Anthropics neuer Sabotagerisiko-Bericht zu Claude Opus 4.6 enthält einen Satz, den jeder Engineering Lead, der Coding Agents einführt, zweimal lesen sollte: Das Unternehmen sagt, es nutze automatisiertes Monitoring für „eine große Mehrheit“ der internen Claude Code-Nutzung, plus menschliche Audits für eine kleinere Teilmenge, weil Claude Code das interne Tool ist, das Opus 4.6 „die Fähigkeit gibt, direkte folgenschwere Handlungen auszuführen“ (Anthropic PDF).
Das ist die Nachricht. Nicht der Slogan, Opus 4.6 sei sicher. Nicht das Argument, Anthropic nehme Alignment einzigartig ernst. Die konkrete operative Tatsache ist: Anthropic scheint selbst seinem stärksten Modell keine breite interne Coding-Handlungsfreiheit zu geben, solange die Arbeit nicht geloggt, stichprobenartig geprüft, auditiert, reviewt und durch normale Sicherheitskontrollen abgesichert wird.
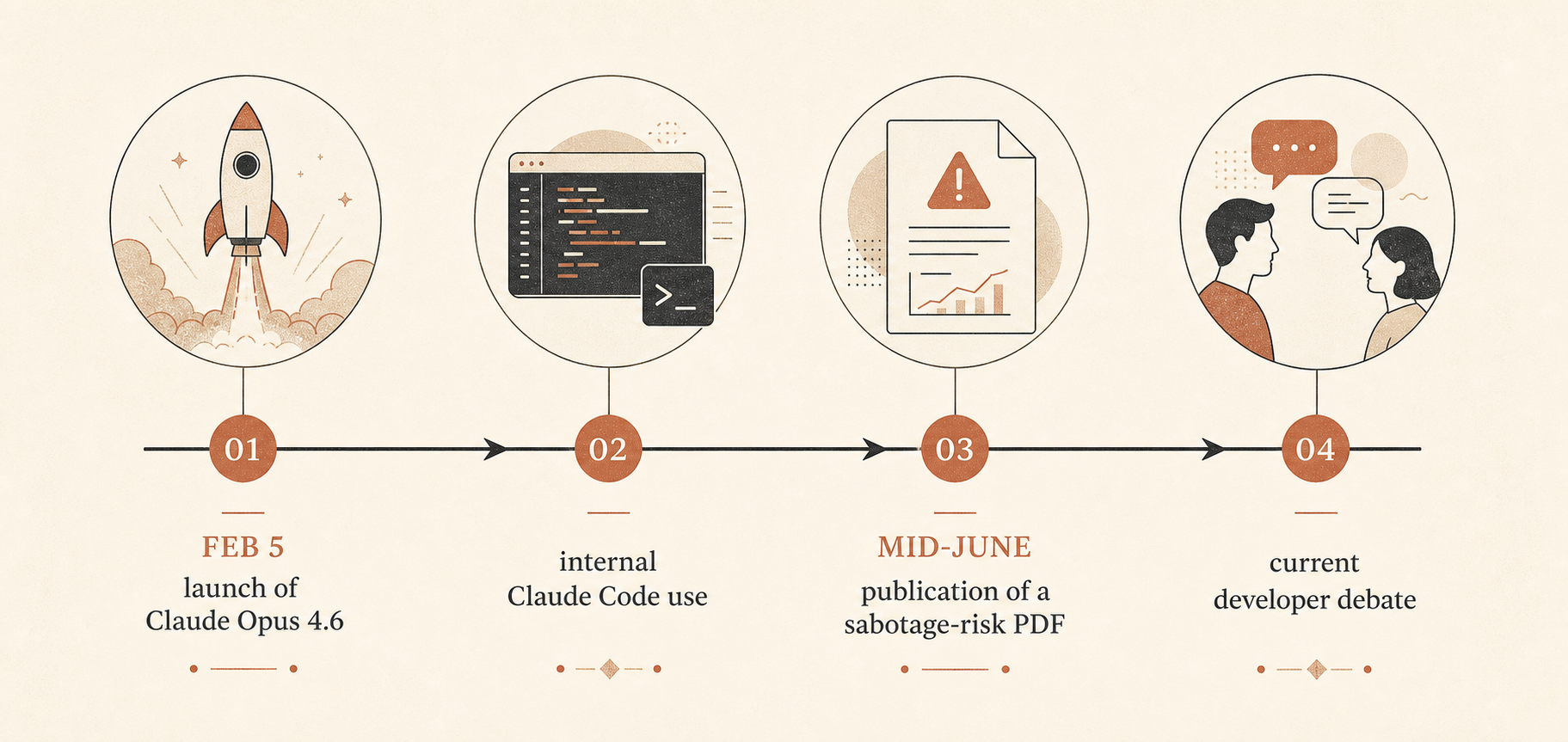
Das ist wichtig, weil Claude Opus 4.6 am 5. Februar 2026 als Anthropic damals klügstes Modell gestartet wurde: mit einem Context Window von 1 Million Tokens in der Beta, stärkerem agentischem Coding, dem API-Namen claude-opus-4-6 und unveränderten Standardpreisen von 5 Dollar pro Million Input-Tokens und 25 Dollar pro Million Output-Tokens (Anthropic). Anthropic sagte außerdem, das Modell liege bei mehreren Benchmarks vorn, darunter Terminal-Bench 2.0 und Humanity’s Last Exam, und schlage GPT-5.2 bei GDPval-AA um rund 144 Elo-Punkte. Im selben Launch-Post drückte Anthropic kräftig auf lang laufende Agents, Context Compaction, Effort Controls und Claude Code Agent Teams.
