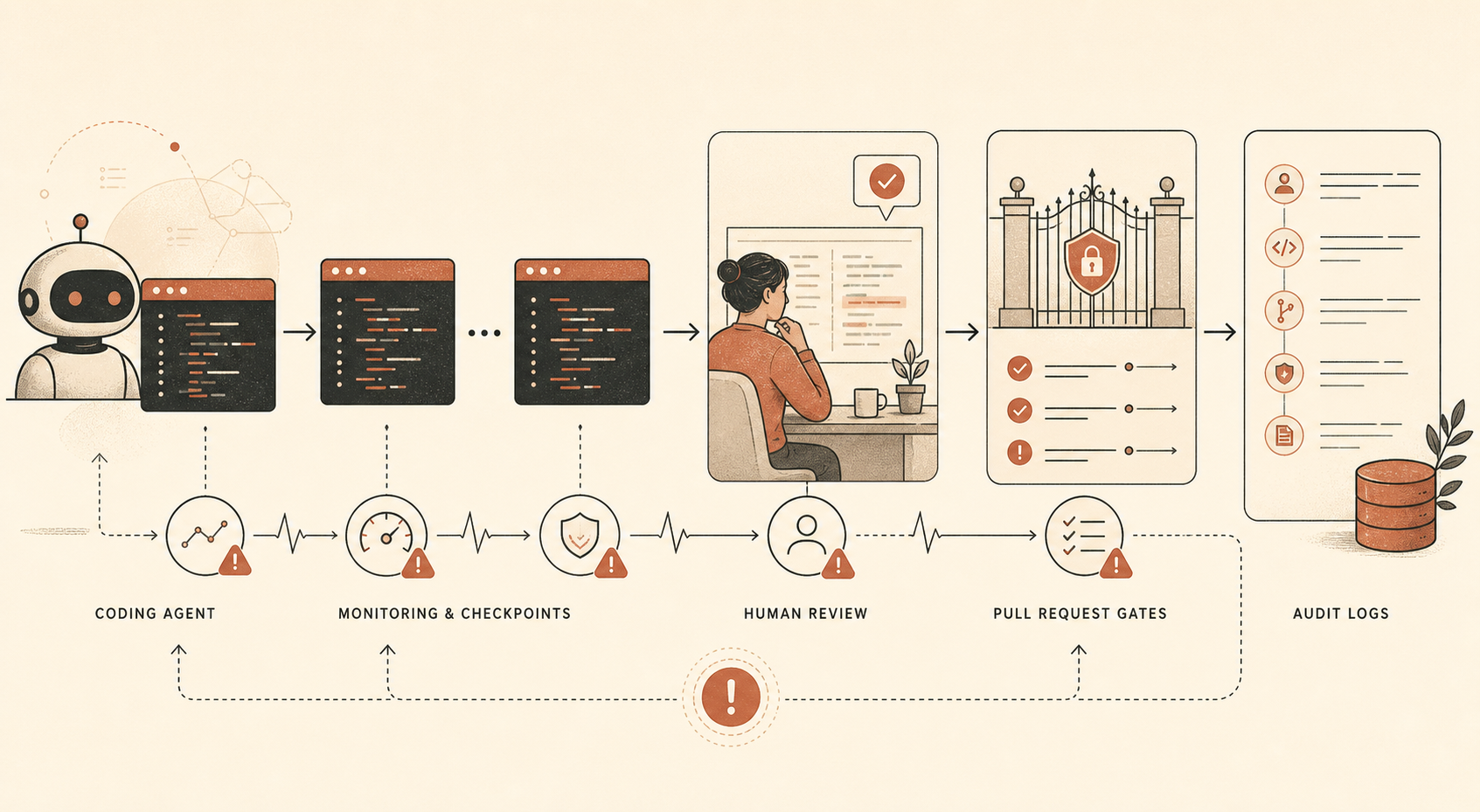
Le nouveau rapport d’Anthropic sur le risque de sabotage de Claude Opus 4.6 contient une phrase que tout responsable engineering en train d’adopter des agents de code devrait lire deux fois : l’entreprise dit utiliser une surveillance automatisée sur « une large majorité » de l’usage interne de Claude Code, en plus d’audits humains sur un sous-ensemble plus réduit, parce que Claude Code est l’outil interne qui donne à Opus 4.6 « la capacité de prendre des actions directes et lourdes de conséquences » (Anthropic PDF).
