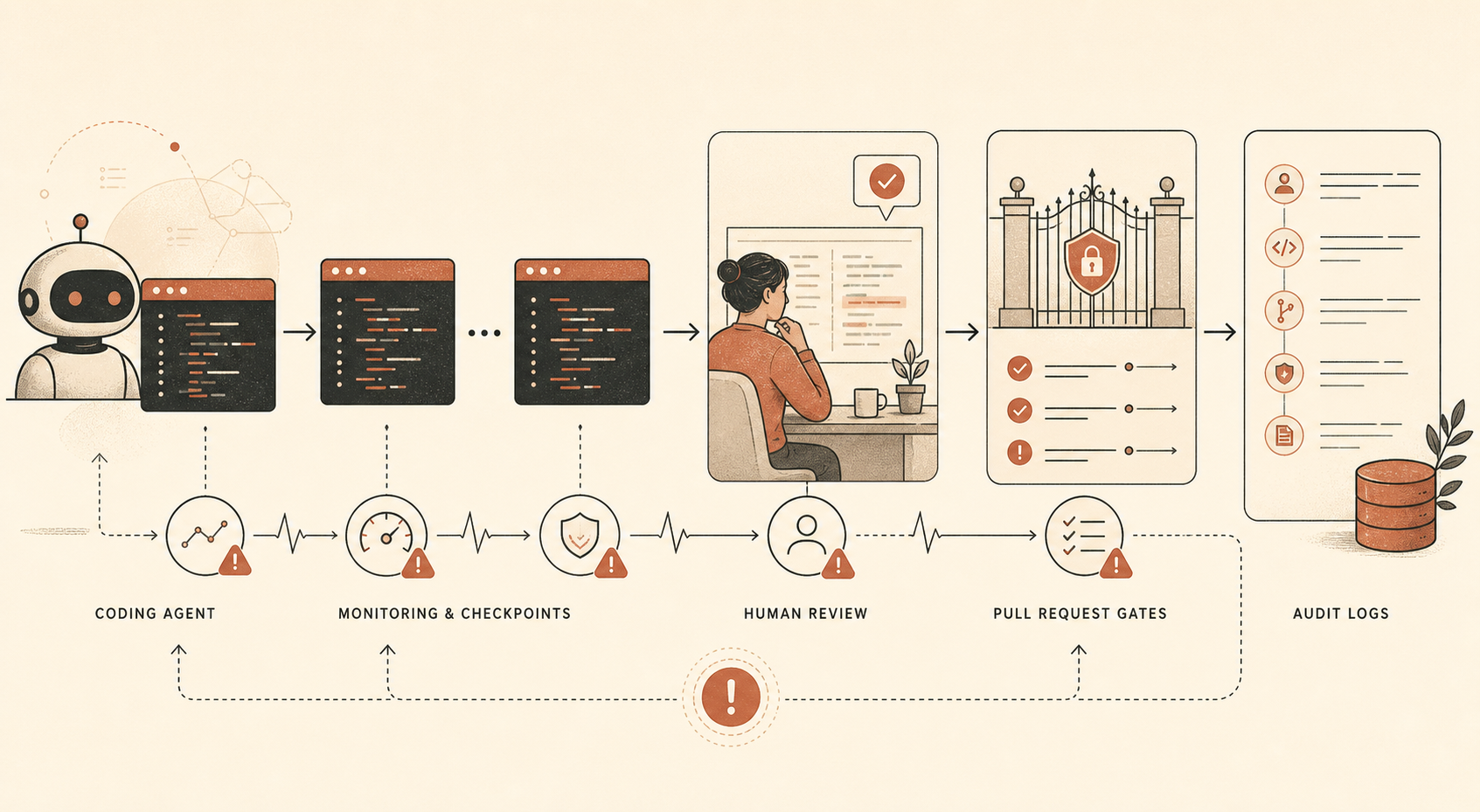
Anthropicが公開したClaude Opus 4.6向けの新しいサボタージュリスク報告書には、コーディングエージェントを導入するすべてのエンジニアリングリードが二度読むべき一文がある。同社は、Opus 4.6に「直接的で重大な行動を取る能力」を与える社内ツールがClaude Codeであるため、社内のClaude Code利用の「大多数」に自動監視をかけ、さらにその一部を人間が監査している、というのだ(Anthropic PDF)。
これこそがニュースだ。Opus 4.6は安全だ、というスローガンではない。Anthropicだけがアラインメントに本気だ、という主張でもない。具体的な運用上の事実は、Anthropicでさえ、自社最強モデルに広範な社内コーディング権限を任せるときには、作業をログ化し、サンプリングし、監査し、レビューし、通常のセキュリティ統制で支えているように見える、ということだ。
これが重要なのは、Claude Opus 4.6が2026年2月5日に、当時のAnthropicで最も賢いモデルとしてローンチされたからだ。ベータ版で100万トークンのコンテキストウィンドウ、より強いエージェント型コーディング、claude-opus-4-6というAPI名、そして標準価格は入力100万トークンあたり5ドル、出力100万トークンあたり25ドルのまま、という内容だった(Anthropic)。Anthropicはまた、このモデルがTerminal-Bench 2.0やHumanity’s Last Examを含む複数のベンチマークで首位に立ち、GDPval-AAではGPT-5.2を約144 Eloポイント上回ったとも述べている。同じローンチ記事で、Anthropicは長時間動くエージェント、コンテキスト圧縮、努力量の制御、Claude Codeのエージェントチームを強く打ち出していた。
つまり、この報告書は机上の話ではない。同じ種類のエージェントが自社のエンジニアリングループに入ったとき、ベンダー自身が何をしているかを見せている。