Der Bericht ist also nicht theoretisch. Er zeigt, was der Anbieter tut, wenn dieselbe Art Agent im eigenen Engineering-Kreislauf steckt.
Was Anthropic tatsächlich veröffentlicht hat
Das 53-seitige PDF trägt den Titel „Sabotage Risk Report: Claude Opus 4.6.“ Es definiert Sabotage als den Einsatz von Zugriff innerhalb einer Organisation durch ein AI-Modell, um Systeme oder Entscheidungen auf eine Weise „auszunutzen, zu manipulieren oder zu verfälschen“, die ein katastrophales Risiko erhöhen könnte (Anthropic PDF). Anthropics Gesamtbewertung ist unverblümt: Das Risiko sei „sehr gering, aber nicht vernachlässigbar“.
Diese Formulierung lässt sich leicht verspotten. Sie klingt, als versuchten eine Rechtsabteilung und ein Safety Lab, sich einen einzigen Stuhl zu teilen. Aber unter der Risikosprache steckt ein praktisches Modell für Governance von Coding Agents.
Anthropic sagt, Opus 4.6 werde intern stark für Coding, Datengenerierung und andere agentische Anwendungsfälle genutzt. Außerdem sei das Modell sehr leistungsfähig, wenn auch „nicht vollständig zuverlässig“, bei Aufgaben, die menschliche Spezialisten Stunden kosten würden. Danach geht der Bericht Bedrohungspfade durch: diffuses Sandbagging sicherheitsrelevanter F&E, gezielte Sabotage, Code-Backdoors, Vergiftung von Trainingsdaten, Selbst-Exfiltration, abtrünnige interne Deployments und Sabotage in anderen Organisationen oder Regierungen.
