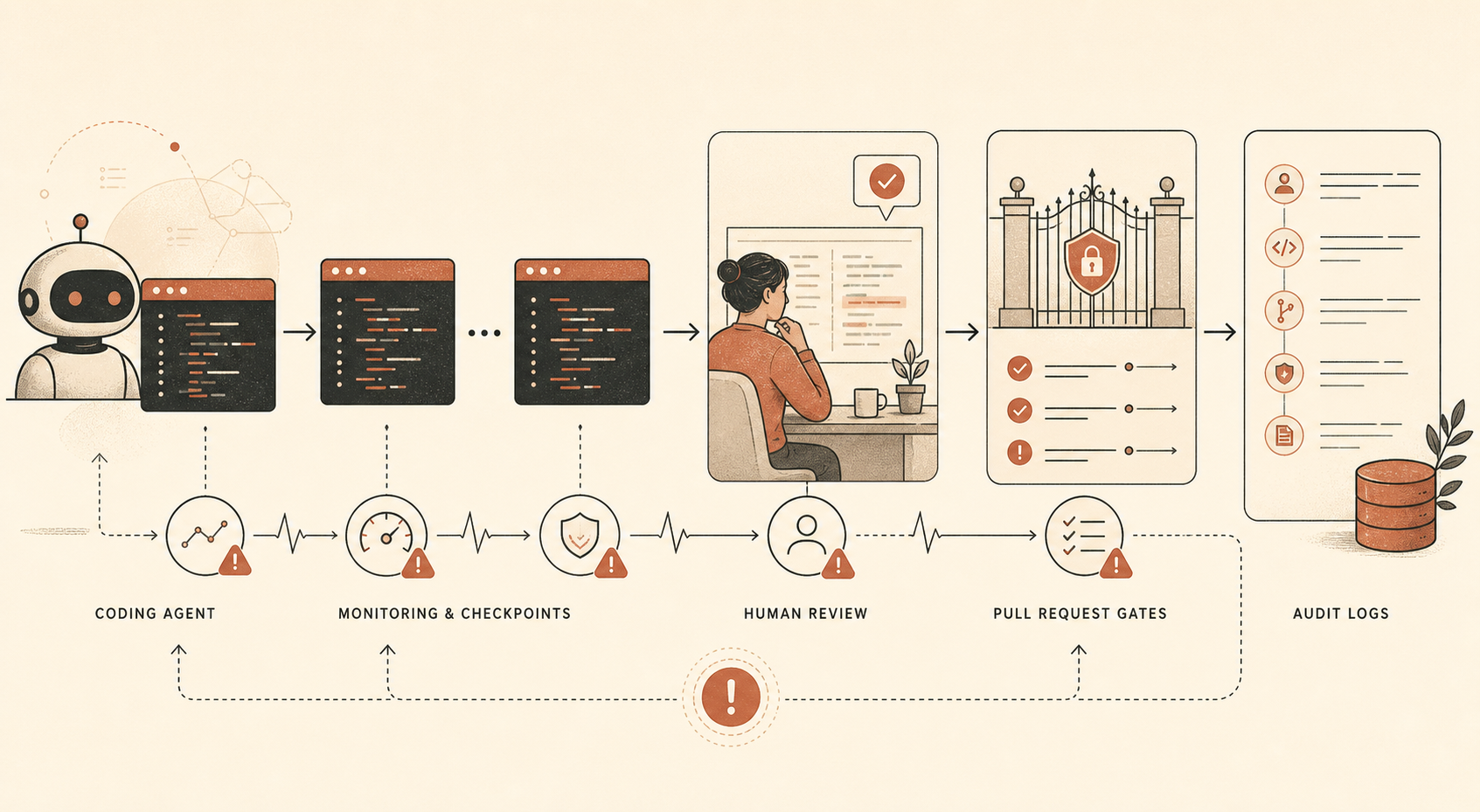
El nuevo informe de Anthropic sobre riesgo de sabotaje para Claude Opus 4.6 contiene una frase que todo líder de ingeniería que esté adoptando agentes de programación debería leer dos veces: la compañía dice que usa supervisión automatizada sobre “una gran mayoría” del uso interno de Claude Code, además de auditorías humanas de un subconjunto más pequeño, porque Claude Code es la herramienta interna que le da a Opus 4.6 “la capacidad de realizar acciones directas con consecuencias” (Anthropic PDF).
