12 июня разговор о маршрутизации сменился с «Какая frontier-модель лучшая?» на «Что происходит, когда выбранная вами модель исчезает?»
Anthropic говорит, что 12 июня 2026 года в 17:21 по восточному времени получила распоряжение правительства США, требующее приостановить доступ к Fable 5 и Mythos 5 для иностранных граждан. Практический ответ был прямолинейным: отключить обе модели для всех клиентов, оставив доступными другие модели Anthropic (Anthropic). В том же посте Anthropic пишет, что проверила заявленную основу jailbreak и обнаружила, что продемонстрированная возможность «широко доступна» в других публичных моделях, прямо назвав GPT-5.5 от OpenAI (Anthropic).
Из-за этого вопрос для разработчиков стал необычно конкретным. Если Fable 5 сегодня выпал из вашего стека, вы маршрутизируете запросы в Claude Opus 4.8, переходите на GPT-5.5 или строите роутер провайдеров и перестаёте ставить своего агента на один endpoint?
Мой ответ: используйте Opus 4.8 как fallback по умолчанию для существующих Claude Code и Anthropic API workflow, используйте GPT-5.5, когда вам нужны более сильные доказательства в духе terminal-bench для coding-задач или лучшее попадание в экосистему OpenAI, и добавляйте маршрутизацию, если workload важен. Если outage одной модели может остановить вашего агента, баг в вашей архитектуре.
Что На Самом Деле Ушло Offline
Anthropic не сказала: «Claude не работает». Она сказала, что Fable 5 и Mythos 5 отключены для всех клиентов, а «все остальные модели Anthropic» остаются доступными (Anthropic). Это важное различие.
Fable 5 была публичной моделью класса Mythos. Mythos 5 была более ограниченной версией. Opus 4.8 остаётся live, и Anthropic позиционирует её как «hybrid reasoning model built for serious coding and AI agents» с контекстным окном в 1M токенов (Anthropic).
Спор здесь тоже не просто политический театр. В заявлении Anthropic от 12 июня сказано, что обеспокоенность правительства была связана с узким jailbreak, использованным для поиска небольшого числа уже известных minor vulnerabilities, а Anthropic утверждает, что другие публичные модели могут находить тот же класс проблем без bypass (Anthropic). Именно поэтому GPT-5.5 здесь релевантен. Anthropic назвала его сопоставимым для спорного класса возможностей.
Для разработчиков ключевой факт проще: вашему production-агенту всё равно, почему доступ исчез. Он видит только failed calls, отсутствующие model IDs, деградировавшие workflow и пользователей, которые спрашивают, почему вчерашний инструмент больше не работает.
Таблица Возможностей И Цен
Вот трезвое сравнение. Без выдуманного benchmark-супа, без вайбов, притворяющихся данными.