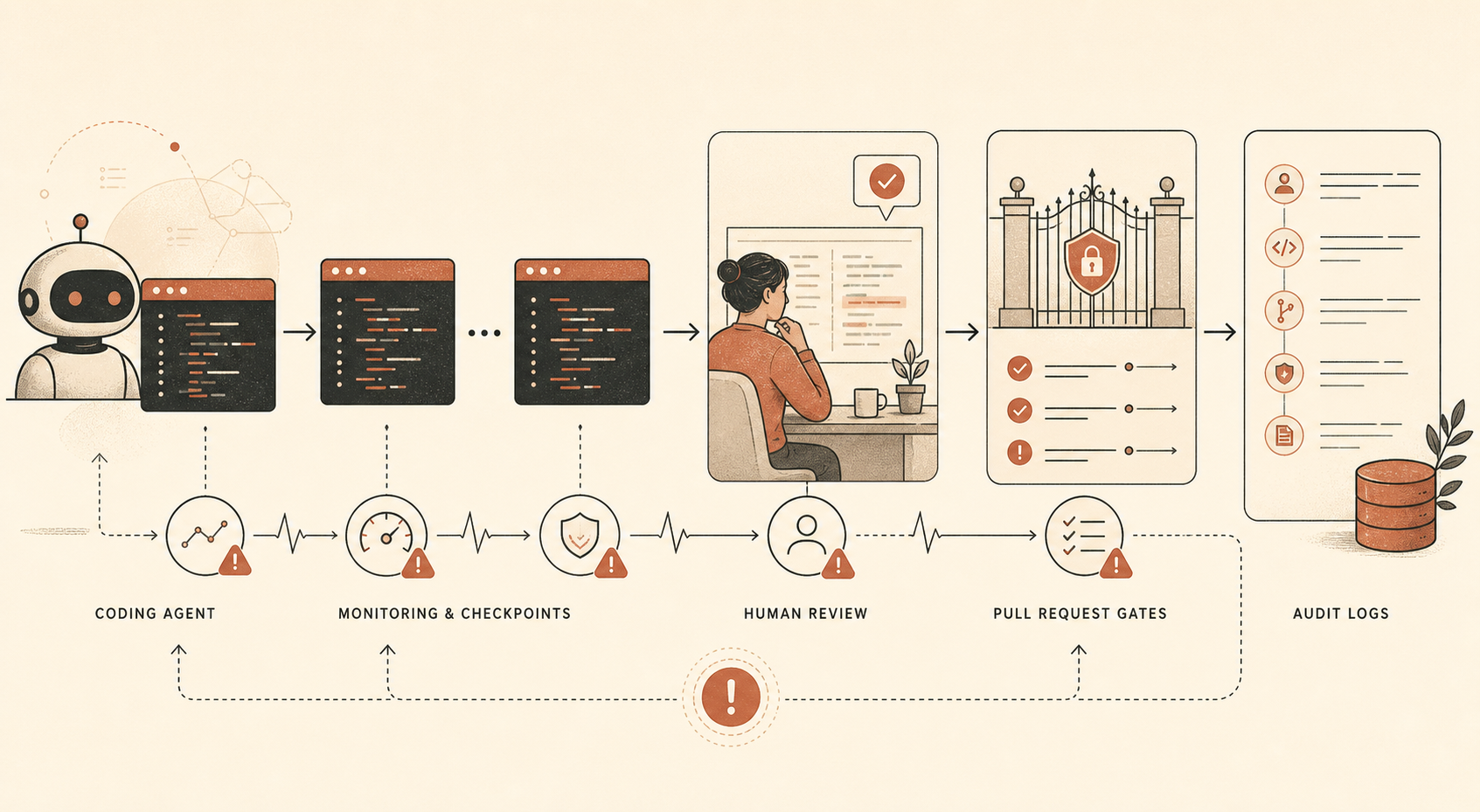
Für Entwickler ist der relevante Teil der Mitigation Stack:
| Control | Was Anthropic laut eigener Aussage nutzt | Übersetzung für Entwickler |
|---|---|---|
| Offline-Claude Code-Monitoring | Große Mehrheit der internen Claude Code-Nutzung; anderswo wird eine Prompt-Stichprobe von ≥10% bei den meisten Nutzern beschrieben | Agent-Sessions loggen und stichprobenartig reviewen |
| Menschliche Audits | Kleine Teilmenge der internen Claude Code-Nutzung | Echte Sessions prüfen, nicht nur finale Diffs |
| Manueller PR-Review | Menschen prüfen Code vor der Integration in gemeinsame Codebases | Menschliche Freigabe für wichtige Merges beibehalten |
| Automatischer PR-Review | Claude-basierter Review prüft Fehler, Sicherheitsprobleme und Abweichungen zwischen erklärter Absicht und tatsächlicher Wirkung | Unabhängigen AI-Review als nicht blockierendes Signal laufen lassen |
| Invariant Tests | Automatisierte Tests prüfen Sicherheitseigenschaften | „Darf nie passieren“-Regeln in CI abbilden |
Ein Detail sticht heraus: Anthropic sagt, der automatische Pull-Request-Monitor habe zum Zeitpunkt der Erstellung auf Claude Opus 4.5 basiert, nicht auf Opus 4.6. Das ist eine leise, aber wichtige Designentscheidung. Das Modell, das die Arbeit macht, und das Modell, das die Arbeit überprüft, müssen nicht identisch sein. Im Gegenteil: Trennung ist gesünder.