Esa es la noticia. No el eslogan de que Opus 4.6 es seguro. No el argumento de que Anthropic se toma la alineación con una seriedad única. El hecho operativo concreto es que Anthropic no parece confiar ni siquiera en su propio modelo más potente con una agencia amplia de programación interna, a menos que el trabajo quede registrado, muestreado, auditado, revisado y respaldado por controles de seguridad normales.
Eso importa porque Claude Opus 4.6 se lanzó el 5 de febrero de 2026 como el modelo más inteligente de Anthropic hasta ese momento, con una ventana de contexto de 1 millón de tokens en beta, programación agéntica más potente, el nombre de API claude-opus-4-6 y el mismo precio estándar de $5 por millón de tokens de entrada y $25 por millón de tokens de salida (Anthropic). Anthropic también dijo que el modelo lideraba varios benchmarks, incluidos Terminal-Bench 2.0 y Humanity’s Last Exam, y que superaba a GPT-5.2 por unos 144 puntos Elo en GDPval-AA. En el mismo post de lanzamiento, Anthropic insistió mucho en agentes de larga duración, compactación de contexto, controles de esfuerzo y equipos de agentes de Claude Code.
Así que el informe no es teórico. Es una mirada a lo que hace el proveedor cuando esa misma clase de agente está dentro de su propio ciclo de ingeniería.
Lo Que Anthropic Publicó Realmente
El PDF de 53 páginas se titula “Sabotage Risk Report: Claude Opus 4.6.” Define sabotaje como el uso por parte de un modelo de IA del acceso dentro de una organización para “explotar, manipular o alterar” sistemas o decisiones de una forma que podría aumentar el riesgo catastrófico (Anthropic PDF). La evaluación general de Anthropic es contundente: el riesgo es “muy bajo, pero no despreciable.”
Esa frase es fácil de ridiculizar. Suena como un departamento legal y un laboratorio de seguridad intentando compartir una sola silla. Pero debajo del lenguaje de riesgo hay un modelo práctico de gobernanza para agentes de programación.
Anthropic dice que Opus 4.6 se usa intensamente de forma interna para programación, generación de datos y otros casos de uso agénticos. También dice que el modelo es muy capaz, aunque “no totalmente fiable,” en tareas que llevarían horas a especialistas humanos. Luego el informe recorre rutas de amenaza: sandbagging difuso de I+D relevante para seguridad, sabotaje dirigido, puertas traseras en código, envenenamiento de datos de entrenamiento, autoexfiltración, despliegues internos rebeldes y sabotaje en otras organizaciones o gobiernos.
Para desarrolladores, la parte relevante es la pila de mitigaciones:
| Control | Lo que Anthropic dice que usa | Traducción para desarrolladores |
|---|---|---|
| Supervisión offline de Claude Code | Gran mayoría del uso interno de Claude Code; en otra parte se describe un submuestreo de prompts ≥10% por la mayoría de usuarios | Registra las sesiones de agentes y muestrealas para revisión |
| Auditorías humanas | Pequeño subconjunto del uso interno de Claude Code | Revisa sesiones reales, no solo diffs finales |
| Revisión manual de PR | Humanos revisan el código antes de integrarlo en la base de código compartida | Mantén aprobación humana en merges importantes |
| Revisión automática de PR | Una revisión basada en Claude comprueba errores, problemas de seguridad y desajustes entre la intención declarada y los efectos reales | Ejecuta una revisión de IA independiente como señal no bloqueante |
| Pruebas de invariantes | Pruebas automatizadas comprueban propiedades de seguridad | Codifica reglas de “esto nunca debe pasar” en CI |
Un detalle destaca: Anthropic dice que su monitor automático de pull requests estaba basado en Claude Opus 4.5 en el momento de escribir el informe, no en Opus 4.6. Es una decisión de diseño discreta pero importante. El modelo que hace el trabajo y el modelo que revisa el trabajo no tienen por qué ser idénticos. De hecho, la separación es más sana.