| Модель | Текущая роль | Цена input | Цена output | Контекст | Полезные проверенные сигналы возможностей |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Лучший fallback Anthropic, когда Fable 5 недоступен | $5 / 1M токенов | $25 / 1M токенов | 1M токенов | Anthropic говорит, что модель создана для серьёзного coding, агентов и долгих задач; доступна в Claude API, AWS, Google Cloud и Microsoft Foundry (Anthropic) |
| GPT-5.5 | Сильная альтернатива OpenAI для coding-агентов | $5 / 1M токенов | $30 / 1M токенов | 1M токенов в API | OpenAI сообщает 58.6% на SWE-Bench Pro Public, 82.7% на Terminal-Bench 2.0, 81.8% на CyberGym и 45.4% на Graphwalks BFS 1M F1 (OpenAI) |
| Claude Fable 5 | Предпочтительный top-end путь Claude, сейчас недоступен через Anthropic | $10 / 1M токенов по прайсу | $50 / 1M токенов по прайсу | 1M токенов | Отключена Anthropic для всех клиентов после распоряжения от 12 июня (Anthropic) |
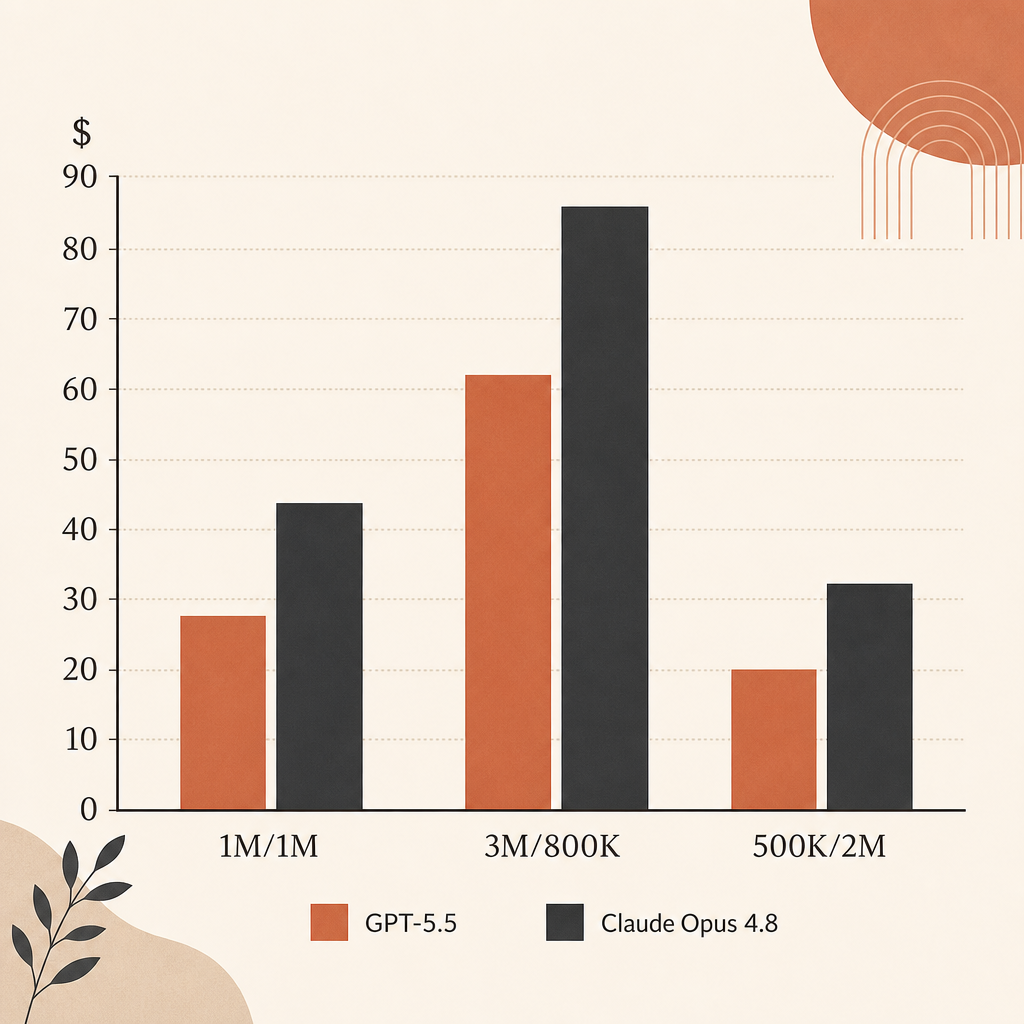
По голому list price Opus 4.8 дешевле GPT-5.5 для agent runs с большим output. Input одинаковый: $5/M. Output — $25/M у Opus 4.8 и $30/M у GPT-5.5.