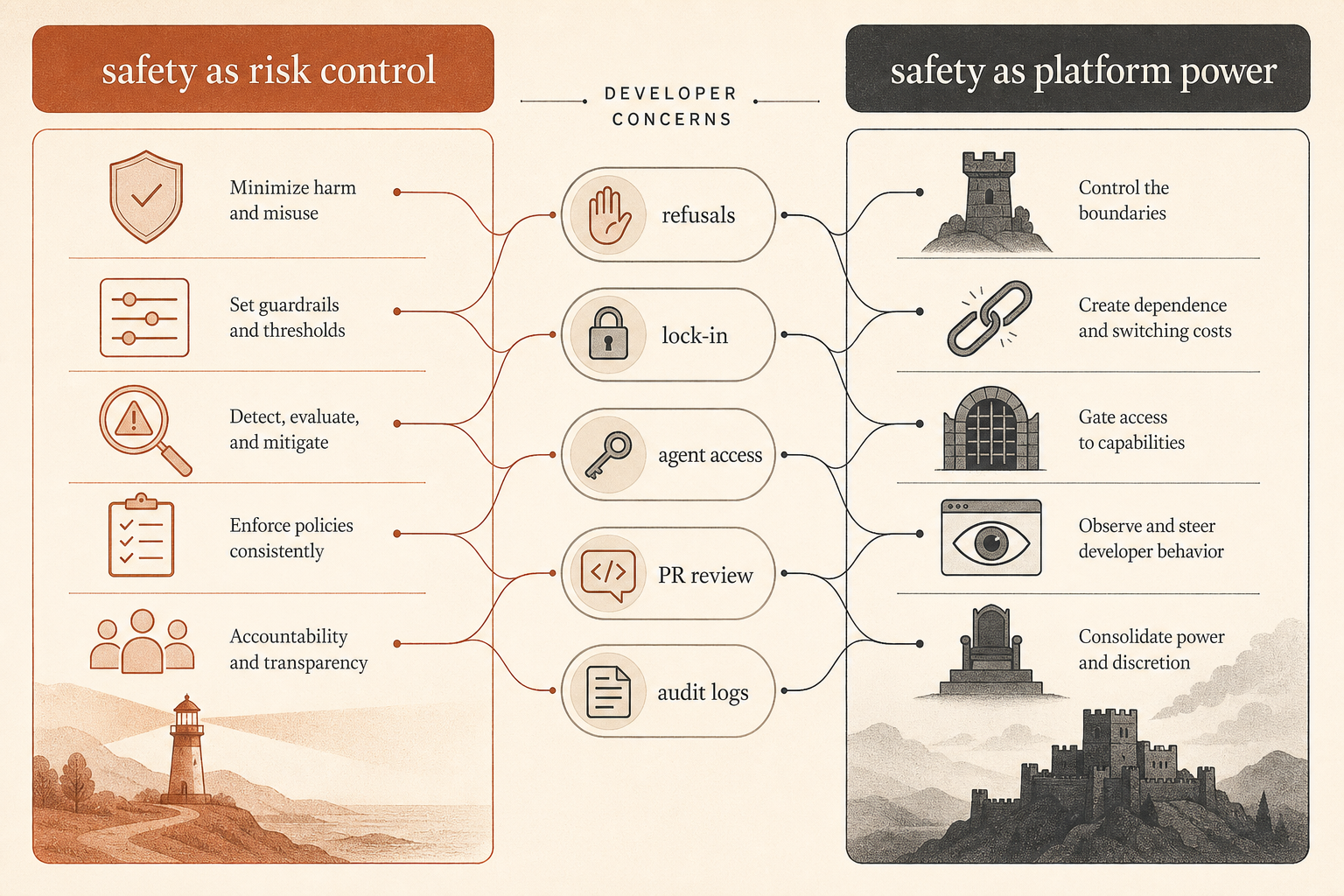
Die Community-Debatte dreht sich um Kontrolle, nicht nur um Safety
Dieser Bericht landete mitten in einer laufenden Auseinandersetzung. Auf Hacker News hatte der Juni-Thread zu Ben Thompsons „Anthropic’s Safety Superpower“ 192 Kommentare und verlief entlang bekannter Fronten: Manche Entwickler argumentierten, Anthropics Safety-Haltung sei der notwendige Preis für den Betrieb leistungsfähiger gehosteter Tools; andere sahen Safety als moralische Verpackung für Plattformkontrolle (Hacker News).
