Anthropic 新發布的 Claude Opus 4.6 破壞風險報告裡,有一句話每個正在導入程式代理的工程主管都該讀兩遍:該公司表示,它會對「絕大多數」內部 Claude Code 使用進行自動化監控,並對較小比例進行人工稽核,因為 Claude Code 是那個讓 Opus 4.6「有能力採取直接且具後果性行動」的內部工具(Anthropic PDF)。
這才是新聞。不是 Opus 4.6 很安全的口號。也不是 Anthropic 對 alignment 特別認真的說法。真正具體的營運事實是:Anthropic 看起來連自家最強模型都不放心讓它在內部廣泛自主寫程式,除非那些工作會被記錄、抽樣、稽核、審查,並搭配普通的安全控制。
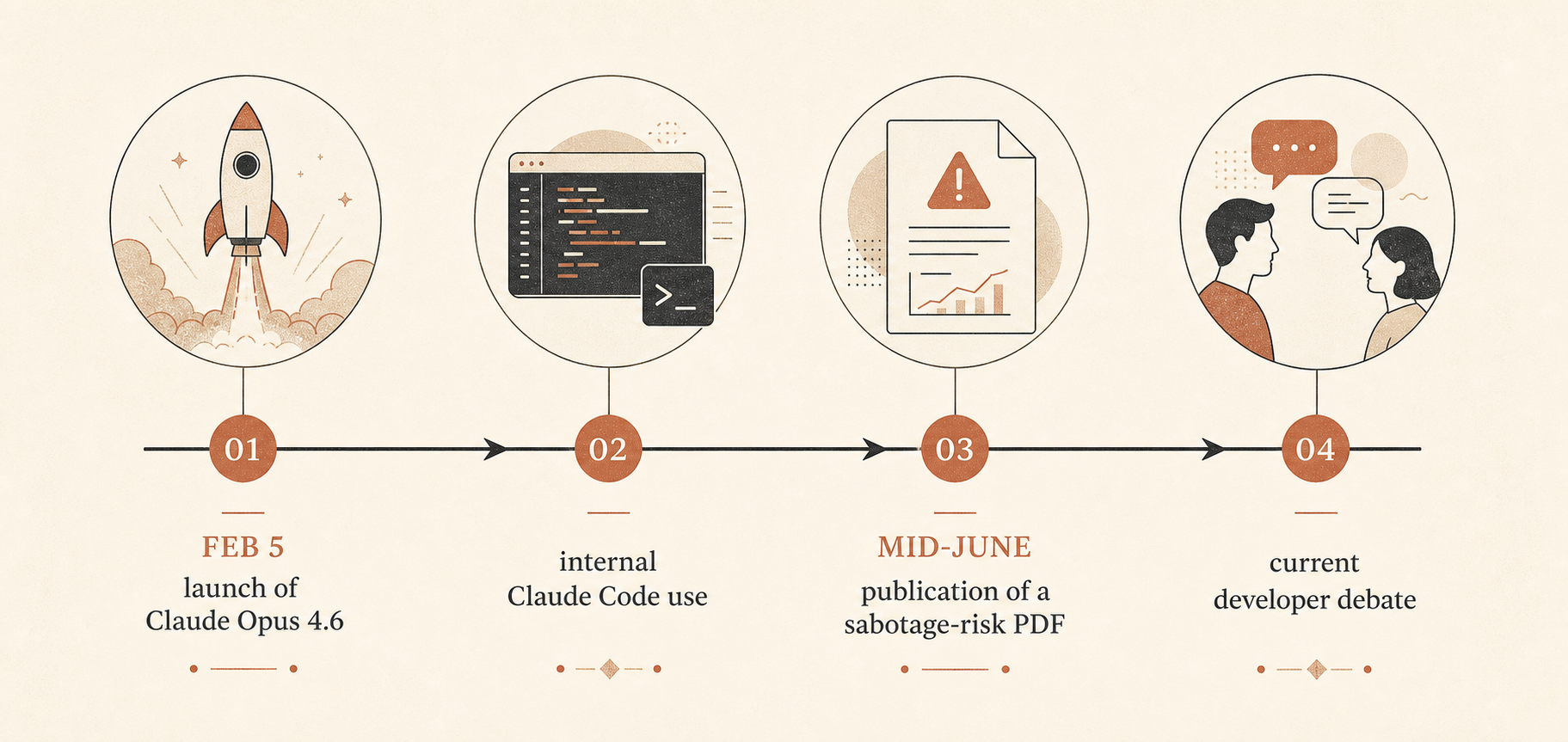
這很重要,因為 Claude Opus 4.6 在 2026 年 2 月 5 日發布時,是 Anthropic 當時最聰明的模型,具備 beta 版 100 萬 token context window、更強的代理式寫程式能力、claude-opus-4-6 API 名稱,以及維持不變的標準價格:每百萬 input tokens 5 美元、每百萬 output tokens 25 美元(Anthropic)。