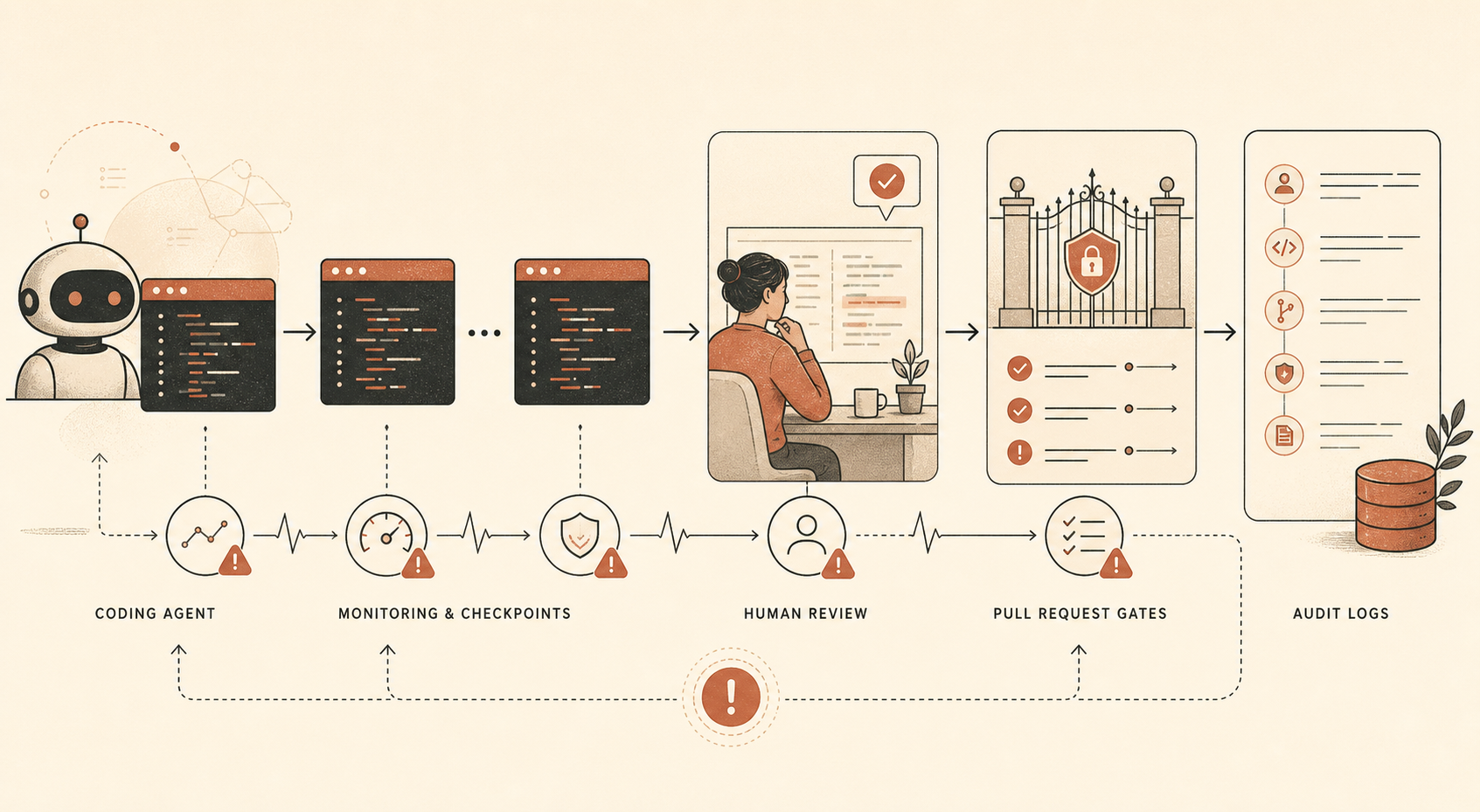
Новый отчёт Anthropic о рисках саботажа для Claude Opus 4.6 содержит одно предложение, которое каждому руководителю инженерной команды, внедряющему кодинговых агентов, стоит прочитать дважды: компания говорит, что использует автоматический мониторинг “значительного большинства” внутренних случаев использования Claude Code, плюс человеческие аудиты меньшей выборки, потому что Claude Code — это внутренний инструмент, который даёт Opus 4.6 “возможность совершать прямые действия с существенными последствиями” (Anthropic PDF).