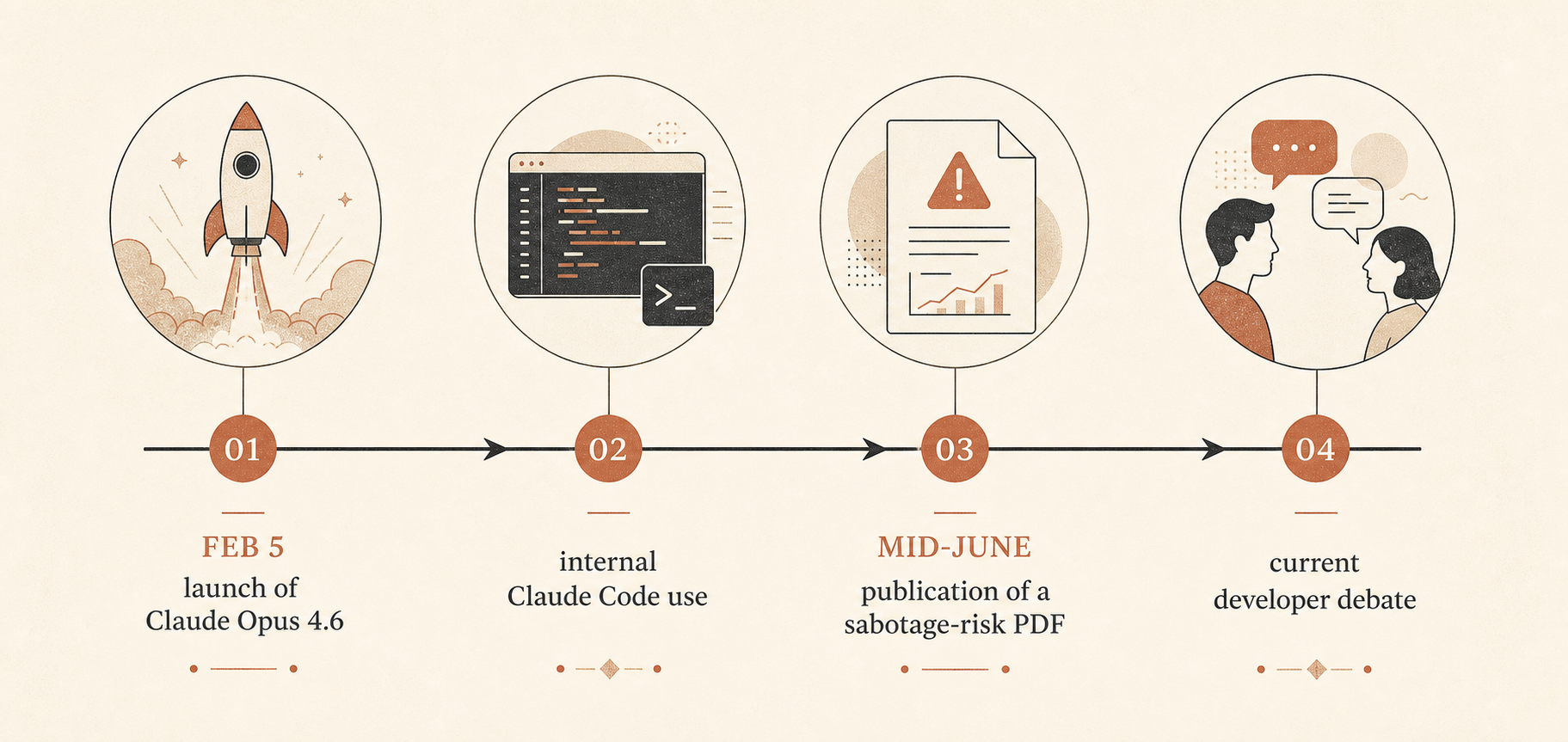
Anthropicが実際に公開したもの
53ページのPDFのタイトルは「Sabotage Risk Report: Claude Opus 4.6」だ。そこではサボタージュを、AIモデルが組織内のアクセス権を使ってシステムや意思決定を「悪用、操作、改ざん」し、壊滅的リスクを高めうる行為として定義している(Anthropic PDF)。Anthropicの総合評価は率直だ。リスクは「非常に低いが、無視できるわけではない」。
この表現は茶化しやすい。法務部門と安全性研究所が一つの椅子を取り合っているように聞こえる。しかしそのリスク文言の下には、コーディングエージェントのガバナンスに関する実用的なモデルが埋まっている。
Anthropicによれば、Opus 4.6は社内でコーディング、データ生成、その他のエージェント型ユースケースに広く使われている。同時に、このモデルは高性能だが、人間の専門家なら数時間かかるようなタスクで「完全に信頼できるわけではない」とも述べている。報告書はそのうえで、安全性に関わるR&Dの広範な手抜き、標的型サボタージュ、コードのバックドア、学習データの汚染、自己流出、不正な社内デプロイ、他組織や政府でのサボタージュといった脅威経路を順に見ていく。
開発者にとって重要なのは、その緩和策の積み重ねだ。
| 統制 | Anthropicが使っていると述べているもの | 開発者向けの翻訳 |
|---|---|---|
| オフラインのClaude Code監視 | 社内Claude Code利用の大多数。別箇所では、ほとんどのユーザーから10%以上のプロンプトをサブサンプルすると説明 | エージェントセッションをログ化し、サンプリングしてレビューする |
| 人間による監査 | 社内Claude Code利用の小さな一部 | 最終diffだけでなく、実際のセッションをレビューする |
| 手動PRレビュー | 共有コードベースに統合する前に人間がコードをレビュー | 重要なマージには人間の承認を残す |
