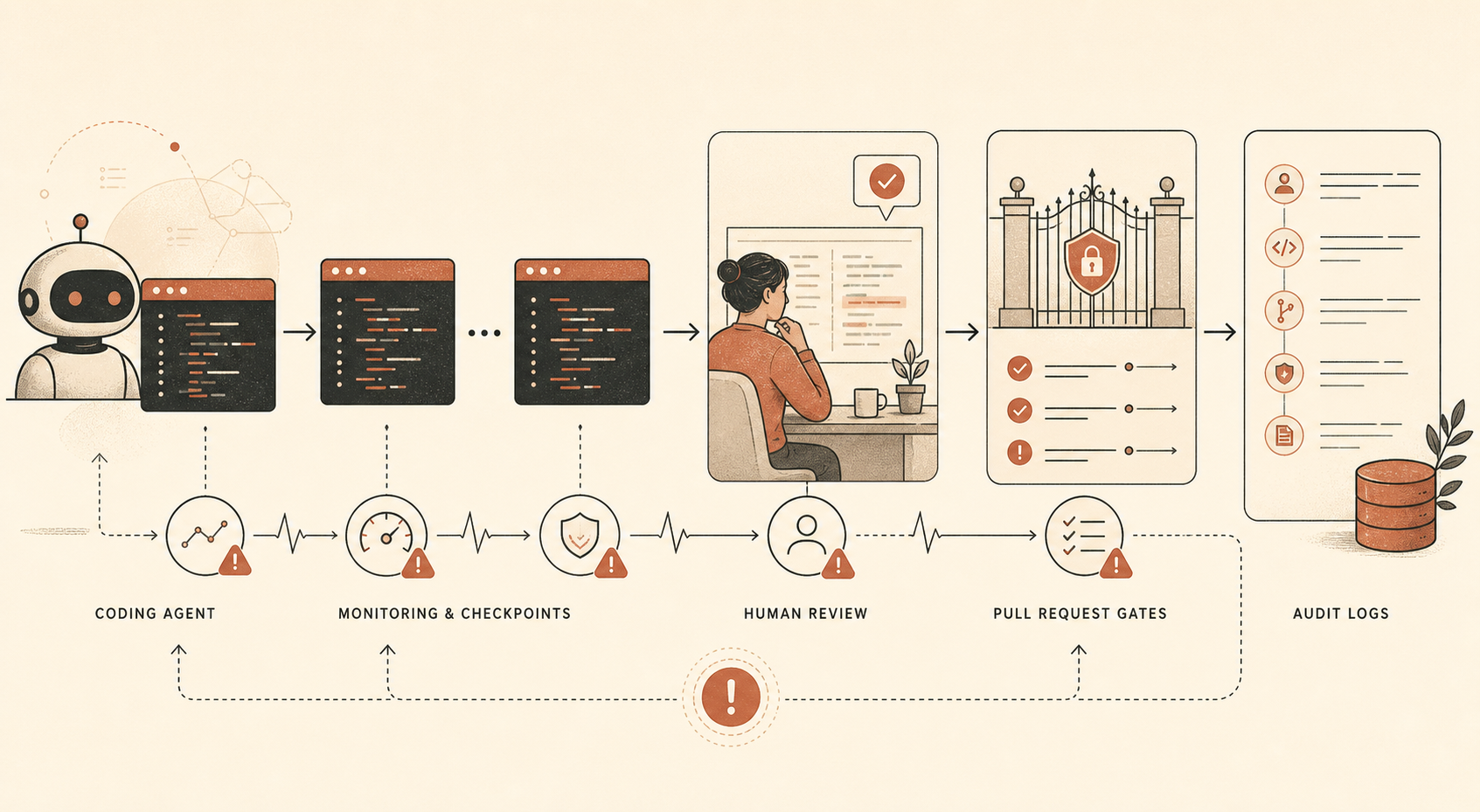
O novo relatório de risco de sabotagem da Anthropic para o Claude Opus 4.6 contém uma frase que todo líder de engenharia adotando agentes de programação deveria ler duas vezes: a empresa diz que usa monitoramento automatizado sobre “uma grande maioria” do uso interno do Claude Code, além de auditorias humanas em um subconjunto menor, porque o Claude Code é a ferramenta interna que dá ao Opus 4.6 “a capacidade de executar ações diretas e consequentes” (Anthropic PDF).