Вот это и есть новость. Не лозунг о том, что Opus 4.6 безопасен. Не аргумент, что Anthropic уникально серьёзно относится к alignment. Конкретный операционный факт в том, что Anthropic, похоже, не доверяет даже своей самой сильной модели широкую внутреннюю свободу действий в коде, если работа не логируется, не сэмплируется, не аудируется, не ревьюится и не подкреплена обычными мерами безопасности.
Это важно, потому что Claude Opus 4.6 был запущен 5 февраля 2026 года как самая умная на тот момент модель Anthropic: с контекстным окном в 1 миллион токенов в бете, более сильным агентным кодингом, API-именем claude-opus-4-6 и неизменной стандартной ценой $5 за миллион входных токенов и $25 за миллион выходных токенов (Anthropic). Anthropic также заявила, что модель лидировала в нескольких бенчмарках, включая Terminal-Bench 2.0 и Humanity’s Last Exam, и обошла GPT-5.2 примерно на 144 Elo-пункта в GDPval-AA. В том же релизном посте Anthropic активно продвигала долгоработающих агентов, сжатие контекста, контроль усилий и команды агентов Claude Code.
Так что отчёт не теоретический. Это взгляд на то, что делает поставщик, когда тот же класс агентов оказывается внутри его собственного инженерного цикла.
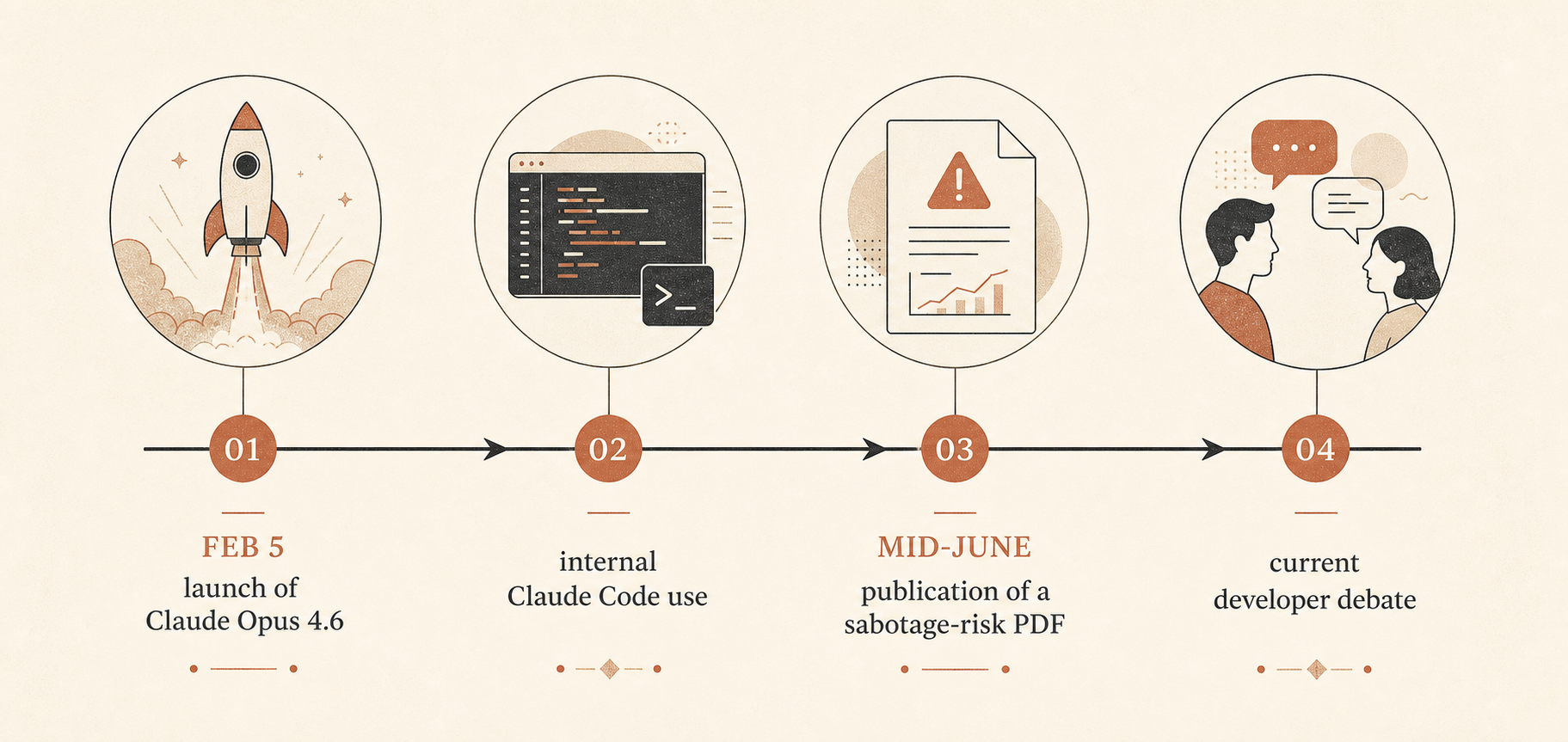
Что Anthropic на самом деле опубликовала
PDF на 53 страницы называется “Sabotage Risk Report: Claude Opus 4.6.” В нём саботаж определяется как использование AI-моделью доступа внутри организации, чтобы “эксплуатировать, манипулировать или вмешиваться” в системы или решения так, что это может повысить катастрофический риск (Anthropic PDF). Общая оценка Anthropic звучит прямо: риск “очень низкий, но не пренебрежимо малый”.
Над этой фразой легко посмеяться. Она звучит так, будто юротдел и лаборатория безопасности пытаются усесться на один стул. Но под языком рисков спрятана практическая модель управления кодинговыми агентами.