Voilà l’info. Pas le slogan selon lequel Opus 4.6 serait sûr. Pas l’argument selon lequel Anthropic serait seule à prendre l’alignement au sérieux. Le fait opérationnel concret, c’est qu’Anthropic ne semble pas faire confiance, même à son propre modèle le plus puissant, avec une large autonomie de code en interne, sauf si le travail est journalisé, échantillonné, audité, revu et adossé à des contrôles de sécurité ordinaires.
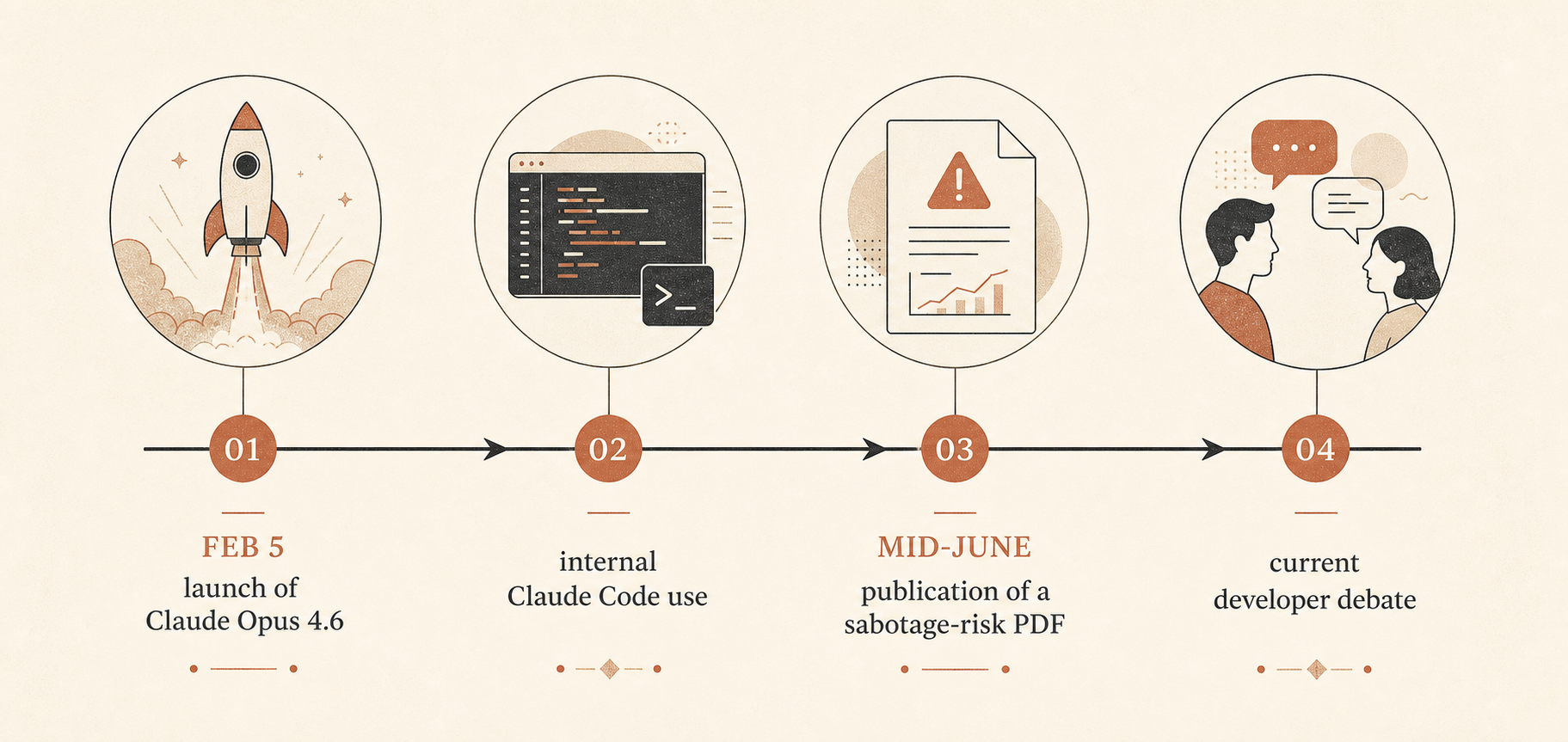
C’est important parce que Claude Opus 4.6 a été lancé le 5 février 2026 comme le modèle alors le plus intelligent d’Anthropic, avec une fenêtre de contexte de 1 million de tokens en bêta, de meilleures capacités de code agentique, un nom d’API claude-opus-4-6, et des tarifs standards inchangés de 5 $ par million de tokens en entrée et 25 $ par million de tokens en sortie (Anthropic). Anthropic a aussi affirmé que le modèle était en tête sur plusieurs benchmarks, dont Terminal-Bench 2.0 et Humanity’s Last Exam, et qu’il battait GPT-5.2 d’environ 144 points Elo sur GDPval-AA. Dans le même billet de lancement, Anthropic insistait lourdement sur les agents longue durée, la compaction de contexte, les contrôles d’effort et les équipes d’agents Claude Code.
Le rapport n’a donc rien de théorique. C’est un aperçu de ce que fait le fournisseur quand la même famille d’agents entre dans sa propre boucle engineering.
Ce qu’Anthropic a réellement publié
Le PDF de 53 pages s’intitule « Sabotage Risk Report: Claude Opus 4.6 ». Il définit le sabotage comme l’utilisation, par un modèle d’IA, d’un accès au sein d’une organisation pour « exploiter, manipuler ou altérer » des systèmes ou des décisions d’une manière susceptible d’accroître un risque catastrophique (Anthropic PDF). L’évaluation globale d’Anthropic est directe : le risque est « très faible mais non négligeable ».
La formule est facile à tourner en ridicule. On dirait qu’un service juridique et un labo de sécurité essaient de partager la même chaise. Mais sous le vocabulaire du risque se cache un modèle pratique de gouvernance des agents de code.