| 自動PRレビュー | Claudeベースのレビューが、エラー、セキュリティ問題、表明された意図と実際の影響の不一致をチェック | 独立したAIレビューを非ブロッキングなシグナルとして走らせる |
| 不変条件テスト | 自動テストがセキュリティ性質をチェック | 「絶対に起きてはいけない」ルールをCIに埋め込む |
ひとつ目立つ点がある。Anthropicは、自動プルリクエスト監視が執筆時点でClaude Opus 4.5をベースにしており、Opus 4.6ではなかったと述べている。控えめだが重要な設計判断だ。作業するモデルと、その作業をレビューするモデルが同一である必要はない。むしろ、分離されているほうが健全だ。
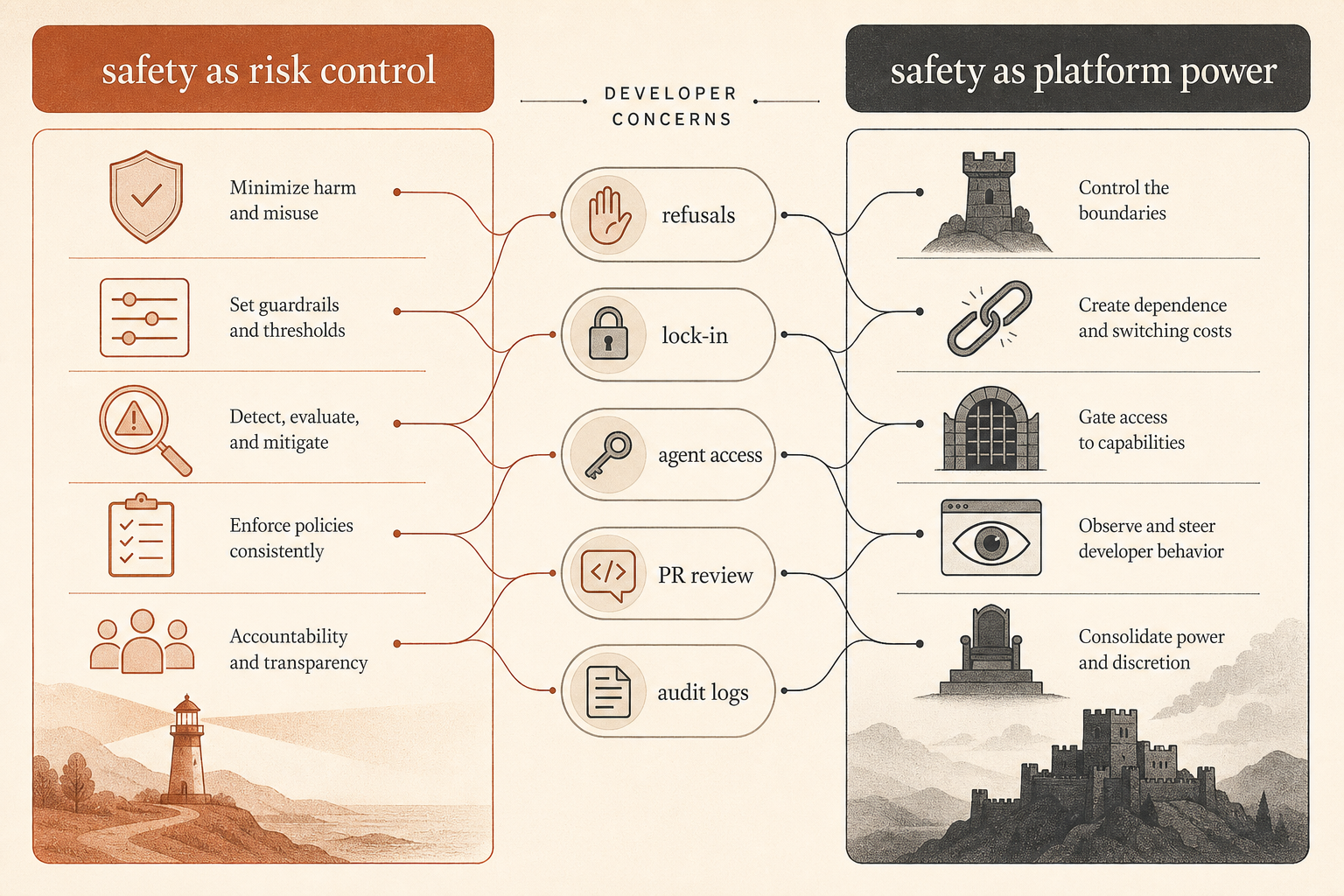
コミュニティの論点は安全性だけでなく、統制だ
この報告書は、すでに進行中だった議論のど真ん中に投げ込まれた。Hacker Newsでは、Ben Thompsonの「Anthropic’s Safety Superpower」をめぐる6月のスレッドに192件のコメントが付き、いつもの線で割れた。ある開発者たちは、Anthropicの安全性重視は強力なホステッドツールを展開するために必要なコストだと主張した。一方で、安全性はプラットフォーム支配を正当化する道徳的な包装だと見る人たちもいた(Hacker News)。
開発者から出ている最も鋭い不満は、「モデルにガードレールなど不要だ」ではない。それは、ツールがソフトウェアサプライチェーンの一部になりつつあるとき、何が不正利用に当たるのかを誰が決めるのか、という問いだ。
あるHNコメント投稿者は、産業制御の問題をきれいに言い表した。Claudeに安全性が重要な制御ソフトウェアを監査させることと、流出した制御ソフトウェアへの侵入口を探させることは、技術的には似た作業を必要とするかもしれない。しかし意図はまったく違う(Hacker News)。別のスレッドでは、プロバイダーが両方をブロックすれば防御側が損をし、両方を許可すれば攻撃側が得をする、という議論があった。安全性レトリックの背後にある本当のプロダクト問題はそこだ。
