El 12 de junio cambió la conversación sobre enrutamiento: de “¿qué modelo de frontera es el mejor?” a “¿qué pasa cuando el modelo que elegiste desaparece?”
Anthropic dice que recibió una directiva del gobierno de EE. UU. a las 5:21 p. m. ET del 12 de junio de 2026, que exigía suspender el acceso a Fable 5 y Mythos 5 para ciudadanos extranjeros. Su respuesta práctica fue tajante: desactivar ambos modelos para todos los clientes, manteniendo disponibles los demás modelos de Anthropic (Anthropic). La misma publicación dice que Anthropic revisó la supuesta base del jailbreak y concluyó que la capacidad demostrada está “ampliamente disponible” en otros modelos públicos, nombrando explícitamente a GPT-5.5 de OpenAI (Anthropic).
Eso vuelve la pregunta para desarrolladores inusualmente concreta. Si Fable 5 desapareció hoy de tu stack, ¿rediriges a Claude Opus 4.8, cambias a GPT-5.5 o construyes un router de proveedores y dejas de apostar tu agente a un solo endpoint?
Mi respuesta: usa Opus 4.8 como fallback Claude-nativo por defecto para flujos existentes de Claude Code y Anthropic API, usa GPT-5.5 cuando quieras evidencia más sólida de estilo terminal-bench para programación o encaje con el ecosistema OpenAI, y añade enrutamiento si la carga de trabajo importa. Si una caída de un solo modelo puede detener tu agente, el bug está en tu arquitectura.
Qué Se Desconectó Realmente
Anthropic no dijo “Claude está caído”. Dijo que Fable 5 y Mythos 5 fueron desactivados para todos los clientes, mientras que “todos los demás modelos de Anthropic” siguen disponibles (Anthropic). Esa distinción importa.
Fable 5 era el modelo público de clase Mythos. Mythos 5 era la versión más restringida. Opus 4.8 sigue activo, y Anthropic lo presenta como un “modelo de razonamiento híbrido creado para programación seria y agentes de IA”, con una ventana de contexto de 1M de tokens (Anthropic).
La disputa tampoco es puro teatro político. La declaración de Anthropic del 12 de junio dice que la preocupación del gobierno se centraba en un jailbreak estrecho usado para encontrar un pequeño número de vulnerabilidades menores ya conocidas, y Anthropic sostiene que otros modelos públicos pueden descubrir la misma clase de problemas sin un bypass (Anthropic). Por eso GPT-5.5 es relevante aquí. Anthropic lo nombró como comparable para esa clase de capacidad en disputa.
Para desarrolladores, el dato clave es más simple: a tu agente de producción no le importa por qué desapareció el acceso. Solo ve llamadas fallidas, IDs de modelo ausentes, flujos degradados y usuarios preguntando por qué la herramienta de ayer ya no funciona.
Tabla de Capacidades y Precios
Aquí va la comparación sobria. Sin sopa de benchmarks inventados, sin vibes disfrazadas de datos.
