.5 için $30/M.
Birkaç gerçekçi ajan faturası:
| İş yükü | Opus 4.8 | GPT-5.5 | Fark |
|---|---|---|---|
| 1M girdi, 1M çıktı | $30 | $35 | GPT-5.5 %16,7 daha pahalı |
| 3M girdi, 800K çıktı | $35 | $39 | GPT-5.5 %11,4 daha pahalı |
| 500K girdi, 2M çıktı | $52.50 | $62.50 | GPT-5.5 %19,0 daha pahalı |
Bu, Opus her zaman kazanır demek değil. Tek geçişte işi bitiren bir model, döngüye giren, yeniden deneyen ya da repoya dokunmadan önce beş sayfa plan yazan daha ucuz bir modelden daha ucuza gelebilir. Simon Willison’ın Fable 5 hata ayıklama yazısı etrafındaki HN başlığı tam da bu ayrımla dolu: Bazı geliştiriciler “inatla proaktif” davranışı sevdi, bazıları ise küçük bir düzeltme için israf, token yakma ve fazla otonom mekanik gördü (Hacker News).
Topluluk Tartışmasının Doğru Yakaladığı Şey
En iyi geliştirici tartışması “Claude iyi” ile “OpenAI iyi” arasında değil. Kontrol hakkında.
Simon Willison’ın 11 Haziran yazısı en net örnek. Claude Fable 5’e bir ekran görüntüsü ve kaydırma çubuğu hatasıyla ilgili tek satırlık bir prompt verdi. Model yerel repro sayfaları kurdu, gerçek tarayıcılar açtı, Quartz üzerinden macOS pencere ID’lerini kullandı, ekran görüntüleri aldı, JavaScript enjekte etti, küçük bir CORS sunucusu çalıştırdı, shadow DOM’u ölçtü ve ardından bir guardrail’e takılınca işi Opus’a devretti (Simon Willison). Maliyet takipçisi, seansın tam fiyatla yaklaşık $12.11 tutacağını tahmin etti.
O yazının altındaki HN başlığı işe yarıyor çünkü sahte fikir birliğini reddediyor. Bir taraf, ajanlı kodlamanın tam olarak böyle olması gerektiğini söylüyor: araçları kullan, gerçekliğe karşı doğrula, somut çıktılar üret. Diğer taraf ise bir CSS kaydırma çubuğunu düzeltmek için dolarları ve shell erişimini yakmanın, özellikle ajan sıkı bir sandbox dışında çalışıyorsa, yanlış soyutlama olduğunu söylüyor (Hacker News).
Reddit daha dağınık, ama operasyonel acıyı iyi yakalıyor. r/ClaudeCode’da geliştiriciler Fable benzeri davranışı Opus 4.8 için talimat dosyalarına damıtmaya başlamış durumda; Fable5.md promptları, --append-system-prompt-file fikirleri ve “Opus’u daha proaktif yapma” tarifleri paylaşılıyor (Reddit). r/cybersecurity ve r/LocalLLaMA’da tartışma platform riskine kayıyor: Sınır seviyesinde barındırılan bir model bir gecede çekilebiliyorsa, ciddi ekipler yerel modellere, çok sağlayıcılı yönlendirmeye ya da daha alt seviye barındırılan yedeklere daha mı fazla yaslanmalı (Reddit, Reddit).
Birçok başlıkta eksik kalan pratik cevap şu: Sağlayıcı riskinden “prompt” yazarak kurtulmaya çalışma. Promptlar Opus’un Fable’a daha çok benzemesini sağlayabilir. Kullanılamayan bir modeli kullanılabilir hale getiremez.
Claude Sürekliliği İstediğinde Opus 4.8 Kullan
Sistemin zaten Claude’un araç kullanma stiline, uzun bağlam davranışına, Claude Code’a, Anthropic Messages API semantiğine ya da prompt caching’e bağlıysa Claude Opus 4.8’i seç.
Opus 4.8 en az sarsıntılı yedektir. Anthropic’in kendi Opus sayfası modelin claude-opus-4-8 olarak mevcut olduğunu, $5/M girdi ve $25/M çıktıdan başladığını, %90’a kadar prompt caching tasarrufu ve %50 batch processing tasarrufu desteklediğini söylüyor (Anthropic). Claude’un mesaj formatı, sistem promptları, tool call’ları ya da CLAUDE.md gelenekleri üzerine kurduysan Claude ailesinde kalmak geçiş riskini azaltır.
Şunlar için kullan:
- Modelin çok sayıda dosyayı ve kuralı aklında tutması gereken büyük kod tabanı incelemeleri.
- Claude’un temkinli planlama ve kendi kendini kontrol etme tarzından fayda gören ajanlı iş akışları.
- Zaten Claude Code kullanan ve düşük sürtünmeli bir Fable 5 yedeği isteyen ekipler.
- GPT-5.5’in $30/M çıktı fiyatının önem kazanmaya başladığı çıktı ağırlıklı işler.
- Prompt caching’den yararlanabilen iş akışları.
Zayıf tarafı benchmark netliği. OpenAI’ın GPT-5.5 sayfası metinde okunabilir çok sayıda benchmark değeri veriyor. Anthropic’in Opus 4.8 sayfası konumlandırma, fiyatlandırma, bağlam, iş ortağı alıntıları ve görsel tabanlı bir benchmark bölümü sunuyor, ama sayfa metninde kolay denetlenebilir sayısal karşılaştırmalar daha az. Satın alma sürecin isimli benchmark skorlarından oluşan bir tablo istiyorsa GPT-5.5’i savunmak daha kolay.
