12 de junho mudou a conversa sobre roteamento de “Qual modelo de fronteira é o melhor?” para “O que acontece quando o modelo que você escolheu desaparece?”
Anthropic diz que recebeu uma diretriz do governo dos EUA às 17h21 ET em 12 de junho de 2026, exigindo a suspensão do acesso ao Fable 5 e ao Mythos 5 para estrangeiros. A resposta prática foi direta: desativar os dois modelos para todos os clientes, mantendo os outros modelos da Anthropic disponíveis (Anthropic). O mesmo post diz que a Anthropic revisou a base do jailbreak relatado e concluiu que a capacidade demonstrada era “amplamente disponível” em outros modelos públicos, citando explicitamente o GPT-5.5 da OpenAI (Anthropic).
Isso torna a pergunta para desenvolvedores incomumente concreta. Se o Fable 5 sumiu da sua stack hoje, você roteia para Claude Opus 4.8, muda para GPT-5.5 ou cria um roteador de provedores e para de apostar seu agente em um único endpoint?
Minha resposta: use Opus 4.8 como fallback padrão nativo de Claude para fluxos existentes com Claude Code e Anthropic API, use GPT-5.5 quando quiser evidência mais forte em coding no estilo terminal-bench ou melhor encaixe no ecossistema OpenAI, e adicione roteamento se a carga de trabalho importa. Se uma indisponibilidade de um único modelo consegue parar seu agente, o bug está na sua arquitetura.
O Que Realmente Saiu do Ar
Anthropic não disse “Claude caiu”. Disse que Fable 5 e Mythos 5 foram desativados para todos os clientes, enquanto “todos os outros modelos da Anthropic” continuam disponíveis (Anthropic). Essa distinção importa.
Fable 5 era o modelo público da classe Mythos. Mythos 5 era a versão mais restrita. Opus 4.8 continua no ar, e a Anthropic o posiciona como um “modelo de raciocínio híbrido criado para coding sério e agentes de AI”, com janela de contexto de 1M de tokens (Anthropic).
A disputa também não é só teatro de política pública. A declaração de 12 de junho da Anthropic diz que a preocupação do governo envolvia um jailbreak estreito usado para encontrar um pequeno número de vulnerabilidades menores já conhecidas, e a Anthropic argumenta que outros modelos públicos conseguem descobrir a mesma classe de problemas sem bypass (Anthropic). É por isso que GPT-5.5 é relevante aqui. A Anthropic o citou como comparável para a classe de capacidade em disputa.
Para desenvolvedores, o fato principal é mais simples: seu agente em produção não se importa por que o acesso desapareceu. Ele só vê chamadas falhando, IDs de modelo ausentes, fluxos degradados e usuários perguntando por que a ferramenta de ontem não funciona mais.
Tabela de Capacidade e Preço
Aqui vai a comparação sóbria. Sem sopa de benchmark inventada, sem feeling fingindo ser dado.