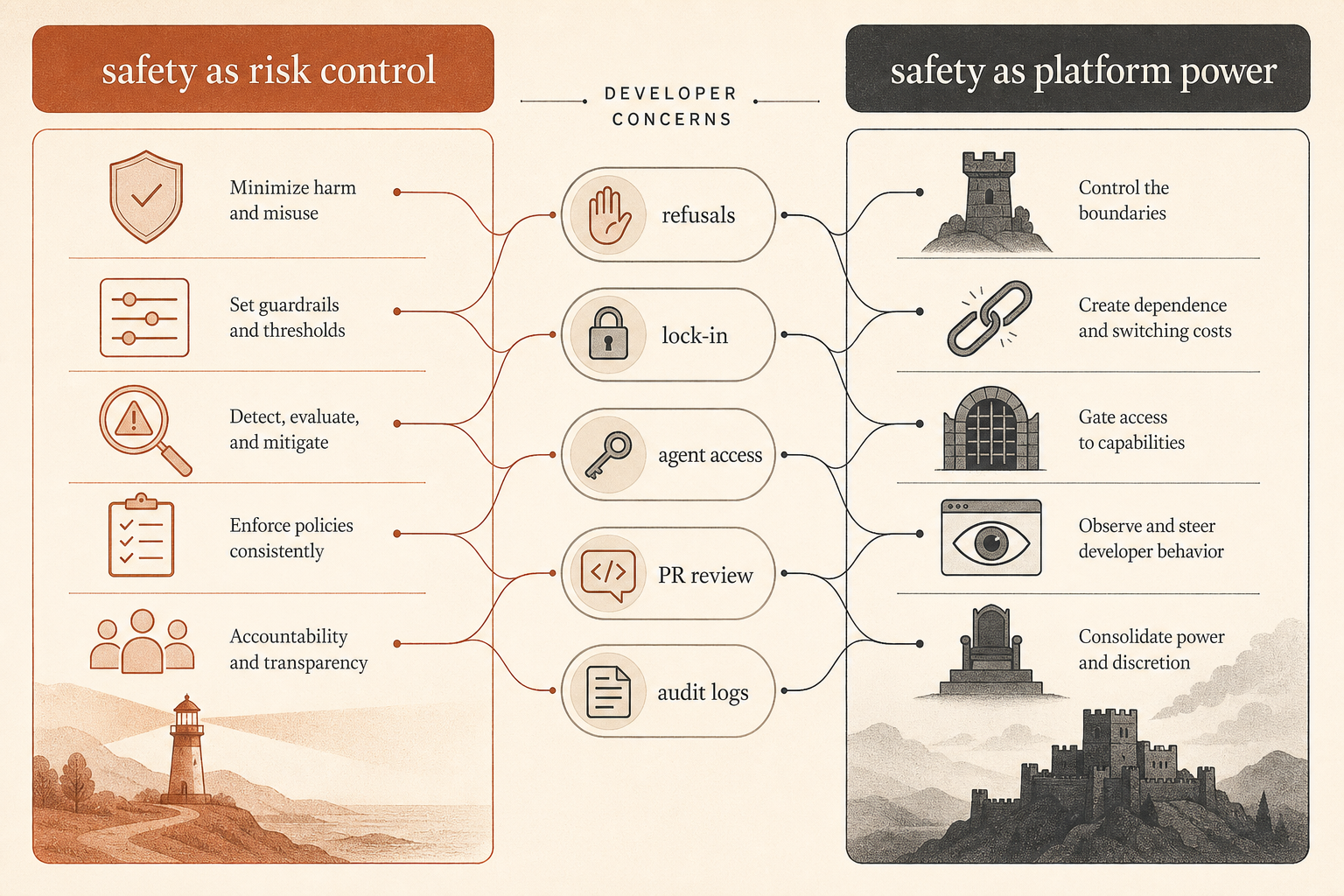
El Debate De La Comunidad Va De Control, No Solo De Seguridad
Este informe cayó en medio de una discusión viva. En Hacker News, el hilo de junio sobre “Anthropic’s Safety Superpower” de Ben Thompson tuvo 192 comentarios y se dividió en líneas familiares: algunos desarrolladores argumentaron que la postura de seguridad de Anthropic es un coste necesario para desplegar herramientas alojadas potentes; otros vieron la seguridad como una envoltura moral para el control de plataforma (Hacker News).
