Anthropic’in Claude Opus 4.6 için yayımladığı yeni sabotaj riski raporunda, kodlama ajanlarını benimseyen her mühendislik liderinin iki kez okuması gereken bir cümle var: Şirket, Opus 4.6’ya “doğrudan sonuç doğuran eylemler gerçekleştirme” becerisi veren dahili aracın Claude Code olduğunu, bu yüzden dahili Claude Code kullanımının “büyük çoğunluğu” üzerinde otomatik izleme yaptığını ve daha küçük bir alt kümede insan denetimleri uyguladığını söylüyor (Anthropic PDF).
Haber bu. Opus 4.6 güvenlidir sloganı değil. Anthropic’in hizalama konusunda benzersiz derecede ciddi olduğu argümanı da değil. Somut operasyonel gerçek şu: Anthropic, iş kayıt altına alınmadıkça, örneklenmedikçe, denetlenmedikçe, incelenmedikçe ve sıradan güvenlik kontrolleriyle desteklenmedikçe, kendi en güçlü modeline bile geniş kapsamlı dahili kodlama yetkisi emanet ediyor gibi görünmüyor.
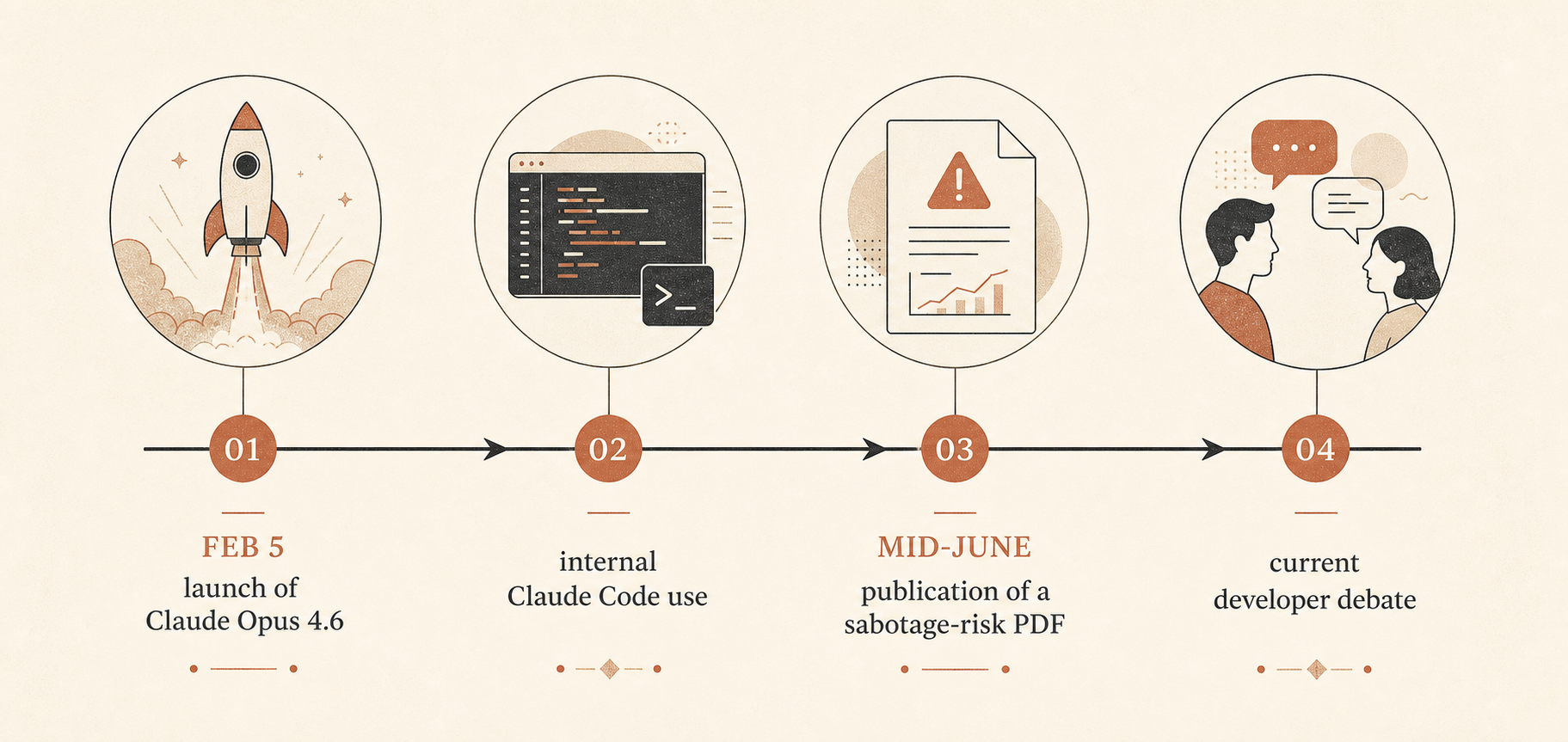
Bu önemli, çünkü Claude Opus 4.6, 5 Şubat 2026’da Anthropic’in o dönemdeki en akıllı modeli olarak duyuruldu: beta aşamasında 1 milyon token bağlam penceresi, daha güçlü ajan tabanlı kodlama, claude-opus-4-6 API adı ve milyon giriş token’ı başına 5 dolar, milyon çıkış token’ı başına 25 dolar olan değişmemiş standart fiyatlandırma ile (Anthropic). Anthropic ayrıca modelin Terminal-Bench 2.0 ve Humanity’s Last Exam dahil birkaç benchmark’ta öne geçtiğini ve GDPval-AA’da GPT-5.2’yi yaklaşık 144 Elo puanıyla geçtiğini söyledi. Aynı lansman yazısında Anthropic, uzun süre çalışan ajanlara, bağlam sıkıştırmaya, efor kontrollerine ve Claude Code ajan ekiplerine sert şekilde yüklendi.