もうひとつの不満はロックインだ。ホステッドモデルのベンダーが、ポリシーを変えたり、タスクを拒否したり、挙動を劣化させたり、アクセスを制限したりできるなら、中立的なツール提供者として信頼できるのか、と複数のコメント投稿者が疑問を呈した。一方で、Anthropicが売っているのはローカルツールではなくサービスであり、サービス提供者が一部の利用を拒否するのは昔からあることだ、という反論もあった。
サボタージュ報告書は、この議論に欠けていたピースを加える。Anthropicはモデル境界でユーザー出力を制御しようとしているだけではない。社内では、コーディングエージェントを半信頼の本番アクターとして扱っている。信頼モデルは「Claudeはアラインしている、出荷しよう」ではない。むしろ「Claudeは動かすだけの有用性があり、監視するだけのリスクがあり、レビューするだけの重大性がある」に近い。
チームが真似すべきなのはそこだ。
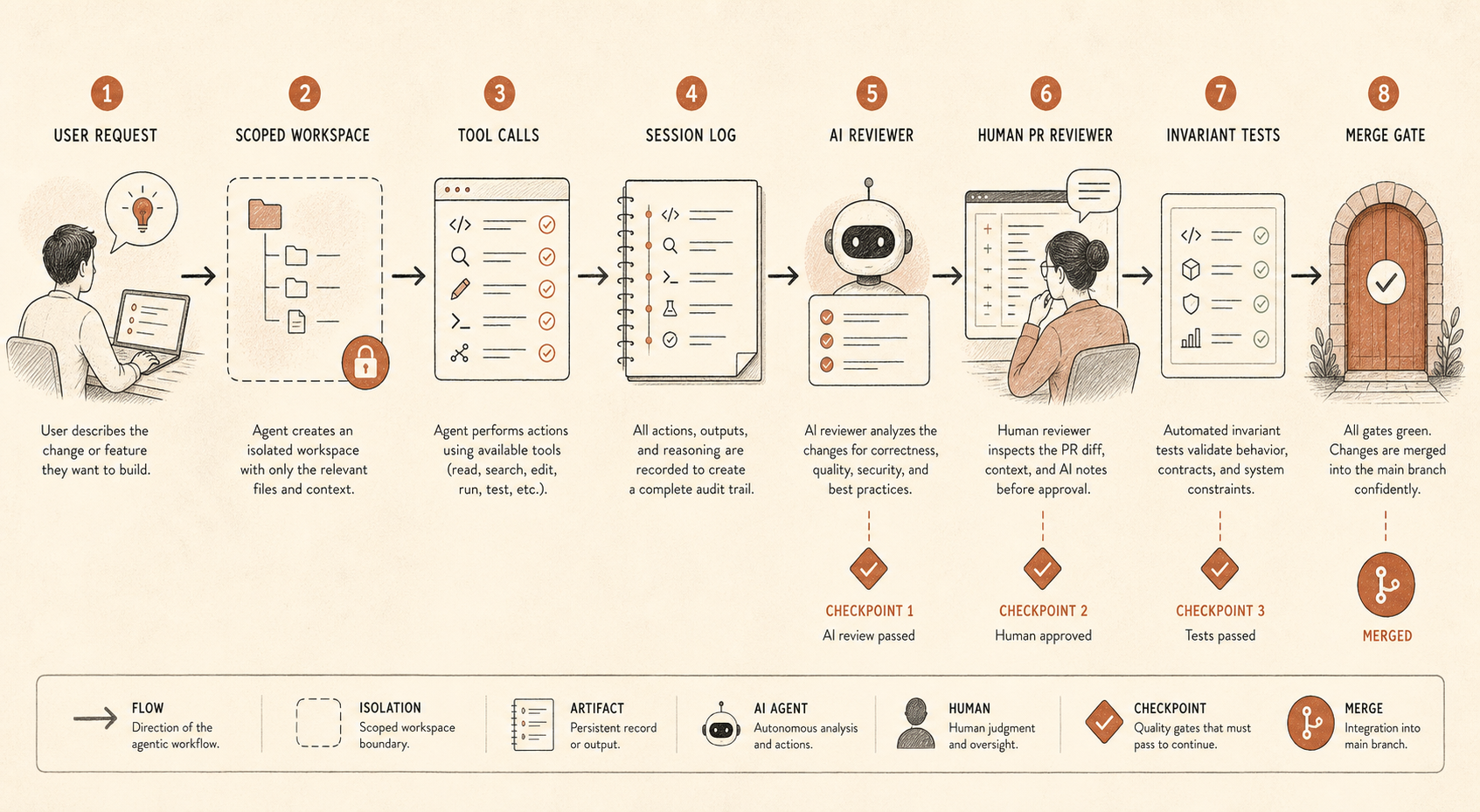
実践的な教訓:エージェント型コーディングには多層防御が必要だ
コーディングエージェントは、ファイルを編集し、コマンドを実行し、シークレットに近い設定を調べ、PRを開き、MCPツールを呼び、サブエージェントを調整できるようになった時点で、ただの高性能なオートコンプリートではない。それは判断力にばらつきがあり、雇用契約がなく、完璧な忍耐力を持つ、ジュニアからシニア寄りの請負人だ。
そうなると、統制すべき面が変わる。
あなたのチームがClaude Code、Cursor、Codex、Devin、OpenCode、あるいは社内エージェントハーネスを使っているなら、問うべきは「モデルを信頼するか」ではない。「第二のシステムに気づかれずに、モデルはどんな行動を取れるのか」だ。
妥当なベースラインはこうなる。
coding_agent_controls:
session_logging: required
write_access: repo-scoped
secret_access: denied_by_default
shell_commands: allowlist_or_confirm
