يتضمن تقرير Anthropic الجديد عن خطر التخريب في Claude Opus 4.6 جملة واحدة ينبغي لكل قائد هندسي يتبنى وكلاء البرمجة أن يقرأها مرتين: تقول الشركة إنها تستخدم مراقبة آلية على «الغالبية الكبيرة» من استخدام Claude Code داخليًا، إضافة إلى تدقيق بشري على عينة أصغر، لأن Claude Code هو الأداة الداخلية التي تمنح Opus 4.6 «القدرة على اتخاذ أفعال مباشرة ذات أثر» (Anthropic PDF).
هذه هي الخبر. لا الشعار القائل إن Opus 4.6 آمن. ولا الحجة بأن Anthropic جادة بشكل استثنائي في مسألة المواءمة. الحقيقة التشغيلية الملموسة هي أن Anthropic، على ما يبدو، لا تثق حتى بأقوى نماذجها حين يُمنح وكالة برمجية داخلية واسعة، إلا إذا كان العمل مسجلًا، ومأخوذًا منه عينات، ومدققًا، ومراجعًا، ومدعومًا بضوابط أمنية عادية.
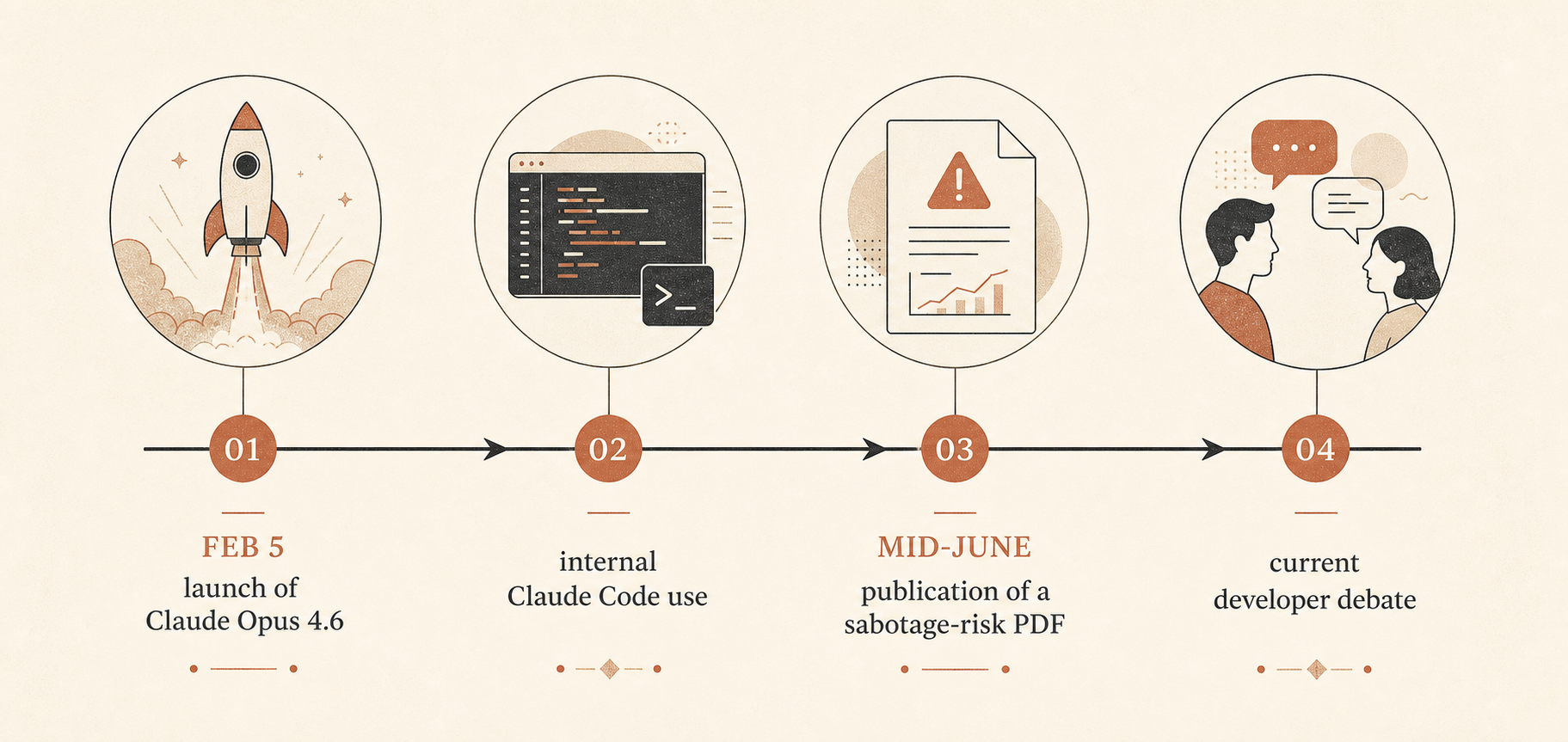
وهذا مهم لأن Claude Opus 4.6 أُطلق في 5 فبراير 2026 بوصفه أذكى نماذج Anthropic حينها، مع نافذة سياق بمليون رمز في النسخة التجريبية، وقدرات أقوى في البرمجة الوكيلة، واسم API هو claude-opus-4-6، وتسعير قياسي غير متغير قدره 5 دولارات لكل مليون رمز إدخال و25 دولارًا لكل مليون رمز إخراج (Anthropic). وقالت Anthropic أيضًا إن النموذج تصدر عدة مقاييس، منها Terminal-Bench 2.0 وHumanity’s Last Exam، وتفوق على GPT-5.2 بنحو 144 نقطة Elo في GDPval-AA. وفي منشور الإطلاق نفسه، دفعت Anthropic بقوة نحو الوكلاء طويلي التشغيل، وضغط السياق، وضوابط الجهد، وفرق وكلاء Claude Code.
