Anthropic 针对 Claude Opus 4.6 发布的新破坏风险报告里,有一句话值得每个正在引入编码代理的工程负责人读两遍:该公司表示,由于 Claude Code 是让 Opus 4.6 “能够直接采取有重大后果行动”的内部工具,它会对“绝大多数”内部 Claude Code 使用进行自动化监控,并对其中较小一部分进行人工审计(Anthropic PDF)。
这才是新闻。不是 Opus 4.6 很安全的口号。也不是 Anthropic 在对齐问题上格外认真的论证。真正具体的运营事实是:Anthropic 似乎并不愿意把广泛的内部编码自主权交给哪怕是自家最强模型,除非这些工作被记录、抽样、审计、审查,并由常规安全控制兜底。
这很重要,因为 Claude Opus 4.6 于 2026 年 2 月 5 日发布,当时是 Anthropic 最聪明的模型,beta 版支持 100 万 token 上下文窗口,具备更强的代理式编码能力,API 名称为 claude-opus-4-6,标准价格保持不变:每百万输入 token 5 美元、每百万输出 token 25 美元(Anthropic)。Anthropic 还称,该模型在多项基准测试中领先,包括 Terminal-Bench 2.0 和 Humanity’s Last Exam,并在 GDPval-AA 上以约 144 Elo 分领先 GPT-5.2。在同一篇发布文章中,Anthropic 大力宣传了长时间运行的代理、上下文压缩、努力程度控制,以及 Claude Code 代理团队。