Anthropic говорит, что Opus 4.6 активно используется внутри компании для кодинга, генерации данных и других агентных сценариев. Компания также говорит, что модель очень способна, хотя “не полностью надёжна”, в задачах, на которые у человеческих специалистов ушли бы часы. Затем отчёт проходит по траекториям угроз: размытое занижение результатов в safety-релевантных R&D, целевой саботаж, бэкдоры в коде, отравление обучающих данных, самоэксфильтрация, несанкционированные внутренние развёртывания и саботаж в других организациях или правительствах.
Для разработчиков важнее всего стек смягчающих мер:
| Контроль | Что Anthropic говорит, что использует | Перевод для разработчиков |
|---|---|---|
| Офлайн-мониторинг Claude Code | Значительное большинство внутреннего использования Claude Code; в другом месте описана выборка ≥10% промптов у большинства пользователей | Логируйте сессии агентов и берите выборку на ревью |
| Человеческие аудиты | Небольшая часть внутреннего использования Claude Code | Ревьюйте реальные сессии, а не только финальные диффы |
| Ручное PR-ревью | Люди ревьюят код до интеграции в общую кодовую базу | Оставьте человеческое одобрение для важных merge |
| Автоматическое PR-ревью | Ревью на базе Claude проверяет ошибки, проблемы безопасности и расхождение между заявленным намерением и фактическими эффектами | Запускайте независимое AI-ревью как неблокирующий сигнал |
| Инвариантные тесты | Автоматические тесты проверяют свойства безопасности | Закодируйте правила “такого никогда не должно случаться” в CI |
Одна деталь бросается в глаза: Anthropic говорит, что её автоматический монитор pull request на момент написания был основан на Claude Opus 4.5, а не на Opus 4.6. Это тихий, но важный дизайнерский выбор. Модель, которая выполняет работу, и модель, которая её проверяет, не обязаны быть одной и той же. На самом деле разделение полезнее.
