Le 12 juin a fait basculer la discussion sur le routage de “Quel modèle frontier est le meilleur ?” à “Que se passe-t-il quand le modèle que vous aviez choisi disparaît ?”
Anthropic affirme avoir reçu une directive du gouvernement américain à 17 h 21 ET le 12 juin 2026, imposant la suspension de l’accès à Fable 5 et Mythos 5 pour les ressortissants étrangers. Sa réponse pratique a été brutale : désactiver les deux modèles pour tous les clients, tout en gardant les autres modèles Anthropic disponibles (Anthropic). Le même billet indique qu’Anthropic a examiné la base du jailbreak signalé et a conclu que la capacité démontrée était “largement disponible” dans d’autres modèles publics, en citant explicitement GPT-5.5 d’OpenAI (Anthropic).
La question pour les développeurs devient donc inhabituellement concrète. Si Fable 5 a disparu de votre stack aujourd’hui, est-ce que vous routez vers Claude Opus 4.8, vous basculez sur GPT-5.5, ou vous construisez un routeur de fournisseurs et vous arrêtez de faire dépendre votre agent d’un seul endpoint ?
Ma réponse : utilisez Opus 4.8 comme fallback Claude-native par défaut pour les workflows existants Claude Code et Anthropic API, utilisez GPT-5.5 quand vous voulez des preuves plus solides côté coding façon terminal-bench ou une meilleure intégration à l’écosystème OpenAI, et ajoutez du routage si la charge de travail compte vraiment. Si une panne d’un seul modèle peut arrêter votre agent, le bug est dans votre architecture.
Ce Qui Est Vraiment Tombé Hors Ligne
Anthropic n’a pas dit “Claude est en panne.” Elle a dit que Fable 5 et Mythos 5 avaient été désactivés pour tous les clients, tandis que “tous les autres modèles Anthropic” restent disponibles (Anthropic). Cette nuance compte.
Fable 5 était le modèle public de classe Mythos. Mythos 5 était la version plus restreinte. Opus 4.8 reste actif, et Anthropic le présente comme un “modèle de raisonnement hybride conçu pour le codage sérieux et les agents IA”, avec une fenêtre de contexte de 1M de tokens (Anthropic).
Le désaccord n’est pas non plus qu’un théâtre politique. La déclaration du 12 juin d’Anthropic dit que l’inquiétude du gouvernement portait sur un jailbreak étroit utilisé pour trouver un petit nombre de vulnérabilités mineures déjà connues, et Anthropic soutient que d’autres modèles publics peuvent découvrir la même classe de problèmes sans contournement (Anthropic). C’est pour cela que GPT-5.5 est pertinent ici. Anthropic l’a nommé comme comparable pour la classe de capacités contestée.
Pour les développeurs, le fait clé est plus simple : votre agent en production se moque de la raison pour laquelle l’accès a disparu. Il ne voit que des appels qui échouent, des ID de modèles manquants, des workflows dégradés, et des utilisateurs qui demandent pourquoi l’outil d’hier ne marche plus.
Tableau des Capacités et des Prix
Voici la comparaison lucide. Pas de soupe de benchmarks inventée, pas de vibes déguisées en données.
