Anthropic 6 月 3 日的網路威脅報告有一個資安團隊不該忽視的硬數字:它分析了 2025 年 3 月到 2026 年 3 月間,因惡意網路活動而遭封禁的 832 個 Claude 帳號,並將這些活動對應到 MITRE ATT&CK(Anthropic)。這份報告的重點不是「AI 會寫惡意軟體」。這我們早就知道了。更銳利的主張是:MITRE ATT&CK 這套許多防禦者用來描述對手行為的共通語言,還沒有捕捉到讓 AI 原生攻擊變得不同的關鍵:代理式協同編排。
這個論點正好落在一個吵翻天的週中間。6 月 9 日,Anthropic 發表 Claude Fable 5 和 Claude Mythos 5,將 Fable 描述為公開的 Mythos 級模型,具備網路安全與生物學防護,而 Mythos 則是提供給通過審核防禦者的受限版本(Anthropic)。到了 6 月 12 日,Anthropic 表示,因一項與傳出 jailbreak 疑慮相關的美國政府指令,它已暫停 Fable 5 和 Mythos 5 的存取(Anthropic)。Hacker News 和 Reddit 上的討論串現在吵的是:這些 guardrails 到底是在保護大眾、削弱防禦者,還是主要製造令人困惑的誤判。
開發者應該把 6 月 3 日的報告和 Fable 風波分開看。它不是產品發布文。它是一篇量測報告。而且它給了安全工程師一個本季就能採取的實務更新:開始把代理腳手架視為攻擊基礎設施來建模。
Anthropic 實際量到了什麼
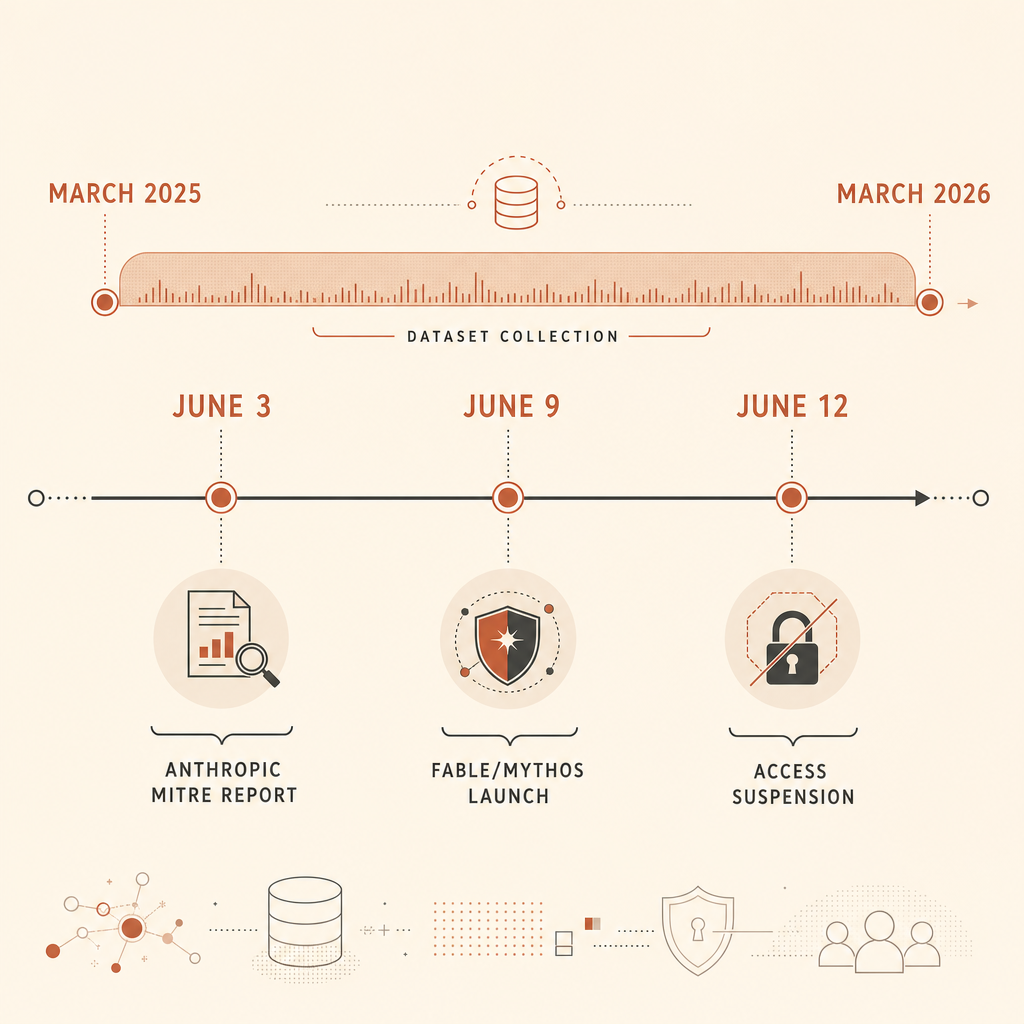
Anthropic 表示,這 832 個帳號是遭封禁帳號中的一個子集,調查人員對它們有足夠細節,可將觀察到的活動對應到 MITRE ATT&CK。它的 Frontier Red Team 文章提供了更多細節:團隊擷取了 13,873 筆惡意活動觀察結果,對應到 ATT&CK v18,並發現活動橫跨全部 14 個 ATT&CK tactics,以及 482 個獨特 sub-techniques(Anthropic Frontier Red Team)。