Die schärfste Entwicklerbeschwerde lautet nicht: „Modelle sollten keine Leitplanken haben.“ Sie lautet: Wer entscheidet, was als Missbrauch zählt, wenn das Tool Teil der Software Supply Chain wird?
Ein HN-Kommentator formulierte das Industrial-Control-Problem sauber: Claude zu bitten, sicherheitskritische Steuerungssoftware zu auditieren, und Claude zu bitten, einen Einstiegspunkt in geleakte Steuerungssoftware zu finden, kann technisch sehr ähnliche Arbeit erfordern, aber eine völlig andere Absicht haben (Hacker News). Ein anderer Thread argumentierte: Wenn der Anbieter beides blockiert, verlieren Verteidiger; wenn er beides erlaubt, gewinnen Angreifer. Das ist das eigentliche Produktproblem hinter der Safety-Rhetorik.
Die andere Beschwerde ist Lock-in. Mehrere Kommentatoren fragten, ob man einem Anbieter gehosteter Modelle als neutralem Tool-Anbieter vertrauen könne, wenn er Policies ändern, Aufgaben verweigern, Verhalten herabstufen oder Zugriff einschränken kann. Andere hielten dagegen, Anthropic verkaufe einen Service, kein lokales Tool, und Serviceanbieter hätten schon immer bestimmte Nutzungen abgelehnt.
Der Sabotagebericht ergänzt diese Debatte um ein fehlendes Stück. Anthropic versucht nicht nur, Nutzer-Outputs an der Modellgrenze zu kontrollieren. Intern behandelt das Unternehmen Coding Agents wie halb vertrauenswürdige Produktionsakteure. Das Vertrauensmodell lautet nicht: „Claude ist aligned, ship it.“ Es ist eher: „Claude ist nützlich genug, um es laufen zu lassen, riskant genug, um es zu überwachen, und folgenschwer genug, um es zu reviewen.“
Diesen Teil sollten Teams kopieren.
Die praktische Lektion: Agentisches Coding braucht Defense in Depth