لذلك فالتقرير ليس نظريًا. إنه لمحة عما يفعله المورّد عندما تدخل الفئة نفسها من الوكلاء داخل دورة الهندسة الخاصة به.
ما الذي نشرته Anthropic فعلًا
يحمل ملف PDF المؤلف من 53 صفحة عنوان “Sabotage Risk Report: Claude Opus 4.6.” ويعرّف التخريب بأنه استخدام نموذج ذكاء اصطناعي لصلاحياته داخل مؤسسة من أجل «استغلال» الأنظمة أو القرارات أو «التلاعب بها» أو «العبث بها» بطريقة قد ترفع خطرًا كارثيًا (Anthropic PDF). تقييم Anthropic العام مباشر: الخطر «منخفض جدًا لكنه ليس معدومًا».
هذه العبارة سهلة السخرية. تبدو كأن قسمًا قانونيًا ومختبر سلامة يحاولان الجلوس على كرسي واحد. لكن تحت لغة المخاطر، يوجد نموذج عملي لحوكمة وكلاء البرمجة.
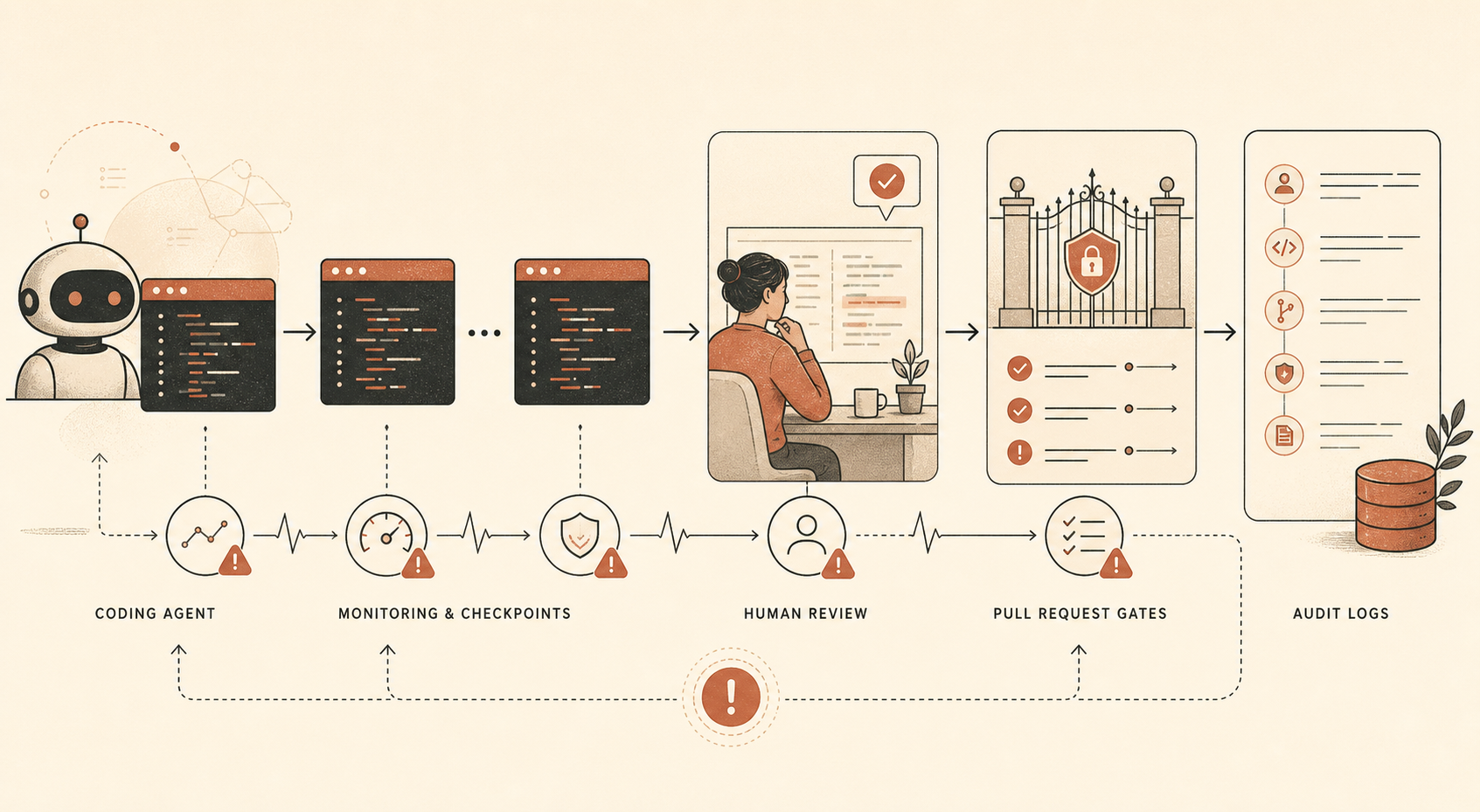
تقول Anthropic إن Opus 4.6 يُستخدم داخليًا بكثافة في البرمجة، وتوليد البيانات، وحالات استخدام وكيلة أخرى. وتقول أيضًا إن النموذج شديد القدرة، وإن كان «غير موثوق بالكامل»، في مهام قد تستغرق من متخصصين بشر ساعات. ثم يستعرض التقرير مسارات التهديد: التراخي الخفي واسع النطاق في أبحاث وتطوير مرتبطة بالسلامة، والتخريب الموجه، والأبواب الخلفية في الكود، وتسميم بيانات التدريب، وتسريب الذات، وعمليات نشر داخلية متمردة، والتخريب في مؤسسات أو حكومات أخرى.