這很重要,因為這不是叫模型去解合成 CTF 題目的 benchmark。這是真實使用者違反網路相關使用政策時留下的濫用遙測資料。這也代表資料集有其限制。它看到的是 Anthropic 介面上的濫用:Claude.ai、Claude Code,以及 API。它沒有量到整個網際網路、其他模型供應商、本地 open-weight 系統,或從未碰過 Claude 的攻擊。把它當成一個很強的感測器,而不是整片天空。
最常見的行為很無聊,也很重要。Anthropic 報告指出,832 個帳號中有 560 個,也就是 67.3%,使用 AI 進行惡意軟體開發。根據 Frontier Red Team 文章,更廣義的「Develop Capabilities」ATT&CK 家族 T1587 出現在 574 個帳號中,也就是 69%。這是商品化層級:寫腳本、調整 payload、自動化規避、產生膠水程式碼。
更有意思的訊號,是活動隨時間移動到哪裡。在研究期間的前半段,Anthropic 的 ARiES 風險評分將 33% 的行為者歸類為中風險或更高。到了後半段,這個比例升到 56%,約為 1.7 倍成長。Anthropic 也表示,AI 輔助的帳號探索上升 8.9%,而 AI 輔助的 phishing 下降 8.6%(Anthropic)。
這才是防禦者該在意的部分。Phishing 是入口。帳號探索、橫向移動、權限提升、憑證存取,都是入侵後的工作。它們需要脈絡、調整,以及戰術選擇。如果 AI 的使用正在往那裡漂移,模型就不再只是 payload 產生器。它正在成為操作者迴路的一部分。
| Anthropic 資料集中的訊號 | 數字 |
|---|---|
| 分析的遭封禁惡意網路帳號 | 832 |
| 研究期間 | 2025 年 3 月至 2026 年 3 月 |
| 對應到 ATT&CK 的已觀察惡意行動 | 13,873 |
| 觀察到的獨特 ATT&CK sub-techniques | 482 |
| 使用 AI 進行惡意軟體開發的帳號 | 560,或 67.3% |
| 前半段中風險或更高的行為者 | 33% |