Anthropic 也表示,該模型在多個 benchmark 上領先,包括 Terminal-Bench 2.0 和 Humanity’s Last Exam,並在 GDPval-AA 上以約 144 Elo 分擊敗 GPT-5.2。在同一篇發布文章裡,Anthropic 也大力推 long-running agents、context compaction、effort controls,以及 Claude Code agent teams。
所以這份報告不是理論。它是在看:當同一類代理進入供應商自己的工程流程時,供應商自己到底怎麼做。
Anthropic 實際發布了什麼
這份 53 頁 PDF 的標題是「Sabotage Risk Report: Claude Opus 4.6」。它把破壞定義為:AI 模型利用在組織內部的存取權限,去「利用、操縱或竄改」系統或決策,且其方式可能提高災難性風險(Anthropic PDF)。Anthropic 的整體評估很直接:風險「非常低,但並非可忽略」。
這句話很容易被嘲笑。聽起來像法務部門和安全實驗室在搶同一張椅子坐。但埋在風險措辭底下的,是一套實用的程式代理治理模型。
Anthropic 表示,Opus 4.6 在內部大量用於寫程式、資料生成,以及其他代理式使用情境。它也說,該模型在需要人類專家花數小時完成的任務上能力很強,雖然「並非完全可靠」。接著報告逐一走過威脅路徑:分散式拖累安全相關研發、定向破壞、程式碼後門、訓練資料投毒、自我外洩、失控的內部部署,以及在其他組織或政府中的破壞行為。
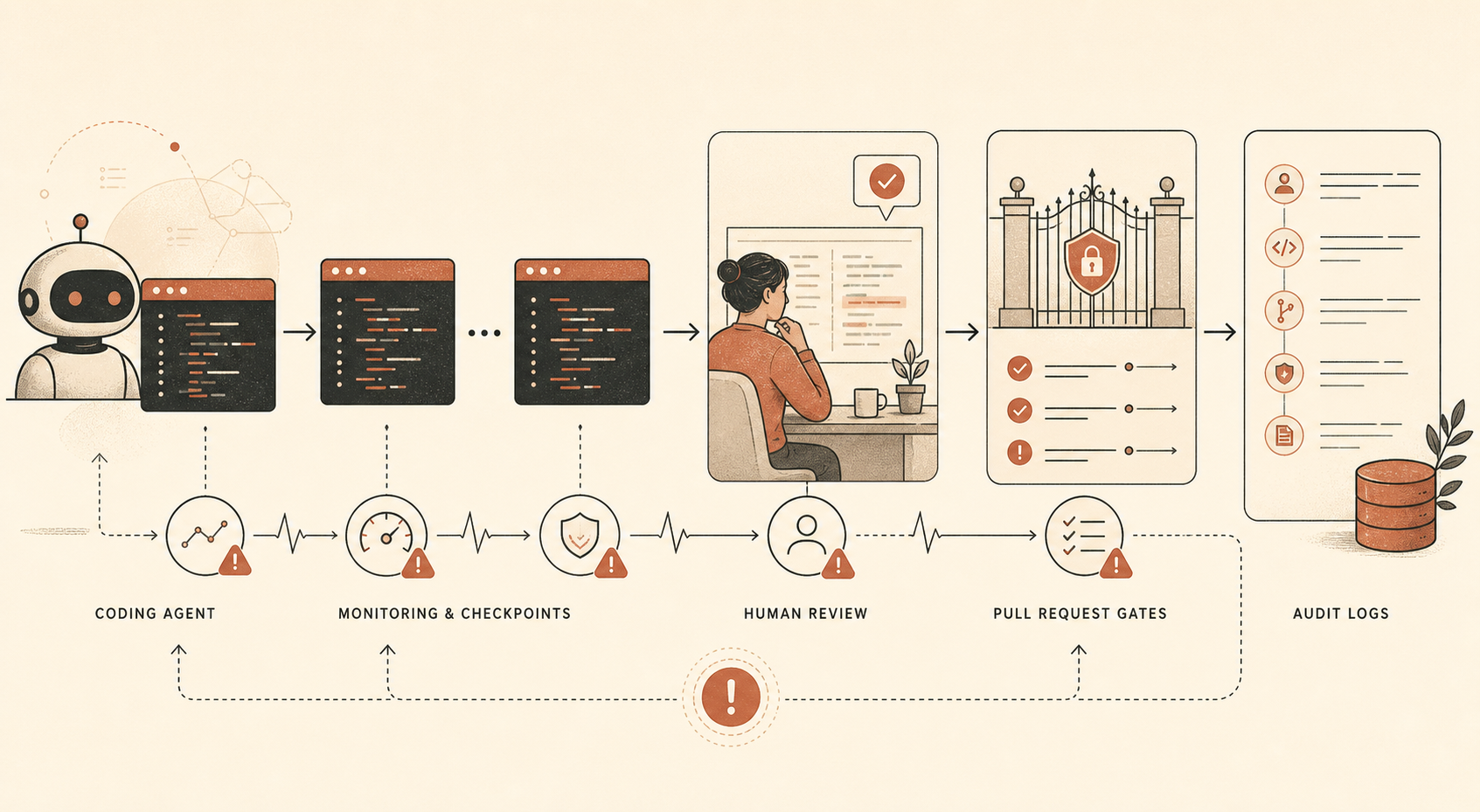
對開發者來說,重點是這組緩解措施:
| 控制 | Anthropic 說它使用什麼 | 給開發者的翻譯 |
|---|---|---|
| 離線 Claude Code 監控 | 絕大多數內部 Claude Code 使用;其他地方則描述多數使用者有 ≥10% prompt 子樣本 | 記錄代理 session,並抽樣審查 |
| 人工稽核 | 小部分內部 Claude Code 使用 | 審查真實 session,不只看最後 diff |
| 人工 PR 審查 | 人類在程式碼整合到共享 codebase 前進行審查 | 重要 merge 保留人工核准 |