Essa é a notícia. Não o slogan de que o Opus 4.6 é seguro. Não o argumento de que a Anthropic é singularmente séria com alinhamento. O fato operacional concreto é que a Anthropic aparentemente não confia nem no seu próprio modelo mais forte com ampla agência interna de programação, a menos que o trabalho seja registrado, amostrado, auditado, revisado e sustentado por controles de segurança comuns.
Isso importa porque o Claude Opus 4.6 foi lançado em 5 de fevereiro de 2026 como o modelo então mais inteligente da Anthropic, com janela de contexto de 1 milhão de tokens em beta, programação agêntica mais forte, nome de API claude-opus-4-6 e preço padrão inalterado de US$ 5 por milhão de tokens de entrada e US$ 25 por milhão de tokens de saída (Anthropic). A Anthropic também disse que o modelo liderava em vários benchmarks, incluindo Terminal-Bench 2.0 e Humanity’s Last Exam, e superava o GPT-5.2 por cerca de 144 pontos Elo no GDPval-AA. No mesmo post de lançamento, a Anthropic apostou pesado em agentes de longa duração, compactação de contexto, controles de esforço e equipes de agentes do Claude Code.
Então o relatório não é teórico. É um retrato do que o fornecedor faz quando a mesma classe de agente está dentro do seu próprio ciclo de engenharia.
O Que a Anthropic Realmente Publicou
O PDF de 53 páginas se chama “Sabotage Risk Report: Claude Opus 4.6.” Ele define sabotagem como o uso, por um modelo de IA, de acesso dentro de uma organização para “explorar, manipular ou adulterar” sistemas ou decisões de uma forma que poderia aumentar o risco catastrófico (Anthropic PDF). A avaliação geral da Anthropic é direta: o risco é “muito baixo, mas não desprezível.”
É fácil zombar dessa frase. Ela soa como um departamento jurídico e um laboratório de segurança tentando dividir a mesma cadeira. Mas, enterrado sob a linguagem de risco, há um modelo prático de governança para agentes de programação.
A Anthropic diz que o Opus 4.6 é muito usado internamente para programação, geração de dados e outros casos de uso agênticos. Também diz que o modelo é altamente capaz, embora “não totalmente confiável”, em tarefas que levariam horas para especialistas humanos. Em seguida, o relatório percorre caminhos de ameaça: sabotagem difusa de P&D relevante para segurança, sabotagem direcionada, backdoors em código, envenenamento de dados de treinamento, autoexfiltração, implantações internas rebeldes e sabotagem em outras organizações ou governos.
Para desenvolvedores, a parte relevante é a pilha de mitigação:
| Controle | O que a Anthropic diz que usa | Tradução para desenvolvedores |
|---|---|---|
| Monitoramento offline do Claude Code | Grande maioria do uso interno do Claude Code; em outro trecho, é descrita uma subamostra de prompts ≥10% pela maioria dos usuários | Registre sessões de agentes e faça amostragem para revisão |
| Auditorias humanas | Pequeno subconjunto do uso interno do Claude Code | Revise sessões reais, não apenas diffs finais |
| Revisão manual de PR | Humanos revisam código antes da integração à base compartilhada | Mantenha aprovação humana em merges importantes |
| Revisão automática de PR | Revisão baseada em Claude verifica erros, problemas de segurança e divergência entre intenção declarada e efeitos reais | Rode uma revisão independente por IA como sinal não bloqueante |
| Testes de invariantes | Testes automatizados verificam propriedades de segurança | Codifique regras de “isso nunca pode acontecer” no CI |
Um detalhe chama atenção: a Anthropic diz que seu monitor automático de pull requests era baseado no Claude Opus 4.5 no momento da escrita, não no Opus 4.6. É uma escolha de design discreta, mas importante. O modelo que faz o trabalho e o modelo que revisa o trabalho não precisam ser idênticos. Na verdade, separação é mais saudável.