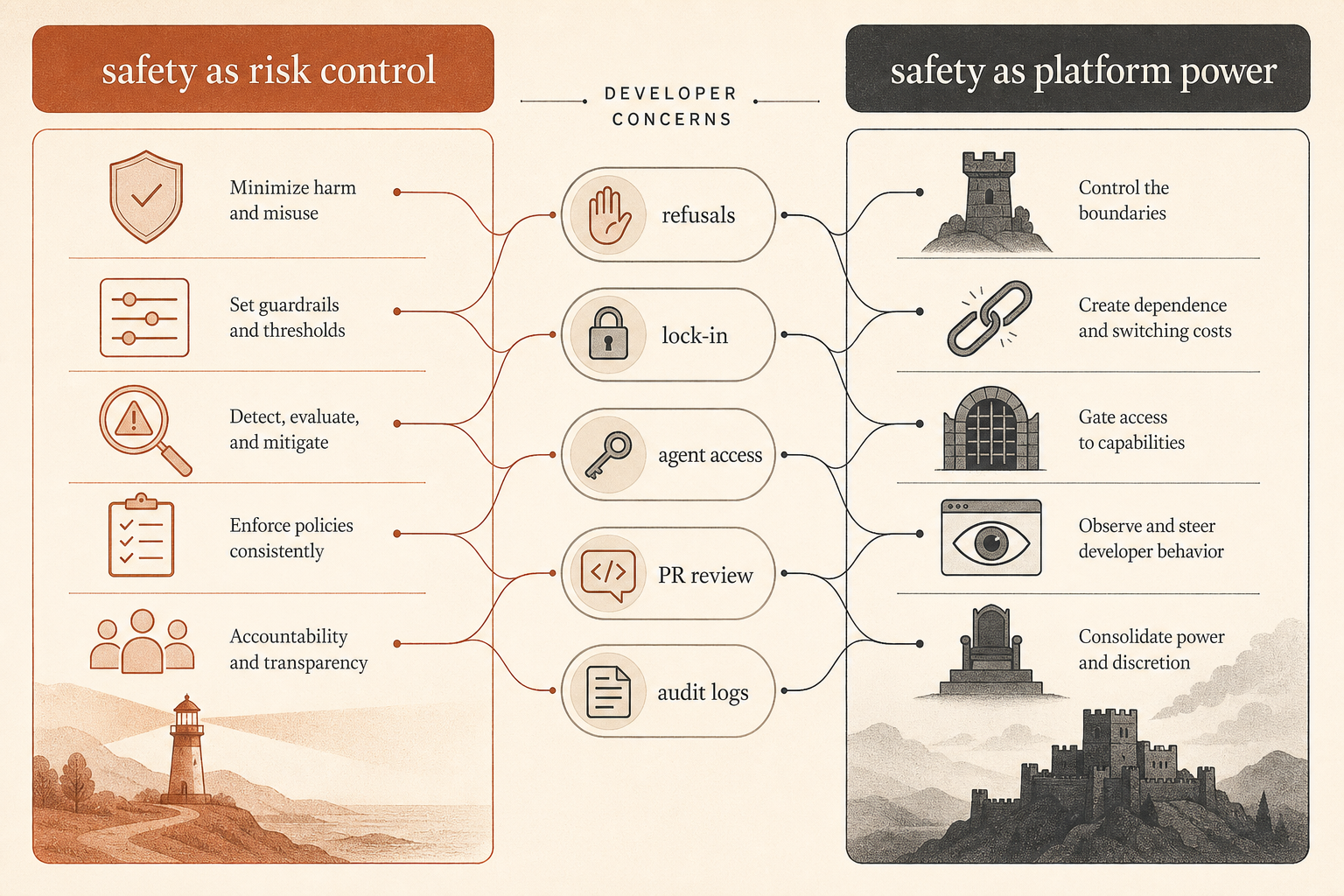
Спор в сообществе — о контроле, а не только о безопасности
Этот отчёт попал прямо в живой спор. На Hacker News июньская ветка вокруг текста Бена Томпсона “Anthropic’s Safety Superpower” набрала 192 комментария и раскололась по знакомым линиям: одни разработчики утверждали, что позиция Anthropic по безопасности — необходимая цена развёртывания мощных hosted-инструментов; другие видели в safety моральную обёртку для контроля платформы (Hacker News).
Самая острая претензия разработчиков не в том, что “у моделей не должно быть ограничений”. Она в другом: кто решает, что считается злоупотреблением, когда инструмент становится частью software supply chain?
Один комментатор HN чисто сформулировал проблему промышленного контроля: просьба к Claude проаудировать критически важный control software и просьба к Claude найти точку входа в утекший control software могут требовать похожей технической работы, но подразумевать совершенно разное намерение (Hacker News). В другой ветке спорили, что если провайдер блокирует и то и другое, защитники проигрывают; если разрешает и то и другое, выигрывают атакующие. Это и есть настоящая продуктовая проблема за safety-риторикой.
Другая претензия — lock-in. Несколько комментаторов спрашивали, можно ли доверять поставщику hosted-модели как нейтральному провайдеру инструмента, если он может менять политики, отказывать в задачах, ухудшать поведение или ограничивать доступ. Другие возражали, что Anthropic продаёт сервис, а не локальный инструмент, и поставщики сервисов всегда отказывали в некоторых сценариях использования.