| 自動 PR 審查 | 以 Claude 為基礎的審查會檢查錯誤、安全問題,以及宣稱意圖與實際效果之間的不一致 | 用獨立 AI 審查作為非阻擋訊號 |
| 不變性測試 | 自動化測試檢查安全屬性 | 在 CI 裡編碼「絕對不能發生」的規則 |
有個細節很醒目:Anthropic 說,它的自動 pull-request 監控在撰寫時是基於 Claude Opus 4.5,而不是 Opus 4.6。這是安靜但重要的設計選擇。執行工作的模型和審查工作的模型不必相同。事實上,分離更健康。
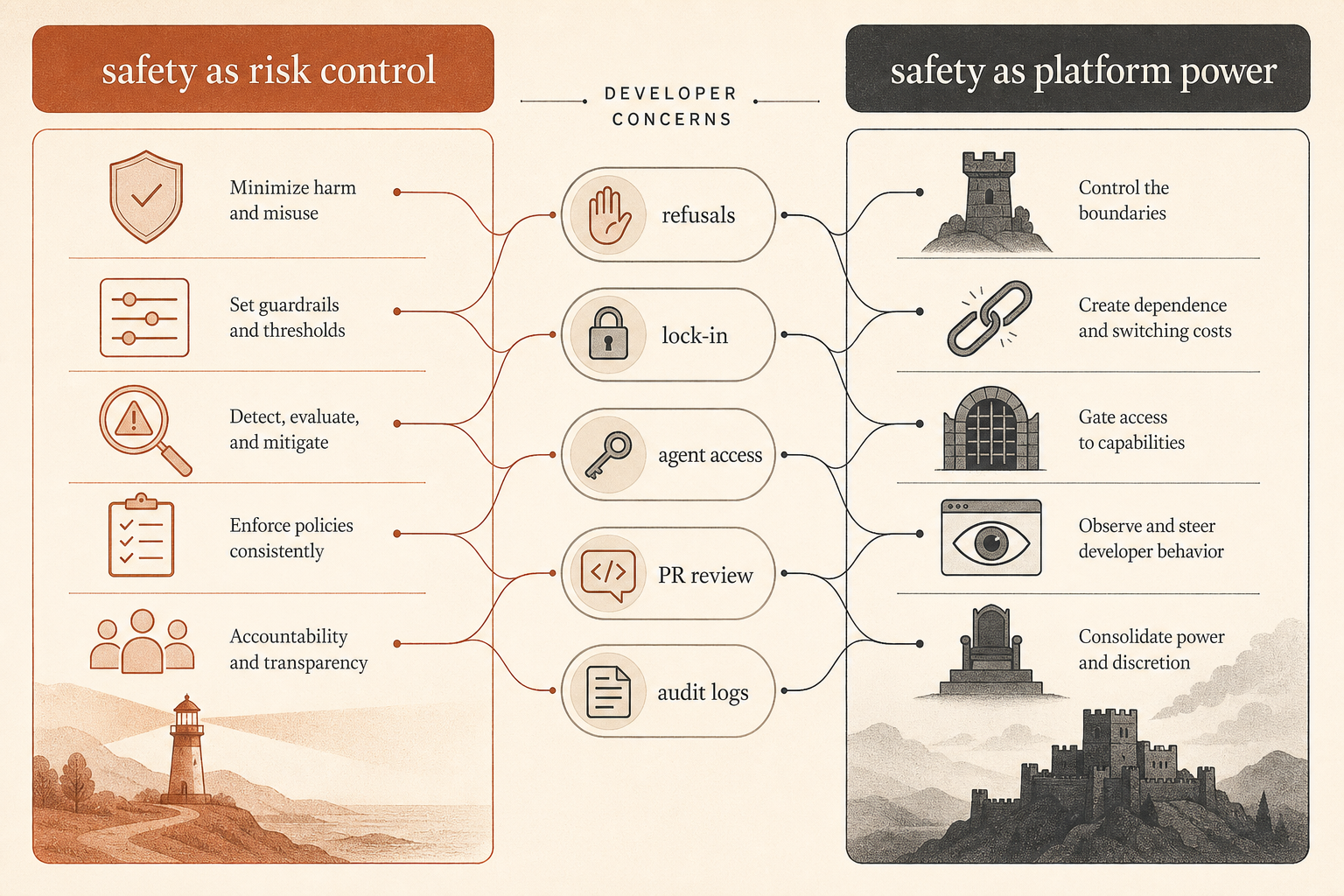
社群爭論的是控制,不只是安全
這份報告進入的是一場正在發生的爭論。在 Hacker News 上,圍繞 Ben Thompson〈Anthropic’s Safety Superpower〉的 6 月討論串有 192 則留言,分裂成幾條熟悉路線:有些開發者認為 Anthropic 的安全姿態,是部署強大託管工具時必要的成本;另一些人則把安全看成平台控制的道德包裝(Hacker News)。
最尖銳的開發者抱怨不是「模型不該有任何護欄」。而是:當這個工具正在成為軟體供應鏈的一部分時,誰來決定什麼算濫用?