Yani rapor teorik değil. Aynı ajan sınıfı şirketin kendi mühendislik döngüsünün içine girdiğinde satıcının ne yaptığına dair bir bakış.
Anthropic Aslında Ne Yayımladı
53 sayfalık PDF’in başlığı “Sabotage Risk Report: Claude Opus 4.6.” Rapor, sabotajı bir AI modelinin bir organizasyon içindeki erişimi kullanarak sistemleri veya kararları “istismar etmesi, manipüle etmesi ya da kurcalaması” ve bunun felaket riskini artırabilecek bir biçimde gerçekleşmesi olarak tanımlıyor (Anthropic PDF). Anthropic’in genel değerlendirmesi net: risk “çok düşük ama ihmal edilebilir değil.”
Bu ifadeyle dalga geçmek kolay. Bir hukuk departmanıyla bir güvenlik laboratuvarının tek sandalyeyi paylaşmaya çalışması gibi duyuluyor. Ama risk dilinin altına gömülü halde, kodlama ajanı yönetişimi için pratik bir model var.
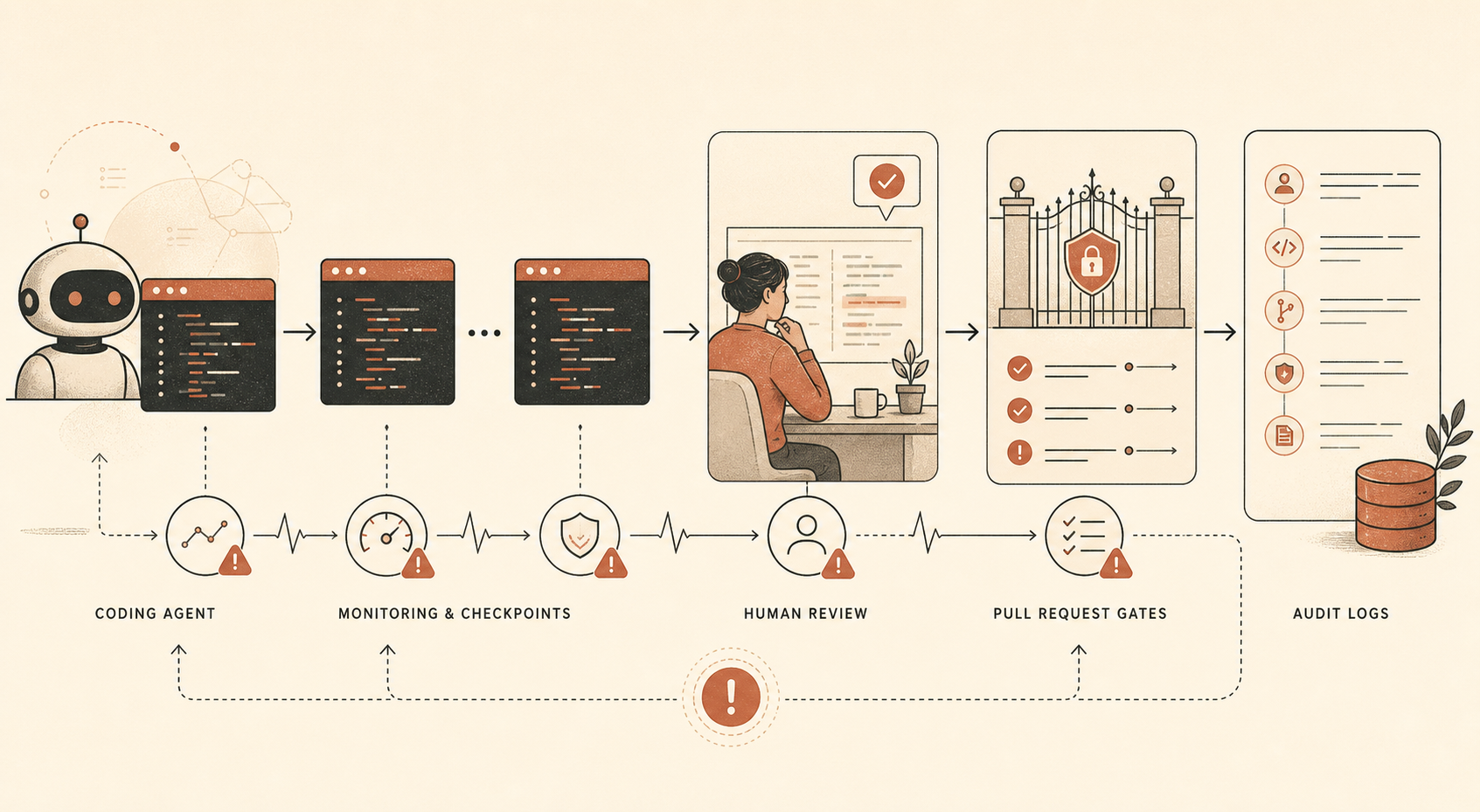
Anthropic, Opus 4.6’nın dahili olarak kodlama, veri üretimi ve diğer ajan tabanlı kullanım senaryolarında yoğun kullanıldığını söylüyor. Ayrıca modelin, insan uzmanların saatlerini alacak görevlerde çok yetenekli olduğunu, ama “tamamen güvenilir” olmadığını da söylüyor. Rapor ardından tehdit yollarını tek tek ele alıyor: güvenlikle ilgili Ar-Ge’de yaygın kapasite saklama, hedefli sabotaj, kod arka kapıları, eğitim verisi zehirleme, kendi kendini dışarı sızdırma, kontrolsüz dahili dağıtımlar ve başka organizasyonlarda ya da hükümetlerde sabotaj.