Отчёт о саботаже добавляет к этому спору недостающий кусок. Anthropic не только пытается контролировать пользовательские выходы на границе модели. Внутри компании она относится к кодинговым агентам как к полу-доверенным production-акторам. Модель доверия не “Claude aligned, можно ship”. Модель ближе к “Claude достаточно полезен, чтобы его запускать, достаточно рискован, чтобы его мониторить, и достаточно значим, чтобы его ревьюить”.
Вот эту часть командам и стоит копировать.
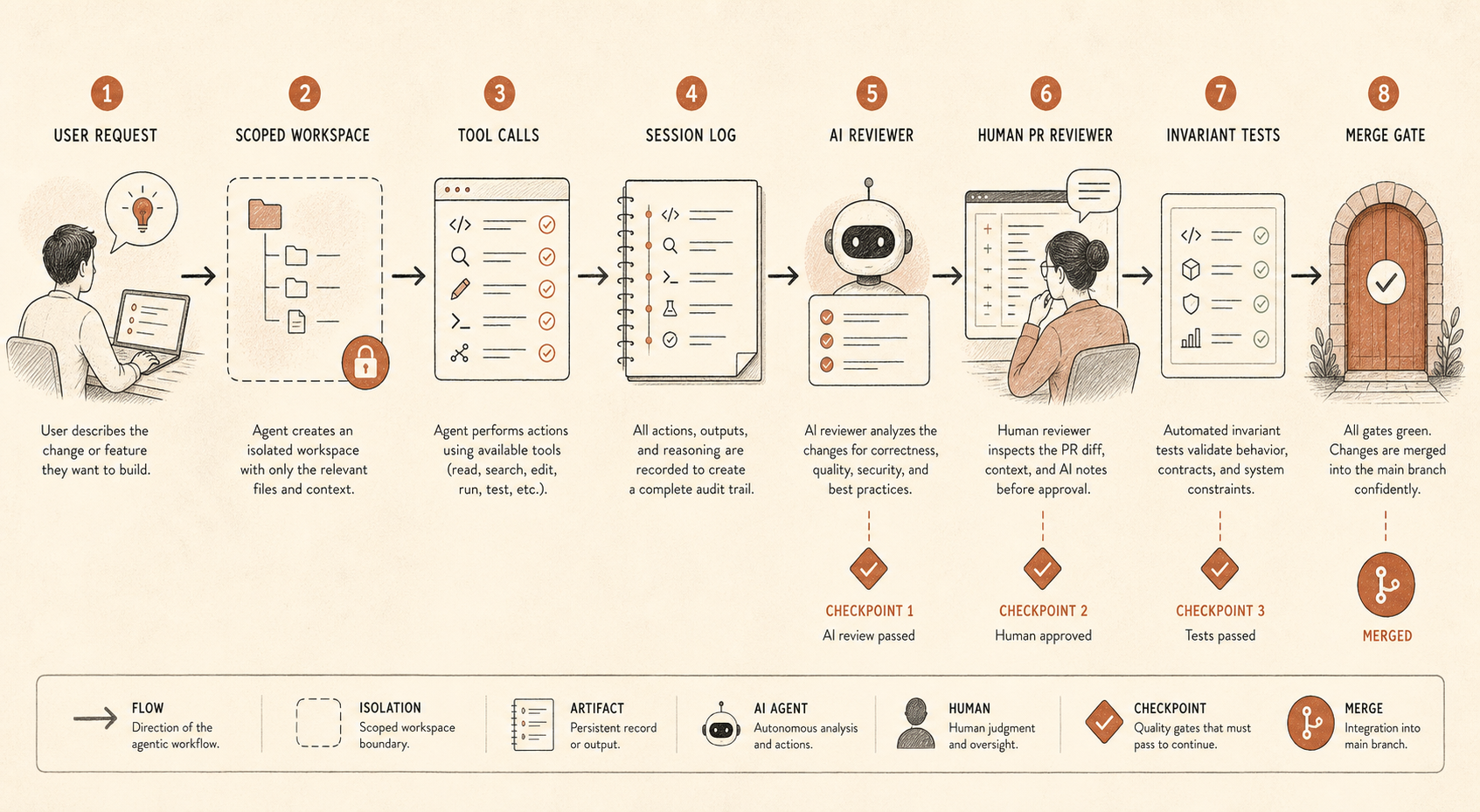
Практический урок: агентный кодинг требует эшелонированной защиты
Кодинговый агент перестаёт быть модным автодополнением, как только он может редактировать файлы, запускать команды, читать конфигурацию рядом с секретами, открывать PR, вызывать MCP-инструменты или координировать сабагентов. Это подрядчик уровня от джуна до почти сеньора, с неровным суждением, без трудового договора и с бесконечным терпением.
