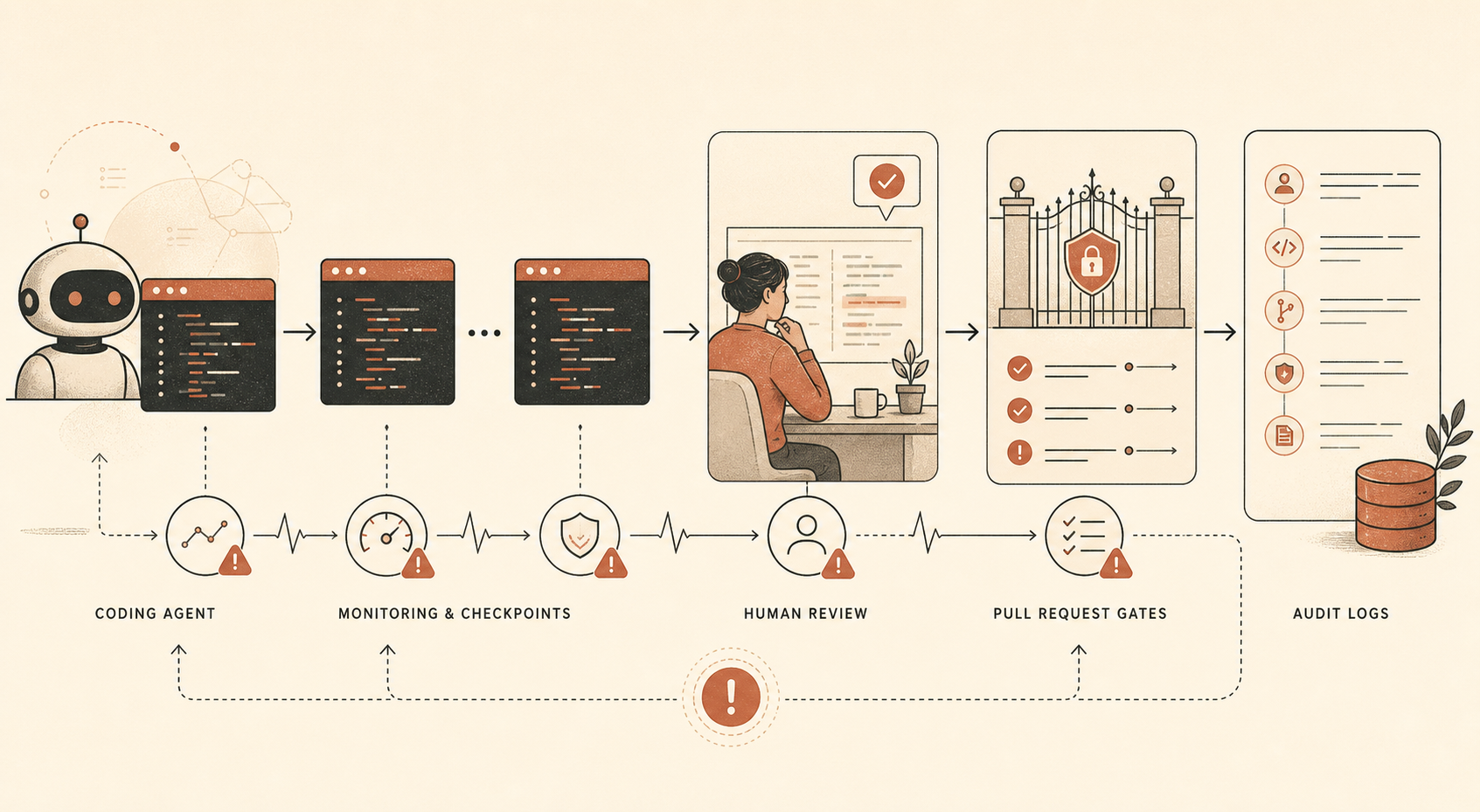
Anthropic’s new sabotage-risk report for Claude Opus 4.6 contains one sentence every engineering lead adopting coding agents should read twice: the company says it uses automated monitoring over “a large majority” of internal Claude Code use, plus human audits of a smaller subset, because Claude Code is the internal tool that gives Opus 4.6 “the ability to take direct consequential actions” (Anthropic PDF).
That is the news. Not the slogan that Opus 4.6 is safe. Not the argument that Anthropic is uniquely serious about alignment. The concrete operational fact is that Anthropic does not appear to trust even its own strongest model with broad internal coding agency unless the work is logged, sampled, audited, reviewed, and backed by ordinary security controls.