Anthropic dit qu’Opus 4.6 est très utilisé en interne pour le code, la génération de données et d’autres cas d’usage agentiques. Elle dit aussi que le modèle est très capable, bien que « pas totalement fiable », sur des tâches qui prendraient des heures à des spécialistes humains. Le rapport passe ensuite en revue les chemins de menace : sous-performance diffuse sur la R&D liée à la sécurité, sabotage ciblé, portes dérobées dans le code, empoisonnement des données d’entraînement, auto-exfiltration, déploiements internes non autorisés, et sabotage dans d’autres organisations ou gouvernements.
Pour les développeurs, la partie pertinente est la pile de mitigations :
| Contrôle | Ce qu’Anthropic dit utiliser | Traduction pour développeurs |
|---|---|---|
| Surveillance hors ligne de Claude Code | Large majorité de l’usage interne de Claude Code ; ailleurs, un sous-échantillon d’au moins 10 % des prompts par la plupart des utilisateurs est décrit | Journaliser les sessions d’agents et en échantillonner pour revue |
| Audits humains | Petit sous-ensemble de l’usage interne de Claude Code | Revoir les vraies sessions, pas seulement les diffs finaux |
| Revue manuelle des PR | Des humains relisent le code avant intégration dans une base de code partagée | Garder une approbation humaine sur les merges importants |
| Revue automatique des PR | Une revue basée sur Claude vérifie les erreurs, les problèmes de sécurité et les écarts entre l’intention déclarée et les effets réels | Lancer une revue IA indépendante comme signal non bloquant |
| Tests d’invariants | Des tests automatisés vérifient les propriétés de sécurité | Encoder les règles « ne doit jamais arriver » dans la CI |
Un détail ressort : Anthropic dit que son moniteur automatique de pull requests reposait sur Claude Opus 4.5 au moment de la rédaction, pas sur Opus 4.6. C’est un choix discret, mais important. Le modèle qui fait le travail et celui qui le relit n’ont pas besoin d’être identiques. En fait, la séparation est plus saine.