Yine de soru “Fable gittiğine göre Claude ajanım şimdi neyi çağırmalı?” ise Opus 4.8 ile başla.
Kanıt ve OpenAI Uyumu İstediğinde GPT-5.5 Kullan
Herkese açık benchmark rakamları, OpenAI API uyumluluğu ya da Codex entegrasyonu olan güçlü bir kodlama modeli istediğinde GPT-5.5’i seç.
OpenAI, GPT-5.5’in API geliştiricileri için $5/M girdi ve $30/M çıktı fiyatına sahip olduğunu, 1M token bağlam penceresi sunduğunu söylüyor (OpenAI). Yayınlanan kodlama ve araç rakamları güçlü: Terminal-Bench 2.0’da %82,7, SWE-Bench Pro Public’te %58,6, MCP Atlas’ta %75,3 ve CyberGym’de %81,8 (OpenAI). OpenAI ayrıca GPT-5.5’in siber ve biyo/kimyasal kabiliyetlerini Preparedness Framework altında High olarak sınıflandırıyor, ama Critical siber güvenlik kabiliyeti seviyesine ulaşmadığını söylüyor (OpenAI).
Şunlar için kullan:
- Terminal-Bench tarzı performansın iş yükünle örtüştüğü terminal ağırlıklı kodlama görevleri.
- Claude planlarını çapraz kontrol etmek, özellikle güvenlik hassasiyeti olan ya da ağır migrasyon içeren değişikliklerde.
- Zaten OpenAI Responses veya Chat Completions üzerinde standartlaşmış ekipler.
- GPT-5.5’in gözden geçiren, eleştirmen ya da ikinci geçiş doğrulayıcı olarak davrandığı ajan yönlendiricileri.
- Herkese açık sayısal eval’ların Claude iş akışı sürekliliğinden daha önemli olduğu durumlar.
Dezavantajı çıktı ağırlıklı çalıştırmalarda maliyet. GPT-5.5 dramatik biçimde daha pahalı değil, ama ajan döngüleri çıktı üretir. Ajanın uzun planlar, uzun diff’ler, uzun test log’ları ve uzun postmortem’ler yazıyorsa, o $5/M çıktı farkı görünür hale gelir.
Daha İyi Mimari: Dua Etme, Yönlendir
Benim gerçekten ship edeceğim seçim rehberi şu:
- Claude-yerel kodlama ajanlarında varsayılan olarak Opus 4.8 kullan.
- Bağımsız inceleme, terminal ağırlıklı görevler ve OpenAI-yerel stack’ler için GPT-5.5’e yönlendir.
- Fable 5 yolunu hazır tut, ama üretimi ona bağlama.
- Bütçe sınırları, sandboxing ve görev bazlı model politikaları ekle.
- Modeli, sağlayıcıyı, token karışımını, fallback gerekçesini ve nihai insan onayını logla.
Bir sağlayıcı yönlendiricisinin süslü olması gerekmez. Bir politika dosyasıyla başla:
routes:
default_coding: claude-opus-4-8
critical_review: gpt-5.5
long_context_refactor: claude-opus-4-8
security_review: gpt-5.5
limits:
max_usd_per_task: 8
require_approval_over_usd: 3Sonra model çağrısından önce bunu uygula. Mesele kusursuz otomatik yönlendirme peşinde koşmak değil. Mesele iş sürekliliğini tek bir model ID’sine hard-code etmemek.
Erişim varken hâlâ Fable 5 istiyorsan, OneHop yönlendirme tablosunda tutabileceğin en düşük sürtünmeli yol. OneHop, Claude Fable 5’i anthropic/claude-fable-5 olarak listeliyor, resmi $10/M girdi ve $50/M çıktı liste fiyatını gösteriyor, ayrıca indirimli fiyatlandırma ve kart gerektirmeden yeni hesaplara $10 ücretsiz kredi sunduğunu söylüyor (OneHop). Doğal kalıp, uygulamanın sağlayıcı soyutlamasını sabit tutup base URL’i değiştirmek.
OpenAI uyumlu istemciler için:
from openai import OpenAI
client = OpenAI(
base_url="https://api.onehop.ai/v1",
api_key="ONEHOP_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-fable-5",
messages=[
{"role": "user", "content": "Review this migration plan for hidden failure modes."}
],
)
print(response.choices[0].message.content)Özellikle Fable rotasını istediğinde OneHop’ta Claude Fable 5 kullan. Sağlayıcı yönlendirmeyi sıfırdan test ediyorsan $10 ücretsiz krediyle başla.
Son öneri bilinçli olarak sıkıcı. Fable 5 kullanılamıyorsa haftayı Opus 4.8 mi yoksa GPT-5.5 mi daha iyi kişiliğe sahip diye tartışarak geçirme. Claude fallback yuvasına Opus 4.8’i koy. İnceleyici ve OpenAI-yerel yuvaya GPT-5.5’i koy. Fable 5’i erişilebilir olduğunda OneHop üzerinden yönlendirilmiş bir seçenek olarak tut. Sonra kendi görevlerini ölç: başarı oranı, insan düzenlemeleri, duvar saati süresi, token maliyeti ve rollback sayısı.
Yetişkin işi budur. Model fan tartışmaları eğlencelidir. Üretim ajanlarının çıkış planına ihtiyacı vardır.