بالنسبة إلى المطورين، الجزء المهم هو طبقة التخفيف:
| Control | What Anthropic says it uses | Developer translation |
|---|---|---|
| مراقبة Claude Code دون اتصال | الغالبية الكبيرة من استخدام Claude Code داخليًا؛ وفي موضع آخر تُذكر عينة فرعية لا تقل عن 10% من المطالبات لدى معظم المستخدمين | سجّل جلسات الوكيل وخذ منها عينات للمراجعة |
| تدقيقات بشرية | عينة صغيرة من استخدام Claude Code داخليًا | راجع الجلسات الفعلية، لا الفروقات النهائية فقط |
| مراجعة PR يدوية | يراجع البشر الكود قبل دمجه في قاعدة كود مشتركة | أبقِ موافقة البشر على عمليات الدمج المهمة |
| مراجعة PR آلية | مراجعة مبنية على Claude تتحقق من الأخطاء، والمشكلات الأمنية، والتطابق بين النية المعلنة والآثار الفعلية | شغّل مراجعة ذكاء اصطناعي مستقلة كإشارة غير حاسمة |
| اختبارات الثوابت | اختبارات آلية تتحقق من الخصائص الأمنية | حوّل قواعد «يجب ألا يحدث أبدًا» إلى CI |
تفصيل واحد يلفت الانتباه: تقول Anthropic إن مراقب طلبات السحب الآلي لديها كان مبنيًا على Claude Opus 4.5 وقت كتابة التقرير، لا على Opus 4.6. هذا خيار تصميمي هادئ لكنه مهم. النموذج الذي ينفذ العمل والنموذج الذي يراجع العمل لا يجب أن يكونا متطابقين. بل إن الفصل بينهما أصح.