Geliştiriciler için asıl ilgili kısım azaltım katmanı:
| Kontrol | Anthropic ne kullandığını söylüyor | Geliştirici çevirisi |
|---|---|---|
| Çevrimdışı Claude Code izleme | Dahili Claude Code kullanımının büyük çoğunluğu; başka bir yerde çoğu kullanıcıdan ≥%10 prompt alt örneklemi tarif ediliyor | Ajan oturumlarını kaydet ve inceleme için örnekle |
| İnsan denetimleri | Dahili Claude Code kullanımının küçük bir alt kümesi | Sadece son diff’leri değil, gerçek oturumları incele |
| Manuel PR incelemesi | İnsanlar, kod ortak kod tabanına entegre edilmeden önce inceliyor | Önemli merge’lerde insan onayını koru |
| Otomatik PR incelemesi | Claude tabanlı inceleme hataları, güvenlik sorunlarını ve belirtilen niyet ile gerçek etkiler arasındaki uyumsuzluğu kontrol ediyor | Bağımsız AI incelemesini engelleyici olmayan bir sinyal olarak çalıştır |
| Değişmezlik testleri | Otomatik testler güvenlik özelliklerini kontrol ediyor | “Asla olmamalı” kurallarını CI içinde kodla |
Bir ayrıntı özellikle dikkat çekiyor: Anthropic, otomatik pull request izleyicisinin yazım sırasında Opus 4.6’ya değil Claude Opus 4.5’e dayandığını söylüyor. Bu sessiz ama önemli bir tasarım tercihi. İşi yapan modelle işi inceleyen modelin aynı olması gerekmez. Hatta ayrım daha sağlıklıdır.