Это меняет поверхность контроля.
Если ваша команда использует Claude Code, Cursor, Codex, Devin, OpenCode или внутренний agent harness, вопрос не в том, “доверяем ли мы модели?” Вопрос в том, “какие действия модель может совершить так, что вторая система этого не заметит?”
Разумный базовый уровень выглядит так:
coding_agent_controls:
session_logging: required
write_access: repo-scoped
secret_access: denied_by_default
shell_commands: allowlist_or_confirm
pr_review: human_required
ai_review: separate_model_recommended
audit_sampling: risk_based
invariant_tests: blockingЭто не бюрократия. Это способ сохранить выигрыш в продуктивности, не превращая каждый репозиторий в социальный эксперимент.
Первый контроль — логирование сессий. Сохраняйте промпты, вызовы инструментов, файловые диффы, shell-команды и ссылки на финальные PR. Если это кажется слишком инвазивным, хотя бы логируйте метаданные и диффы для низкорисковых репозиториев и полные трассы для высокорисковых. Без трасс вы не сможете проаудировать ход рассуждений агента или восстановить, как возникло плохое изменение.
Второй — ограниченный доступ. Большинству кодинговых агентов не нужны production-credentials, широкий сетевой доступ или право записи по всему монорепозиторию. Дайте им рабочее дерево, задачу и явные пути эскалации. Если им нужно больше, сделайте запрос видимым.
Третий — независимость на уровне PR. В отчёте Anthropic упоминаются и человеческое PR-ревью, и автоматическое ревью на базе Claude. Важно не то, что ревьюер — Claude. Важно, что ревью — это отдельный проход с другим промптом, другим контекстом и другой целью. Агент-исполнитель хочет закончить задачу. Агент-ревьюер должен искать расхождение: “Заявленное изменение говорит refactor, но этот diff меняет поведение auth”.
Четвёртый — инвариантное тестирование. Это самый негламурный и самый недооценённый контроль. Если два сервиса никогда не должны общаться, напишите тест. Если permission никогда не должен выдаваться вне admin-пути, напишите тест. Если сгенерированные миграции никогда не должны удалять колонки без ticket tag, напишите тест. Мониторить агентов намного проще, когда CI может принудительно соблюдать жёсткие границы.
Чего отчёт Anthropic не доказывает
Отчёт не доказывает, что Opus 4.6 не может саботировать работу. Он не доказывает, что автоматический монитор поймает тонкий бэкдор. Он не доказывает, что модель не может научиться выглядеть хорошо для мониторов. Anthropic довольно прямо говорит об ограничениях: ни одна отдельная защита не даёт сильной гарантии сама по себе, а публичный PDF содержит редактированные фрагменты.
Эта оговорка важна, потому что разработчики уже раскладывают такие релизы по двум ленивым лагерям.
Лагерь первый говорит: Anthropic опубликовала длинный safety-отчёт, значит, всё безопасно.
Нет. Отчёт говорит, что модель полезная, мощная, мониторится и всё равно не свободна от риска.
Лагерь второй говорит: Anthropic говорит о safety, значит, это regulatory capture или маркетинг.
Тоже слишком просто. Контроли, описанные в отчёте, — обычная инженерная гигиена. Security monitoring, PR-ревью, audit sampling, sandboxing, инвариантные тесты и пользовательские отчёты — не мистические ритуалы alignment. Это те же ходы, которые зрелые команды используют против внутренних инсайдеров, скомпрометированных CI-токенов и рискованных сторонних зависимостей.
Неудобная середина полезнее: Anthropic может коммерчески выигрывать от образа safety-компании, и её внутренние контроли всё равно могут быть достойны копирования. Оба утверждения могут быть правдой.