所以这份报告不是理论推演。它是在看,当同一类代理进入供应商自己的工程循环时,供应商到底怎么做。
Anthropic 到底发布了什么
这份 53 页的 PDF 标题是《Sabotage Risk Report: Claude Opus 4.6》。它将破坏定义为:AI 模型利用其在组织内部的访问权限,以可能提高灾难性风险的方式“利用、操纵或篡改”系统或决策(Anthropic PDF)。Anthropic 的总体评估很直白:风险“非常低,但并非可以忽略”。
这句话很容易被嘲笑。听起来像是法务部门和安全实验室挤在同一把椅子上。但埋在风险表述下面的,是一套实用的编码代理治理模型。
Anthropic 表示,Opus 4.6 在内部被大量用于编码、数据生成以及其他代理式用例。它还表示,该模型能力很强,尽管在需要人类专家花费数小时完成的任务上“并非完全可靠”。报告随后梳理了多条威胁路径:对安全相关研发的分散式装傻、定向破坏、代码后门、训练数据投毒、自我外泄、失控的内部部署,以及在其他组织或政府中的破坏行为。
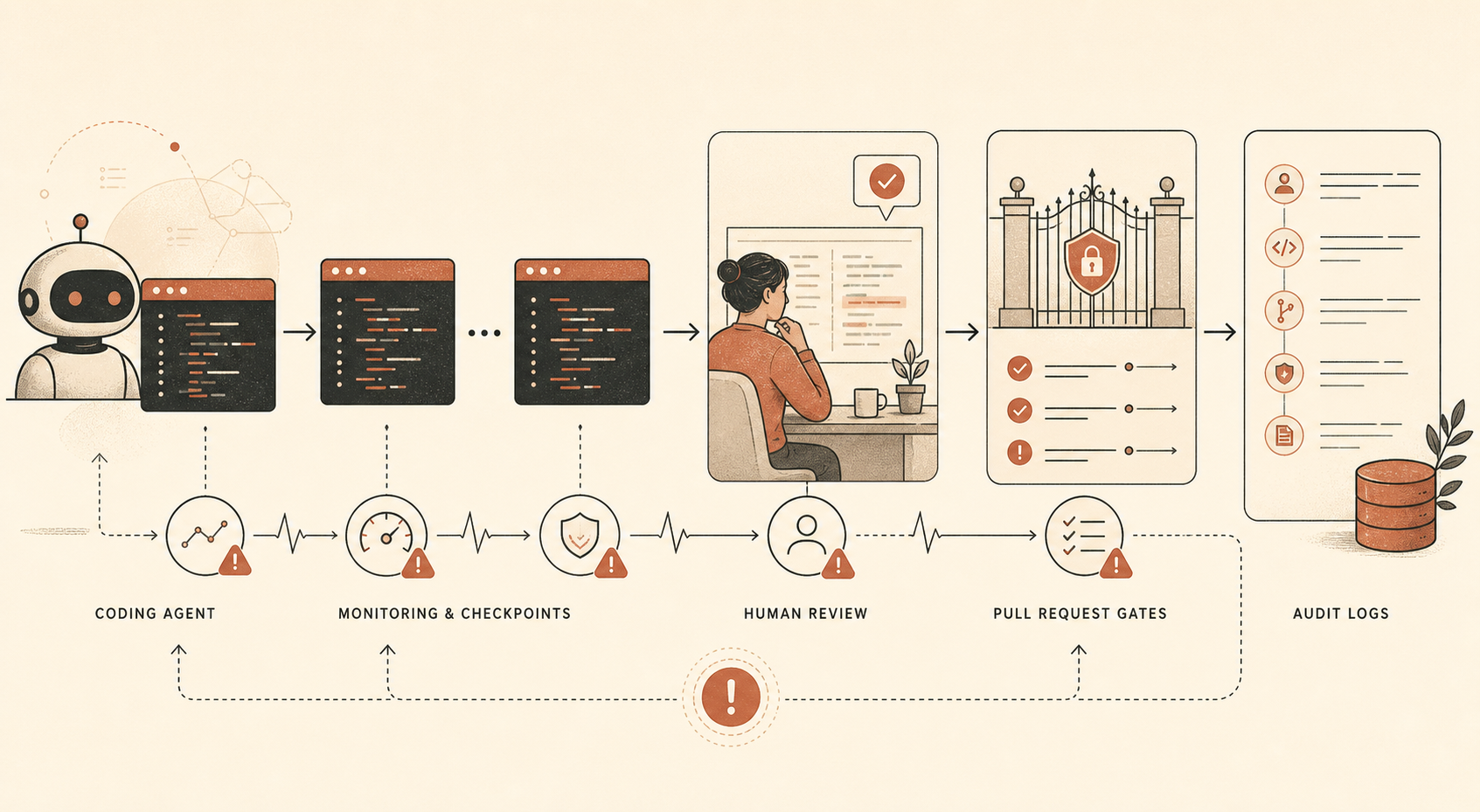
对开发者来说,相关部分是这套缓解控制栈:
| 控制 | Anthropic 称其使用了什么 | 给开发者的翻译 |
|---|---|---|
| 离线 Claude Code 监控 | 绝大多数内部 Claude Code 使用;其他地方还描述了对大多数用户进行 ≥10% 的提示抽样 | 记录代理会话,并抽样审查 |