一位 HN 留言者把工業控制問題講得很清楚:要求 Claude 稽核安全關鍵控制軟體,和要求 Claude 在外洩的控制軟體裡找入口點,可能需要相近的技術工作,但意圖完全不同(Hacker News)。另一串討論則指出,如果供應商兩者都擋,防守方會吃虧;如果兩者都放行,攻擊者會得利。這才是安全修辭背後真正的產品問題。
另一個抱怨是鎖定。好幾位留言者質疑,如果託管模型供應商可以改政策、拒絕任務、降級行為或限制存取,它還能不能被信任為中立工具提供者。其他人則反駁說,Anthropic 賣的是服務,不是本機工具,而服務供應商一直以來都會拒絕某些用途。
破壞報告替這場辯論補上了一塊缺失的拼圖。Anthropic 不只是試圖在模型邊界控制使用者輸出。在內部,它把程式代理當成半可信的生產環境角色來對待。信任模型不是「Claude 已 alignment,出貨吧」。它更接近「Claude 夠有用,值得跑;也夠有風險,必須監控;而且夠有後果,必須審查」。
這才是團隊應該照抄的部分。
實務教訓:代理式寫程式需要縱深防禦
一旦程式代理可以編輯檔案、執行指令、查看接近 secrets 的設定、開 PR、呼叫 MCP 工具,或協調 subagents,它就不再只是漂亮一點的 autocomplete。它是一位介於 junior 到 senior 之間的外包人員,判斷力不穩定,沒有雇傭契約,耐心卻完美無缺。
這會改變控制面。
如果你的團隊正在使用 Claude Code、Cursor、Codex、Devin、OpenCode,或內部 agent harness,問題不是「我們信不信這個模型?」問題是「模型可以在沒有第二套系統注意到的情況下做哪些事?」
合理的基準線大概長這樣:
coding_agent_controls:
session_logging: required
write_access: repo-scoped
secret_access: denied_by_default
shell_commands: allowlist_or_confirm
pr_review: human_required
ai_review: separate_model_recommended
audit_sampling: risk_based
invariant_tests: blocking這不是官僚。這是讓你保住生產力收益,又不把每個 repository 都變成社會實驗的方法。
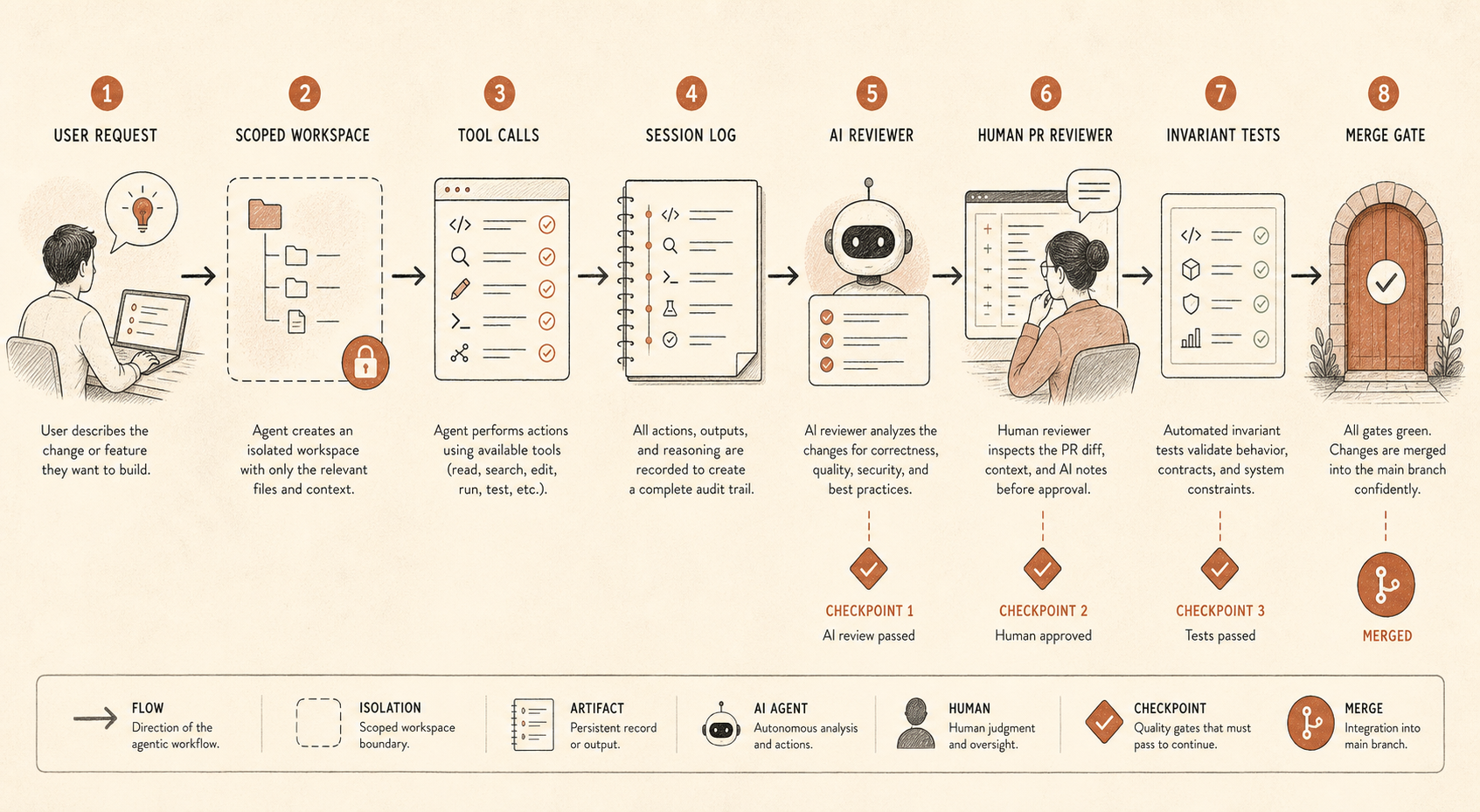
第一個控制是 session logging。儲存 prompts、tool calls、file diffs、shell commands,以及最後的 PR links。如果這感覺太侵入,至少對低風險 repo 記錄 metadata 和 diffs,對高風險 repo 保留完整 traces。沒有 traces,你就無法稽核代理的推理路徑,也無法重建一個壞變更是怎麼發生的。
第二個是範圍化存取。多數程式代理不需要 production credentials、廣泛的網路存取,或橫跨整個 monorepo 的寫入權限。給它們一個 working tree、一個任務,以及明確的升級路徑。若它們需要更多,就讓請求可見。