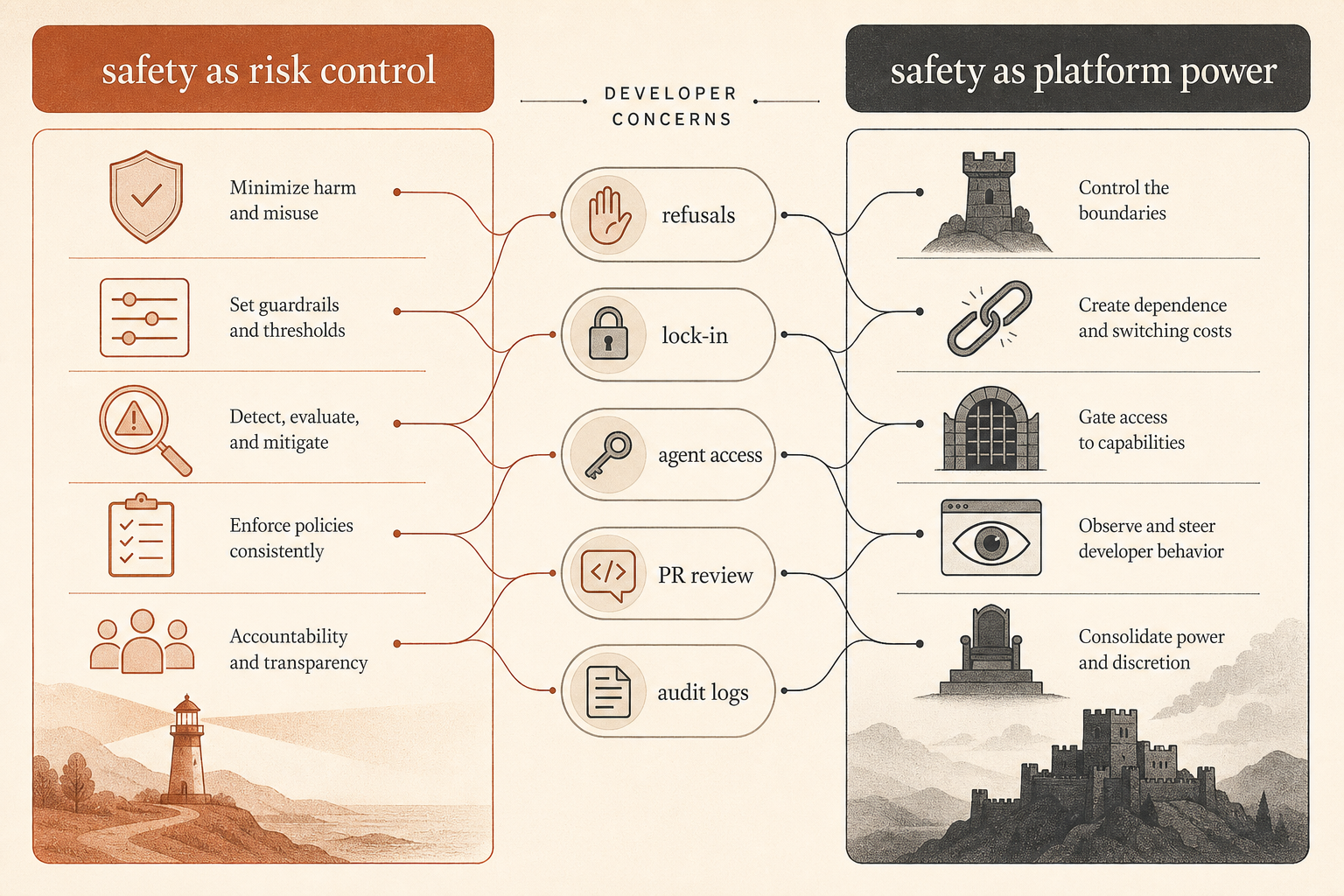
نقاش المجتمع يدور حول السيطرة، لا السلامة فقط
وصل هذا التقرير إلى قلب جدل قائم. في Hacker News، كان نقاش يونيو حول مقال Ben Thompson بعنوان “Anthropic’s Safety Superpower” يضم 192 تعليقًا وانقسم وفق خطوط مألوفة: رأى بعض المطورين أن موقف Anthropic من السلامة تكلفة ضرورية لنشر أدوات مستضافة قوية؛ ورأى آخرون أن السلامة غلاف أخلاقي لسلطة المنصة (Hacker News).