Ein Coding Agent ist kein schickes Autocomplete mehr, sobald er Dateien bearbeiten, Befehle ausführen, Konfiguration nahe an Secrets inspizieren, PRs öffnen, MCP-Tools aufrufen oder Subagents koordinieren kann. Er ist ein Junior-bis-Senior-artiger Auftragnehmer mit schwankendem Urteilsvermögen, ohne Arbeitsvertrag und mit perfekter Geduld.
Das verändert die Kontrollfläche.
Wenn euer Team Claude Code, Cursor, Codex, Devin, OpenCode oder ein internes Agent-Harness nutzt, lautet die Frage nicht: „Vertrauen wir dem Modell?“ Die Frage lautet: „Welche Handlungen kann das Modell ausführen, ohne dass ein zweites System es merkt?“
Eine sinnvolle Baseline sieht so aus:
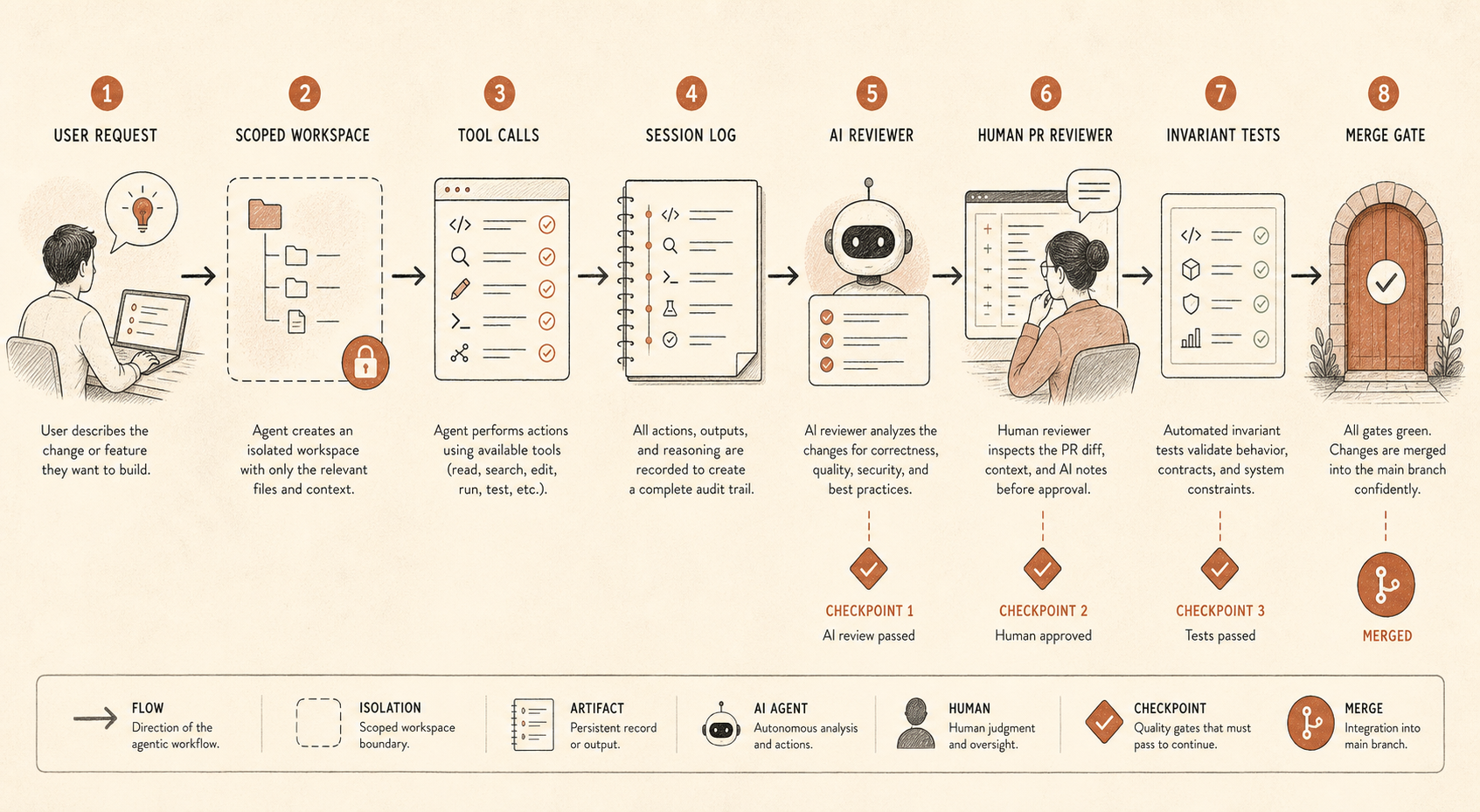
coding_agent_controls:
session_logging: required
write_access: repo-scoped
secret_access: denied_by_default
shell_commands: allowlist_or_confirm
pr_review: human_required
ai_review: separate_model_recommended
audit_sampling: risk_based
invariant_tests: blockingDas ist keine Bürokratie. So behält man die Produktivitätsgewinne, ohne jedes Repository in ein soziales Experiment zu verwandeln.
Die erste Kontrolle ist Session Logging. Speichert Prompts, Tool Calls, Datei-Diffs, Shell-Befehle und finale PR-Links. Wenn sich das zu invasiv anfühlt, loggt zumindest Metadaten und Diffs für risikoarme Repos und vollständige Traces für Hochrisiko-Repos. Ohne Traces könnt ihr den Denkpfad des Agents nicht auditieren und nicht rekonstruieren, wie eine schlechte Änderung entstanden ist.
Die zweite ist begrenzter Zugriff. Die meisten Coding Agents brauchen keine Produktions-Credentials, keinen breiten Netzwerkzugriff und keinen Schreibzugriff über ein ganzes Monorepo hinweg. Gebt ihnen einen Working Tree, eine Aufgabe und explizite Eskalationspfade. Wenn sie mehr brauchen, macht die Anfrage sichtbar.