| Model | Current role | Input price | Output price | Context | Useful verified capability signals |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Mejor fallback de Anthropic cuando Fable 5 no está disponible | $5 / 1M tokens | $25 / 1M tokens | 1M tokens | Anthropic dice que está creado para programación seria, agentes y tareas de larga duración; disponible en Claude API, AWS, Google Cloud y Microsoft Foundry (Anthropic) |
| GPT-5.5 | Alternativa sólida de OpenAI para agentes de programación | $5 / 1M tokens | $30 / 1M tokens | 1M tokens en API | OpenAI reporta 58.6% en SWE-Bench Pro Public, 82.7% en Terminal-Bench 2.0, 81.8% en CyberGym y 45.4% en Graphwalks BFS 1M F1 (OpenAI) |
| Claude Fable 5 | Ruta Claude de gama alta preferida, actualmente no disponible a través de Anthropic | $10 / 1M tokens de lista | $50 / 1M tokens de lista | 1M tokens | Desactivado por Anthropic para todos los clientes tras la directiva del 12 de junio (Anthropic) |
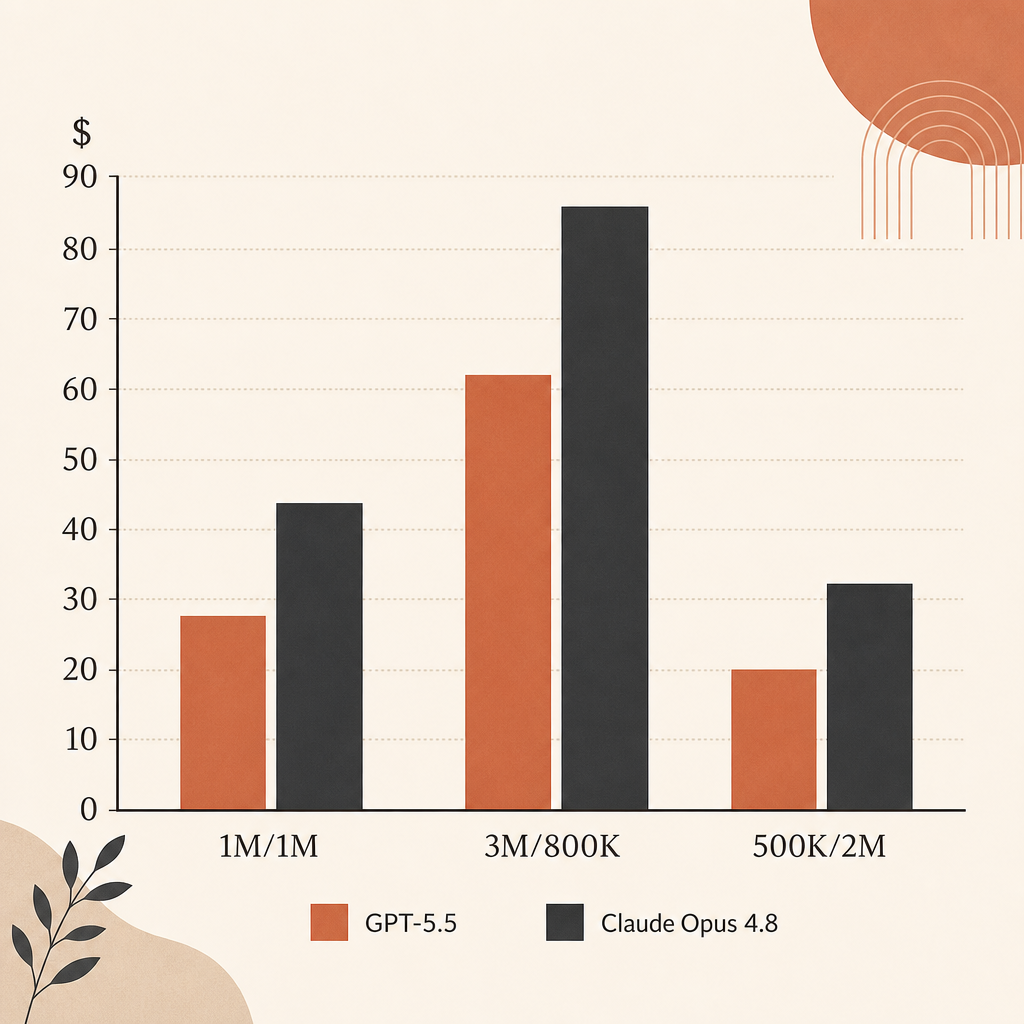
En precio de lista bruto, Opus 4.8 es más barato que GPT-5.5 para ejecuciones de agentes cargadas de salida. La entrada empata en $5/M. La salida es $25/M para Opus 4.8 y $30/M para GPT-5.5.
Unas cuantas facturas realistas de agentes:
| Workload | Opus 4.8 | GPT-5.5 | Difference |
|---|---|---|---|
| 1M input, 1M output | $30 | $35 | GPT-5.5 cuesta 16.7% más |
| 3M input, 800K output | $35 | $39 | GPT-5.5 cuesta 11.4% más |
| 500K input, 2M output | $52.50 | $62.50 | GPT-5.5 cuesta 19.0% más |
Eso no significa que Opus gane siempre. Un modelo que termina en una sola pasada puede salir más barato que un modelo más barato que entra en bucles, reintenta o escribe cinco páginas de plan antes de tocar el repo. El hilo de HN alrededor del post de debugging con Fable 5 de Simon Willison está lleno de esa división exacta: algunos desarrolladores adoraron el comportamiento “implacablemente proactivo”; otros vieron desperdicio, quema de tokens y demasiada maquinaria autónoma para un arreglo pequeño (Hacker News).