أدق شكوى من المطورين ليست «ينبغي ألا تكون للنماذج أي حواجز». بل هي: من يقرر ما الذي يُعد إساءة استخدام عندما تصبح الأداة جزءًا من سلسلة توريد البرمجيات؟
أحد معلقي HN صاغ مشكلة التحكم الصناعي بوضوح: أن تطلب من Claude تدقيق برمجيات تحكم حرجة للسلامة، وأن تطلب من Claude إيجاد نقطة دخول في برمجيات تحكم مسربة، قد يتطلبان عملًا تقنيًا متشابهًا، لكن النية مختلفة تمامًا (Hacker News). وجادل خيط آخر بأنه إذا حظر المزوّد الحالتين معًا خسر المدافعون؛ وإذا سمح بالحالتين معًا كسب المهاجمون. هذه هي مشكلة المنتج الحقيقية خلف خطاب السلامة.
الشكوى الأخرى هي الانغلاق على المورّد. تساءل عدة معلقين عمّا إذا كان يمكن الوثوق بمورّد نموذج مستضاف كمزوّد أداة محايد إذا كان يستطيع تغيير السياسات، ورفض المهام، وخفض جودة السلوك، أو تقييد الوصول. ورد آخرون بأن Anthropic تبيع خدمة، لا أداة محلية، ومزوّدو الخدمات لطالما رفضوا بعض الاستخدامات.
يضيف تقرير التخريب قطعة ناقصة إلى ذلك النقاش. Anthropic لا تحاول فقط التحكم في مخرجات المستخدم عند حدود النموذج. داخليًا، تتعامل مع وكلاء البرمجة كجهات إنتاج شبه موثوقة. نموذج الثقة ليس «Claude موائم، فلنشحنه». نموذج الثقة أقرب إلى «Claude مفيد بما يكفي لتشغيله، وخطر بما يكفي لمراقبته، ومؤثر بما يكفي لمراجعته».
هذا هو الجزء الذي ينبغي للفرق نسخه.
الدرس العملي: البرمجة الوكيلة تحتاج دفاعًا متعدد الطبقات
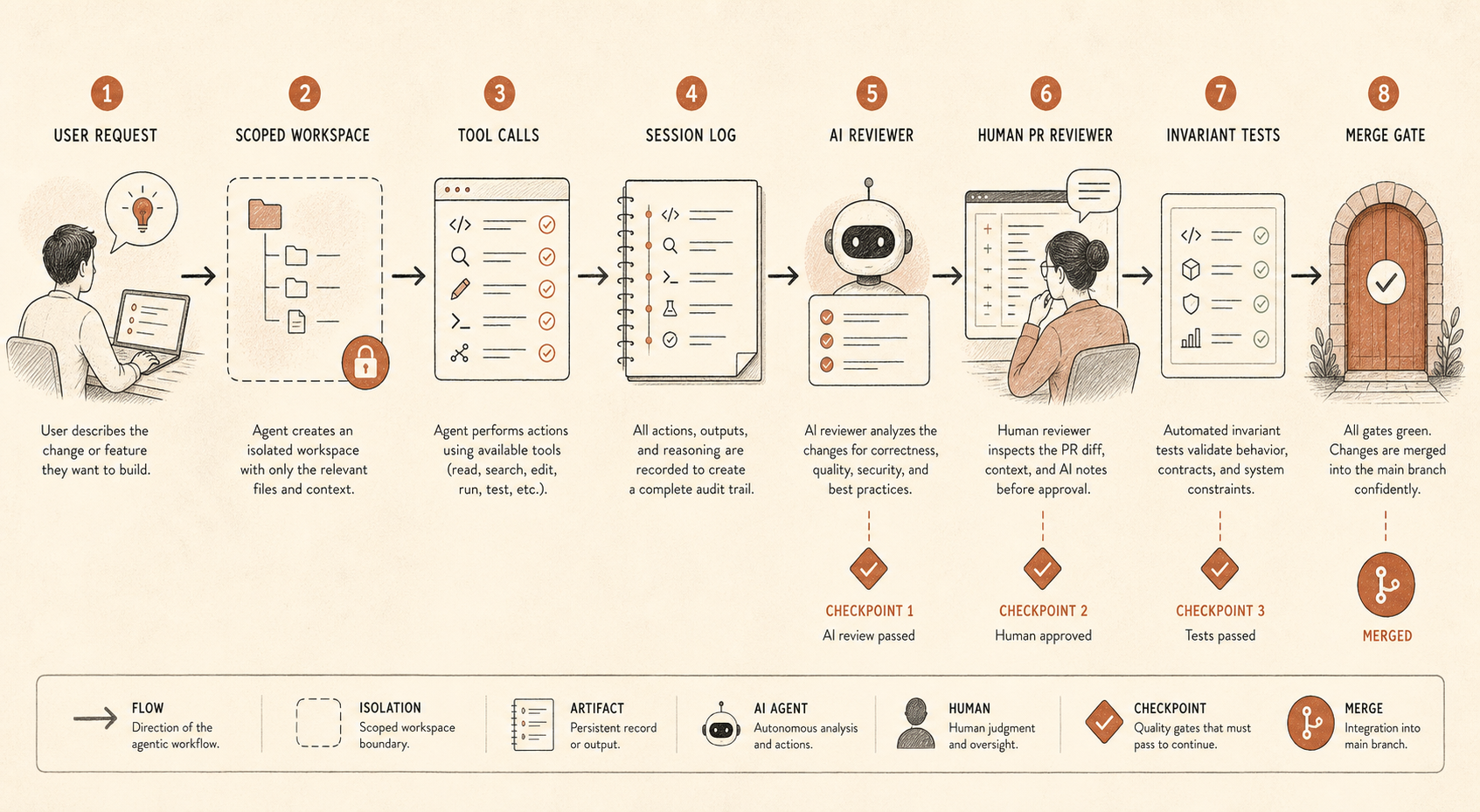
لا يعود وكيل البرمجة مجرد إكمال تلقائي فاخر عندما يصبح قادرًا على تعديل الملفات، وتشغيل الأوامر، وتفقد إعدادات قريبة من الأسرار، وفتح PRs، واستدعاء أدوات MCP، أو تنسيق وكلاء فرعيين. إنه مقاول بين مبتدئ وشبه خبير، بحكم متذبذب، بلا عقد عمل، وبصبر كامل.
هذا يغيّر سطح التحكم.