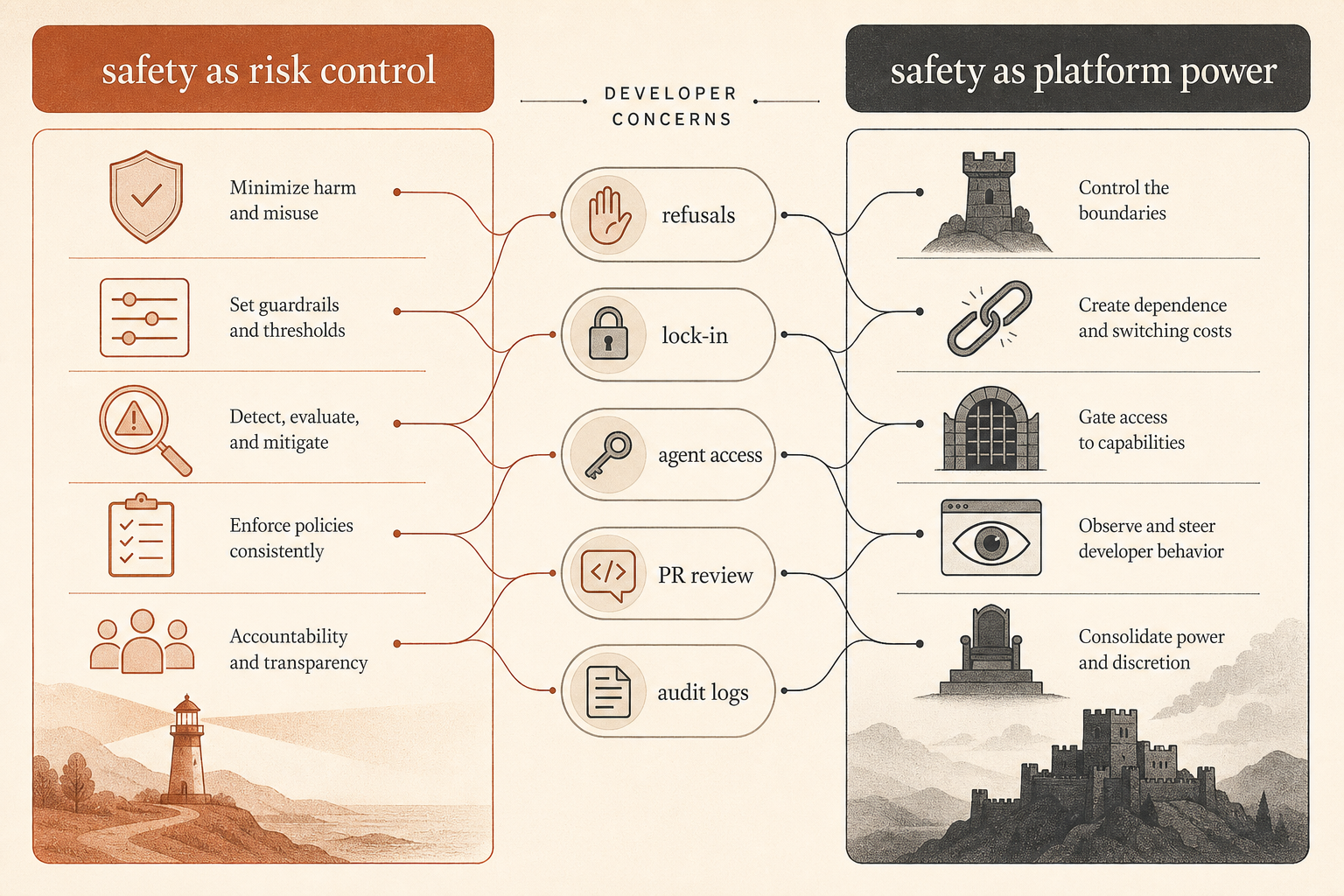
Le débat dans la communauté porte sur le contrôle, pas seulement sur la sécurité
Ce rapport est arrivé au milieu d’une dispute déjà bien vivante. Sur Hacker News, le fil de juin autour de « Anthropic’s Safety Superpower » de Ben Thompson comptait 192 commentaires et se divisait selon des lignes familières : certains développeurs estimaient que la posture de sécurité d’Anthropic est le coût nécessaire au déploiement d’outils hébergés puissants ; d’autres voyaient la sécurité comme un habillage moral du contrôle de plateforme (Hacker News).