pr_review: human_required
ai_review: separate_model_recommended
audit_sampling: risk_based
invariant_tests: blockingこれは官僚主義ではない。すべてのリポジトリを社会実験に変えずに、生産性向上を取り込むためのやり方だ。
最初の統制はセッションログだ。プロンプト、ツール呼び出し、ファイルdiff、シェルコマンド、最終PRリンクを保存する。侵襲的すぎると感じるなら、低リスクのリポジトリでは少なくともメタデータとdiffを記録し、高リスクのリポジトリでは完全なトレースを残す。トレースがなければ、エージェントの推論経路を監査できず、悪い変更がどう起きたのかを再構成できない。
二つ目はアクセス範囲の制限だ。ほとんどのコーディングエージェントに、本番認証情報、広範なネットワークアクセス、モノレポ全体への書き込み権限は必要ない。作業ツリー、タスク、明示的なエスカレーション経路を与えればいい。さらに必要なら、そのリクエストを見えるようにする。
三つ目はPRレベルでの独立性だ。Anthropicの報告書は、人間によるPRレビューとClaudeベースの自動レビューの両方に触れている。重要なのは、レビュアーがClaudeであることではない。重要なのは、レビューが別のプロンプト、別のコンテキスト、別の目的を持つ独立したパスであることだ。実装エージェントはタスクを完了したがる。レビューエージェントは不一致を探すべきだ。「表明された変更はリファクタリングだが、このdiffは認可の挙動を変えている」といった具合に。
四つ目は不変条件テストだ。これは最も地味で、最も過小評価されている統制だ。二つのサービスが絶対に通信してはいけないなら、そのテストを書く。ある権限が管理者パス以外で絶対に付与されてはいけないなら、そのテストを書く。生成されたマイグレーションがチケットタグなしにカラムを削除してはいけないなら、そのテストを書く。CIが硬い境界を強制できると、エージェント監視はずっと楽になる。
Anthropicの報告書が証明していないこと