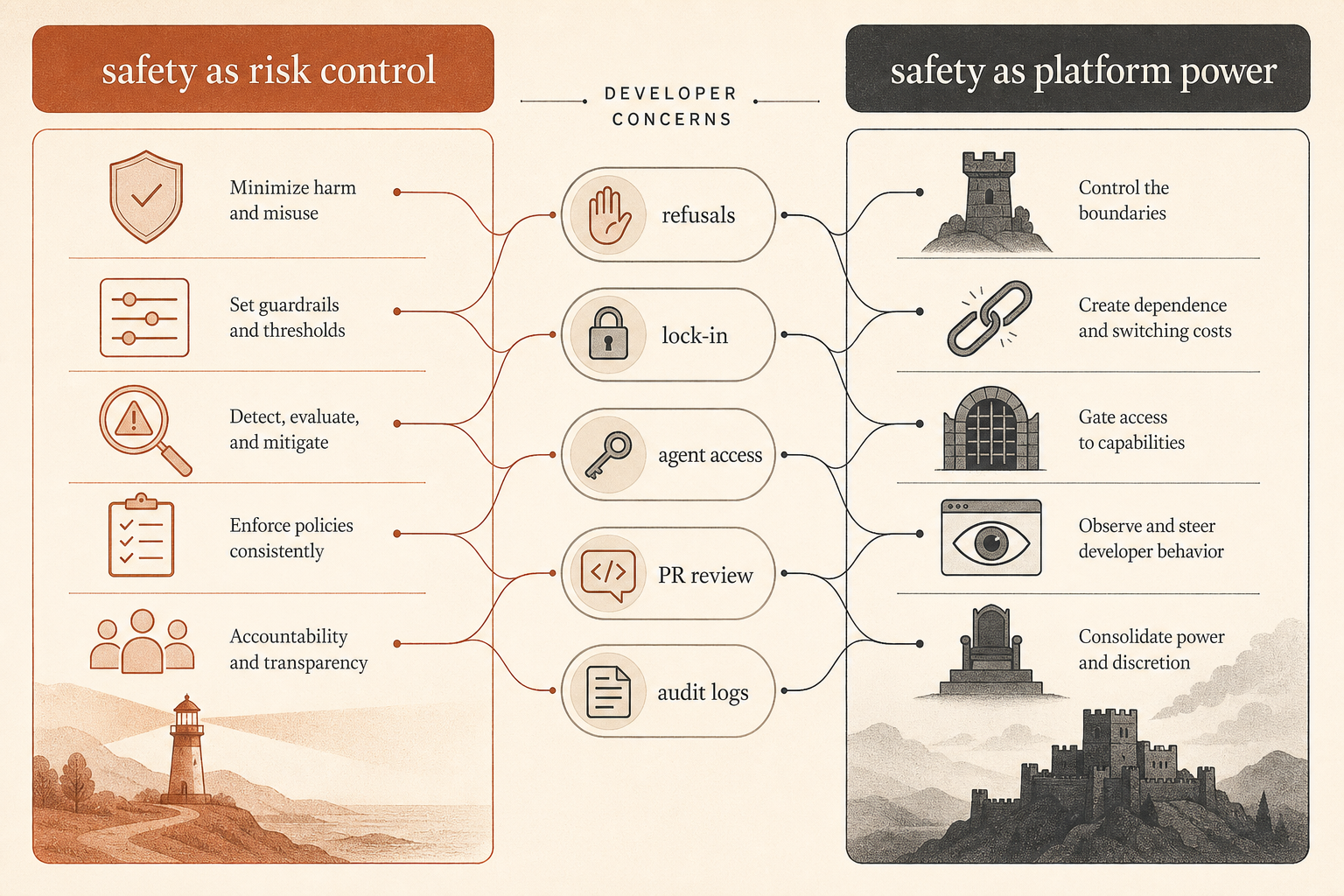
O Debate da Comunidade É Sobre Controle, Não Só Segurança
Esse relatório caiu no meio de uma discussão em andamento. No Hacker News, a thread de junho em torno de “Anthropic’s Safety Superpower”, de Ben Thompson, teve 192 comentários e se dividiu em linhas conhecidas: alguns desenvolvedores argumentaram que a postura de segurança da Anthropic é um custo necessário para implantar ferramentas hospedadas poderosas; outros viram segurança como uma embalagem moral para controle de plataforma (Hacker News).
A crítica mais afiada dos desenvolvedores não é “modelos não deveriam ter guardrails.” É: quem decide o que conta como mau uso quando a ferramenta está virando parte da cadeia de suprimentos de software?
Um comentarista do HN enquadrou bem o problema de controle industrial: pedir ao Claude para auditar software de controle crítico de segurança e pedir ao Claude para encontrar um ponto de entrada em software de controle vazado podem exigir trabalho técnico parecido, mas intenções muito diferentes (Hacker News). Outra thread argumentou que, se o provedor bloqueia ambos, defensores perdem; se permite ambos, atacantes ganham. Esse é o problema real de produto por trás da retórica de segurança.