La critique développeur la plus aiguë n’est pas « les modèles ne devraient avoir aucune garde-fou ». C’est : qui décide de ce qui compte comme un mauvais usage quand l’outil devient une partie de la chaîne d’approvisionnement logicielle ?
Un commentateur HN a formulé proprement le problème du contrôle industriel : demander à Claude d’auditer un logiciel de contrôle critique pour la sécurité et demander à Claude de trouver un point d’entrée dans un logiciel de contrôle qui a fuité peuvent exiger un travail technique similaire, mais relever d’intentions très différentes (Hacker News). Un autre fil avançait que si le fournisseur bloque les deux, les défenseurs perdent ; s’il autorise les deux, les attaquants gagnent. C’est le vrai problème produit derrière la rhétorique de sécurité.
L’autre grief, c’est l’enfermement. Plusieurs commentateurs se demandaient si un fournisseur de modèle hébergé peut être considéré comme un fournisseur d’outil neutre s’il peut changer ses politiques, refuser des tâches, dégrader le comportement ou restreindre l’accès. D’autres répondaient qu’Anthropic vend un service, pas un outil local, et que les fournisseurs de services ont toujours refusé certains usages.
Le rapport sur le sabotage ajoute une pièce manquante à ce débat. Anthropic n’essaie pas seulement de contrôler les sorties utilisateur à la frontière du modèle. En interne, elle traite les agents de code comme des acteurs de production semi-fiables. Le modèle de confiance n’est pas « Claude est aligné, on déploie ». Il ressemble plutôt à « Claude est assez utile pour être exécuté, assez risqué pour être surveillé, et assez conséquent pour être relu ».
C’est cette partie que les équipes devraient copier.