この報告書は、Opus 4.6が作業をサボタージュできないことを証明してはいない。自動モニターが巧妙なバックドアを検出できることも証明していない。モデルがモニターに対して見栄えよく振る舞うことを学習できない、という証明でもない。Anthropicは制約についてかなり明示的だ。単独で強い保証を与えるセーフガードは存在しないと述べており、公開PDFには墨消しも含まれている。
この但し書きが重要なのは、開発者たちがすでにこうしたリリースを二つの怠惰な陣営に当てはめ始めているからだ。
陣営その一はこう言う。Anthropicが長い安全性報告書を出したのだから、安全に違いない。
違う。報告書が言っているのは、このモデルは有用で、強力で、監視されていて、それでもリスクゼロではない、ということだ。
陣営その二はこう言う。Anthropicが安全性を語るのだから、規制の取り込みかマーケティングに違いない。
これも単純すぎる。報告書に書かれている統制は、普通のエンジニアリング衛生だ。セキュリティ監視、PRレビュー、監査サンプリング、サンドボックス化、不変条件テスト、ユーザー報告は、神秘的なアラインメント儀式ではない。成熟したチームが人間の内部者、侵害されたCIトークン、リスクのあるサードパーティ依存関係に対して使うのと同じ手だ。
居心地の悪い中間のほうが役に立つ。Anthropicは安全性の会社として見られることで商業的利益を得ているかもしれないし、それでも同社の内部統制は真似する価値があるかもしれない。その二つは両立する。
この報告書には、マルチエージェントコーディングを導入するチームへのさりげない警告もある。Anthropicのローンチ記事は、Claude Codeのエージェントチーム、並列サブエージェント、コンテキスト圧縮、長時間実行される作業を強調していた(Anthropic)。監視が難しくなるのは、まさにそうした機能だ。一人のアシスタントが一つのdiffを作るだけなら、検査は簡単だ。複数のエージェントが読み、編集し、要約し、状態を引き継ぐ群れになると、来歴の問題になる。