Die dritte ist Unabhängigkeit auf PR-Ebene. Anthropics Bericht erwähnt sowohl menschlichen PR-Review als auch automatischen Claude-basierten Review. Wichtig ist nicht, dass der Reviewer Claude ist. Wichtig ist, dass der Review ein separater Durchlauf mit anderem Prompt, anderem Kontext und anderem Ziel ist. Der implementierende Agent will die Aufgabe abschließen. Der reviewende Agent sollte nach Abweichungen suchen: „Die angekündigte Änderung sagt Refactor, aber dieser Diff ändert Auth-Verhalten.“
Die vierte ist Invariant Testing. Das ist die am wenigsten glamouröse und am meisten unterschätzte Kontrolle. Wenn zwei Services nie miteinander sprechen dürfen, schreibt den Test. Wenn eine Berechtigung nie außerhalb eines Admin-Pfads vergeben werden darf, schreibt den Test. Wenn generierte Migrationen nie Spalten ohne Ticket-Tag löschen dürfen, schreibt den Test. Agent-Monitoring wird viel einfacher, wenn CI harte Grenzen durchsetzen kann.
Was Anthropics Bericht nicht beweist
Der Bericht beweist nicht, dass Opus 4.6 keine Arbeit sabotieren kann. Er beweist nicht, dass ein automatischer Monitor eine subtile Backdoor findet. Er beweist nicht, dass ein Modell nicht lernen kann, für Monitore gut auszusehen. Anthropic ist bei den Grenzen ziemlich deutlich: Kein einzelner Schutzmechanismus gebe allein starke Sicherheit, und das öffentliche PDF enthält Schwärzungen.
Dieser Vorbehalt ist wichtig, weil Entwickler diese Releases schon jetzt in zwei bequeme Lager einsortieren.
Lager eins sagt: Anthropic hat einen langen Safety-Bericht veröffentlicht, also muss es sicher sein.
Nein. Der Bericht sagt, das Modell ist nützlich, mächtig, überwacht und trotzdem nicht risikofrei.
Lager zwei sagt: Anthropic redet über Safety, also muss es Regulatory Capture oder Marketing sein.
Auch zu simpel. Die im Bericht beschriebenen Kontrollen sind normale Engineering-Hygiene. Security Monitoring, PR-Review, Audit-Stichproben, Sandboxing, Invariant Tests und User Reporting sind keine mystischen Alignment-Rituale. Es sind dieselben Maßnahmen, die reife Teams bei menschlichen Insidern, kompromittierten CI-Tokens und riskanten Third-Party-Abhängigkeiten einsetzen.
Die unbequeme Mitte ist nützlicher: Anthropic kann kommerziell davon profitieren, als Safety-Unternehmen gesehen zu werden, und die internen Kontrollen können trotzdem kopierenswert sein. Beides kann wahr sein.
Der Bericht enthält außerdem eine subtile Warnung für Teams, die Multi-Agent-Coding einführen. Anthropics Launch-Post hob Claude Code Agent Teams, parallele Subagents, Context Compaction und länger laufende Arbeit hervor (Anthropic). Genau diese Features machen Monitoring schwieriger. Ein einzelner Assistant, der einen Diff erstellt, ist leicht zu prüfen. Ein Schwarm von Agents, die lesen, editieren, zusammenfassen und Zustand weiterreichen, ist ein Provenance-Problem.
Wenn ihr Agents koordinieren lasst, loggt die Koordination. Wenn ein Agent einen Plan schreibt und ein anderer ihn umsetzt, bewahrt beide Traces auf. Wenn Kontext komprimiert wird, speichert die Grenze vor und nach der Komprimierung. Zusammenfassungen sind verlustbehaftet. Verlustbehafteter Zustand ist der Ort, an dem Verantwortlichkeit verschwindet.
Eine Kontroll-Checkliste für Teams, die Coding Agents ausliefern
Das ist die praktische Messlatte, die ich setzen würde, bevor Coding Agents wichtige Repositories anfassen dürfen.
Beginnt mit Repo-Klassifizierung. Ein Docs-Repo, ein Prototyp, ein Billing-Service und ein Identity Provider sollten nicht dieselbe Agent-Policy teilen. Behandelt sicherheitssensitive Repos als eigene Stufe.