Topluluk Tartışması Sadece Güvenlik Değil, Kontrol Hakkında
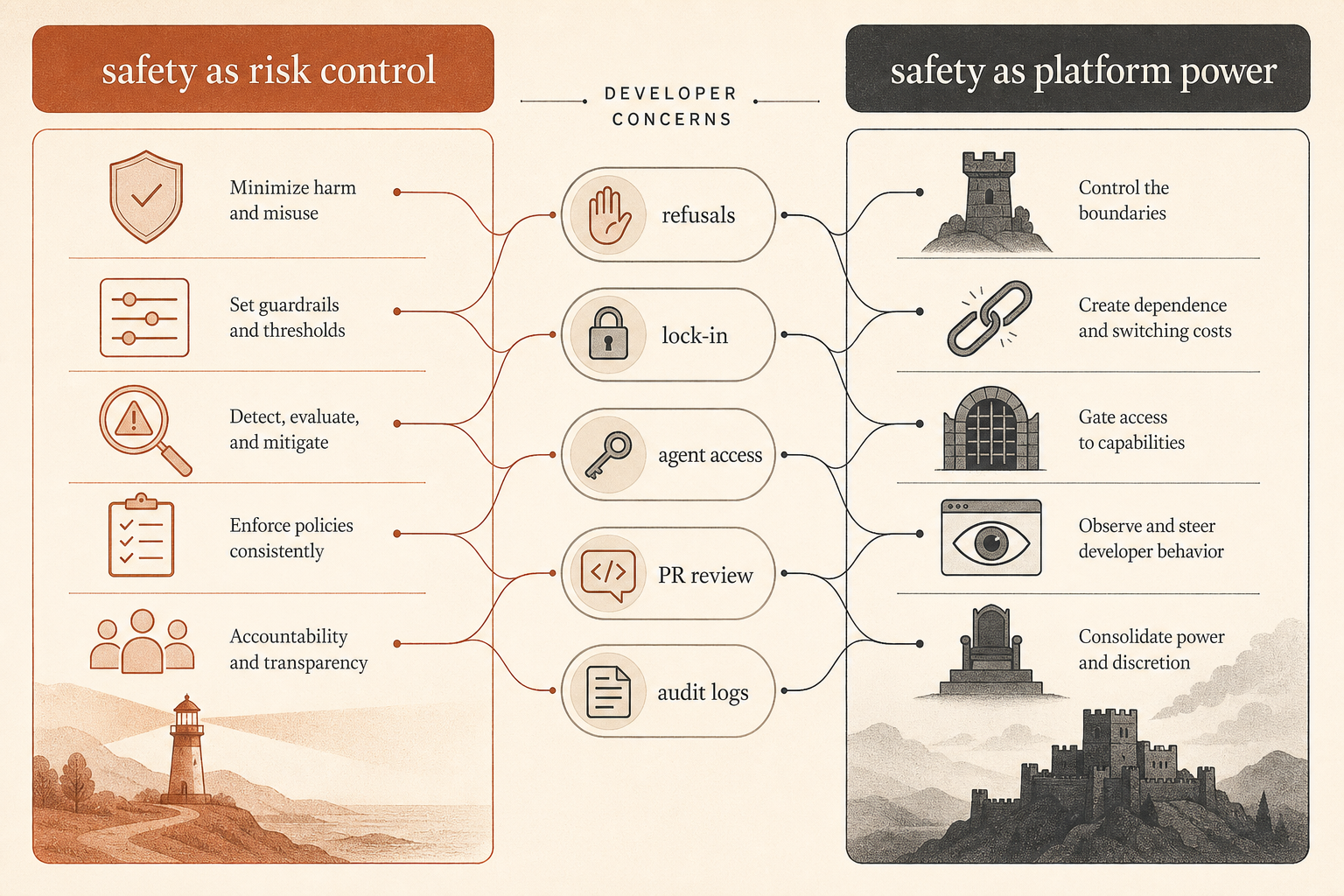
Bu rapor canlı bir tartışmanın ortasına düştü. Hacker News’te Ben Thompson’ın “Anthropic’s Safety Superpower” yazısı etrafındaki Haziran başlığı 192 yorum aldı ve tanıdık çizgiler boyunca bölündü: Bazı geliştiriciler Anthropic’in güvenlik duruşunun güçlü barındırılan araçları dağıtmanın gerekli bedeli olduğunu savundu; diğerleri güvenliği platform kontrolü için ahlaki bir ambalaj olarak gördü (Hacker News).