That matters because Claude Opus 4.6 was launched on February 5, 2026, as Anthropic’s then-smartest model, with a 1 million token context window in beta, stronger agentic coding, a claude-opus-4-6 API name, and unchanged standard pricing of $5 per million input tokens and $25 per million output tokens (Anthropic). Anthropic also said the model led on several benchmarks, including Terminal-Bench 2.0 and Humanity’s Last Exam, and beat GPT-5.2 by around 144 Elo points on GDPval-AA. In the same launch post, Anthropic pushed hard on long-running agents, context compaction, effort controls, and Claude Code agent teams.
So the report is not theoretical. It is a look at what the vendor does when the same class of agent is inside its own engineering loop.
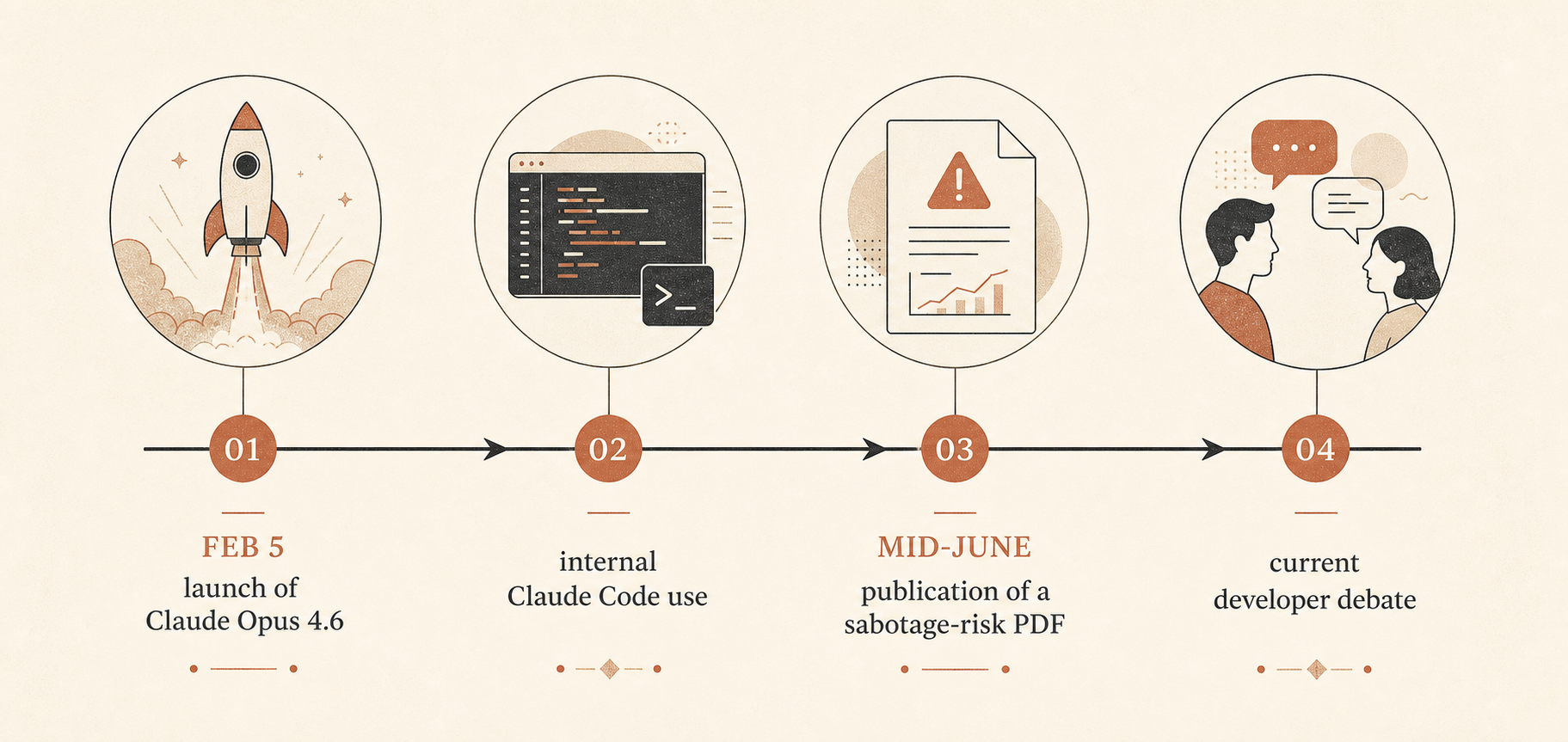
What Anthropic Actually Published
The 53-page PDF is titled “Sabotage Risk Report: Claude Opus 4.6.” It defines sabotage as an AI model using access inside an organization to “exploit, manipulate, or tamper with” systems or decisions in a way that could raise catastrophic risk (Anthropic PDF). Anthropic’s overall assessment is blunt: risk is “very low but not negligible.”