Lo Que el Debate de la Comunidad Acierta
La mejor discusión entre desarrolladores no es “Claude bueno” contra “OpenAI bueno”. Es sobre control.
El artículo de Simon Willison del 11 de junio es la pieza más clara. Le dio a Claude Fable 5 una captura de pantalla y un prompt de una línea sobre un bug de scrollbar. El modelo construyó páginas locales de reproducción, abrió navegadores reales, usó IDs de ventana de macOS mediante Quartz, capturó pantallas, inyectó JavaScript, levantó un pequeño servidor CORS, midió el shadow DOM y luego cedió el trabajo a Opus tras topar con una barrera (Simon Willison). Su rastreador de costes estimó que la sesión habría costado unos $12.11 a precio completo.
El hilo de HN bajo ese post es útil porque rechaza el consenso falso. Un bando dice que esto es exactamente lo que debería ser la programación agentiva: usar herramientas, verificar contra la realidad, producir artefactos. El otro dice que quemar dólares y acceso a shell para arreglar un scrollbar CSS es la abstracción equivocada, especialmente cuando el agente opera fuera de un sandbox estricto (Hacker News).
Reddit es menos ordenado, pero captura el dolor operativo. En r/ClaudeCode, los desarrolladores ya están intentando destilar el comportamiento tipo Fable en archivos de instrucciones para Opus 4.8, compartiendo prompts Fable5.md, ideas con --append-system-prompt-file y recetas para “hacer Opus más proactivo” (Reddit). En r/cybersecurity y r/LocalLLaMA, el debate se desplaza al riesgo de plataforma: si un modelo frontier alojado puede ser retirado de la noche a la mañana, ¿deberían los equipos serios apoyarse más en modelos locales, enrutamiento multi-proveedor o fallbacks alojados de menor nivel (Reddit, Reddit).
La respuesta práctica que falta en muchos hilos: no intentes salir del riesgo de proveedor a base de “prompting”. Los prompts pueden hacer que Opus se comporte más como Fable. No pueden hacer disponible un modelo que no está disponible.
Usa Opus 4.8 Cuando Quieras Continuidad con Claude
Elige Claude Opus 4.8 cuando tu sistema ya depende del estilo de uso de herramientas de Claude, su comportamiento de contexto largo, Claude Code, la semántica de Anthropic Messages API o el prompt caching.
Opus 4.8 es el fallback menos disruptivo. La propia página de Opus de Anthropic dice que el modelo está disponible como claude-opus-4-8, empieza en $5/M de entrada y $25/M de salida, admite ahorros de prompt caching de hasta 90% y admite ahorros de 50% con procesamiento por lotes (Anthropic). Si construiste alrededor del formato de mensajes de Claude, prompts de sistema, llamadas a herramientas o convenciones CLAUDE.md, quedarte dentro de la familia Claude reduce el riesgo de migración.
Úsalo para:
- Revisión de bases de código grandes donde el modelo necesita mantener muchos archivos y convenciones.
- Flujos agentivos que se benefician de la planificación cautelosa y la autoverificación de Claude.
- Equipos que ya usan Claude Code y quieren un fallback de baja fricción para Fable 5.
- Trabajos cargados de salida donde el precio de salida de $30/M de GPT-5.5 empieza a importar.
- Flujos que pueden aprovechar prompt caching.
La debilidad es la claridad de benchmarks. La página de GPT-5.5 de OpenAI da muchos números de benchmarks legibles en texto. La página de Opus 4.8 de Anthropic da posicionamiento, precios, contexto, citas de partners y una sección de benchmarks basada en imagen, pero menos comparaciones numéricas fácilmente auditables en el texto de la página. Si tu proceso de compras necesita una tabla de puntuaciones de benchmarks con nombre, GPT-5.5 es más fácil de defender.