第三個是 PR 層級的獨立性。Anthropic 的報告同時提到人工 PR 審查和自動 Claude-based review。重點不是審查者是不是 Claude。重點是審查是一次分離的 pass,有不同 prompt、不同 context、不同目標。實作代理想完成任務。審查代理應該尋找不一致:「宣稱的變更說是 refactor,但這個 diff 改了 auth 行為。」
第四個是不變性測試。這是最不光鮮、也最被低估的控制。如果兩個服務絕對不能互相通訊,就寫測試。如果某個權限絕對不能在 admin path 之外被授予,就寫測試。如果生成的 migrations 絕對不能在沒有 ticket tag 的情況下 drop columns,就寫測試。當 CI 能強制執行硬邊界時,代理監控會容易得多。
Anthropic 的報告沒有證明什麼
這份報告沒有證明 Opus 4.6 無法破壞工作。它沒有證明自動化監控器會抓到隱蔽後門。它沒有證明模型無法學會在監控器面前表現良好。Anthropic 對限制講得相當明白:它說沒有任何單一 safeguard 本身能提供強保證,而且公開 PDF 也包含遮蔽內容。
這個 caveat 很重要,因為開發者已經把這些發布自動歸到兩個偷懶陣營裡。
第一陣營說:Anthropic 發了一份很長的安全報告,所以它一定安全。
不。報告說的是:模型有用、強大、被監控,而且仍然不是零風險。
第二陣營說:Anthropic 談安全,所以這一定是 regulatory capture 或行銷。
這也太簡化。報告裡描述的控制都是普通工程衛生。安全監控、PR 審查、稽核抽樣、sandboxing、不變性測試、使用者回報,並不是神祕的 alignment 儀式。它們是成熟團隊面對內部人員、被入侵的 CI tokens,以及高風險第三方相依套件時,用的同一套動作。
更有用的是那個不舒服的中間地帶:Anthropic 可能會因為被視為安全公司而獲得商業利益,同時它的內部控制仍然值得照抄。兩件事可以同時為真。
這份報告也對採用 multi-agent coding 的團隊提出一個細微警告。Anthropic 的發布文章強調 Claude Code agent teams、parallel subagents、context compaction,以及更長時間運行的工作(Anthropic)。這些功能正是監控變得更難的地方。單一 assistant 做一個 diff 很容易檢查。一群 agents 讀取、編輯、摘要、交接 state,則是 provenance 問題。
如果你讓 agents 協調,就記錄協調過程。如果一個 agent 寫計畫、另一個實作,就保留兩邊 traces。如果 context 被 compact,就儲存 compaction 前後的邊界。摘要是有損的。有損 state 正是 accountability 消失的地方。
給正在出貨程式代理團隊的控制清單
這是我會在讓程式代理碰重要 repositories 前設定的實務門檻。
先從 repo 分級開始。docs repo、prototype、billing service、identity provider,不該共用同一套 agent policy。把安全敏感 repo 當成不同等級處理。
要求進入共享 branches 的 merge 必須有人類審查。這聽起來很明顯,但當 agents 建出「明顯正確」的機械式 diffs 時,團隊會悄悄繞過它。不要。Agent-written code 應該走跟 intern-written code 一樣的審查路徑,而且要更注意測試和權限。