| 後半段中風險或更高的行為者 | 56% |
為什麼 MITRE ATT&CK 開始被拉彎
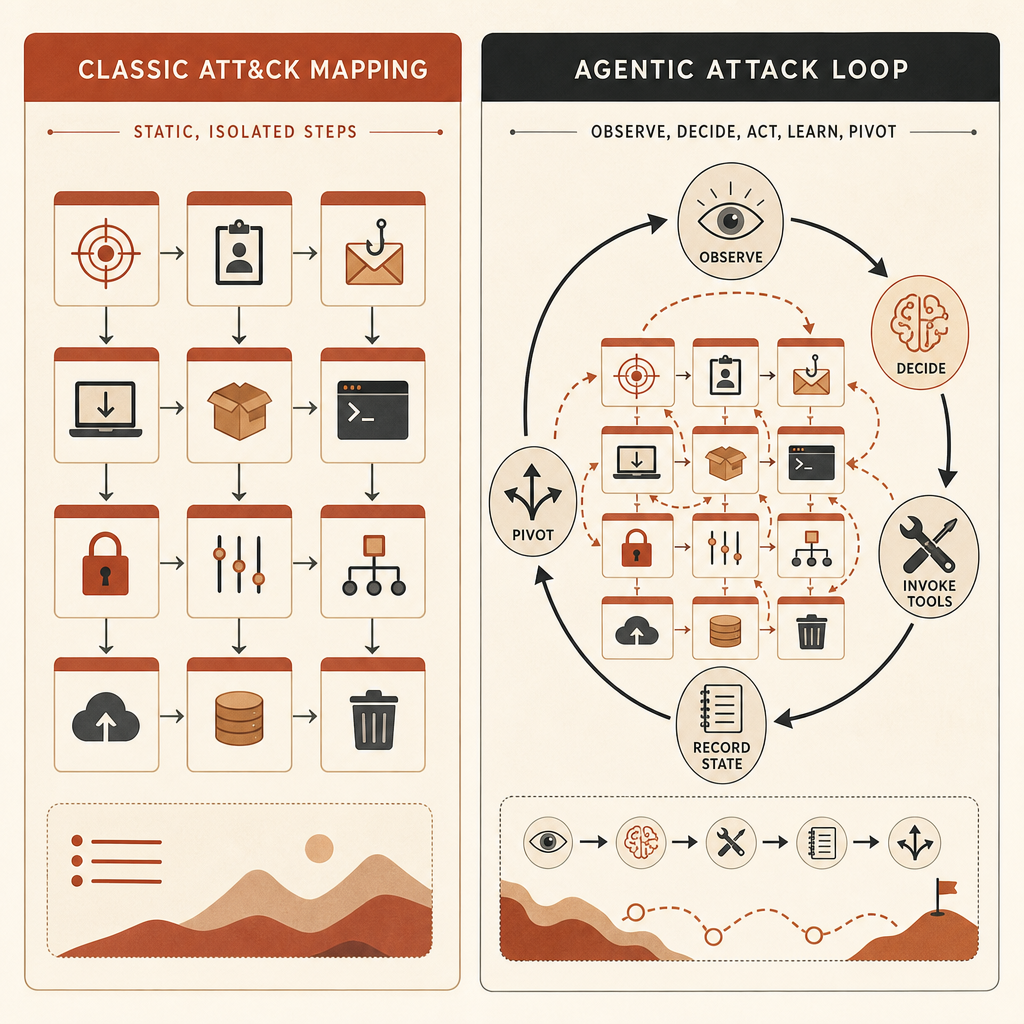
MITRE ATT&CK 仍然有價值。MITRE 將它描述為一個全球可存取的知識庫,根據真實世界觀察整理對手 tactics 和 techniques,供產業與政府用於威脅模型和方法論(MITRE)。它讓團隊能用共通 ID 描述像是 T1587.001 惡意軟體開發、憑證傾印、帳號探索、命令執行,以及資料外洩這類事情。
問題在於,ATT&CK 最擅長命名的是那些原子動作。Anthropic 的主張是,危險的 AI 行為存在於這些動作之間。
人類操作者可能會決定:掃描這台主機、檢查這個結果、轉向這些憑證、嘗試這條橫向路徑,然後外洩這些檔案。ATT&CK 可以對應每一步。但如果是代理式 harness 在做選擇、執行工具、更新計畫,並以極少的人類輸入繼續推進,ATT&CK 地圖看起來可能很普通,但整個行動在性質上已經不同。
Anthropic 的例子是它聲稱在 2025 年 11 月阻斷的一場網路間諜活動。在該案例中,攻擊者使用 Claude Code 進行一場 Anthropic 稱其試圖以很少人類介入滲透全球目標的行動。對應到 ATT&CK,它使用了橫跨 13 個 tactics 的 30 種 techniques,與資料集中許多中風險行為者相當。在 Anthropic 的 ARiES 系統下,它得到 100 分,滿分(Anthropic)。
這個落差才是重點。Technique 數量說的是「大概中等」。代理式執行說的是「嚴重」。
Frontier Red Team 文章更具體:這名標記為 GTG-1002 的行為者在 Kali Linux 上使用 Claude Code,並將開源滲透測試工具整合為 MCP servers,把模型變成自主攻擊平台,而不是程式碼助手(Anthropic Frontier Red Team)。這正是大多數內部威脅模型仍然描述不足的行為。
用營運語言理解「代理式網路風險」