Aun así, si la pregunta es “¿A qué debería llamar ahora mi agente Claude, ya que Fable se fue?”, empieza con Opus 4.8.
Usa GPT-5.5 Cuando Quieras Evidencia y Encaje con OpenAI
Elige GPT-5.5 cuando quieras un modelo de programación sólido con números públicos de benchmarks, compatibilidad con OpenAI API o integración con Codex.
OpenAI dice que GPT-5.5 tiene un precio de $5/M de entrada y $30/M de salida para desarrolladores de API, con una ventana de contexto de 1M de tokens (OpenAI). Sus números publicados de programación y herramientas son fuertes: 82.7% en Terminal-Bench 2.0, 58.6% en SWE-Bench Pro Public, 75.3% en MCP Atlas y 81.8% en CyberGym (OpenAI). OpenAI también clasifica las capacidades cibernéticas y bio/químicas de GPT-5.5 como High bajo su Preparedness Framework, aunque dice que no alcanzó el nivel Critical en capacidad de ciberseguridad (OpenAI).
Úsalo para:
- Tareas de programación intensivas en terminal donde el rendimiento tipo Terminal-Bench se parece a tu carga de trabajo.
- Contrastar planes de Claude, especialmente cambios sensibles en seguridad o migraciones pesadas.
- Equipos ya estandarizados en OpenAI Responses o Chat Completions.
- Routers de agentes donde GPT-5.5 actúa como revisor, crítico o verificador de segunda pasada.
- Casos donde las evaluaciones numéricas públicas importan más que la continuidad del flujo Claude.
La desventaja es el coste en ejecuciones con mucha salida. GPT-5.5 no es dramáticamente más caro, pero los bucles de agentes producen salida. Si tu agente escribe planes largos, diffs largos, logs de tests largos y postmortems largos, esos $5/M extra de salida aparecen en la factura.
La Mejor Arquitectura: Enruta, No Reces
Esta es la guía de selección que yo pondría en producción:
- Usa Opus 4.8 por defecto para agentes de programación Claude-nativos.
- Enruta a GPT-5.5 para revisión independiente, tareas intensivas en terminal y stacks nativos de OpenAI.
- Mantén lista una ruta a Fable 5, pero no bloquees producción por ella.
- Añade topes de presupuesto, sandboxing y políticas de modelo por tarea.
- Registra modelo, proveedor, mezcla de tokens, motivo de fallback y aprobación humana final.