إذا كان فريقك يستخدم Claude Code أو Cursor أو Codex أو Devin أو OpenCode أو إطار وكلاء داخليًا، فالسؤال ليس «هل نثق بالنموذج؟». السؤال هو «ما الأفعال التي يستطيع النموذج اتخاذها من دون أن يلاحظها نظام ثانٍ؟».
خط أساس معقول يبدو هكذا:
coding_agent_controls:
session_logging: required
write_access: repo-scoped
secret_access: denied_by_default
shell_commands: allowlist_or_confirm
pr_review: human_required
ai_review: separate_model_recommended
audit_sampling: risk_based
invariant_tests: blockingهذه ليست بيروقراطية. هذه هي الطريقة التي تحتفظ بها بمكاسب الإنتاجية من دون تحويل كل مستودع إلى تجربة اجتماعية.
أول ضابط هو تسجيل الجلسات. خزّن المطالبات، واستدعاءات الأدوات، وفروقات الملفات، وأوامر الطرفية، وروابط PR النهائية. إذا بدا هذا متطفلًا أكثر من اللازم، فسجّل على الأقل البيانات الوصفية والفروقات للمستودعات منخفضة المخاطر، والمسارات الكاملة للمستودعات عالية المخاطر. من دون آثار، لا يمكنك تدقيق مسار استدلال الوكيل أو إعادة بناء كيفية حدوث تغيير سيئ.
الثاني هو الوصول المحدد النطاق. معظم وكلاء البرمجة لا يحتاجون إلى بيانات اعتماد الإنتاج، أو وصول شبكي واسع، أو صلاحية كتابة عبر monorepo كامل. أعطهم شجرة عمل، ومهمة، ومسارات تصعيد واضحة. إذا احتاجوا إلى أكثر، فاجعل الطلب مرئيًا.
الثالث هو الاستقلالية على مستوى PR. يذكر تقرير Anthropic مراجعة PR بشرية ومراجعة آلية مبنية على Claude. الجزء المهم ليس أن المراجع هو Claude. الجزء المهم هو أن المراجعة تمريرة منفصلة بمطالبة مختلفة، وسياق مختلف، وهدف مختلف. الوكيل المنفذ يريد إكمال المهمة. أما الوكيل المراجع فينبغي أن يبحث عن عدم التطابق: «التغيير المعلن يقول إعادة هيكلة، لكن هذا الفرق يغيّر سلوك المصادقة».