エージェント同士を連携させるなら、その連携をログに残す。一つのエージェントが計画を書き、別のエージェントが実装するなら、両方のトレースを保存する。コンテキストが圧縮されるなら、圧縮前と圧縮後の境界を保存する。要約は損失を伴う。損失のある状態こそ、説明責任が消える場所だ。
コーディングエージェントを出荷するチームのための統制チェックリスト
重要なリポジトリにコーディングエージェントを触らせる前に、私ならこの実用的な基準を置く。
まずリポジトリを分類する。ドキュメント用リポジトリ、プロトタイプ、課金サービス、IDプロバイダーを同じエージェントポリシーで扱うべきではない。セキュリティ上重要なリポジトリは別階層として扱う。
共有ブランチへのマージには人間のレビューを必須にする。当たり前に聞こえるが、エージェントが「明らかに正しい」機械的なdiffを作ると、チームは静かにこれを迂回しがちだ。やめたほうがいい。エージェントが書いたコードは、インターンが書いたコードと同じレビューパスを通すべきであり、テストと権限には追加の注意を払うべきだ。
第二のレビュアーを走らせる。別のモデル、別のプロンプト、あるいは静的解析パスを使う。ユーザーが求めた変更と実際のdiffを比較させる。この不一致チェックは安く、通常のレビューが見逃すタイプの失敗を捕まえる。
PRだけでなくセッションをサンプリングする。悪意のある、あるいは混乱したエージェントは、機密ファイルを探ったり、奇妙なコマンドを実行したり、最終diffには残らない変更を試みたりするかもしれない。マージ済みコードだけでなくClaude Code利用そのものに注目するAnthropicの本能は正しい。
シークレットは設計でブロックする。モデルが.env.productionを読んではいけないと「理解している」ことに頼らない。ファイルシステム権限、シークレットスキャナー、環境分離、コマンド確認を使う。
セキュリティ性質の不変条件テストを追加する。報告書の例は素朴だ。二つのノードが互いにトラフィックを送るべきでないなら、送れないことをテストする。これを自分たちの世界に置き換える。認可境界、テナント分離、支払い状態遷移、データ保持、輸出規制、監査イベント。