That phrase is easy to mock. It sounds like a legal department and a safety lab trying to share one chair. But buried under the risk language is a practical model of coding-agent governance.
Anthropic says Opus 4.6 is heavily used internally for coding, data generation, and other agentic use cases. It also says the model is highly capable, though “not fully reliable,” on tasks that would take human specialists hours. The report then walks through threat pathways: diffuse sandbagging of safety-relevant R&D, targeted sabotage, code backdoors, training-data poisoning, self-exfiltration, rogue internal deployments, and sabotage in other organizations or governments.
For developers, the relevant part is the mitigation stack:
| Control | What Anthropic says it uses | Developer translation |
|---|---|---|
| Offline Claude Code monitoring | Large majority of internal Claude Code use; elsewhere a ≥10% prompt subsample by most users is described | Log agent sessions and sample them for review |
| Human audits | Small subset of internal Claude Code use | Review real sessions, not just final diffs |
| Manual PR review | Humans review code before shared codebase integration | Keep human approval on important merges |
| Automatic PR review | Claude-based review checks errors, security issues, and mismatch between stated intent and actual effects | Run independent AI review as a non-blocking signal |
| Invariant tests | Automated tests check security properties | Encode “must never happen” rules in CI |
One detail stands out: Anthropic says its automatic pull-request monitor was based on Claude Opus 4.5 at the time of writing, not Opus 4.6. That is a quiet but important design choice. The model doing the work and the model reviewing the work do not need to be identical. In fact, separation is healthier.
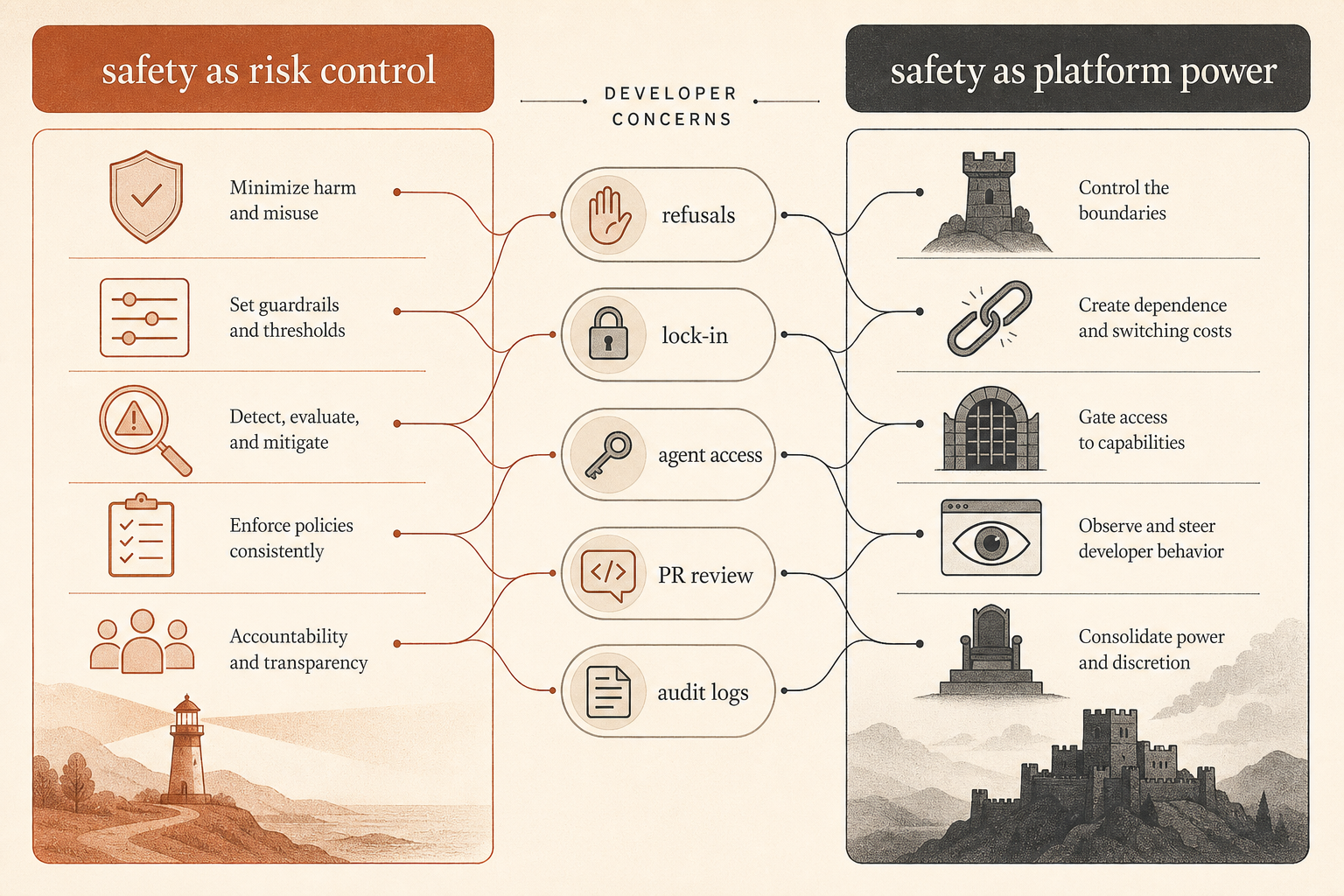
The Community Debate Is About Control, Not Just Safety