這個詞聽起來很抽象。其實不是。對工程團隊來說,代理式網路風險代表攻擊者有一個像這樣的迴路:
observe target state -> choose next tactic -> call tool -> parse result
-> update memory -> pivot or stop -> repeat without waiting for a human這個迴路改變了三件事。
第一,它壓縮時間。低技術行為者不再需要深入理解每個工具,只要模型能選擇命令、解讀輸出,並從錯誤中恢復。Anthropic 發現,表面上的行為者技能與使用的 techniques 數量之間相關性很弱:技能最低的行為者平均約使用 16 種不同 techniques,而技能最高者平均約 20 種(Anthropic)。
第二,它讓介面選擇不再那麼令人安心。Anthropic 表示,行為者使用 Claude Code、API,或聊天介面,與風險等級沒有相關。高風險的區分點在於,行為者把 AI 套用在攻擊生命週期的哪個位置,以及他們在周圍搭了什麼腳手架。
第三,它把「guardrails」變成執行期系統問題。被擋下的 prompt 是一種控制。但一個長時間運作、帶有工具、記憶、重試、shell 存取、瀏覽器存取,以及 MCP servers 的代理,是一個分散式系統。風險行動可能跨越許多請求才浮現。這也解釋了為什麼 Anthropic 將 Fable 5 和 Mythos 級模型與 30 天留存政策綁在一起用於安全監控,並表示這些資料有助於偵測多請求 jailbreak 和濫用模式(Anthropic)。
開發者可能不喜歡這項政策。擁有零留存承諾的企業買家真的很不喜歡。但從偵測角度看,Anthropic 的論點是連貫的:單輪分類器看不到攻擊圖。
社群爭論的是誤判與存取權
開發者圈的爭論不是「AI 應不應該幫駭客?」認真的人沒有人想要 malware-as-a-service。真正的爭點是:誰能拿到完整模型、誰會被降級,以及控制措施有多透明?