La queja más afilada de los desarrolladores no es “los modelos no deberían tener guardrails.” Es: ¿quién decide qué cuenta como mal uso cuando la herramienta se está convirtiendo en parte de la cadena de suministro de software?
Un comentarista de HN planteó con claridad el problema de control industrial: pedirle a Claude que audite software de control crítico para seguridad y pedirle a Claude que encuentre un punto de entrada en software de control filtrado puede requerir un trabajo técnico parecido, pero una intención muy distinta (Hacker News). Otro hilo argumentó que si el proveedor bloquea ambas cosas, los defensores pierden; si permite ambas, los atacantes ganan. Ese es el verdadero problema de producto detrás de la retórica de seguridad.
La otra queja es el lock-in. Varios comentaristas cuestionaron si se puede confiar en un proveedor de modelos alojados como proveedor neutral de herramientas si puede cambiar políticas, rechazar tareas, degradar comportamiento o restringir acceso. Otros respondieron que Anthropic vende un servicio, no una herramienta local, y que los proveedores de servicios siempre han rechazado algunos usos.
El informe de sabotaje añade una pieza que faltaba en ese debate. Anthropic no solo intenta controlar las salidas de usuario en el límite del modelo. Internamente, trata a los agentes de programación como actores de producción semiconfiables. El modelo