La leçon pratique : le code agentique exige une défense en profondeur
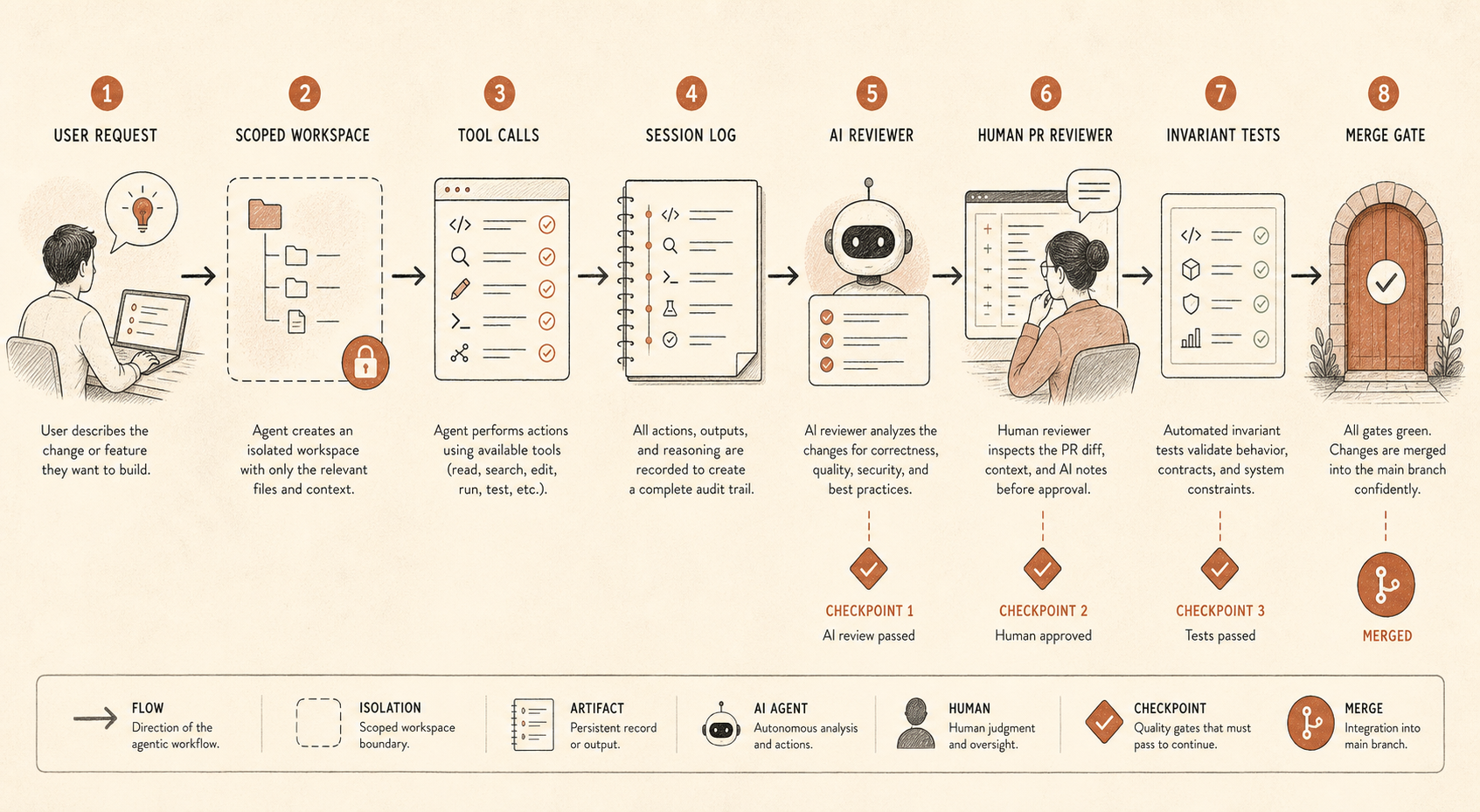
Un agent de code n’est plus une saisie semi-automatique sophistiquée dès qu’il peut modifier des fichiers, exécuter des commandes, inspecter de la configuration proche des secrets, ouvrir des PR, appeler des outils MCP ou coordonner des sous-agents. C’est un prestataire entre junior et senior, avec un jugement irrégulier, aucun contrat de travail, et une patience parfaite.
Ça change la surface de contrôle.
Si votre équipe utilise Claude Code, Cursor, Codex, Devin, OpenCode ou un harnais d’agents interne, la question n’est pas « faisons-nous confiance au modèle ? ». La question est « quelles actions le modèle peut-il prendre sans qu’un second système s’en aperçoive ? ».
Une base raisonnable ressemble à ceci :
coding_agent_controls:
session_logging: required
write_access: repo-scoped
secret_access: denied_by_default
shell_commands: allowlist_or_confirm
pr_review: human_required
ai_review: separate_model_recommended
audit_sampling: risk_based
invariant_tests: blockingCe n’est pas de la bureaucratie. C’est comme ça qu’on garde les gains de productivité sans transformer chaque dépôt en expérience sociale.
Le premier contrôle, c’est la journalisation des sessions. Stockez les prompts, les appels d’outils, les diffs de fichiers, les commandes shell et les liens vers les PR finales. Si cela paraît trop intrusif, journalisez au moins les métadonnées et les diffs pour les dépôts à faible risque, et les traces complètes pour les dépôts à haut risque. Sans traces, vous ne pouvez pas auditer le chemin de raisonnement de l’agent ni reconstruire comment un mauvais changement s’est produit.