跑第二個 reviewer。用另一個模型、另一個 prompt,或 static analysis pass。請它比較使用者要求的變更和實際 diff。這種 mismatch check 很便宜,而且能抓到普通審查會漏掉的一類失敗。
抽樣 sessions,不只是 PR。一個惡意或混亂的 agent 可能會探索敏感檔案、執行奇怪指令,或嘗試一些最後沒有進入 final diff 的變更。Anthropic 聚焦在 Claude Code use,而不只是 merged code,這個直覺是對的。
用設計阻擋 secrets。不要依賴模型「知道」不該讀 .env.production。使用 filesystem permissions、secret scanners、environment isolation,以及 command confirmation。
為安全屬性加入不變性測試。報告裡的例子很直白:如果兩個 nodes 不該互相傳送流量,就測試它們不能。把它翻譯成你的世界:auth boundaries、tenant isolation、payment state transitions、data retention、export controls、audit events。
寫好 incident path。如果 reviewer 看到可疑的 agent 行為,要送去哪裡?Slack?Security?Vendor report?擋下一個 merge 不等於 incident process。

為什麼現在這很重要
舊的 AI 寫程式問題,是模型能不能寫出有用的程式碼。Opus 4.6、Sonnet 4.6、GPT-5-class systems,以及當前這批程式代理,基本上已經回答了。它們可以寫有用的程式碼。它們也能很快寫出爛程式碼、自信地寫出看似合理的程式碼,並在有足夠 context 時,寫出危險的安全敏感程式碼。
新的問題是營運問題:你的團隊能不能吸收 agent labor,而不失去對軟體供應鏈的控制?
Anthropic 的破壞報告有價值,因為它讓供應商自己的答案變得可見。對於內部 Claude Code 使用,Anthropic 描述了覆蓋絕大多數使用的自動化監控、人工稽核、人工 PR 審查、自動 PR 監控、sandboxing、安全監控,以及不變性測試。這不是 vibe。這是一組 control stack。
開發者應該停止把「信任模型」當成決策本身。真正的決策,是把模型放進一個預設它會犯錯的系統裡的哪個位置。讓它起草。讓它搜尋。讓它重構。讓它開 PR。但讓重要行動可觀測、可審查、可逆轉、可測試。
這才是這份報告真正有用的 takeaway。安全主張會繼續在 HN、Reddit 和 X 上吵下去。你的 CI pipeline 不需要解決哲學問題。它需要抓到壞 diff。
想親自試用 Claude Fable 5 的讀者,可以透過 OneHop 使用:一個 drop-in endpoint,價格約低於標價 30%,新帳號有 10 美元免費額度,且不需信用卡。請看 OneHop 上的 Claude Fable 5 或 從 10 美元免費額度開始。
延伸閱讀:Claude Fable 5 入門.