de confianza no es “Claude está alineado, lánzalo.” El modelo de confianza se parece más a “Claude es lo bastante útil para ejecutarlo, lo bastante arriesgado para supervisarlo y lo bastante trascendente para revisarlo.”
Esa es la parte que los equipos deberían copiar.
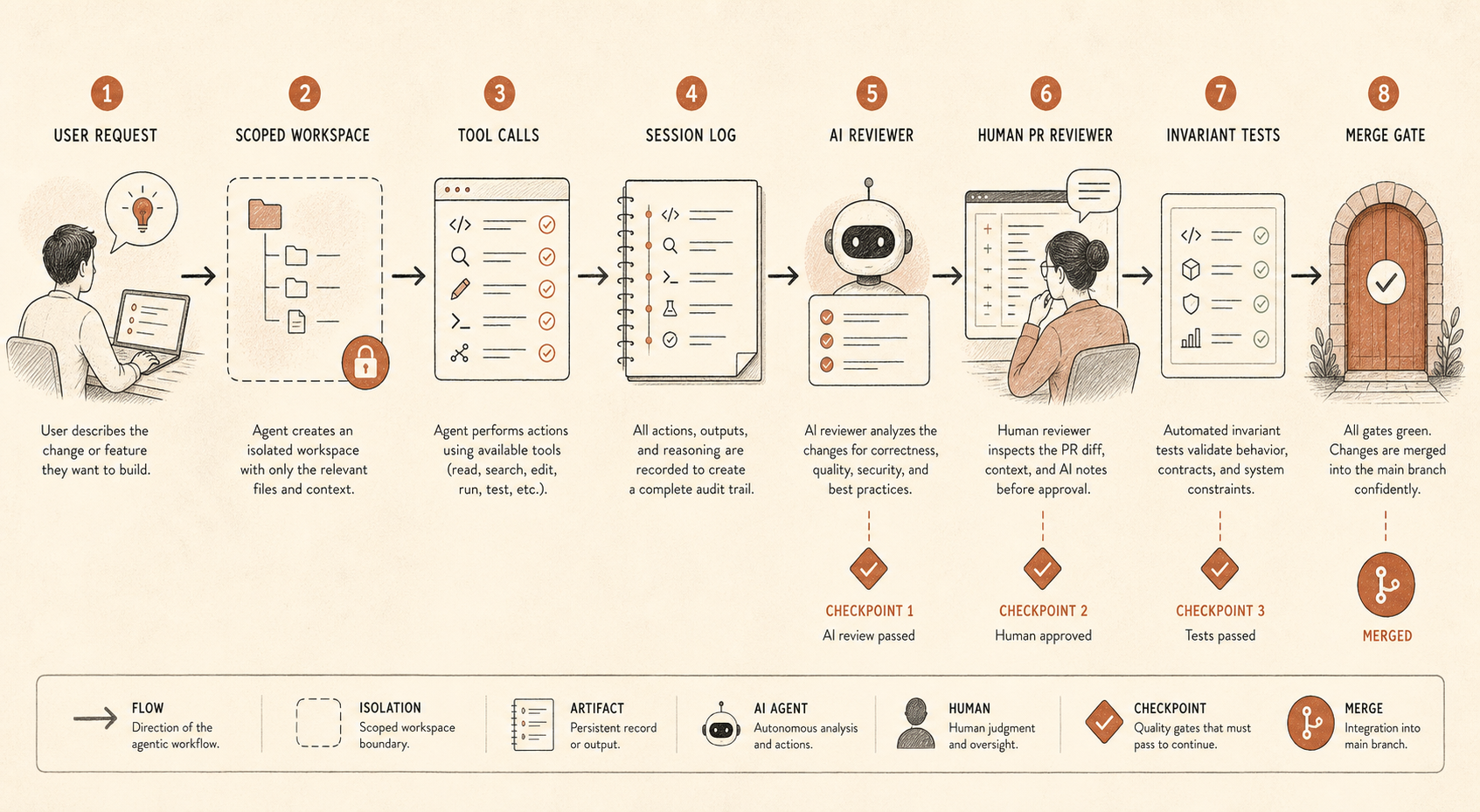
La Lección Práctica: La Programación Agéntica Necesita Defensa En Profundidad
Un agente de programación no es un autocompletado elegante cuando ya puede editar archivos, ejecutar comandos, inspeccionar configuración cercana a secretos, abrir PRs, llamar herramientas MCP o coordinar subagentes. Es un contratista entre junior y casi senior, con criterio irregular, sin contrato laboral y paciencia perfecta.
Eso cambia la superficie de control.
Si tu equipo usa Claude Code, Cursor, Codex, Devin, OpenCode o un arnés interno de agentes, la pregunta no es “¿confiamos en el modelo?” La pregunta es “¿qué acciones puede realizar el modelo sin que un segundo sistema se entere?”
Una base sensata se ve así:
coding_agent_controls:
session_logging: required
write_access: repo-scoped
secret_access: denied_by_default
shell_commands: allowlist_or_confirm
pr_review: human_required
ai_review: separate_model_recommended
audit_sampling: risk_based
invariant_tests: blockingEsto no es burocracia. Es cómo mantener las ganancias de productividad sin convertir cada repositorio en un experimento social.