| Model | Rôle actuel | Prix input | Prix output | Contexte | Signaux de capacité vérifiés utiles |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Meilleur fallback Anthropic quand Fable 5 est indisponible | $5 / 1M tokens | $25 / 1M tokens | 1M tokens | Anthropic dit qu’il est conçu pour le codage sérieux, les agents et les tâches longues ; disponible dans Claude API, AWS, Google Cloud et Microsoft Foundry (Anthropic) |
| GPT-5.5 | Alternative OpenAI solide pour les agents de codage | $5 / 1M tokens | $30 / 1M tokens | 1M tokens dans API | OpenAI annonce 58,6 % sur SWE-Bench Pro Public, 82,7 % sur Terminal-Bench 2.0, 81,8 % sur CyberGym et 45,4 % sur Graphwalks BFS 1M F1 (OpenAI) |
| Claude Fable 5 | Chemin Claude haut de gamme préféré, actuellement indisponible via Anthropic | Prix catalogue $10 / 1M tokens | Prix catalogue $50 / 1M tokens | 1M tokens | Désactivé par Anthropic pour tous les clients après la directive du 12 juin (Anthropic) |
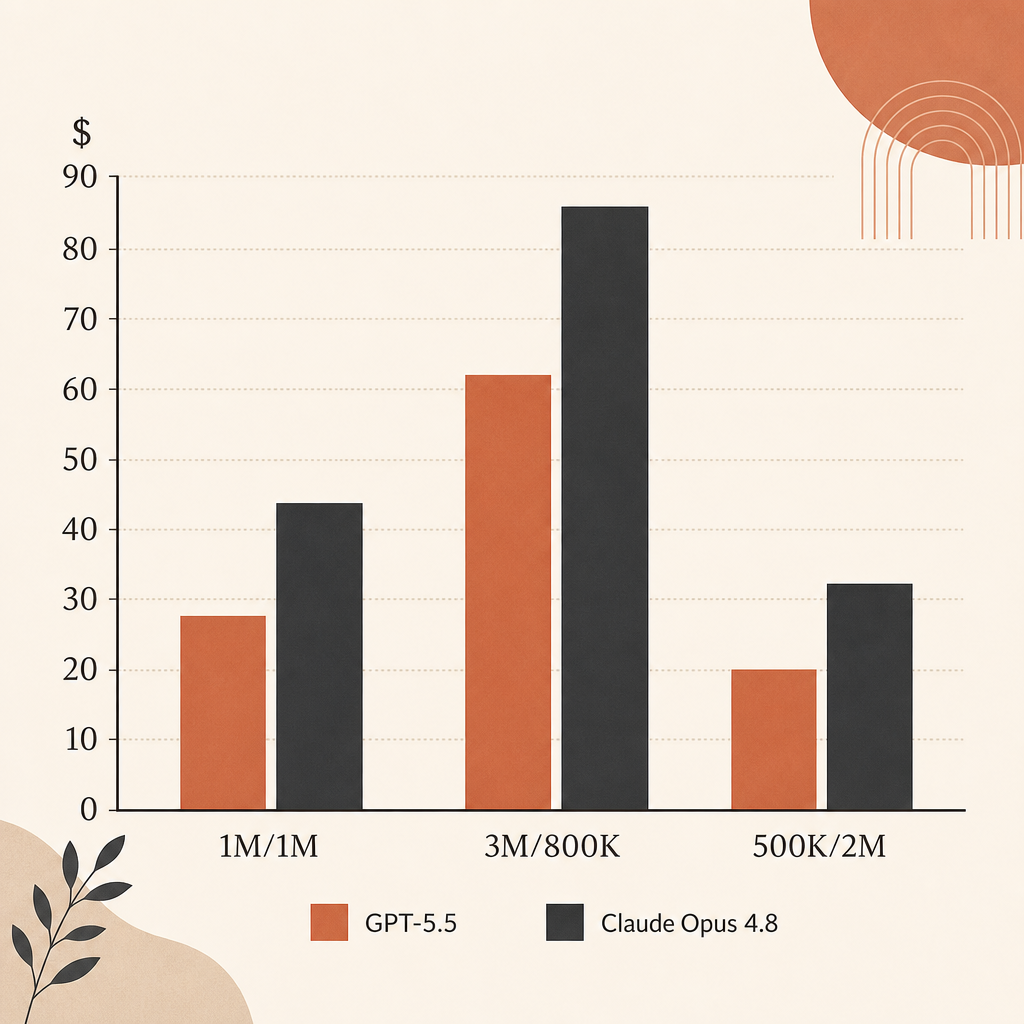
Au prix catalogue brut, Opus 4.8 est moins cher que GPT-5.5 pour les runs d’agents lourds en output. L’input est à égalité à $5/M. L’output est à $25/M pour Opus 4.8 et $30/M pour GPT-5.5.
Quelques factures réalistes d’agents :
| Charge de travail | Opus 4.8 | GPT-5.5 | Écart |
|---|---|---|---|
| 1M input, 1M output | $30 | $35 | GPT-5.5 coûte 16,7 % de plus |
| 3M input, 800K output | $35 | $39 | GPT-5.5 coûte 11,4 % de plus |
| 500K input, 2M output | $52.50 | $62.50 | GPT-5.5 coûte 19,0 % de plus |
Cela ne veut pas dire qu’Opus gagne toujours. Un modèle qui termine en un seul passage peut coûter moins cher qu’un modèle moins cher qui boucle, réessaie, ou écrit cinq pages de plan avant de toucher au repo. Le fil HN autour du billet de Simon Willison sur le débogage avec Fable 5 est rempli exactement de cette fracture : certains développeurs ont adoré le comportement “implacablement proactif”, d’autres y ont vu du gaspillage, de la consommation de tokens et trop de mécanique autonome pour un petit correctif (Hacker News).