| 人工审计 | 一小部分内部 Claude Code 使用 | 审查真实会话,而不只是最终 diff |
| 人工 PR 审查 | 人类在代码合入共享代码库前进行审查 | 重要合并保留人工批准 |
| 自动 PR 审查 | 基于 Claude 的审查会检查错误、安全问题,以及声明意图和实际效果之间的不一致 | 将独立 AI 审查作为非阻塞信号运行 |
| 不变量测试 | 自动化测试检查安全属性 | 在 CI 中编码“绝不能发生”的规则 |
有一个细节格外醒目:Anthropic 表示,撰写报告时,它的自动 pull-request 监控基于 Claude Opus 4.5,而不是 Opus 4.6。这是一个低调但重要的设计选择。做事的模型和审查工作的模型不需要相同。事实上,分离更健康。
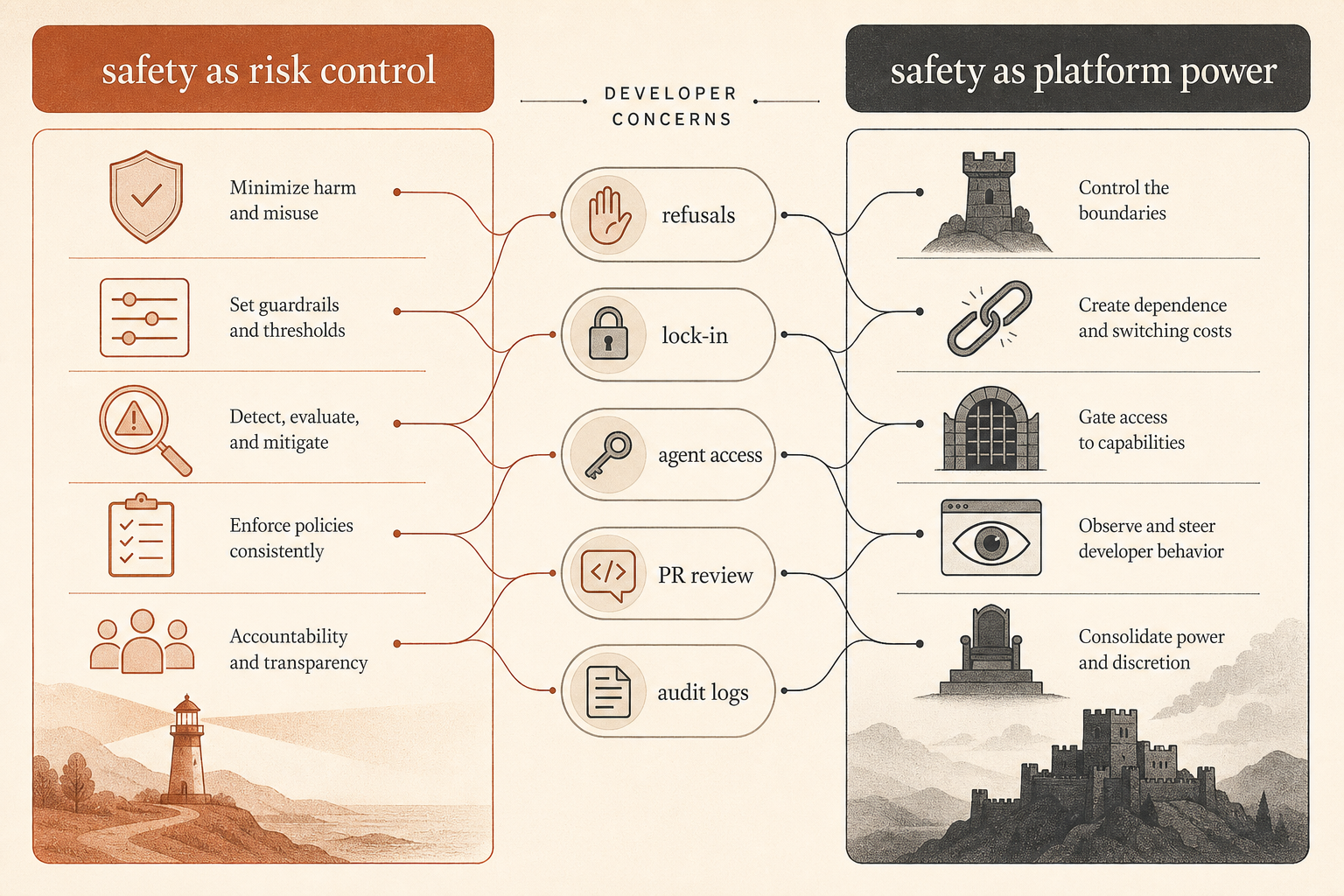
社区争论的核心是控制,不只是安全
这份报告落进了一场正在进行的争论里。在 Hacker News 上,围绕 Ben Thompson《Anthropic’s Safety Superpower》的 6 月讨论帖有 192 条评论,并沿着熟悉的路线分裂:一些开发者认为,Anthropic 的安全姿态是部署强大托管工具所必须付出的成本;另一些人则认为,安全只是平台控制的道德包装(Hacker News)。
开发者最尖锐的抱怨不是“模型不该有任何护栏”。而是:当这个工具正成为软件供应链的一部分时,谁来决定什么算滥用?