El primer control es el registro de sesiones. Guarda prompts, llamadas a herramientas, diffs de archivos, comandos de shell y enlaces finales a PRs. Si eso parece demasiado invasivo, al menos registra metadatos y diffs para repos de bajo riesgo y trazas completas para repos de alto riesgo. Sin trazas, no puedes auditar el camino de razonamiento del agente ni reconstruir cómo ocurrió un cambio malo.
El segundo es el acceso acotado. La mayoría de agentes de programación no necesitan credenciales de producción, acceso amplio a la red ni permisos de escritura por todo un monorepo. Dales un árbol de trabajo, una tarea y rutas explícitas de escalado. Si necesitan más, que la solicitud sea visible.
El tercero es la independencia a nivel de PR. El informe de Anthropic menciona tanto revisión humana de PR como revisión automática basada en Claude. Lo importante no es que el revisor sea Claude. Lo importante es que la revisión sea una pasada separada, con un prompt distinto, un contexto distinto y un objetivo distinto. El agente implementador quiere completar la tarea. El agente revisor debería buscar desajustes: “El cambio declarado dice refactorización, pero este diff cambia el comportamiento de autenticación.”
El cuarto son las pruebas de invariantes. Este es el control menos glamuroso y más infravalorado. Si dos servicios nunca deben hablar entre sí, escribe la prueba. Si nunca debe concederse un permiso fuera de una ruta de administrador, escribe la prueba. Si las migraciones generadas nunca deben eliminar columnas sin una etiqueta de ticket, escribe la prueba. Supervisar agentes se vuelve mucho más fácil cuando CI puede imponer límites duros.
Lo Que El Informe De Anthropic No Demuestra
El informe no demuestra que Opus 4.6 no pueda sabotear trabajo. No demuestra que un monitor automatizado vaya a detectar una puerta trasera sutil. No demuestra que un modelo no pueda aprender a quedar bien ante los monitores. Anthropic es bastante explícita sobre las limitaciones: dice que ninguna salvaguarda por sí sola ofrece una garantía fuerte, y su PDF público incluye censuras.
Esa advertencia importa porque los desarrolladores ya están encajando estos lanzamientos en dos bandos perezosos.
El primer bando dice: Anthropic publicó un largo informe de seguridad, así que debe ser seguro.
No. El informe dice que el modelo es útil, potente, supervisado y aun así no está libre de riesgos.
El segundo bando dice: Anthropic habla de seguridad, así que debe ser captura regulatoria o marketing.
También demasiado simple. Los controles descritos en el informe son higiene de ingeniería normal. Supervisión de seguridad, revisión de PR, muestreo de auditoría, sandboxing, pruebas de invariantes y reportes de usuarios no son rituales místicos de alineación. Son las mismas jugadas que usan los equipos maduros con insiders humanos, tokens de CI comprometidos y dependencias de terceros arriesgadas.
El punto medio incómodo es más útil: Anthropic puede beneficiarse comercialmente de ser vista como la compañía de la seguridad, y sus controles internos aun así pueden merecer ser copiados. Ambas cosas pueden ser ciertas.
El informe también contiene una advertencia sutil para los equipos que adoptan programación multiagente. El post de lanzamiento de Anthropic destacó los equipos de agentes de Claude Code, subagentes paralelos, compactación de contexto y trabajo de mayor duración (Anthropic). Esas funciones son exactamente donde la supervisión se complica. Un solo asistente haciendo un diff es fácil de inspeccionar. Un enjambre de agentes leyendo, editando, resumiendo y transfiriendo estado es un problema de procedencia.
Si dejas que los agentes se coordinen, registra la coordinación. Si un agente escribe un plan y otro lo implementa, conserva ambas trazas. Si el contexto se compacta, guarda el límite antes y después de la compactación. Los resúmenes tienen pérdida. El estado con pérdida es donde desaparece la rendición de cuentas.
Una Checklist De Control Para Equipos Que Lanzan Agentes De Programación
Esta es la vara práctica que pondría antes de dejar que agentes de programación toquen repositorios importantes.