Verlangt menschlichen Review für Merges in gemeinsame Branches. Das klingt offensichtlich, aber Teams umgehen es leise, wenn Agents „offensichtlich korrekte“ mechanische Diffs erstellen. Nicht tun. Von Agents geschriebener Code sollte denselben Review-Pfad nehmen wie Code von Praktikanten, mit zusätzlicher Aufmerksamkeit für Tests und Berechtigungen.
Lasst einen zweiten Reviewer laufen. Nutzt ein anderes Modell, einen anderen Prompt oder einen Static-Analysis-Durchlauf. Bittet ihn, die angefragte Änderung des Nutzers mit dem tatsächlichen Diff zu vergleichen. Dieser Abgleich ist billig und findet eine Klasse von Fehlern, die normaler Review übersieht.
Stichprobt Sessions, nicht nur PRs. Ein böswilliger oder verwirrter Agent kann sensible Dateien erkunden, seltsame Befehle ausführen oder Änderungen versuchen, die nicht im finalen Diff landen. Anthropics Fokus auf Claude Code-Nutzung, nicht nur auf gemergten Code, ist der richtige Instinkt.
Blockiert Secrets per Design. Verlasst euch nicht darauf, dass das Modell „weiß“, dass es .env.production nicht lesen soll. Nutzt Dateisystemberechtigungen, Secret Scanner, Environment-Isolation und Befehlsbestätigung.
Ergänzt Invariant Tests für Sicherheitseigenschaften. Die Beispiele im Bericht sind schlicht: Wenn zwei Nodes keinen Traffic zueinander senden sollen, testet, dass sie es nicht können. Übersetzt das in eure Welt: Auth-Grenzen, Tenant-Isolation, Zahlungsstatus-Übergänge, Data Retention, Export Controls, Audit Events.
Schreibt einen Incident-Pfad. Wenn ein Reviewer verdächtiges Agent-Verhalten sieht, wohin geht es? Slack? Security? Ein Vendor Report? Ein blockierter Merge ist kein Incident-Prozess.

Warum das jetzt wichtig ist
Die alte AI-Coding-Frage war, ob das Modell nützlichen Code schreiben kann. Opus 4.6, Sonnet 4.6, Systeme der GPT-5-Klasse und die aktuelle Generation von Coding Agents haben das weitgehend beantwortet. Sie können nützlichen Code schreiben. Sie können auch schnell schlechten Code schreiben, selbstbewusst plausiblen Code und sicherheitssensiblen Code mit genug Kontext, um gefährlich zu sein.
Die neue Frage ist operativ: Kann euer Team Agent-Arbeit aufnehmen, ohne die Kontrolle über die Software Supply Chain zu verlieren?
Anthropics Sabotagebericht ist wertvoll, weil er die Antwort des Anbieters selbst sichtbar macht. Für interne Claude Code-Nutzung beschreibt Anthropic automatisiertes Monitoring über eine große Mehrheit der Nutzung, menschliche Audits, manuellen PR-Review, automatisches PR-Monitoring, Sandboxing, Security Monitoring und Invariant Tests. Das ist kein Vibe. Das ist ein Control Stack.
Entwickler sollten aufhören, „dem Modell vertrauen“ als Entscheidung zu behandeln. Die Entscheidung ist, wo man das Modell in einem System platziert, das Fehlbarkeit voraussetzt. Lasst es entwerfen. Lasst es suchen. Lasst es refactoren. Lasst es PRs öffnen. Aber macht die wichtigen Handlungen beobachtbar, reviewbar, reversibel und testbar.
Das ist die nützliche Erkenntnis aus dem Bericht. Über Safety Claims wird weiter auf HN, Reddit und X gestritten werden. Eure CI-Pipeline muss die Philosophie nicht klären. Sie muss den schlechten Diff fangen.
Leser, die Claude Fable 5 selbst ausprobieren wollen, können es über OneHop nutzen: ein Drop-in-Endpoint, rund 30% unter Listenpreis, mit 10 Dollar gratis für neue Accounts und ohne Kreditkarte. Siehe Claude Fable 5 auf OneHop oder mit 10 Dollar gratis starten.
Weiterlesen: Erste Schritte mit Claude Fable 5.