| Modelo | Papel atual | Preço de entrada | Preço de saída | Contexto | Sinais úteis de capacidade verificada |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Melhor fallback da Anthropic quando Fable 5 está indisponível | $5 / 1M tokens | $25 / 1M tokens | 1M tokens | Anthropic diz que ele foi criado para coding sério, agentes e tarefas longas; disponível em Claude API, AWS, Google Cloud e Microsoft Foundry (Anthropic) |
| GPT-5.5 | Alternativa forte da OpenAI para agentes de coding | $5 / 1M tokens | $30 / 1M tokens | 1M tokens na API | OpenAI relata 58,6% no SWE-Bench Pro Public, 82,7% no Terminal-Bench 2.0, 81,8% no CyberGym e 45,4% no Graphwalks BFS 1M F1 (OpenAI) |
| Claude Fable 5 | Caminho Claude preferido de ponta, atualmente indisponível via Anthropic | $10 / 1M tokens preço de tabela | $50 / 1M tokens preço de tabela | 1M tokens | Desativado pela Anthropic para todos os clientes após a diretriz de 12 de junho (Anthropic) |
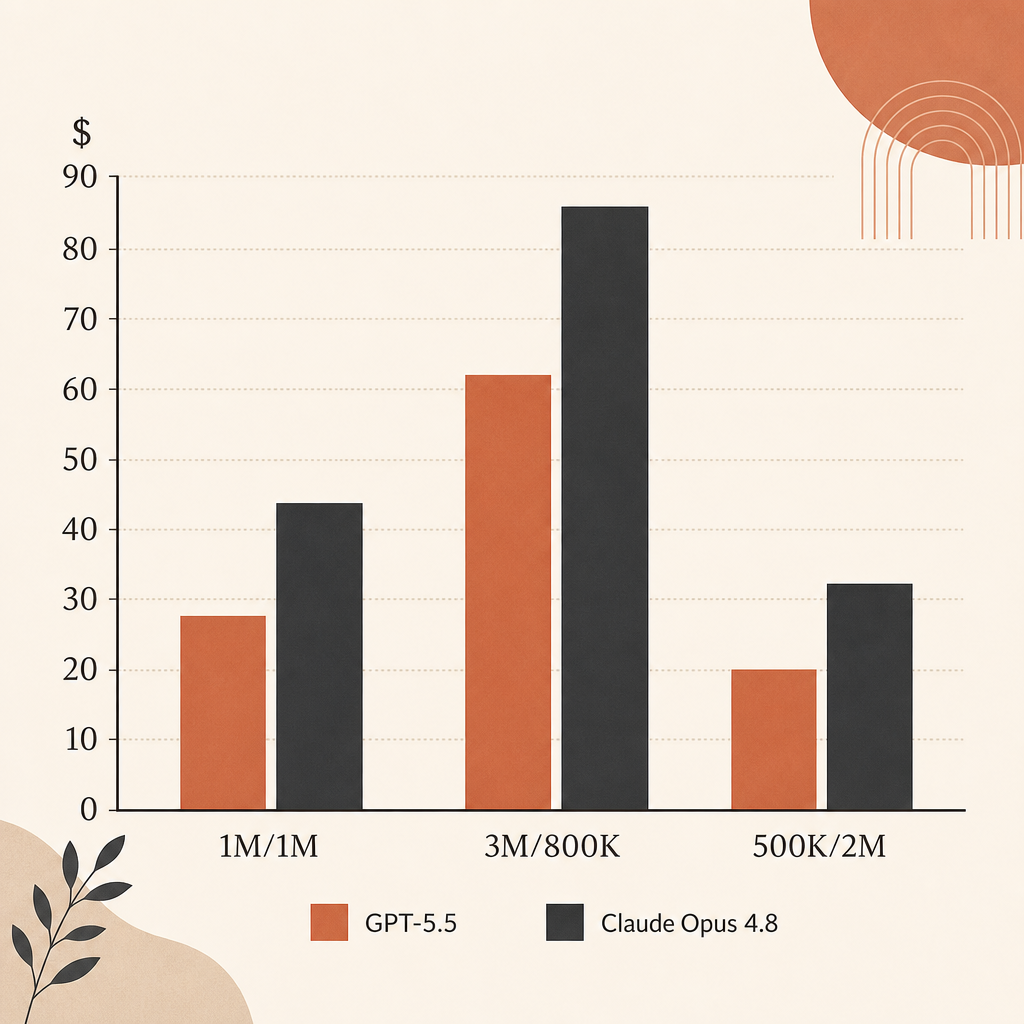
No preço de tabela bruto, Opus 4.8 é mais barato que GPT-5.5 em execuções de agente pesadas em saída. A entrada empata em $5/M. A saída é $25/M no Opus 4.8 e $30/M no GPT-5.5.