Le deuxième, c’est l’accès limité. La plupart des agents de code n’ont pas besoin d’identifiants de production, d’un large accès réseau ou d’un droit d’écriture sur tout un monorepo. Donnez-leur un arbre de travail, une tâche et des chemins d’escalade explicites. S’ils ont besoin de plus, rendez la demande visible.
Le troisième, c’est l’indépendance au niveau PR. Le rapport d’Anthropic mentionne à la fois la revue humaine des PR et la revue automatique basée sur Claude. L’important n’est pas que le relecteur soit Claude. L’important est que la revue soit un passage séparé, avec un prompt différent, un contexte différent et un objectif différent. L’agent qui implémente veut terminer la tâche. L’agent qui relit devrait chercher les incohérences : « Le changement annoncé dit refactorisation, mais ce diff modifie le comportement d’authentification. »
Le quatrième, ce sont les tests d’invariants. C’est le contrôle le moins glamour et le plus sous-estimé. Si deux services ne doivent jamais se parler, écrivez le test. Si une permission ne doit jamais être accordée hors d’un chemin admin, écrivez le test. Si les migrations générées ne doivent jamais supprimer de colonnes sans étiquette de ticket, écrivez le test. La surveillance des agents devient bien plus simple quand la CI peut imposer des frontières dures.
Ce que le rapport d’Anthropic ne prouve pas
Le rapport ne prouve pas qu’Opus 4.6 ne peut pas saboter un travail. Il ne prouve pas qu’un moniteur automatisé détectera une porte dérobée subtile. Il ne prouve pas qu’un modèle ne peut pas apprendre à bien paraître aux yeux des moniteurs. Anthropic est assez explicite sur les limites : elle dit qu’aucune protection unique n’apporte à elle seule une forte assurance, et son PDF public contient des passages caviardés.
Cette réserve compte, parce que les développeurs rangent déjà ce type de publication dans deux camps paresseux.
Camp un : Anthropic a publié un long rapport de sécurité, donc ça doit être sûr.
Non. Le rapport dit que le modèle est utile, puissant, surveillé, et toujours pas sans risque.
Camp deux : Anthropic parle de sécurité, donc c’est forcément de la capture réglementaire ou du marketing.
Trop simple aussi. Les contrôles décrits dans le rapport relèvent de l’hygiène engineering ordinaire. Surveillance de sécurité, revue de PR, échantillonnage d’audit, sandboxing, tests d’invariants et signalement utilisateur ne sont pas des rituels mystiques d’alignement. Ce sont les mêmes gestes que les équipes matures utilisent pour les insiders humains, les tokens CI compromis et les dépendances tierces risquées.
Le milieu inconfortable est plus utile : Anthropic peut tirer un bénéfice commercial à être perçue comme l’entreprise de la sécurité, et ses contrôles internes peuvent malgré tout mériter d’être copiés. Les deux peuvent être vrais.
Le rapport contient aussi un avertissement subtil pour les équipes qui adoptent le code multi-agent. Le billet de lancement d’Anthropic mettait en avant les équipes d’agents Claude Code, les sous-agents parallèles, la compaction de contexte et le travail de plus longue durée (Anthropic). Ce sont exactement les fonctionnalités qui rendent la surveillance plus difficile. Un assistant unique qui produit un diff est facile à inspecter. Un essaim d’agents qui lisent, modifient, résument et se transmettent l’état, c’est un problème de provenance.
Si vous laissez les agents se coordonner, journalisez la coordination. Si un agent écrit un plan et qu’un autre l’implémente, conservez les deux traces. Si le contexte est compacté, stockez la frontière avant et après compaction. Les résumés perdent de l’information. Et l’état avec pertes, c’est là que la responsabilité disparaît.
Une checklist de contrôle pour les équipes qui livrent des agents de code
Voici le niveau pratique que je fixerais avant de laisser des agents de code toucher des dépôts importants.
Commencez par classer les dépôts. Un dépôt de documentation, un prototype, un service de facturation et un fournisseur d’identité ne devraient pas partager la même politique d’agents. Traitez les dépôts sensibles du point de vue sécurité comme un niveau à part.