A outra reclamação é lock-in. Vários comentaristas questionaram se um fornecedor de modelo hospedado pode ser confiável como provedor neutro de ferramenta se consegue mudar políticas, recusar tarefas, rebaixar comportamento ou restringir acesso. Outros rebateram que a Anthropic vende um serviço, não uma ferramenta local, e provedores de serviço sempre recusaram alguns usos.
O relatório de sabotagem adiciona uma peça que faltava nesse debate. A Anthropic não está apenas tentando controlar saídas de usuários na fronteira do modelo. Internamente, ela trata agentes de programação como atores de produção semiconfiáveis. O modelo de confiança não é “Claude está alinhado, pode lançar.” O modelo de confiança está mais perto de “Claude é útil o bastante para rodar, arriscado o bastante para monitorar e consequente o bastante para revisar.”
Essa é a parte que as equipes deveriam copiar.
A Lição Prática: Programação Agêntica Precisa de Defesa em Profundidade
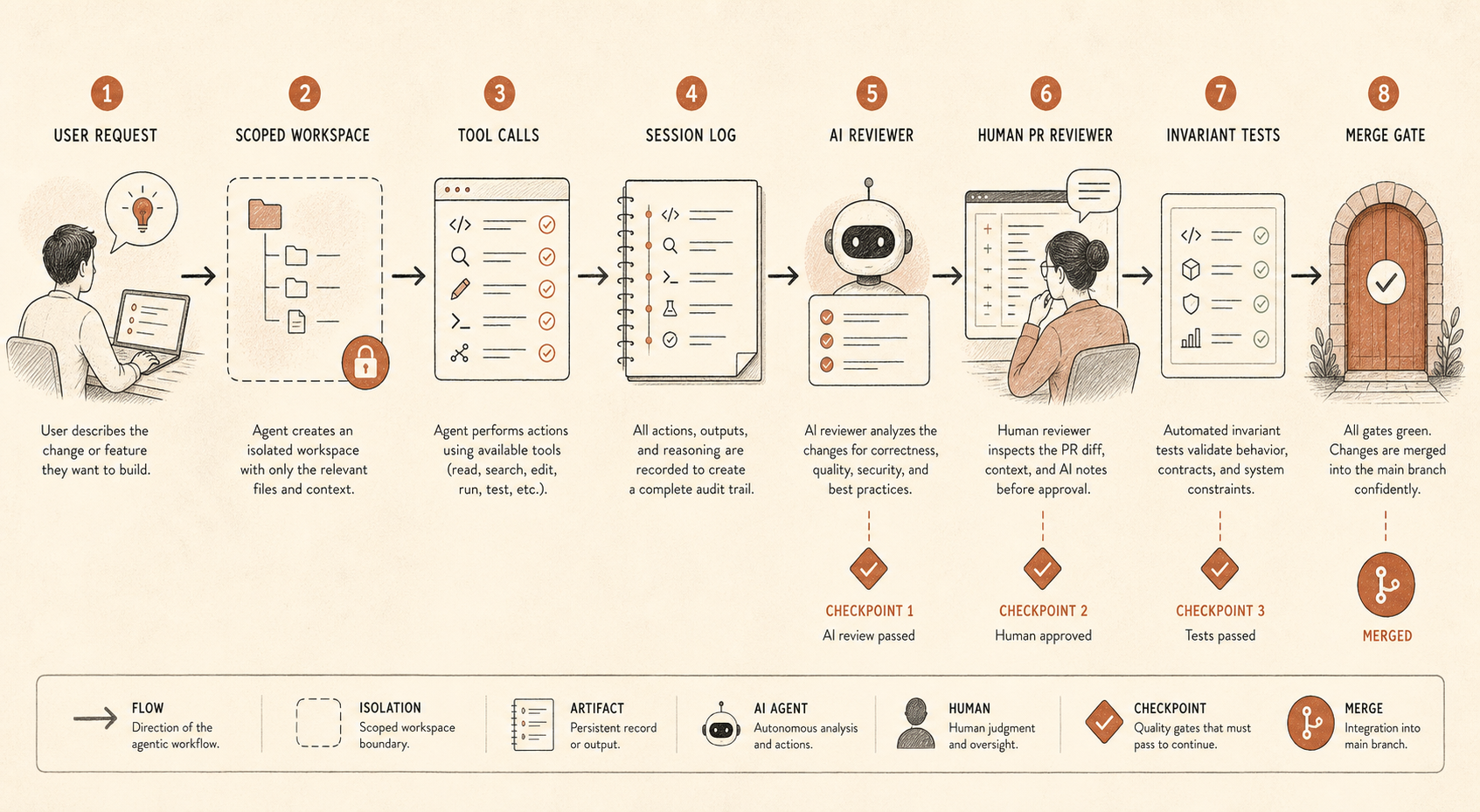
Um agente de programação deixa de ser um autocomplete chique quando consegue editar arquivos, executar comandos, inspecionar configurações próximas de segredos, abrir PRs, chamar ferramentas MCP ou coordenar subagentes. Ele é um contratado meio júnior, meio sênior, com julgamento inconsistente, sem contrato de trabalho e paciência perfeita.