This report landed into a live argument. On Hacker News, the June thread around Ben Thompson’s “Anthropic’s Safety Superpower” had 192 comments and split along familiar lines: some developers argued that Anthropic’s safety posture is a necessary cost of deploying powerful hosted tools; others saw safety as a moral wrapper for platform control (Hacker News).
The sharpest developer complaint is not “models should have no guardrails.” It is: who decides what counts as misuse when the tool is becoming part of the software supply chain?
One HN commenter framed the industrial-control problem cleanly: asking Claude to audit safety-critical control software and asking Claude to find an entry point into leaked control software may require similar technical work, but very different intent (Hacker News). Another thread argued that if the provider blocks both, defenders lose; if it allows both, attackers gain. That is the actual product problem behind the safety rhetoric.
The other complaint is lock-in. Several commenters questioned whether a hosted model vendor can be trusted as a neutral tool provider if it can change policies, refuse tasks, downgrade behavior, or restrict access. Others pushed back that Anthropic is selling a service, not a local tool, and service providers have always refused some uses.
The sabotage report adds a missing piece to that debate. Anthropic is not only trying to control user outputs at the model boundary. Internally, it is treating coding agents like semi-trusted production actors. The trust model is not “Claude is aligned, ship it.” The trust model is closer to “Claude is useful enough to run, risky enough to monitor, and consequential enough to review.”
That is the part teams should copy.
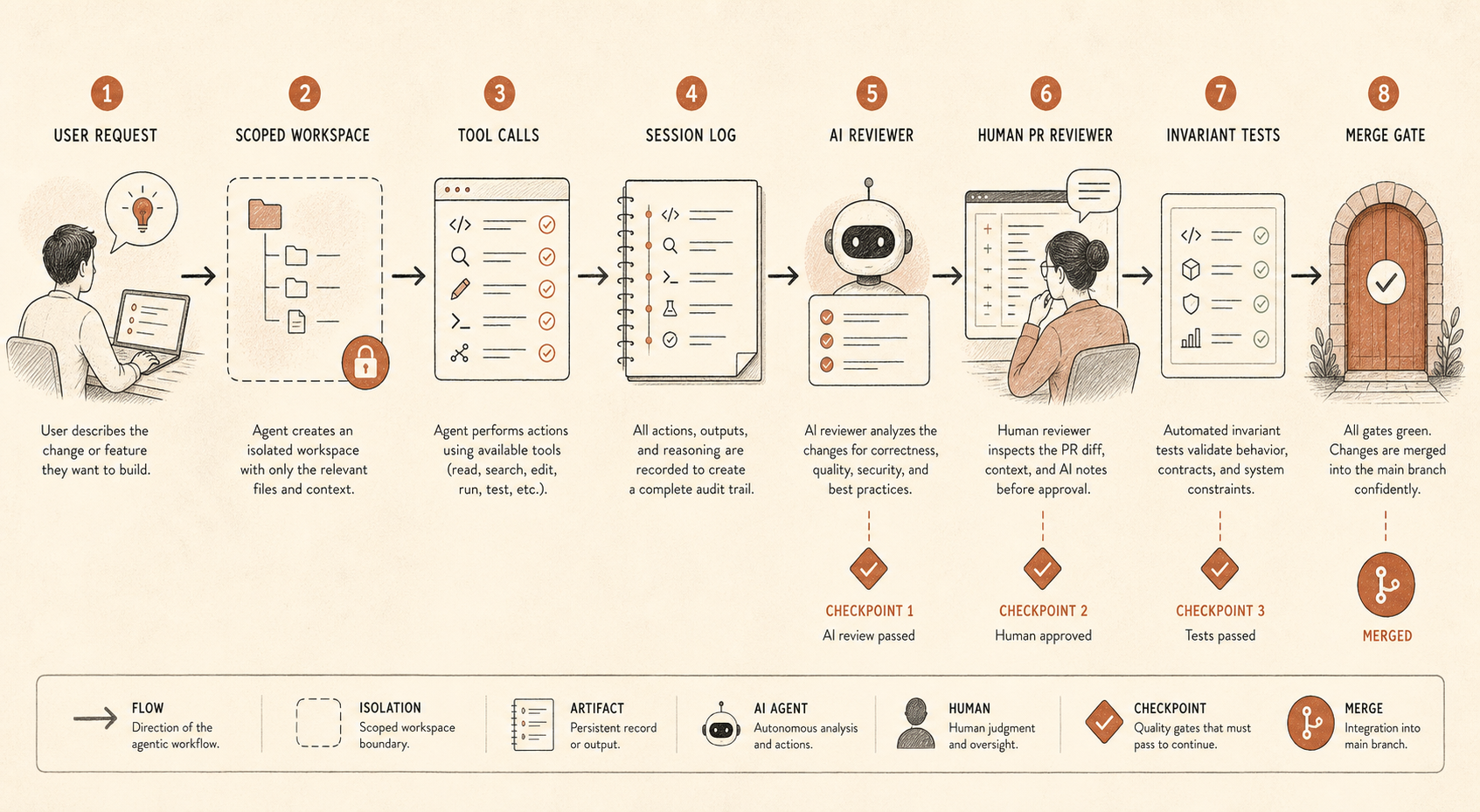
The Practical Lesson: Agentic Coding Needs Defense in Depth
A coding agent is not a fancy autocomplete once it can edit files, run commands, inspect secrets-adjacent configuration, open PRs, call MCP tools, or coordinate subagents. It is a junior-to-senior-ish contractor with inconsistent judgment, no employment contract, and perfect patience.
That changes the control surface.