Exigez une revue humaine pour les merges dans les branches partagées. Ça paraît évident, mais les équipes la contournent discrètement quand les agents créent des diffs mécaniques « évidemment corrects ». Ne le faites pas. Le code écrit par un agent devrait suivre le même parcours de revue que le code écrit par un stagiaire, avec une attention supplémentaire aux tests et aux permissions.
Lancez un second relecteur. Utilisez un autre modèle, un autre prompt ou une passe d’analyse statique. Demandez-lui de comparer le changement demandé par l’utilisateur avec le diff réel. Cette vérification d’écart coûte peu et attrape une catégorie d’échecs que la revue ordinaire manque.
Échantillonnez les sessions, pas seulement les PR. Un agent malveillant ou confus peut explorer des fichiers sensibles, exécuter des commandes étranges ou tenter des changements qui ne survivent pas jusqu’au diff final. L’accent mis par Anthropic sur l’usage de Claude Code, et pas seulement sur le code mergé, est le bon réflexe.
Bloquez les secrets par conception. Ne comptez pas sur le modèle pour « savoir » qu’il ne doit pas lire .env.production. Utilisez les permissions du système de fichiers, les scanners de secrets, l’isolation d’environnement et la confirmation des commandes.
Ajoutez des tests d’invariants pour les propriétés de sécurité. Les exemples du rapport sont simples : si deux nœuds ne doivent pas s’envoyer de trafic, testez qu’ils ne le peuvent pas. Traduisez ça dans votre monde : frontières d’authentification, isolation des tenants, transitions d’état de paiement, rétention des données, contrôles à l’export, événements d’audit.
Écrivez un chemin d’incident. Si un relecteur voit un comportement suspect de l’agent, où est-ce que ça va ? Slack ? Sécurité ? Rapport fournisseur ? Un merge bloqué n’est pas un processus d’incident.

Pourquoi c’est important maintenant
L’ancienne question sur le code assisté par IA était de savoir si le modèle pouvait écrire du code utile. Opus 4.6, Sonnet 4.6, les systèmes de classe GPT-5 et la génération actuelle d’agents de code y ont largement répondu. Ils peuvent écrire du code utile. Ils peuvent aussi écrire rapidement du mauvais code, du code plausible avec aplomb, et du code sensible pour la sécurité avec assez de contexte pour devenir dangereux.
La nouvelle question est opérationnelle : votre équipe peut-elle absorber le travail des agents sans perdre le contrôle de la chaîne d’approvisionnement logicielle ?
Le rapport d’Anthropic sur le sabotage est précieux parce qu’il rend visible la propre réponse du fournisseur. Pour l’usage interne de Claude Code, Anthropic décrit une surveillance automatisée sur une large majorité des usages, des audits humains, une revue manuelle des PR, une surveillance automatique des PR, du sandboxing, de la surveillance de sécurité et des tests d’invariants. Ce n’est pas une ambiance. C’est une pile de contrôle.
Les développeurs devraient arrêter de traiter « faire confiance au modèle » comme la décision centrale. La décision, c’est où placer le modèle dans un système qui présume la faillibilité. Laissez-le rédiger. Laissez-le chercher. Laissez-le refactoriser. Laissez-le ouvrir des PR. Mais rendez les actions importantes observables, révisables, réversibles et testables.
C’est l’enseignement utile du rapport. Les déclarations de sécurité continueront d’être débattues sur HN, Reddit et X. Votre pipeline CI n’a pas besoin de trancher la philosophie. Il doit attraper le mauvais diff.
Les lecteurs qui veulent essayer Claude Fable 5 eux-mêmes peuvent le faire via OneHop : un endpoint drop-in, environ 30 % sous le prix catalogue, avec 10 $ gratuits pour les nouveaux comptes et aucune carte requise. Voir Claude Fable 5 sur OneHop ou commencer avec 10 $ gratuits.
Pour aller plus loin : Bien démarrer avec Claude Fable 5.