Несколько реалистичных счетов для агентов:
| Workload | Opus 4.8 | GPT-5.5 | Разница |
|---|---|---|---|
| 1M input, 1M output | $30 | $35 | GPT-5.5 стоит на 16.7% дороже |
| 3M input, 800K output | $35 | $39 | GPT-5.5 стоит на 11.4% дороже |
| 500K input, 2M output | $52.50 | $62.50 | GPT-5.5 стоит на 19.0% дороже |
Это не значит, что Opus всегда выигрывает. Модель, которая завершает задачу за один проход, может оказаться дешевле, чем более дешёвая модель, которая зацикливается, делает retries или пишет пять страниц плана перед тем, как тронуть repo. Тред на HN вокруг поста Simon Willison о debugging с Fable 5 полон именно такого раскола: одни разработчики обожали «relentlessly proactive» поведение, другие видели waste, token burn и слишком много автономной машинерии ради маленького fix (Hacker News).
В Чём Прав Community-Дебаты
Лучшее обсуждение среди разработчиков — не «Claude хорош» против «OpenAI хорош». Оно про контроль.
Разбор Simon Willison от 11 июня — самый ясный артефакт. Он дал Claude Fable 5 screenshot и one-line prompt про баг со scrollbar. Модель построила локальные repro-страницы, открыла реальные браузеры, использовала macOS window IDs через Quartz, сделала screenshots, injected JavaScript, подняла крошечный CORS-сервер, измерила shadow DOM, а затем передала задачу Opus после guardrail (Simon Willison). Его cost tracker оценил, что сессия стоила бы около $12.11 по полной цене.
Тред HN под этим постом полезен, потому что отвергает фальшивый консенсус. Один лагерь говорит: именно таким и должен быть agentic coding — использовать tools, проверять реальность, производить artifacts. Другой лагерь говорит: сжигать доллары и shell access ради исправления CSS scrollbar — неправильная абстракция, особенно когда агент работает вне жёсткого sandbox (Hacker News).
Reddit менее аккуратен, но хорошо передаёт операционную боль. В r/ClaudeCode разработчики уже пытаются дистиллировать Fable-подобное поведение в instruction files для Opus 4.8, делятся Fable5.md prompts, идеями --append-system-prompt-file и рецептами «сделать Opus более proactive» (Reddit). В r/cybersecurity и r/LocalLLaMA спор смещается к platform risk: если hosted frontier-модель можно убрать overnight, должны ли серьёзные команды сильнее полагаться на local models, multi-provider routing или lower-tier hosted fallbacks (Reddit, Reddit).
Практический ответ, которого не хватает во многих тредах: не пытайтесь «запромптить» выход из provider risk. Prompts могут заставить Opus вести себя больше как Fable. Они не могут сделать недоступную модель доступной.
Используйте Opus 4.8, Когда Нужна Claude-Непрерывность
Выбирайте Claude Opus 4.8, когда ваша система уже зависит от Claude’s tool-use style, long-context behavior, Claude Code, семантики Anthropic Messages API или prompt caching.
Opus 4.8 — наименее разрушительный fallback. Собственная страница Opus от Anthropic говорит, что модель доступна как claude-opus-4-8, стартует с $5/M input и $25/M output, поддерживает экономию на prompt caching до 90% и экономию на batch processing в 50% (Anthropic). Если вы строили вокруг Claude’s message format, system prompts, tool calls или конвенций CLAUDE.md, оставаться внутри семейства Claude — значит снизить migration risk.
Используйте её для:
- Ревью больших codebase, где модели нужно держать в голове много файлов и conventions.
- Agentic workflows, которым полезны осторожное planning и self-checking Claude.
- Команд, уже использующих Claude Code и желающих low-friction fallback для Fable 5.
- Output-heavy задач, где цена GPT-5.5 в $30/M за output начинает иметь значение.
- Workflow, которые могут использовать prompt caching.
Слабое место — ясность benchmarks. Страница OpenAI по GPT-5.5 даёт много чисел benchmarks, читаемых как текст. Страница Anthropic по Opus 4.8 даёт positioning, pricing, context, partner quotes и image-based benchmark section, но меньше легко проверяемых числовых сравнений в тексте страницы. Если вашему procurement-процессу нужна таблица named benchmark scores, GPT-5.5 проще защищать.