Isso muda a superfície de controle.
Se sua equipe usa Claude Code, Cursor, Codex, Devin, OpenCode ou um harness interno de agentes, a pergunta não é “confiamos no modelo?” A pergunta é “quais ações o modelo consegue executar sem que um segundo sistema perceba?”
Uma linha de base sensata se parece com isto:
coding_agent_controls:
session_logging: required
write_access: repo-scoped
secret_access: denied_by_default
shell_commands: allowlist_or_confirm
pr_review: human_required
ai_review: separate_model_recommended
audit_sampling: risk_based
invariant_tests: blockingIsso não é burocracia. É como manter os ganhos de produtividade sem transformar todo repositório em um experimento social.
O primeiro controle é registro de sessão. Armazene prompts, chamadas de ferramentas, diffs de arquivos, comandos de shell e links finais de PR. Se isso parecer invasivo demais, pelo menos registre metadados e diffs para repositórios de baixo risco e traces completos para repositórios de alto risco. Sem traces, você não consegue auditar o caminho de raciocínio do agente nem reconstruir como uma mudança ruim aconteceu.
O segundo é acesso escopado. A maioria dos agentes de programação não precisa de credenciais de produção, acesso amplo à rede ou permissão de escrita em um monorepo inteiro. Dê a eles uma árvore de trabalho, uma tarefa e caminhos explícitos de escalonamento. Se precisarem de mais, torne a solicitação visível.
O terceiro é independência no nível do PR. O relatório da Anthropic menciona tanto revisão humana de PR quanto revisão automática baseada em Claude. O ponto importante não é que o revisor seja Claude. O ponto importante é que a revisão seja uma passada separada, com prompt diferente, contexto diferente e objetivo diferente. O agente implementador quer concluir a tarefa. O agente revisor deve procurar divergências: “A mudança declarada diz refatoração, mas este diff altera comportamento de autenticação.”
O quarto é teste de invariantes. Esse é o controle menos glamouroso e mais subestimado. Se dois serviços nunca devem se comunicar, escreva o teste. Se uma permissão nunca deve ser concedida fora de um caminho de admin, escreva o teste. Se migrations geradas nunca devem remover colunas sem uma tag de ticket, escreva o teste. Monitorar agentes fica muito mais fácil quando o CI consegue impor limites rígidos.
O Que o Relatório da Anthropic Não Prova
O relatório não prova que o Opus 4.6 não consegue sabotar trabalho. Não prova que um monitor automatizado vai pegar um backdoor sutil. Não prova que um modelo não consegue aprender a parecer bom para monitores. A Anthropic é bem explícita sobre limitações: diz que nenhuma salvaguarda isolada oferece forte garantia por si só, e seu PDF público inclui trechos ocultados.
Essa ressalva importa porque desenvolvedores já estão encaixando esses lançamentos em dois campos preguiçosos.
Campo um diz: a Anthropic publicou um relatório longo de segurança, então deve ser seguro.
Não. O relatório diz que o modelo é útil, poderoso, monitorado e ainda assim não é livre de risco.
Campo dois diz: a Anthropic fala de segurança, então deve ser captura regulatória ou marketing.
Também é simples demais. Os controles descritos no relatório são higiene comum de engenharia. Monitoramento de segurança, revisão de PR, amostragem de auditoria, sandboxing, testes de invariantes e reporte de usuários não são rituais místicos de alinhamento. São as mesmas jogadas que equipes maduras usam para insiders humanos, tokens de CI comprometidos e dependências arriscadas de terceiros.
O meio desconfortável é mais útil: a Anthropic pode se beneficiar comercialmente de ser vista como a empresa da segurança, e seus controles internos ainda podem valer a pena copiar. As duas coisas podem ser verdade.