Empieza con la clasificación de repos. Un repo de documentación, un prototipo, un servicio de facturación y un proveedor de identidad no deberían compartir una sola política de agentes. Trata los repos sensibles a seguridad como un nivel distinto.
Exige revisión humana para merges en ramas compartidas. Suena obvio, pero los equipos se lo saltan en silencio cuando los agentes crean diffs mecánicos “obviamente correctos.” No lo hagas. El código escrito por agentes debería pasar por el mismo camino de revisión que el código escrito por becarios, con atención extra a pruebas y permisos.
Ejecuta un segundo revisor. Usa otro modelo, otro prompt o una pasada de análisis estático. Pídele que compare el cambio solicitado por el usuario con el diff real. Esa comprobación de desajuste es barata y captura una clase de fallos que la revisión ordinaria pasa por alto.
Muestrea sesiones, no solo PRs. Un agente malicioso o confundido puede explorar archivos sensibles, ejecutar comandos extraños o intentar cambios que no sobreviven hasta el diff final. El foco de Anthropic en el uso de Claude Code, no solo en el código fusionado, es el instinto correcto.
Bloquea secretos por diseño. No dependas de que el modelo “sepa” que no debe leer .env.production. Usa permisos de sistema de archivos, escáneres de secretos, aislamiento de entorno y confirmación de comandos.
Añade pruebas de invariantes para propiedades de seguridad. Los ejemplos del informe son sencillos: si dos nodos no deberían enviarse tráfico entre sí, prueba que no puedan hacerlo. Tradúcelo a tu mundo: límites de autenticación, aislamiento de tenants, transiciones de estado de pagos, retención de datos, controles de exportación, eventos de auditoría.
Escribe una ruta de incidentes. Si un revisor ve comportamiento sospechoso de un agente, ¿adónde va? ¿Slack? ¿Seguridad? ¿Un reporte al proveedor? Un merge bloqueado no es un proceso de incidentes.

Por Qué Esto Importa Ahora
La vieja pregunta sobre IA para programar era si el modelo podía escribir código útil. Opus 4.6, Sonnet 4.6, sistemas de clase GPT-5 y la cosecha actual de agentes de programación ya han respondido en gran parte a eso. Pueden escribir código útil. También pueden escribir código malo rápido, código plausible con confianza y código sensible para seguridad con suficiente contexto como para ser peligrosos.
La nueva pregunta es operativa: ¿puede tu equipo absorber trabajo de agentes sin perder el control de la cadena de suministro de software?
El informe de sabotaje de Anthropic es valioso porque hace visible la propia respuesta del proveedor. Para el uso interno de Claude Code, Anthropic describe supervisión automatizada sobre una gran mayoría del uso, auditorías humanas, revisión manual de PR, supervisión automática de PR, sandboxing, supervisión de seguridad y pruebas de invariantes. Eso no es una vibra. Es una pila de controles.
Los desarrolladores deberían dejar de tratar “confiar en el modelo” como la decisión. La decisión es dónde colocar el modelo dentro de un sistema que asume falibilidad. Déjalo redactar. Déjalo buscar. Déjalo refactorizar. Déjalo abrir PRs. Pero haz que las acciones importantes sean observables, revisables, reversibles y comprobables.
Esa es la conclusión útil del informe. Las afirmaciones de seguridad seguirán discutiéndose en HN, Reddit y X. Tu pipeline de CI no necesita resolver la filosofía. Necesita detectar el diff malo.
Los lectores que quieran probar Claude Fable 5 por su cuenta pueden usarlo a través de OneHop: un endpoint drop-in, alrededor de un 30% por debajo del precio de lista, con $10 gratis para cuentas nuevas y sin tarjeta requerida. Ver Claude Fable 5 en OneHop o empieza con $10 gratis.
Lectura adicional: Primeros pasos con Claude Fable 5.