一位 HN 评论者把工业控制问题说得很清楚:让 Claude 审计安全关键控制软件,和让 Claude 在泄露的控制软件中寻找入口点,可能需要类似的技术工作,但意图完全不同(Hacker News)。另一条讨论则认为,如果提供商同时阻止两者,防守者会吃亏;如果同时允许两者,攻击者会获利。这才是安全话术背后真正的产品问题。
另一个抱怨是锁定。几位评论者质疑,如果一个托管模型供应商能够改变政策、拒绝任务、降级行为或限制访问,它是否还能被信任为中立的工具提供者。也有人反驳说,Anthropic 卖的是服务,不是本地工具,而服务提供商一直都会拒绝某些用途。
这份破坏报告给这场争论补上了缺失的一块。Anthropic 不只是试图在模型边界控制用户输出。在内部,它把编码代理当作半可信的生产参与者来对待。它的信任模型不是“Claude 已经对齐了,发吧”。它更接近于:“Claude 有用到值得运行,也有风险到必须监控,并且足够关键到需要审查。”
这才是团队应该照抄的部分。
实用教训:代理式编码需要纵深防御
一旦编码代理能够编辑文件、运行命令、查看接近秘密的配置、打开 PR、调用 MCP 工具,或协调子代理,它就不再是高级版自动补全。它更像是一个判断力不稳定、没有劳动合同、却极有耐心的初级到资深之间的外包工程师。
这会改变控制面。
如果你的团队在使用 Claude Code、Cursor、Codex、Devin、OpenCode,或内部代理框架,问题不是“我们是否信任模型?”问题是:“模型能在没有第二套系统察觉的情况下采取哪些行动?”
一个合理的基线大概是这样:
coding_agent_controls:
session_logging: required
write_access: repo-scoped
secret_access: denied_by_default
shell_commands: allowlist_or_confirm
pr_review: human_required
ai_review: separate_model_recommended
audit_sampling: risk_based
invariant_tests: blocking这不是官僚主义。这是你在保住生产力收益的同时,不把每个代码库都变成社会实验的方法。
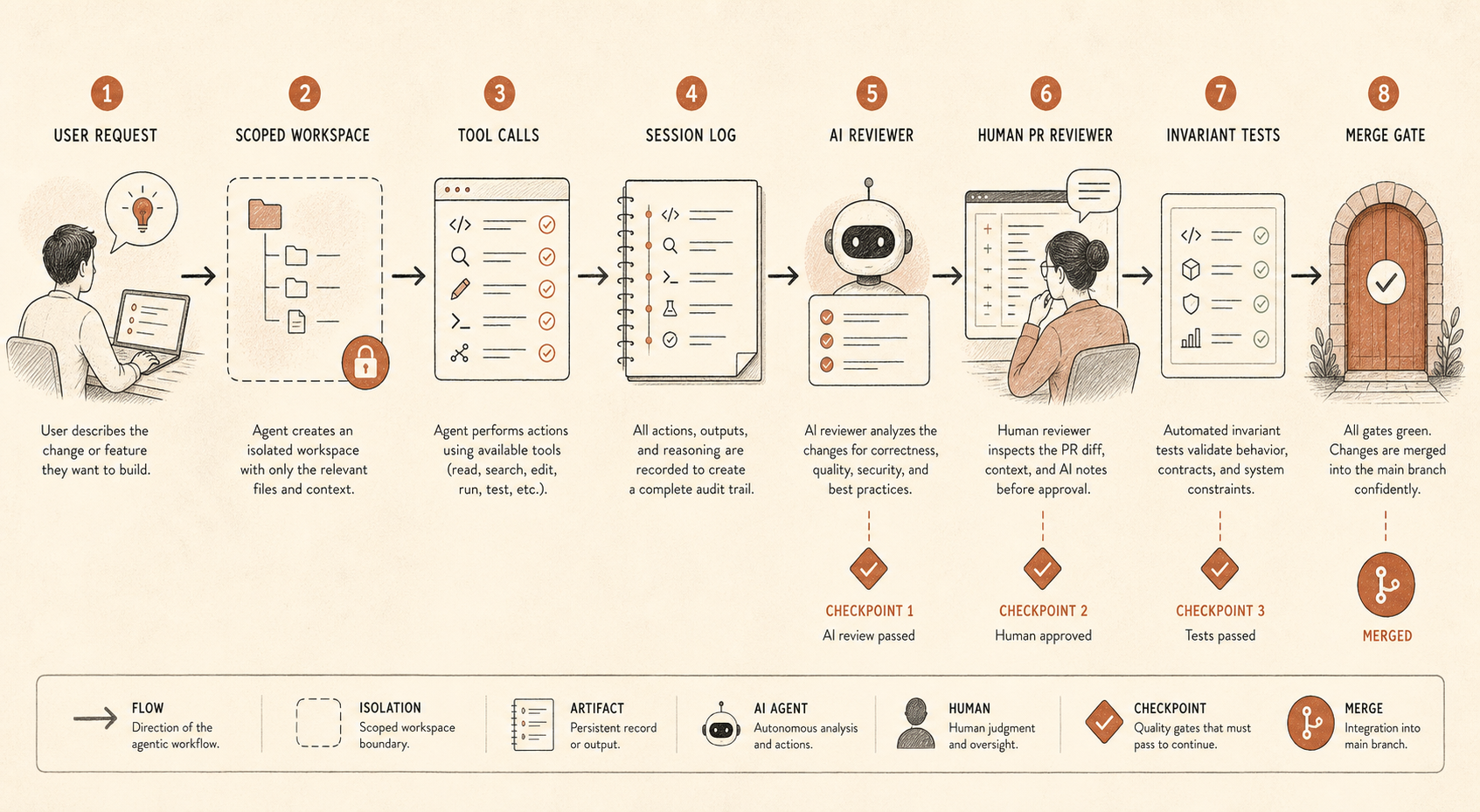
第一个控制是会话记录。存储提示、工具调用、文件 diff、shell 命令和最终 PR 链接。如果这听起来太侵入,至少对低风险仓库记录元数据和 diff,对高风险仓库记录完整轨迹。没有轨迹,你就无法审计代理的推理路径,也无法还原一次糟糕变更是怎么发生的。