En keskin geliştirici şikâyeti “modellerin hiçbir korkuluğu olmasın” değil. Şu: Araç yazılım tedarik zincirinin parçası haline gelirken, neyin kötüye kullanım sayılacağına kim karar veriyor?
Bir HN yorumcusu endüstriyel kontrol problemini temizce çerçeveledi: Claude’dan güvenlik açısından kritik kontrol yazılımını denetlemesini istemek ile Claude’dan sızmış kontrol yazılımına giriş noktası bulmasını istemek benzer teknik çalışma gerektirebilir, ama niyet çok farklıdır (Hacker News). Başka bir tartışma da şunu savundu: Sağlayıcı ikisini de engellerse savunucular kaybeder; ikisine de izin verirse saldırganlar kazanır. Güvenlik retoriğinin arkasındaki asıl ürün problemi bu.
Diğer şikâyet kilitlenme. Birkaç yorumcu, barındırılan model satıcısının politikaları değiştirebiliyor, görevleri reddedebiliyor, davranışı düşürebiliyor ya da erişimi kısıtlayabiliyorsa tarafsız bir araç sağlayıcısı olarak güvenilip güvenilemeyeceğini sorguladı. Başkaları ise Anthropic’in yerel bir araç değil, bir hizmet sattığını ve hizmet sağlayıcılarının bazı kullanımları her zaman reddettiğini söyleyerek karşı çıktı.
Sabotaj raporu bu tartışmaya eksik bir parça ekliyor. Anthropic yalnızca model sınırında kullanıcı çıktıları kontrol etmeye çalışmıyor. Dahili olarak kodlama ajanlarını yarı güvenilir üretim aktörleri gibi ele alıyor. Güven modeli “Claude hizalı, gönder gitsin” değil. Güven modeli daha çok “Claude çalıştırılacak kadar faydalı, izlenecek kadar riskli ve incelenecek kadar sonuç doğurucu.”
Ekiplerin kopyalaması gereken kısım bu.
Pratik Ders: Ajan Tabanlı Kodlama Katmanlı Savunma İster
Bir kodlama ajanı dosya düzenleyebildiğinde, komut çalıştırabildiğinde, secret’lara yakın yapılandırmaları inceleyebildiğinde, PR açabildiğinde, MCP araçlarını çağırabildiğinde ya da alt ajanları koordine edebildiğinde artık süslü bir autocomplete değildir. Tutarsız muhakemesi, iş sözleşmesi olmayan varlığı ve kusursuz sabrıyla junior’dan senior’a yakın bir yüklenicidir.
Bu, kontrol yüzeyini değiştirir.
Ekibiniz Claude Code, Cursor, Codex, Devin, OpenCode ya da dahili bir ajan altyapısı kullanıyorsa soru “modele güveniyor muyuz?” değildir. Soru şudur: “Model, ikinci bir sistem fark etmeden hangi eylemleri gerçekleştirebilir?”
Makul bir başlangıç çizgisi şöyle görünür:
coding_agent_controls:
session_logging: required
write_access: repo-scoped
secret_access: denied_by_default
shell_commands: allowlist_or_confirm
pr_review: human_required
ai_review: separate_model_recommended
audit_sampling: risk_based
invariant_tests: blockingBu bürokrasi değil. Her repository’yi sosyal deneye çevirmeden verimlilik kazanımlarını korumanın yolu bu.