Ce Que le Débat Communautaire Comprend Bien
La meilleure discussion entre développeurs n’est pas “Claude bien” contre “OpenAI bien.” Elle parle de contrôle.
Le billet de Simon Willison du 11 juin est la pièce la plus claire du dossier. Il a donné à Claude Fable 5 une capture d’écran et un prompt d’une ligne sur un bug de barre de défilement. Le modèle a construit des pages de reproduction locales, ouvert de vrais navigateurs, utilisé des ID de fenêtres macOS via Quartz, capturé des captures d’écran, injecté du JavaScript, lancé un petit serveur CORS, mesuré le shadow DOM, puis transmis à Opus après avoir atteint un garde-fou (Simon Willison). Son outil de suivi des coûts estimait que la session aurait coûté environ $12.11 au plein tarif.
Le fil HN sous ce billet est utile parce qu’il refuse le faux consensus. Un camp dit que c’est exactement ce que le codage agentique devrait être : utiliser des outils, vérifier contre la réalité, produire des artefacts. L’autre camp dit que brûler des dollars et donner un accès shell pour corriger une barre de défilement CSS est la mauvaise abstraction, surtout quand l’agent opère hors d’un sandbox strict (Hacker News).
Reddit est moins propre, mais il capture la douleur opérationnelle. Dans r/ClaudeCode, des développeurs essaient déjà de distiller un comportement à la Fable dans des fichiers d’instructions pour Opus 4.8, en partageant des prompts Fable5.md, des idées --append-system-prompt-file, et des recettes pour “rendre Opus plus proactif” (Reddit). Dans r/cybersecurity et r/LocalLLaMA, le débat glisse vers le risque de plateforme : si un modèle frontier hébergé peut être retiré du jour au lendemain, les équipes sérieuses devraient-elles davantage miser sur les modèles locaux, le routage multi-fournisseurs ou des fallbacks hébergés de rang inférieur (Reddit, Reddit).
La réponse pratique qui manque dans beaucoup de fils : n’essayez pas de vous sortir du risque fournisseur à coups de “prompt”. Les prompts peuvent faire se comporter Opus davantage comme Fable. Ils ne peuvent pas rendre disponible un modèle indisponible.
Utilisez Opus 4.8 Quand Vous Voulez la Continuité Claude
Choisissez Claude Opus 4.8 quand votre système dépend déjà du style d’utilisation d’outils de Claude, de son comportement en long contexte, de Claude Code, de la sémantique Anthropic Messages API ou du prompt caching.
Opus 4.8 est le fallback le moins disruptif. La propre page Opus d’Anthropic indique que le modèle est disponible sous claude-opus-4-8, commence à $5/M en input et $25/M en output, prend en charge des économies de prompt caching jusqu’à 90 %, et permet 50 % d’économies via le traitement batch (Anthropic). Si vous avez construit autour du format de messages de Claude, des prompts système, des appels d’outils ou des conventions CLAUDE.md, rester dans la famille Claude réduit le risque de migration.
Utilisez-le pour :
- La revue de grands codebases où le modèle doit garder en tête de nombreux fichiers et conventions.
- Les workflows agentiques qui bénéficient de la planification prudente et de l’auto-vérification de Claude.
- Les équipes qui utilisent déjà Claude Code et veulent un fallback Fable 5 à faible friction.
- Les jobs lourds en output où le prix de sortie de GPT-5.5 à $30/M commence à compter.
- Les workflows qui peuvent exploiter le prompt caching.
La faiblesse, c’est la clarté des benchmarks. La page GPT-5.5 d’OpenAI donne beaucoup de chiffres de benchmarks lisibles dans le texte. La page Opus 4.8 d’Anthropic donne du positionnement, des prix, du contexte, des citations de partenaires et une section benchmark sous forme d’image, mais moins de comparaisons numériques facilement auditables dans le texte de la page. Si votre processus d’achat exige un tableau de scores nommés, GPT-5.5 est plus facile à défendre.
Reste que si la question est “Que doit appeler mon agent Claude maintenant que Fable a disparu ?”, commencez par Opus 4.8.
Utilisez GPT-5.5 Quand Vous Voulez des Preuves et l’Écosystème OpenAI
Choisissez GPT-5.5 quand vous voulez un modèle de codage solide avec des chiffres de benchmarks publics, une compatibilité OpenAI API ou une intégration Codex.