Но если вопрос звучит как «Куда теперь должен звонить мой Claude-агент, раз Fable пропал?», начните с Opus 4.8.
Используйте GPT-5.5, Когда Нужны Evidence И OpenAI Fit
Выбирайте GPT-5.5, когда вам нужна сильная coding-модель с публичными benchmark numbers, совместимостью с OpenAI API или интеграцией Codex.
OpenAI говорит, что GPT-5.5 для API developers стоит $5/M input и $30/M output, с контекстным окном 1M токенов (OpenAI). Опубликованные coding и tool numbers сильные: 82.7% на Terminal-Bench 2.0, 58.6% на SWE-Bench Pro Public, 75.3% на MCP Atlas и 81.8% на CyberGym (OpenAI). OpenAI также классифицирует cyber и bio/chemical capabilities GPT-5.5 как High в рамках Preparedness Framework, при этом заявляя, что модель не достигла Critical cybersecurity capability level (OpenAI).
Используйте её для:
- Terminal-heavy coding задач, где performance в стиле Terminal-Bench хорошо ложится на ваш workload.
- Cross-checking планов Claude, особенно security-sensitive или migration-heavy изменений.
- Команд, уже стандартизированных на OpenAI Responses или Chat Completions.
- Agent routers, где GPT-5.5 выступает reviewer, critic или second-pass verifier.
- Случаев, где публичные numeric evals важнее непрерывности Claude workflow.
Минус — стоимость output-heavy runs. GPT-5.5 не радикально дороже, но agent loops производят output. Если ваш агент пишет длинные планы, длинные diffs, длинные test logs и длинные postmortems, эта разница в $5/M за output становится заметной.
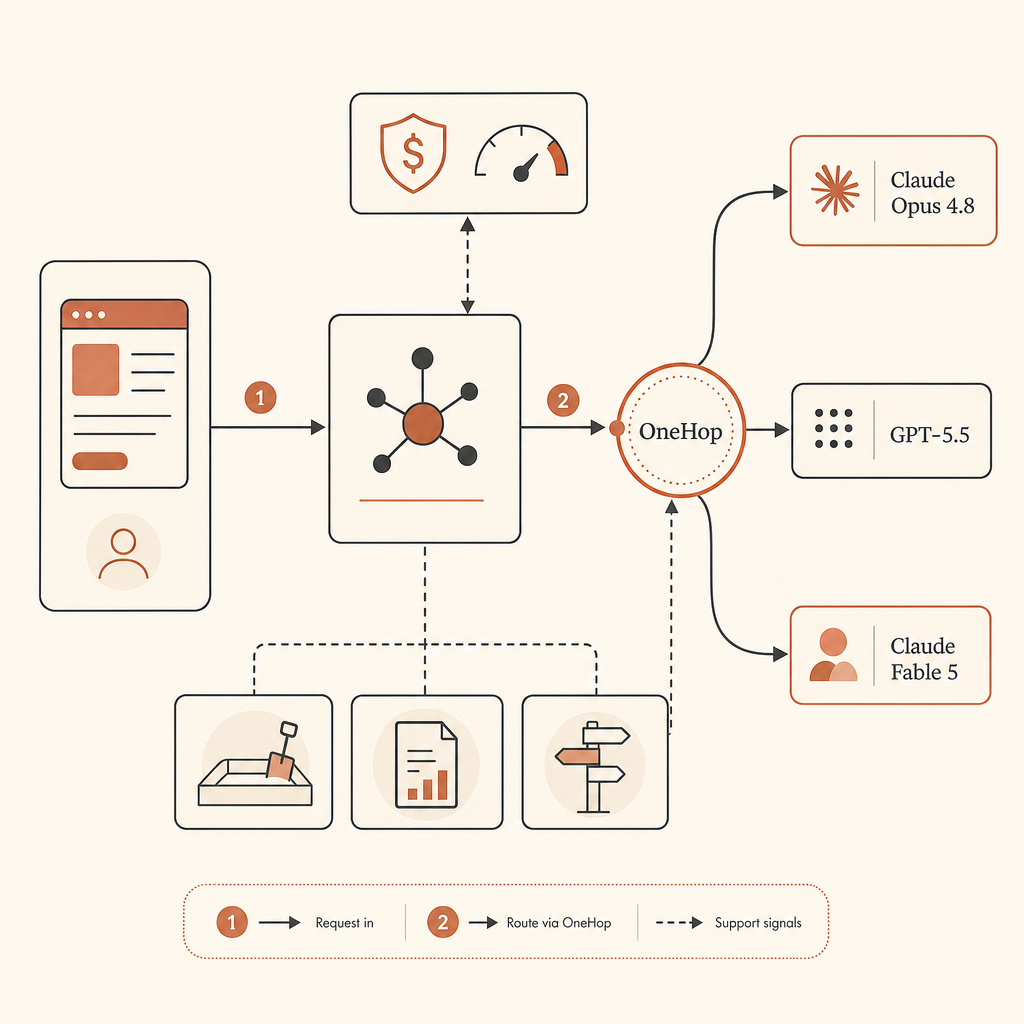
Лучшая Архитектура: Маршрутизируйте, А Не Молитесь
Вот selection guide, который я бы действительно отправил в production:
- По умолчанию используйте Opus 4.8 для Claude-native coding agents.
- Маршрутизируйте в GPT-5.5 для independent review, terminal-heavy tasks и OpenAI-native stacks.
- Держите путь к Fable 5 готовым, но не блокируйте на нём production.
- Добавьте budget caps, sandboxing и per-task model policies.