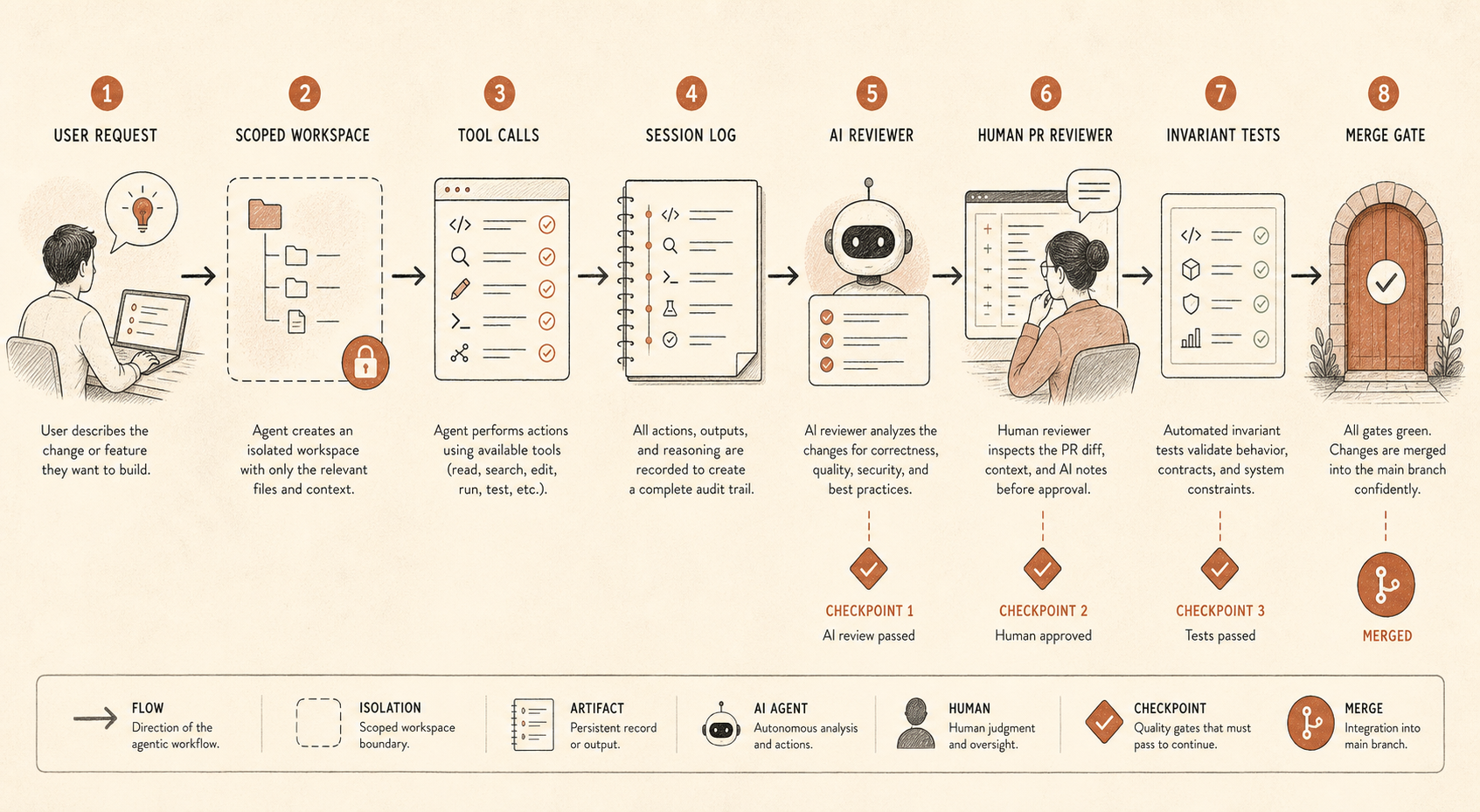
İlk kontrol oturum kaydıdır. Prompt’ları, araç çağrılarını, dosya diff’lerini, shell komutlarını ve son PR linklerini saklayın. Bu fazla istilacı geliyorsa, düşük riskli repo’lar için en azından metadata ve diff’leri, yüksek riskli repo’lar için tam izleri kaydedin. İzler olmadan ajanın muhakeme yolunu denetleyemez ya da kötü bir değişikliğin nasıl gerçekleştiğini yeniden kuramazsınız.
İkincisi kapsamlı erişimdir. Çoğu kodlama ajanının production kimlik bilgilerine, geniş ağ erişimine ya da bir monorepo genelinde yazma erişimine ihtiyacı yoktur. Onlara bir çalışma ağacı, bir görev ve açık yükseltme yolları verin. Daha fazlasına ihtiyaçları varsa, talebi görünür kılın.