インシデント経路を書く。レビュアーが怪しいエージェント挙動を見つけたら、どこへ行くのか。Slackか。セキュリティチームか。ベンダー報告か。マージをブロックすることは、インシデントプロセスではない。

なぜ今これが重要なのか
昔のAIコーディングの問いは、モデルが有用なコードを書けるかどうかだった。Opus 4.6、Sonnet 4.6、GPT-5級のシステム、そして現在のコーディングエージェント群は、その問いにはほぼ答えを出した。有用なコードは書ける。同時に、悪いコードを素早く、もっともらしいコードを自信満々に、そして危険になりうるだけのコンテキストを持ってセキュリティ上重要なコードを書くこともできる。
新しい問いは運用上のものだ。あなたのチームは、ソフトウェアサプライチェーンの制御を失わずに、エージェント労働を吸収できるのか。
Anthropicのサボタージュ報告書に価値があるのは、ベンダー自身の答えを見える形にしているからだ。社内のClaude Code利用について、Anthropicは利用の大多数に対する自動監視、人間による監査、手動PRレビュー、自動PR監視、サンドボックス化、セキュリティ監視、不変条件テストを説明している。これは雰囲気ではない。統制スタックだ。
開発者は「モデルを信頼するか」を意思決定として扱うのをやめるべきだ。意思決定すべきなのは、誤りを前提にしたシステムのどこにモデルを置くかだ。下書きさせればいい。検索させればいい。リファクタリングさせればいい。PRを開かせればいい。ただし、重要な行動は観測可能で、レビュー可能で、巻き戻し可能で、テスト可能にしておく。
この報告書から得るべき有用な教訓はそこだ。安全性の主張は、HN、Reddit、Xでこれからも議論され続けるだろう。あなたのCIパイプラインが哲学に決着をつける必要はない。悪いdiffを捕まえればいい。
Claude Fable 5を自分で試したい読者は、OneHop経由で使える。差し替えだけで使えるエンドポイント、定価より約30%安い価格、新規アカウントには10ドル分無料、カード不要だ。OneHopのClaude Fable 5または10ドル無料で始めるを参照してほしい。
さらに読む: Claude Fable 5を始める.