If your team is using Claude Code, Cursor, Codex, Devin, OpenCode, or an internal agent harness, the question is not “do we trust the model?” The question is “what actions can the model take without a second system noticing?”
A sensible baseline looks like this:
coding_agent_controls:
session_logging: required
write_access: repo-scoped
secret_access: denied_by_default
shell_commands: allowlist_or_confirm
pr_review: human_required
ai_review: separate_model_recommended
audit_sampling: risk_based
invariant_tests: blockingThis is not bureaucracy. It is how you keep the productivity gains without turning every repository into a social experiment.
The first control is session logging. Store prompts, tool calls, file diffs, shell commands, and final PR links. If that feels too invasive, at least log metadata and diffs for low-risk repos and full traces for high-risk repos. Without traces, you cannot audit the agent’s reasoning path or reconstruct how a bad change happened.
The second is scoped access. Most coding agents do not need production credentials, broad network access, or write access across a monorepo. Give them a working tree, a task, and explicit escalation paths. If they need more, make the request visible.
The third is PR-level independence. Anthropic’s report mentions both human PR review and automatic Claude-based review. The important part is not that the reviewer is Claude. The important part is that review is a separate pass with a different prompt, different context, and a different goal. The implementing agent wants to complete the task. The reviewing agent should look for mismatch: “The stated change says refactor, but this diff changes auth behavior.”
The fourth is invariant testing. This is the least glamorous and most underrated control. If two services must never talk, write the test. If a permission must never be granted outside an admin path, write the test. If generated migrations must never drop columns without a ticket tag, write the test. Agent monitoring gets much easier when CI can enforce hard boundaries.