Algumas contas realistas de agentes:
| Carga de trabalho | Opus 4.8 | GPT-5.5 | Diferença |
|---|---|---|---|
| 1M entrada, 1M saída | $30 | $35 | GPT-5.5 custa 16,7% mais |
| 3M entrada, 800K saída | $35 | $39 | GPT-5.5 custa 11,4% mais |
| 500K entrada, 2M saída | $52.50 | $62.50 | GPT-5.5 custa 19,0% mais |
Isso não quer dizer que Opus sempre vença. Um modelo que resolve em uma passada pode sair mais barato que um modelo mais barato que entra em loop, tenta de novo ou escreve cinco páginas de plano antes de tocar no repo. A thread do HN sobre o post de debugging do Fable 5 do Simon Willison está cheia exatamente dessa divisão: alguns desenvolvedores adoraram o comportamento “incansavelmente proativo”, outros viram desperdício, queima de tokens e maquinário autônomo demais para uma correção pequena (Hacker News).
Onde o Debate da Comunidade Acerta
A melhor discussão entre desenvolvedores não é “Claude bom” versus “OpenAI bom”. É sobre controle.
O texto de 11 de junho do Simon Willison é o artefato mais claro. Ele deu ao Claude Fable 5 uma captura de tela e um prompt de uma linha sobre um bug de scrollbar. O modelo criou páginas locais de reprodução, abriu navegadores reais, usou IDs de janela do macOS via Quartz, capturou screenshots, injetou JavaScript, rodou um pequeno servidor CORS, mediu o shadow DOM e então passou a tarefa para Opus depois de bater em uma proteção (Simon Willison). O rastreador de custo dele estimou que a sessão teria custado cerca de $12.11 no preço cheio.
A thread do HN abaixo daquele post é útil porque rejeita o consenso falso. Um lado diz que isso é exatamente o que coding agentic deveria ser: usar ferramentas, verificar contra a realidade, produzir artefatos. O outro lado diz que queimar dólares e acesso ao shell para corrigir uma scrollbar em CSS é a abstração errada, especialmente quando o agente opera fora de uma sandbox rígida (Hacker News).
O Reddit é menos organizado, mas captura a dor operacional. No r/ClaudeCode, desenvolvedores já estão tentando destilar comportamento parecido com o do Fable em arquivos de instrução para Opus 4.8, compartilhando prompts Fable5.md, ideias com --append-system-prompt-file e receitas de “deixar o Opus mais proativo” (Reddit). No r/cybersecurity e no r/LocalLLaMA, o debate muda para risco de plataforma: se um modelo hospedado de fronteira pode ser retirado da noite para o dia, equipes sérias deveriam depender mais de modelos locais, roteamento multiprovedor ou fallbacks hospedados de camada inferior (Reddit, Reddit).
A resposta prática que falta em muitas threads: não tente sair de risco de provedor “no prompt”. Prompts podem fazer Opus se comportar mais como Fable. Eles não conseguem tornar disponível um modelo indisponível.
Use Opus 4.8 Quando Você Quer Continuidade com Claude
Escolha Claude Opus 4.8 quando seu sistema já depende do estilo de uso de ferramentas do Claude, do comportamento em contexto longo, do Claude Code, da semântica da Anthropic Messages API ou de prompt caching.
Opus 4.8 é o fallback menos disruptivo. A própria página de Opus da Anthropic diz que o modelo está disponível como claude-opus-4-8, começa em $5/M de entrada e $25/M de saída, oferece economia de até 90% com prompt caching e economia de 50% com processamento em lote (Anthropic). Se você construiu em cima do formato de mensagens do Claude, system prompts, chamadas de ferramenta ou convenções de CLAUDE.md, ficar dentro da família Claude reduz o risco de migração.
Use para:
- Revisão de codebases grandes, onde o modelo precisa manter muitos arquivos e convenções na cabeça.
- Fluxos agentic que se beneficiam do planejamento cauteloso e da autoverificação do Claude.
- Equipes que já usam Claude Code e querem um fallback de baixo atrito para Fable 5.
- Jobs pesados em saída, onde o preço de $30/M de saída do GPT-5.5 começa a pesar.
- Fluxos que conseguem explorar prompt caching.
A fraqueza é a clareza de benchmarks. A página do GPT-5.5 da OpenAI traz muitos números de benchmark legíveis em texto. A página do Opus 4.8 da Anthropic traz posicionamento, preço, contexto, citações de parceiros e uma seção de benchmarks baseada em imagem, mas menos comparações numéricas facilmente auditáveis no texto da página. Se seu processo de compras precisa de uma tabela de scores de benchmarks nomeados, GPT-5.5 é mais fácil de defender.