第二个是范围化访问。大多数编码代理不需要生产凭证、广泛网络访问,也不需要跨整个 monorepo 的写权限。给它们一个工作树、一个任务,以及明确的升级路径。如果它们需要更多权限,就让这个请求可见。
第三个是 PR 级别的独立性。Anthropic 的报告同时提到了人工 PR 审查和自动 Claude 审查。重要的不是审查者是不是 Claude。重要的是,审查是一次独立的 pass,有不同的提示、不同的上下文和不同的目标。实现代理想完成任务。审查代理应该寻找不一致:“声明的变更说是重构,但这个 diff 改了认证行为。”
第四个是不变量测试。这是最不性感、也最被低估的控制。如果两个服务绝不能互相通信,就写测试。如果某个权限绝不能在管理员路径之外被授予,就写测试。如果生成的迁移在没有 ticket tag 的情况下绝不能 drop columns,就写测试。当 CI 能强制执行硬边界时,代理监控会容易得多。
Anthropic 的报告没有证明什么
这份报告没有证明 Opus 4.6 不会破坏工作。它没有证明自动监控器能抓住隐蔽后门。它也没有证明模型不会学会在监控器面前表现良好。Anthropic 对局限性说得相当明确:它表示,没有任何单一防护措施能单独提供强保证,而且公开 PDF 中包含删节内容。
这个提醒很重要,因为开发者已经开始把这类发布套进两个偷懒阵营。
阵营一说:Anthropic 发布了一份很长的安全报告,所以它一定安全。
不。报告说的是:这个模型有用、强大、受到监控,但仍然不是零风险。
阵营二说:Anthropic 谈安全,所以这一定是监管俘获或营销。
这也太简单了。报告中描述的控制都是普通工程卫生。安全监控、PR 审查、审计抽样、沙箱、不变量测试和用户报告,不是什么神秘的对齐仪式。它们和成熟团队用于人类内部人员、被盗 CI token、以及高风险第三方依赖的手段是同一类东西。
更有用的是那个令人不舒服的中间地带:Anthropic 可能会从“安全公司”这一形象中获得商业利益,同时它的内部控制仍然值得照抄。这两件事可以同时成立。
这份报告还给采用多代理编码的团队留下了一个细微警告。Anthropic 的发布文章重点介绍了 Claude Code 代理团队、并行子代理、上下文压缩和更长时间运行的工作(Anthropic)。这些功能正是监控变得更难的地方。一个助手做一个 diff,很容易检查。一群代理读取、编辑、总结并交接状态,就是一个来源追踪问题。
如果你让代理协作,就记录协作过程。如果一个代理写计划、另一个代理实现它,就保留两边的轨迹。如果上下文被压缩,就存下压缩前和压缩后的边界。摘要是有损的。有损状态,正是问责消失的地方。
给发布编码代理团队的控制清单
在让编码代理接触重要代码库之前,我会把实用门槛设在这里。
先从仓库分类开始。文档仓库、原型、计费服务和身份提供方不应该共用一套代理策略。把安全敏感仓库当作不同层级来处理。