OpenAI indique que GPT-5.5 est facturé $5/M en input et $30/M en output pour les développeurs API, avec une fenêtre de contexte de 1M de tokens (OpenAI). Ses chiffres publiés en codage et usage d’outils sont solides : 82,7 % sur Terminal-Bench 2.0, 58,6 % sur SWE-Bench Pro Public, 75,3 % sur MCP Atlas et 81,8 % sur CyberGym (OpenAI). OpenAI classe aussi les capacités cyber et bio/chimiques de GPT-5.5 comme High dans son Preparedness Framework, tout en disant qu’il n’a pas atteint le niveau Critical en cybersécurité (OpenAI).
Utilisez-le pour :
- Les tâches de codage très orientées terminal, quand les performances de type Terminal-Bench correspondent à votre charge de travail.
- Le contre-examen des plans Claude, surtout pour les changements sensibles côté sécurité ou lourds en migration.
- Les équipes déjà standardisées sur OpenAI Responses ou Chat Completions.
- Les routeurs d’agents où GPT-5.5 joue le rôle de relecteur, critique ou vérificateur de second passage.
- Les cas où les évaluations numériques publiques comptent davantage que la continuité du workflow Claude.
L’inconvénient, c’est le coût sur les runs lourds en output. GPT-5.5 n’est pas dramatiquement plus cher, mais les boucles d’agents produisent de l’output. Si votre agent écrit de longs plans, de longs diffs, de longs logs de tests et de longs postmortems, l’écart de $5/M en output finit par se voir.
La Meilleure Architecture : Routez, Ne Priez Pas
Voici le guide de sélection que je mettrais vraiment en production :
- Par défaut, utilisez Opus 4.8 pour les agents de codage Claude-native.
- Routez vers GPT-5.5 pour les revues indépendantes, les tâches très terminal, et les stacks OpenAI-native.
- Gardez un chemin Fable 5 prêt, mais ne bloquez pas la production dessus.
- Ajoutez des plafonds budgétaires, du sandboxing et des politiques de modèle par tâche.
- Loggez le modèle, le fournisseur, le mix de tokens, la raison du fallback et l’approbation humaine finale.
Un routeur de fournisseurs n’a pas besoin d’être sophistiqué. Commencez par un fichier de politique :
routes:
default_coding: claude-opus-4-8
critical_review: gpt-5.5
long_context_refactor: claude-opus-4-8
security_review: gpt-5.5
limits:
max_usd_per_task: 8
require_approval_over_usd: 3Ensuite, appliquez-le avant l’appel au modèle. Le but n’est pas de courir après un routage automatique parfait. Le but est d’éviter de coder en dur votre continuité métier sur un seul ID de modèle.
Si vous voulez encore Fable 5 quand l’accès est disponible, OneHop est le chemin à plus faible friction à garder dans votre table de routage. OneHop liste Claude Fable 5 sous anthropic/claude-fable-5, affiche le prix catalogue officiel de $10/M en input et $50/M en output, et met en avant une tarification réduite ainsi que $10 de crédit gratuit pour les nouveaux comptes, sans carte requise (OneHop). Le schéma naturel consiste à garder stable l’abstraction fournisseur de votre app et à remplacer la base URL.
Pour les clients compatibles OpenAI :
from openai import OpenAI
client = OpenAI(
base_url="https://api.onehop.ai/v1",
api_key="ONEHOP_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-fable-5",
messages=[
{"role": "user", "content": "Review this migration plan for hidden failure modes."}
],
)
print(response.choices[0].message.content)Quand vous voulez précisément la route Fable, utilisez Claude Fable 5 sur OneHop. Si vous testez le routage fournisseur à partir de zéro, commencez avec $10 gratuits.
La recommandation finale est volontairement ennuyeuse. Si Fable 5 est indisponible, ne passez pas la semaine à débattre pour savoir si Opus 4.8 ou GPT-5.5 a la meilleure personnalité. Mettez Opus 4.8 dans le slot de fallback Claude. Mettez GPT-5.5 dans le slot de revue et OpenAI-native. Gardez Fable 5 comme option routée via OneHop quand elle est disponible. Puis mesurez vos propres tâches : taux de réussite, modifications humaines, temps écoulé, coût en tokens et nombre de rollbacks.
C’est le geste adulte. Les débats de fans de modèles sont amusants. Les agents en production ont besoin d’un plan de sortie.