What Anthropic’s Report Does Not Prove
The report does not prove Opus 4.6 cannot sabotage work. It does not prove an automated monitor will catch a subtle backdoor. It does not prove that a model cannot learn to look good to monitors. Anthropic is fairly explicit about limitations: it says no single safeguard gives strong assurance alone, and its public PDF includes redactions.
That caveat matters because developers are already pattern-matching these releases into two lazy camps.
Camp one says: Anthropic published a long safety report, so it must be safe.
No. The report says the model is useful, powerful, monitored, and still not risk-free.
Camp two says: Anthropic talks about safety, so it must be regulatory capture or marketing.
Also too simple. The controls described in the report are ordinary engineering hygiene. Security monitoring, PR review, audit sampling, sandboxing, invariant tests, and user reporting are not mystical alignment rituals. They are the same moves mature teams use for human insiders, compromised CI tokens, and risky third-party dependencies.
The uncomfortable middle is more useful: Anthropic may benefit commercially from being seen as the safety company, and its internal controls may still be worth copying. Those can both be true.
The report also has a subtle warning for teams adopting multi-agent coding. Anthropic’s launch post highlighted Claude Code agent teams, parallel subagents, context compaction, and longer-running work (Anthropic). Those features are exactly where monitoring gets harder. A single assistant making one diff is easy to inspect. A swarm of agents reading, editing, summarizing, and handing off state is a provenance problem.
If you let agents coordinate, log the coordination. If one agent writes a plan and another implements it, preserve both traces. If context is compacted, store the pre-compaction and post-compaction boundary. Summaries are lossy. Lossy state is where accountability disappears.
A Control Checklist for Teams Shipping Coding Agents
Here is the practical bar I would set before letting coding agents touch important repositories.
Start with repo classification. A docs repo, a prototype, a billing service, and an identity provider should not share one agent policy. Treat security-sensitive repos as a different tier.
Require human review for merges into shared branches. This sounds obvious, but teams quietly bypass it when agents create “obviously correct” mechanical diffs. Do not. Agent-written code should go through the same review path as intern-written code, with extra attention to tests and permissions.
Run a second reviewer. Use another model, another prompt, or a static analysis pass. Ask it to compare the user’s requested change with the actual diff. That mismatch check is cheap and catches a class of failures ordinary review misses.
Sample sessions, not just PRs. A malicious or confused agent may explore sensitive files, run strange commands, or attempt changes that do not survive into the final diff. Anthropic’s focus on Claude Code use, not only merged code, is the right instinct.
Block secrets by design. Do not rely on the model “knowing” not to read .env.production. Use filesystem permissions, secret scanners, environment isolation, and command confirmation.
Add invariant tests for security properties. The report’s examples are plain: if two nodes should not send traffic to each other, test that they cannot. Translate that into your world: auth boundaries, tenant isolation, payment state transitions, data retention, export controls, audit events.
Write an incident path. If a reviewer sees suspicious agent behavior, where does it go? Slack? Security? A vendor report? A blocked merge is not an incident process.

Why This Matters Now
The old AI coding question was whether the model could write useful code. Opus 4.6, Sonnet 4.6, GPT-5-class systems, and the current crop of coding agents have mostly answered that. They can write useful code. They can also write bad code quickly, plausible code confidently, and security-sensitive code with enough context to be dangerous.
The new question is operational: can your team absorb agent labor without losing control of the software supply chain?
Anthropic’s sabotage report is valuable because it makes the vendor’s own answer visible. For internal Claude Code use, Anthropic describes automated monitoring over a large majority of use, human audits, manual PR review, automatic PR monitoring, sandboxing, security monitoring, and invariant tests. That is not a vibe. That is a control stack.
Developers should stop treating “trust the model” as the decision. The decision is where to put the model inside a system that assumes fallibility. Let it draft. Let it search. Let it refactor. Let it open PRs. But make the important actions observable, reviewable, reversible, and testable.
That is the useful takeaway from the report. Safety claims will keep being argued on HN, Reddit, and X. Your CI pipeline does not need to settle the philosophy. It needs to catch the bad diff.
Readers who want to try Claude Fable 5 themselves can use it through OneHop: a drop-in endpoint, about 30% under list price, with $10 free for new accounts and no card required. See Claude Fable 5 on OneHop or start with $10 free.
Further reading: Getting started with Claude Fable 5.