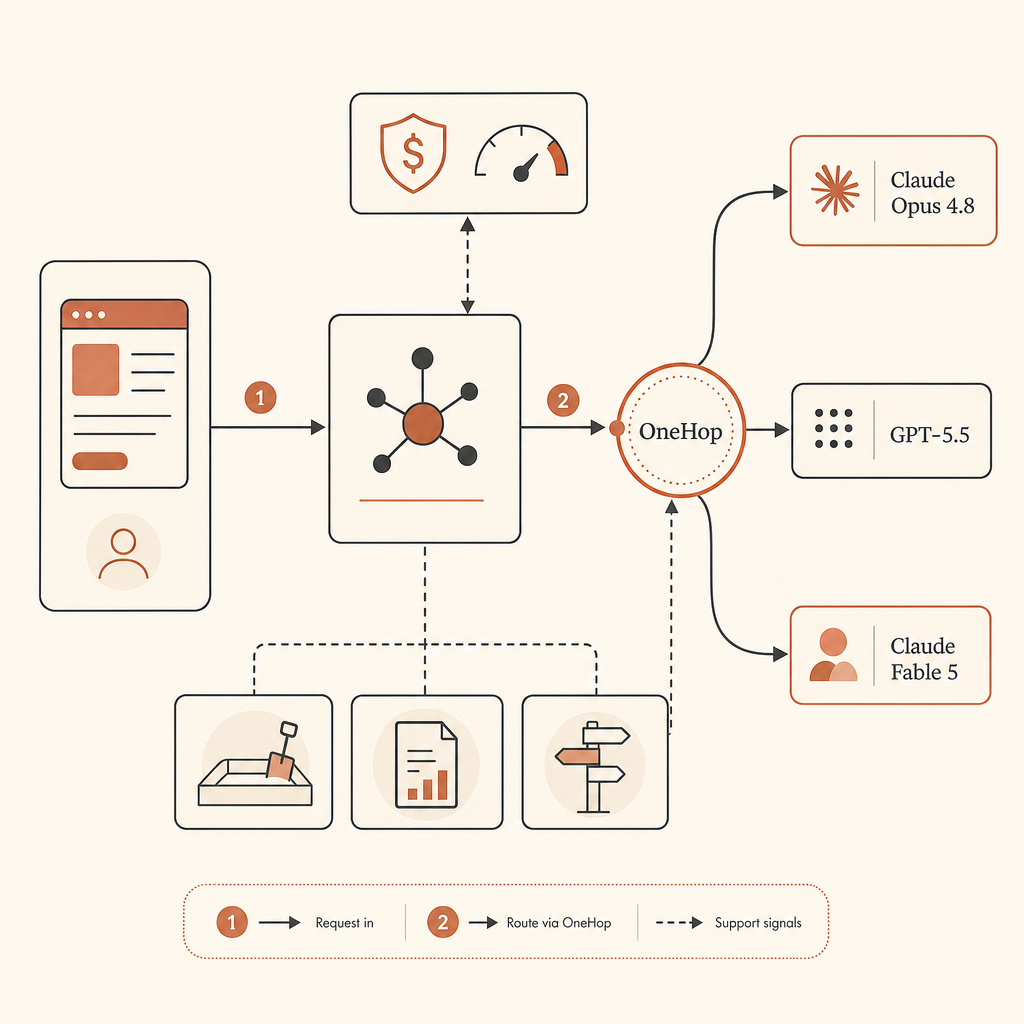
Un router de proveedores no tiene que ser sofisticado. Empieza con un archivo de políticas:
routes:
default_coding: claude-opus-4-8
critical_review: gpt-5.5
long_context_refactor: claude-opus-4-8
security_review: gpt-5.5
limits:
max_usd_per_task: 8
require_approval_over_usd: 3Luego aplícalo antes de la llamada al modelo. El objetivo no es perseguir un enrutamiento automático perfecto. El objetivo es evitar hard-codear la continuidad del negocio a un solo ID de modelo.
Si todavía quieres Fable 5 cuando haya acceso disponible, OneHop es la ruta de menor fricción para mantener en tu tabla de enrutamiento. OneHop lista Claude Fable 5 como anthropic/claude-fable-5, muestra el precio oficial de lista de $10/M de entrada y $50/M de salida, y anuncia precios con descuento más $10 de crédito gratis para cuentas nuevas sin tarjeta requerida (OneHop). El patrón natural es mantener estable la abstracción de proveedor de tu app y cambiar la base URL.
Para clientes compatibles con OpenAI:
from openai import OpenAI
client = OpenAI(
base_url="https://api.onehop.ai/v1",
api_key="ONEHOP_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-fable-5",
messages=[
{"role": "user", "content": "Review this migration plan for hidden failure modes."}
],
)
print(response.choices[0].message.content)Cuando quieras específicamente la ruta Fable, usa Claude Fable 5 en OneHop. Si estás probando enrutamiento de proveedores desde cero, empieza con $10 gratis.
La recomendación final es intencionalmente aburrida. Si Fable 5 no está disponible, no pases la semana discutiendo si Opus 4.8 o GPT-5.5 tiene mejor personalidad. Pon Opus 4.8 en el slot de fallback de Claude. Pon GPT-5.5 en el slot de revisor y nativo de OpenAI. Mantén Fable 5 como opción enrutada a través de OneHop cuando esté disponible. Luego mide tus propias tareas: tasa de éxito, ediciones humanas, tiempo real transcurrido, coste de tokens y número de rollbacks.
Ese es el movimiento adulto. Los debates de fans de modelos son divertidos. Los agentes en producción necesitan un plan de salida.