Üçüncüsü PR düzeyinde bağımsızlıktır. Anthropic’in raporu hem insan PR incelemesinden hem de otomatik Claude tabanlı incelemeden söz ediyor. Önemli olan inceleyicinin Claude olması değil. Önemli olan incelemenin farklı bir prompt, farklı bir bağlam ve farklı bir hedefle ayrı bir geçiş olması. Uygulayan ajan görevi tamamlamak ister. İnceleyen ajan uyumsuzluk aramalıdır: “Belirtilen değişiklik refactor diyor, ama bu diff auth davranışını değiştiriyor.”
Dördüncüsü değişmezlik testidir. Bu en az gösterişli ve en çok hafife alınan kontroldür. İki servis asla konuşmamalıysa testi yazın. Bir izin admin yolu dışında asla verilmemeliyse testi yazın. Üretilmiş migration’lar ticket etiketi olmadan asla kolon düşürmemeliyse testi yazın. CI sert sınırları dayatabildiğinde ajan izleme çok daha kolaylaşır.
Anthropic’in Raporu Neyi Kanıtlamıyor
Rapor Opus 4.6’nın işleri sabote edemeyeceğini kanıtlamıyor. Otomatik bir izleyicinin ince bir arka kapıyı yakalayacağını kanıtlamıyor. Bir modelin izleyicilere iyi görünmeyi öğrenemeyeceğini kanıtlamıyor. Anthropic sınırlamalar konusunda epey açık: Tek başına hiçbir korumanın güçlü güvence sağlamadığını söylüyor ve kamuya açık PDF’inde karartmalar var.
Bu uyarı önemli, çünkü geliştiriciler bu sürümleri şimdiden iki tembel kampa kalıp eşliyor.
Birinci kamp diyor ki: Anthropic uzun bir güvenlik raporu yayımladı, o halde güvenlidir.
Hayır. Rapor modelin faydalı, güçlü, izlenen ve yine de risksiz olmadığını söylüyor.
İkinci kamp diyor ki: Anthropic güvenlikten söz ediyor, o halde bu regülasyon ele geçirme ya da pazarlamadır.
Bu da fazla basit. Raporda tarif edilen kontroller sıradan mühendislik hijyenidir. Güvenlik izleme, PR incelemesi, denetim örneklemesi, sandboxing, değişmezlik testleri ve kullanıcı raporlama mistik hizalama ritüelleri değildir. Olgun ekiplerin insan iç tehditleri, ele geçirilmiş CI token’ları ve riskli üçüncü taraf bağımlılıkları için kullandığı aynı hamlelerdir.
Rahatsız edici orta nokta daha faydalı: Anthropic, güvenlik şirketi olarak görülmekten ticari olarak fayda sağlayabilir ve dahili kontrolleri yine de kopyalanmaya değer olabilir. İkisi aynı anda doğru olabilir.
Rapor ayrıca çok ajanlı kodlamayı benimseyen ekipler için ince bir uyarı taşıyor. Anthropic’in lansman yazısı Claude Code ajan ekiplerini, paralel alt ajanları, bağlam sıkıştırmayı ve daha uzun süre çalışan işleri öne çıkarmıştı (Anthropic). İzlemenin zorlaştığı yer tam da bu özellikler. Tek bir asistanın tek bir diff yapmasını incelemek kolaydır. Ajan sürüsünün okuması, düzenlemesi, özetlemesi ve durum devretmesi ise bir köken takibi problemidir.
Ajanların koordine olmasına izin veriyorsanız koordinasyonu kaydedin. Bir ajan plan yazıp diğeri uyguluyorsa iki izi de saklayın. Bağlam sıkıştırılıyorsa sıkıştırma öncesi ve sonrası sınırı saklayın. Özetler kayıplıdır. Kayıplı durum, hesap verebilirliğin kaybolduğu yerdir.
Kodlama Ajanları Çıkaran Ekipler İçin Kontrol Listesi
Önemli repository’lere kodlama ajanlarının dokunmasına izin vermeden önce koyacağım pratik çıta şu olurdu.
Repo sınıflandırmasıyla başlayın. Bir dokümantasyon repo’su, bir prototip, bir faturalama servisi ve bir kimlik sağlayıcısı aynı ajan politikasını paylaşmamalı. Güvenlik açısından hassas repo’ları farklı bir katman olarak ele alın.