Ainda assim, se a pergunta é “O que meu agente Claude deve chamar agora que Fable sumiu?”, comece com Opus 4.8.
Use GPT-5.5 Quando Você Quer Evidência e Encaixe na OpenAI
Escolha GPT-5.5 quando quiser um modelo forte de coding com números públicos de benchmark, compatibilidade com OpenAI API ou integração com Codex.
A OpenAI diz que GPT-5.5 custa $5/M de entrada e $30/M de saída para desenvolvedores de API, com uma janela de contexto de 1M de tokens (OpenAI). Seus números publicados de coding e ferramentas são fortes: 82,7% no Terminal-Bench 2.0, 58,6% no SWE-Bench Pro Public, 75,3% no MCP Atlas e 81,8% no CyberGym (OpenAI). A OpenAI também classifica as capacidades cyber e bio/químicas do GPT-5.5 como High dentro do seu Preparedness Framework, ao mesmo tempo dizendo que ele não atingiu nível Critical em capacidade de cibersegurança (OpenAI).
Use para:
- Tarefas de coding pesadas em terminal, onde desempenho no estilo Terminal-Bench mapeia bem para sua carga de trabalho.
- Verificação cruzada de planos do Claude, especialmente mudanças sensíveis em segurança ou migrações pesadas.
- Equipes já padronizadas em OpenAI Responses ou Chat Completions.
- Roteadores de agentes em que GPT-5.5 atua como revisor, crítico ou verificador de segunda passada.
- Casos em que avaliações numéricas públicas importam mais que continuidade do fluxo Claude.
A desvantagem é o custo em execuções pesadas em saída. GPT-5.5 não é dramaticamente mais caro, mas loops de agentes produzem saída. Se seu agente escreve planos longos, diffs longos, logs de teste longos e postmortems longos, essa diferença de $5/M em saída aparece.
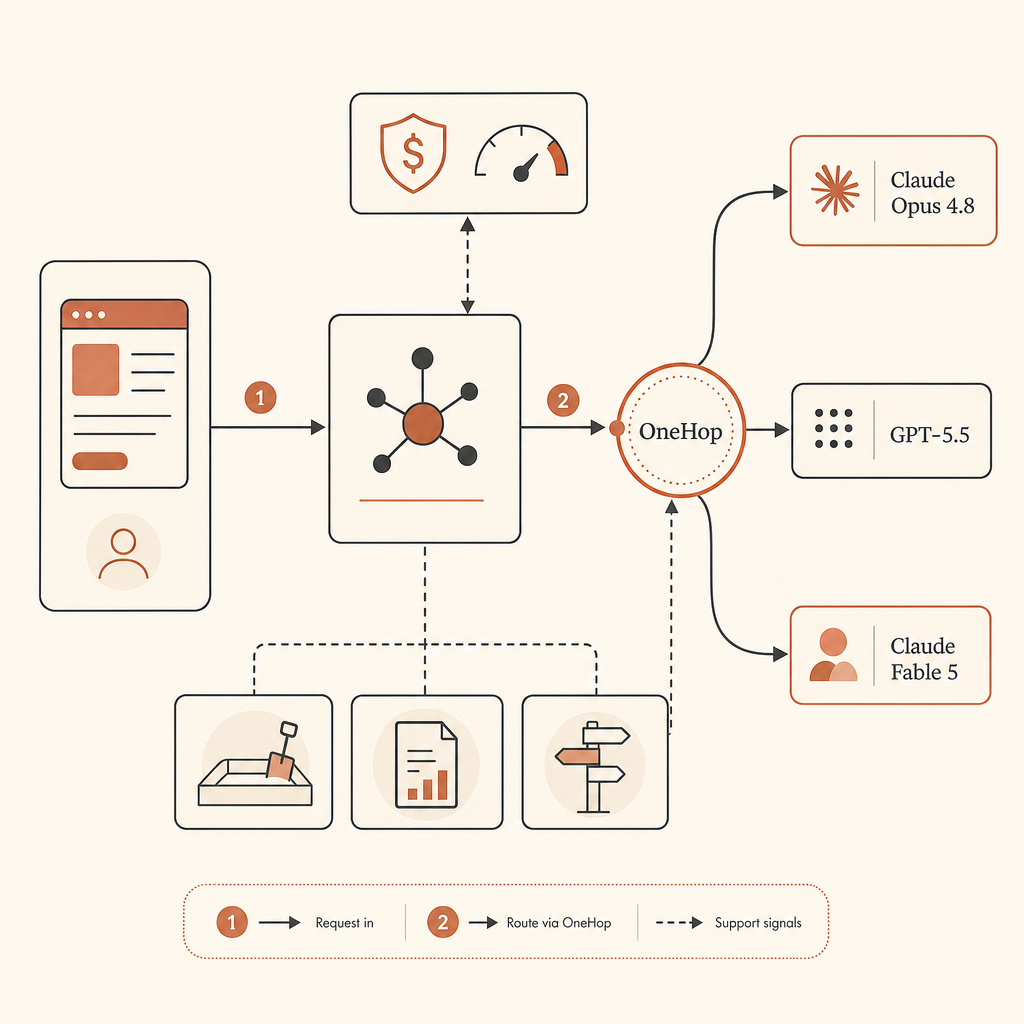
A Arquitetura Melhor: Roteie, Não Reze
Aqui está o guia de seleção que eu realmente colocaria em produção:
- Use Opus 4.8 por padrão para agentes de coding nativos de Claude.
- Roteie para GPT-5.5 para revisão independente, tarefas pesadas em terminal e stacks nativas da OpenAI.
- Mantenha um caminho Fable 5 pronto, mas não bloqueie produção nele.
- Adicione limites de orçamento, sandboxing e políticas de modelo por tarefa.