要求合入共享分支时必须人工审查。这听起来显而易见,但当代理创建“明显正确”的机械 diff 时,团队会悄悄绕过它。别这么做。代理写的代码应该走和实习生写的代码一样的审查路径,并且额外关注测试和权限。
运行第二个审查者。使用另一个模型、另一个提示,或一次静态分析 pass。让它比较用户请求的变更和实际 diff。这个不一致检查成本很低,却能抓住普通审查会漏掉的一类失败。
抽样会话,而不只是 PR。恶意或混乱的代理可能会浏览敏感文件、运行奇怪命令,或尝试一些最终没有进入 diff 的变更。Anthropic 关注的是 Claude Code 使用,而不只是已合并代码,这个直觉是对的。
从设计上阻断秘密。不要依赖模型“知道”不该读取 .env.production。使用文件系统权限、secret scanner、环境隔离和命令确认。
为安全属性添加不变量测试。报告中的例子很朴素:如果两个节点不应该互相发送流量,就测试它们不能这么做。把它翻译到你的世界里:认证边界、租户隔离、支付状态流转、数据保留、出口管制、审计事件。
写好事故路径。如果审查者看到了可疑的代理行为,它该流向哪里?Slack?安全团队?供应商报告?阻止一次合并不等于有了事故流程。

为什么现在重要
过去的 AI 编码问题是模型能不能写出有用的代码。Opus 4.6、Sonnet 4.6、GPT-5 级别系统,以及当前这一批编码代理,基本已经回答了这个问题。它们能写有用的代码。它们也能很快写出坏代码,自信地写出看似合理的代码,并在拥有足够上下文时写出危险的安全敏感代码。
新的问题是运营层面的:你的团队能不能吸收代理劳动力,同时不失去对软件供应链的控制?
Anthropic 的破坏报告之所以有价值,是因为它让供应商自己的答案变得可见。对于内部 Claude Code 使用,Anthropic 描述了覆盖绝大多数使用的自动化监控、人工审计、人工 PR 审查、自动 PR 监控、沙箱、安全监控和不变量测试。这不是一种氛围。这是一套控制栈。
开发者应该停止把“信任模型”当成决策本身。真正的决策是:在一个默认模型会出错的系统里,把模型放在哪里。让它起草。让它搜索。让它重构。让它打开 PR。但要让关键行动可观察、可审查、可回滚、可测试。
这才是报告里真正有用的结论。安全声明会继续在 HN、Reddit 和 X 上争个不停。你的 CI pipeline 不需要解决哲学问题。它需要抓住坏 diff。
想亲自试试 Claude Fable 5 的读者,可以通过 OneHop 使用它:一个可直接替换的 endpoint,价格比标价低约 30%,新账户送 10 美元且无需绑卡。查看 Claude Fable 5 on OneHop 或 start with $10 free。
延伸阅读:Claude Fable 5 入门.