الرابع هو اختبار الثوابت. هذا أقل الضوابط بريقًا وأكثرها تعرضًا للتجاهل. إذا كان يجب ألا تتواصل خدمتان أبدًا، فاكتب الاختبار. إذا كان يجب ألا تُمنح صلاحية خارج مسار المدير، فاكتب الاختبار. إذا كان يجب ألا تسقط ترحيلات مولدة أعمدة من دون وسم تذكرة، فاكتب الاختبار. تصبح مراقبة الوكلاء أسهل بكثير عندما يستطيع CI فرض حدود صلبة.
ما الذي لا يثبته تقرير Anthropic
لا يثبت التقرير أن Opus 4.6 لا يستطيع تخريب العمل. ولا يثبت أن مراقبًا آليًا سيلتقط بابًا خلفيًا خفيًا. ولا يثبت أن نموذجًا لا يستطيع تعلم الظهور بمظهر جيد أمام المراقبين. Anthropic صريحة إلى حد معقول بشأن القيود: تقول إن لا ضمانة واحدة تمنح اطمئنانًا قويًا وحدها، ويتضمن ملف PDF العام لديها حذوفات.
هذا التحفظ مهم لأن المطورين بدأوا بالفعل يضعون هذه الإصدارات في معسكرين كسولين.
المعسكر الأول يقول: نشرت Anthropic تقرير سلامة طويلًا، إذن لا بد أنه آمن.
لا. التقرير يقول إن النموذج مفيد، وقوي، ومراقب، وما زال غير خالٍ من المخاطر.
المعسكر الثاني يقول: تتحدث Anthropic عن السلامة، إذن لا بد أن الأمر استحواذ تنظيمي أو تسويق.
وهذا تبسيط زائد أيضًا. الضوابط الموصوفة في التقرير هي نظافة هندسية عادية. مراقبة الأمن، ومراجعة PR، وأخذ عينات للتدقيق، والعزل، واختبارات الثوابت، وإبلاغ المستخدمين ليست طقوس مواءمة غامضة. إنها التحركات نفسها التي تستخدمها الفرق الناضجة مع المطلعين البشريين، ورموز CI المخترقة، والاعتمادات الخارجية الخطرة.
الوسط غير المريح أكثر فائدة: قد تستفيد Anthropic تجاريًا من صورتها كشركة السلامة، وقد تكون ضوابطها الداخلية في الوقت نفسه جديرة بالنسخ. كلا الأمرين يمكن أن يكون صحيحًا.
يحمل التقرير أيضًا تحذيرًا خفيًا للفرق التي تتبنى البرمجة متعددة الوكلاء. أبرز منشور إطلاق Anthropic فرق وكلاء Claude Code، والوكلاء الفرعيين المتوازيين، وضغط السياق، والعمل الأطول تشغيلًا (Anthropic). هذه الميزات تحديدًا هي حيث تصبح المراقبة أصعب. مساعد واحد يصنع فرقًا واحدًا سهل الفحص. سرب من الوكلاء يقرأ، ويعدّل، ويلخص، ويسلّم الحالة مشكلة نسب.
إذا سمحت للوكلاء بالتنسيق، فسجّل التنسيق. إذا كتب وكيل خطة ونفذها آخر، فاحتفظ بالأثرين معًا. إذا ضُغط السياق، فخزّن حد ما قبل الضغط وما بعده. الملخصات تفقد معلومات. والحالة الفاقدة للمعلومات هي حيث تختفي المساءلة.
قائمة ضوابط للفرق التي تشحن وكلاء برمجة
هذا هو الحد العملي الذي سأضعه قبل السماح لوكلاء البرمجة بلمس مستودعات مهمة.
ابدأ بتصنيف المستودعات. مستودع توثيق، ونموذج أولي، وخدمة فوترة، ومزوّد هوية لا ينبغي أن تشترك كلها في سياسة وكيل واحدة. عامل المستودعات الحساسة أمنيًا كطبقة مختلفة.