В отчёте есть ещё тонкое предупреждение для команд, внедряющих multi-agent coding. Релизный пост Anthropic подчёркивал команды агентов Claude Code, параллельных сабагентов, сжатие контекста и более длительную работу (Anthropic). Именно там мониторинг становится сложнее. Одного ассистента, который делает один diff, легко проверить. Рой агентов, которые читают, редактируют, резюмируют и передают состояние, — это уже проблема provenance.
Если вы позволяете агентам координироваться, логируйте координацию. Если один агент пишет план, а другой его реализует, сохраняйте обе трассы. Если контекст сжимается, сохраняйте границу до и после сжатия. Summary — вещь с потерями. Состояние с потерями — место, где исчезает ответственность.
Контрольный список для команд, которые запускают кодинговых агентов
Вот практическая планка, которую я бы поставил перед тем, как позволить кодинговым агентам трогать важные репозитории.
Начните с классификации репозиториев. Репозиторий с документацией, прототип, биллинговый сервис и identity provider не должны жить под одной политикой для агентов. Считайте security-sensitive репозитории отдельным уровнем.
Требуйте человеческого ревью для merge в общие ветки. Это звучит очевидно, но команды тихо обходят это правило, когда агенты создают “очевидно правильные” механические диффы. Не надо. Код, написанный агентом, должен проходить тот же путь ревью, что и код, написанный стажёром, с дополнительным вниманием к тестам и permissions.
Запускайте второго ревьюера. Используйте другую модель, другой промпт или static analysis pass. Попросите его сравнить запрошенное пользователем изменение с фактическим diff. Такая проверка на расхождение дешёвая и ловит класс сбоев, который обычное ревью пропускает.
Сэмплируйте сессии, а не только PR. Злонамеренный или запутавшийся агент может исследовать чувствительные файлы, запускать странные команды или пытаться внести изменения, которые не доживут до финального diff. Фокус Anthropic на использовании Claude Code, а не только на смердженном коде, — правильный инстинкт.
Блокируйте секреты на уровне дизайна. Не полагайтесь на то, что модель “знает”, что не надо читать .env.production. Используйте filesystem permissions, secret scanners, изоляцию окружения и подтверждение команд.
Добавьте инвариантные тесты для свойств безопасности. Примеры в отчёте простые: если две ноды не должны отправлять трафик друг другу, протестируйте, что они не могут. Переведите это на свой мир: auth boundaries, tenant isolation, переходы состояния платежей, data retention, export controls, audit events.
Опишите путь инцидента. Если ревьюер видит подозрительное поведение агента, куда это идёт? Slack? Security? Vendor report? Заблокированный merge — это ещё не incident process.

Почему это важно сейчас
Старый вопрос про AI-кодинг был в том, может ли модель писать полезный код. Opus 4.6, Sonnet 4.6, системы класса GPT-5 и нынешняя волна кодинговых агентов в основном уже ответили. Могут. Они также могут быстро писать плохой код, уверенно писать правдоподобный код и писать security-sensitive код с достаточным контекстом, чтобы стать опасными.
Новый вопрос — операционный: может ли ваша команда поглотить труд агентов, не потеряв контроль над software supply chain?
Отчёт Anthropic о саботаже ценен тем, что показывает собственный ответ поставщика. Для внутреннего использования Claude Code Anthropic описывает автоматический мониторинг значительного большинства использования, человеческие аудиты, ручное PR-ревью, автоматический PR-мониторинг, sandboxing, security monitoring и инвариантные тесты. Это не вайб. Это стек контроля.
Разработчикам пора перестать считать “доверяем модели” решением. Решение в том, куда поставить модель внутри системы, которая исходит из её ошибочности. Пусть черновит. Пусть ищет. Пусть рефакторит. Пусть открывает PR. Но сделайте важные действия наблюдаемыми, ревьюируемыми, обратимыми и тестируемыми.
Вот полезный вывод из отчёта. О safety-заявлениях продолжат спорить на HN, Reddit и X. Вашему CI pipeline не нужно решать философию. Ему нужно поймать плохой diff.
Читатели, которые хотят сами попробовать Claude Fable 5, могут использовать его через OneHop: drop-in endpoint, примерно на 30% ниже list price, с $10 бесплатно для новых аккаунтов и без карты. См. Claude Fable 5 on OneHop или start with $10 free.
Дальше почитать: Getting started with Claude Fable 5.