- Registre modelo, provedor, mix de tokens, motivo do fallback e aprovação humana final.
Um roteador de provedores não precisa ser sofisticado. Comece com um arquivo de política:
routes:
default_coding: claude-opus-4-8
critical_review: gpt-5.5
long_context_refactor: claude-opus-4-8
security_review: gpt-5.5
limits:
max_usd_per_task: 8
require_approval_over_usd: 3Depois aplique isso antes da chamada ao modelo. O objetivo não é perseguir roteamento automático perfeito. O objetivo é evitar amarrar a continuidade do negócio a um único ID de modelo.
Se você ainda quer Fable 5 quando o acesso estiver disponível, OneHop é o caminho de menor atrito para manter na sua tabela de roteamento. A OneHop lista Claude Fable 5 como anthropic/claude-fable-5, mostra o preço oficial de tabela de $10/M de entrada e $50/M de saída, e anuncia preço com desconto mais $10 de crédito grátis para novas contas sem exigir cartão (OneHop). O padrão natural é manter estável a abstração de provedor do seu app e trocar a base URL.
Para clientes compatíveis com OpenAI:
from openai import OpenAI
client = OpenAI(
base_url="https://api.onehop.ai/v1",
api_key="ONEHOP_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-fable-5",
messages=[
{"role": "user", "content": "Review this migration plan for hidden failure modes."}
],
)
print(response.choices[0].message.content)Quando você quiser especificamente a rota Fable, use Claude Fable 5 na OneHop. Se estiver testando roteamento de provedores do zero, comece com $10 grátis.
A recomendação final é intencionalmente sem graça. Se Fable 5 está indisponível, não passe a semana discutindo se Opus 4.8 ou GPT-5.5 tem a personalidade melhor. Coloque Opus 4.8 no slot de fallback de Claude. Coloque GPT-5.5 no slot de revisor e no slot nativo da OpenAI. Mantenha Fable 5 como opção roteada via OneHop quando disponível. Depois meça suas próprias tarefas: taxa de sucesso, edições humanas, tempo de ponta a ponta, custo de tokens e contagem de rollbacks.
Esse é o movimento adulto. Debates de fãs de modelo são divertidos. Agentes em produção precisam de plano de saída.