- Логируйте model, provider, token mix, fallback reason и финальное human approval.
Provider router не обязан быть сложным. Начните с policy file:
routes:
default_coding: claude-opus-4-8
critical_review: gpt-5.5
long_context_refactor: claude-opus-4-8
security_review: gpt-5.5
limits:
max_usd_per_task: 8
require_approval_over_usd: 3Затем enforce это перед model call. Смысл не в том, чтобы гнаться за идеальной автоматической маршрутизацией. Смысл в том, чтобы не hard-code business continuity на один model ID.
Если вы всё ещё хотите Fable 5, когда доступ есть, OneHop — самый low-friction путь, который стоит держать в routing table. OneHop указывает Claude Fable 5 как anthropic/claude-fable-5, показывает официальный list price $10/M input и $50/M output, а также рекламирует discounted pricing плюс $10 free credit для новых аккаунтов без карты (OneHop). Естественный паттерн — держать provider abstraction вашего приложения стабильной и менять base URL.
Для OpenAI-compatible clients:
from openai import OpenAI
client = OpenAI(
base_url="https://api.onehop.ai/v1",
api_key="ONEHOP_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-fable-5",
messages=[
{"role": "user", "content": "Review this migration plan for hidden failure modes."}
],
)
print(response.choices[0].message.content)Когда вам нужен именно Fable route, используйте Claude Fable 5 on OneHop. Если вы тестируете provider routing с нуля, начните с $10 free.
Финальная рекомендация намеренно скучная. Если Fable 5 недоступен, не тратьте неделю на споры, у кого личность лучше — у Opus 4.8 или GPT-5.5. Поставьте Opus 4.8 в слот Claude fallback. Поставьте GPT-5.5 в слот reviewer и OpenAI-native. Держите Fable 5 как routed option через OneHop, когда он доступен. Затем измеряйте собственные задачи: pass rate, human edits, wall-clock time, token cost и rollback count.
Это взрослый ход. Споры фанатов моделей — весёлое занятие. Production agents нужен exit plan.