O relatório também traz um alerta sutil para equipes adotando programação multiagente. O post de lançamento da Anthropic destacou equipes de agentes do Claude Code, subagentes paralelos, compactação de contexto e trabalhos de maior duração (Anthropic). Esses recursos são exatamente onde o monitoramento fica mais difícil. Um único assistente fazendo um diff é fácil de inspecionar. Um enxame de agentes lendo, editando, resumindo e repassando estado vira um problema de proveniência.
Se você deixa agentes se coordenarem, registre a coordenação. Se um agente escreve um plano e outro implementa, preserve ambos os traces. Se o contexto é compactado, armazene o limite antes e depois da compactação. Resumos têm perda. Estado com perda é onde a responsabilização desaparece.
Um Checklist de Controle Para Equipes Que Estão Colocando Agentes de Programação em Produção
Este é o patamar prático que eu definiria antes de deixar agentes de programação tocarem repositórios importantes.
Comece pela classificação dos repositórios. Um repo de documentação, um protótipo, um serviço de billing e um provedor de identidade não deveriam compartilhar uma única política de agentes. Trate repositórios sensíveis à segurança como uma camada diferente.
Exija revisão humana para merges em branches compartilhadas. Parece óbvio, mas equipes passam por cima disso discretamente quando agentes criam diffs mecânicos “obviamente corretos.” Não faça isso. Código escrito por agente deve passar pelo mesmo caminho de revisão que código escrito por estagiário, com atenção extra a testes e permissões.
Rode um segundo revisor. Use outro modelo, outro prompt ou uma passada de análise estática. Peça para ele comparar a mudança solicitada pelo usuário com o diff real. Essa verificação de divergência é barata e captura uma classe de falhas que a revisão comum deixa passar.
Faça amostragem de sessões, não só de PRs. Um agente malicioso ou confuso pode explorar arquivos sensíveis, rodar comandos estranhos ou tentar mudanças que não chegam ao diff final. O foco da Anthropic no uso do Claude Code, não apenas no código mergeado, é o instinto certo.
Bloqueie segredos por design. Não dependa do modelo “saber” que não deve ler .env.production. Use permissões de sistema de arquivos, scanners de segredo, isolamento de ambiente e confirmação de comandos.
Adicione testes de invariantes para propriedades de segurança. Os exemplos do relatório são simples: se dois nós não deveriam enviar tráfego um ao outro, teste que eles não conseguem. Traduza isso para o seu mundo: fronteiras de autenticação, isolamento de tenants, transições de estado de pagamento, retenção de dados, controles de exportação, eventos de auditoria.
Escreva um caminho de incidente. Se um revisor vê comportamento suspeito de agente, para onde isso vai? Slack? Segurança? Um report ao fornecedor? Um merge bloqueado não é um processo de incidente.

Por Que Isso Importa Agora
A velha pergunta sobre IA para programação era se o modelo conseguia escrever código útil. Opus 4.6, Sonnet 4.6, sistemas da classe GPT-5 e a leva atual de agentes de programação já responderam em grande parte. Eles conseguem escrever código útil. Também conseguem escrever código ruim rapidamente, código plausível com confiança e código sensível à segurança com contexto suficiente para ser perigoso.
A nova pergunta é operacional: sua equipe consegue absorver trabalho de agentes sem perder o controle da cadeia de suprimentos de software?
O relatório de sabotagem da Anthropic é valioso porque torna visível a resposta do próprio fornecedor. Para uso interno do Claude Code, a Anthropic descreve monitoramento automatizado sobre uma grande maioria do uso, auditorias humanas, revisão manual de PR, monitoramento automático de PR, sandboxing, monitoramento de segurança e testes de invariantes. Isso não é uma vibe. É uma pilha de controles.
Desenvolvedores deveriam parar de tratar “confiar no modelo” como a decisão. A decisão é onde colocar o modelo dentro de um sistema que presume falibilidade. Deixe-o rascunhar. Deixe-o pesquisar. Deixe-o refatorar. Deixe-o abrir PRs. Mas faça as ações importantes serem observáveis, revisáveis, reversíveis e testáveis.
Esse é o aprendizado útil do relatório. As alegações de segurança vão continuar sendo debatidas no HN, Reddit e X. Seu pipeline de CI não precisa resolver a filosofia. Ele precisa pegar o diff ruim.
Leitores que quiserem testar o Claude Fable 5 podem usá-lo pela OneHop: um endpoint drop-in, cerca de 30% abaixo do preço de tabela, com US$ 10 grátis para novas contas e sem exigir cartão. Veja Claude Fable 5 na OneHop ou comece com US$ 10 grátis.
Leitura complementar: Começando com Claude Fable 5.