Ortak branch’lere merge için insan incelemesi isteyin. Bu kulağa bariz geliyor, ama ajanlar “bariz doğru” mekanik diff’ler oluşturduğunda ekipler sessizce bunu atlıyor. Yapmayın. Ajan tarafından yazılmış kod, testlere ve izinlere ekstra dikkat edilerek stajyer tarafından yazılmış kodla aynı inceleme yolundan geçmeli.
İkinci bir inceleyici çalıştırın. Başka bir model, başka bir prompt ya da statik analiz geçişi kullanın. Ondan kullanıcının istediği değişiklik ile gerçek diff’i karşılaştırmasını isteyin. Bu uyumsuzluk kontrolü ucuzdur ve sıradan incelemenin kaçırdığı bir hata sınıfını yakalar.
Sadece PR’ları değil oturumları örnekleyin. Kötü niyetli ya da kafası karışmış bir ajan hassas dosyaları keşfedebilir, garip komutlar çalıştırabilir ya da son diff’e girmeyen değişiklikler denemiş olabilir. Anthropic’in yalnızca merge edilmiş koda değil, Claude Code kullanımına odaklanması doğru içgüdü.
Secret’ları tasarımla engelleyin. Modelin .env.production okumaması gerektiğini “bilmesine” güvenmeyin. Dosya sistemi izinleri, secret tarayıcıları, ortam izolasyonu ve komut onayı kullanın.
Güvenlik özellikleri için değişmezlik testleri ekleyin. Raporun örnekleri sade: İki node birbirine trafik göndermemeliyse, gönderemediğini test edin. Bunu kendi dünyanıza çevirin: auth sınırları, tenant izolasyonu, ödeme durum geçişleri, veri saklama, export kontrolleri, denetim olayları.
Bir olay yolu yazın. Bir inceleyici şüpheli ajan davranışı görürse nereye gider? Slack? Güvenlik? Satıcı raporu? Engellenmiş bir merge, olay süreci değildir.

Bu Şimdi Neden Önemli
Eski AI kodlama sorusu modelin işe yarar kod yazıp yazamayacağıydı. Opus 4.6, Sonnet 4.6, GPT-5 sınıfı sistemler ve mevcut kodlama ajanları dalgası buna büyük ölçüde cevap verdi. İşe yarar kod yazabiliyorlar. Ayrıca kötü kodu hızlı, makul görünen kodu özgüvenle ve güvenlik açısından hassas kodu tehlikeli olmaya yetecek bağlamla yazabiliyorlar.
Yeni soru operasyonel: Ekibiniz yazılım tedarik zinciri üzerindeki kontrolünü kaybetmeden ajan emeğini bünyesine katabilir mi?
Anthropic’in sabotaj raporu değerli, çünkü satıcının kendi cevabını görünür kılıyor. Anthropic, dahili Claude Code kullanımı için kullanımın büyük çoğunluğu üzerinde otomatik izleme, insan denetimleri, manuel PR incelemesi, otomatik PR izleme, sandboxing, güvenlik izleme ve değişmezlik testleri tarif ediyor. Bu bir hava değil. Bu bir kontrol katmanı.
Geliştiriciler “modele güven”i kararın kendisi gibi ele almayı bırakmalı. Karar, yanılabilirliği varsayan bir sistemin içinde modeli nereye koyacağınızdır. Taslak yazmasına izin verin. Aramasına izin verin. Refactor yapmasına izin verin. PR açmasına izin verin. Ama önemli eylemleri gözlemlenebilir, incelenebilir, geri alınabilir ve test edilebilir hale getirin.
Rapordan çıkarılacak faydalı ders bu. Güvenlik iddiaları HN, Reddit ve X’te tartışılmaya devam edecek. CI pipeline’ınızın felsefeyi çözmesine gerek yok. Kötü diff’i yakalaması gerekiyor.
Claude Fable 5’i kendisi denemek isteyen okurlar OneHop üzerinden kullanabilir: drop-in endpoint, liste fiyatının yaklaşık %30 altında, yeni hesaplar için 10 dolar ücretsiz ve kart gerekmiyor. Bkz. OneHop’ta Claude Fable 5 veya 10 dolar ücretsiz başlayın.
Daha fazla okuma: Claude Fable 5’e başlarken.