اشترط مراجعة بشرية للدمج في الفروع المشتركة. يبدو هذا بديهيًا، لكن الفرق تتجاوزه بصمت عندما ينشئ الوكلاء فروقات ميكانيكية «صحيحة بوضوح». لا تفعل ذلك. الكود الذي يكتبه الوكيل ينبغي أن يمر بالمسار نفسه الذي يمر به كود المتدرب، مع اهتمام إضافي بالاختبارات والصلاحيات.
شغّل مراجعًا ثانيًا. استخدم نموذجًا آخر، أو مطالبة أخرى، أو تمريرة تحليل ساكن. اطلب منه مقارنة التغيير الذي طلبه المستخدم بالفرق الفعلي. فحص عدم التطابق هذا رخيص ويلتقط فئة من الإخفاقات تفوتها المراجعة العادية.
خذ عينات من الجلسات، لا من PRs فقط. قد يستكشف وكيل خبيث أو مشوش ملفات حساسة، أو يشغّل أوامر غريبة، أو يحاول تغييرات لا تنجو إلى الفرق النهائي. تركيز Anthropic على استخدام Claude Code، لا على الكود المدموج فقط، غريزة صحيحة.
احجب الأسرار بالتصميم. لا تعتمد على «معرفة» النموذج بأنه لا ينبغي قراءة .env.production. استخدم أذونات نظام الملفات، وماسحات الأسرار، وعزل البيئة، وتأكيد الأوامر.
أضف اختبارات ثوابت للخصائص الأمنية. أمثلة التقرير واضحة: إذا كان ينبغي ألا ترسل عقدتان حركة إلى بعضهما، فاختبر أنهما لا تستطيعان. ترجم ذلك إلى عالمك: حدود المصادقة، وعزل المستأجرين، وانتقالات حالة الدفع، والاحتفاظ بالبيانات، وضوابط التصدير، وأحداث التدقيق.
اكتب مسار حوادث. إذا رأى مراجع سلوكًا مريبًا من الوكيل، إلى أين يذهب؟ Slack؟ الأمن؟ تقرير إلى المورّد؟ حظر الدمج ليس عملية حوادث.

لماذا يهم هذا الآن
كان سؤال برمجة الذكاء الاصطناعي القديم هو ما إذا كان النموذج يستطيع كتابة كود مفيد. Opus 4.6 وSonnet 4.6 وأنظمة فئة GPT-5 والدفعة الحالية من وكلاء البرمجة أجابت عن ذلك في الغالب. تستطيع كتابة كود مفيد. وتستطيع أيضًا كتابة كود سيئ بسرعة، وكود مقنع بثقة، وكود حساس أمنيًا بسياق كافٍ ليكون خطرًا.
السؤال الجديد تشغيلي: هل يستطيع فريقك استيعاب عمل الوكلاء من دون فقدان السيطرة على سلسلة توريد البرمجيات؟
تقرير Anthropic عن التخريب قيّم لأنه يجعل إجابة المورّد نفسه مرئية. لاستخدام Claude Code داخليًا، تصف Anthropic مراقبة آلية على الغالبية الكبيرة من الاستخدام، وتدقيقات بشرية، ومراجعة PR يدوية، ومراقبة PR آلية، وعزلًا، ومراقبة أمنية، واختبارات ثوابت. هذه ليست أجواء. إنها طبقة ضوابط.
ينبغي للمطورين التوقف عن التعامل مع «الثقة بالنموذج» كأنه القرار. القرار هو أين تضع النموذج داخل نظام يفترض قابلية الخطأ. دعه يصوغ. دعه يبحث. دعه يعيد الهيكلة. دعه يفتح PRs. لكن اجعل الأفعال المهمة قابلة للملاحظة، والمراجعة، والعكس، والاختبار.
هذه هي الخلاصة المفيدة من التقرير. ستستمر النقاشات حول ادعاءات السلامة على HN وReddit وX. خط CI لديك لا يحتاج إلى حسم الفلسفة. يحتاج إلى التقاط الفرق السيئ.
يمكن للقراء الذين يريدون تجربة Claude Fable 5 بأنفسهم استخدامه عبر OneHop: نقطة وصول بديلة مباشرة، بسعر أقل بنحو 30% من السعر المعلن، مع 10 دولارات مجانية للحسابات الجديدة ومن دون الحاجة إلى بطاقة. انظر Claude Fable 5 on OneHop أو ابدأ مع 10 دولارات مجانية.
قراءة إضافية: البدء مع Claude Fable 5.