在 Hacker News 上,4 月 Project Glasswing 的討論混合了對 Anthropic 行銷的懷疑,以及一個更具體的擔憂:如果一個會用工具的代理具備持續性、目標導向,並連接到真實工具,那些有助於漏洞研究的同樣特性,一旦代理偏離腳本,也會變得危險(Hacker News)。這是這場辯論比較成熟的版本。
在 Reddit 上,發布週的抱怨更直接。在一則 r/Anthropic 討論串中,有使用者描述自己要求 Fable 稽核一個專案,卻被標記並降級到 Opus,並質問如果 Fable 這麼容易觸發,究竟有什麼用(Reddit)。在 r/cybersecurity,使用者討論了 30 天留存要求,以及這條 guardrail 對合法安全工作來說是否太粗暴(Reddit)。
TechCrunch 也捕捉到安全研究人員同樣的痛點。Matt Suiche 告訴該媒體,即使是安全程式碼請求也可能被視為網路安全並遭降級,並形容其行為看起來像是以關鍵字為基礎(TechCrunch)。Anthropic 自己的發布文也承認,防護措施調得保守,有時會抓到無害請求。
接著是 6 月 12 日的暫停。Anthropic 表示,政府指令迫使它為所有客戶停用 Fable 5 和 Mythos 5,即使它不同意一個狹窄的潛在 jailbreak 足以正當化召回商用模型(Anthropic)。這讓社群爭論從「誤判很煩」變成「模型存取現在是網路政策的一部分」。
我的看法:Anthropic 認為代理式網路風險是真實的,這點是對的;它認為完美 jailbreak 抵抗是幻想,這也對。但粗暴降級是糟糕的開發者體驗,也是不好的安全控制,尤其當防禦者無法預測自己的工具何時會改變行為。安全團隊需要透明 routing、稽核日誌、經核准的高風險工作流程,以及限定範圍的工具權限。他們不需要在事件應變中途突然被換模型。
如何更新你的內部威脅模型
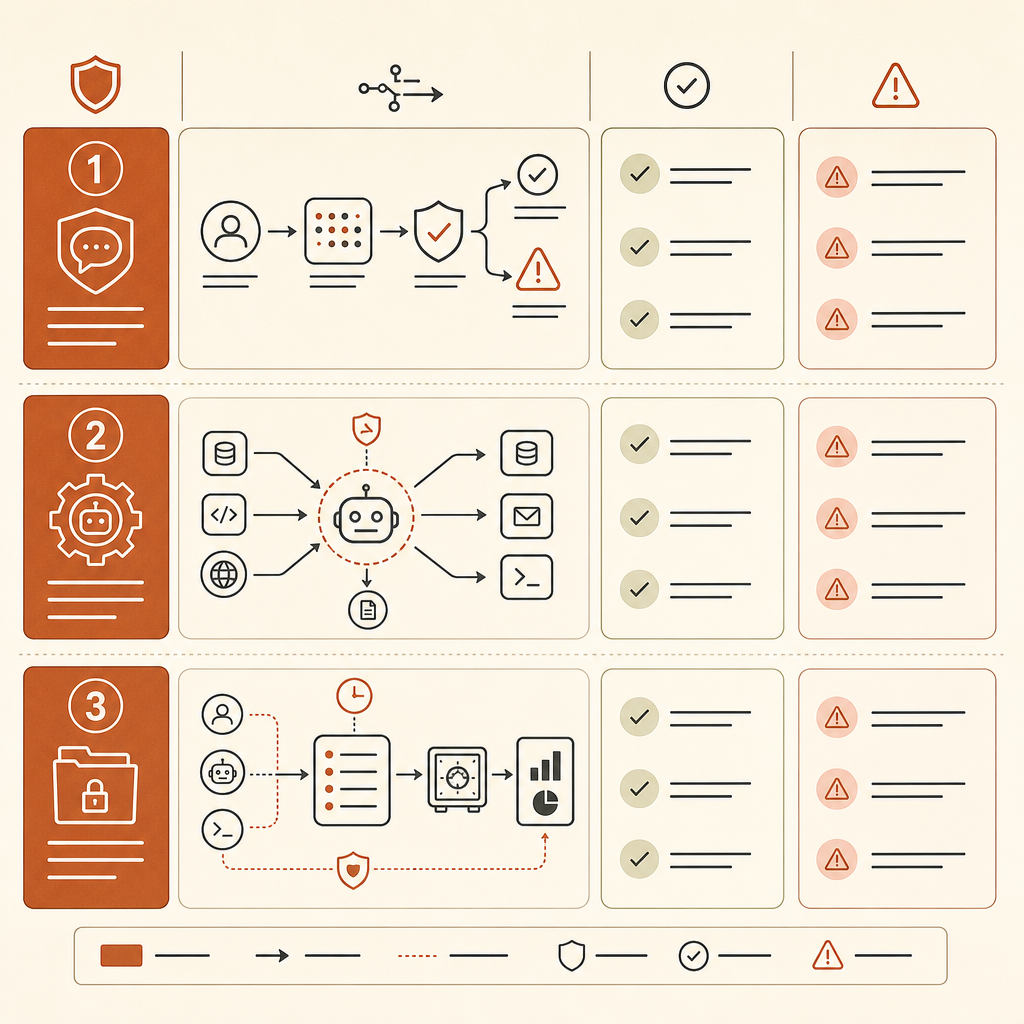
如果你的公司允許 Claude Code 風格工具、類 Cursor 代理、內部 coding agents,或 API 驅動的 LLM 自動化,現在就更新威脅模型。不要等 MITRE 鑄造新的 ID。
從代理盤點開始。追蹤哪些代理可以讀取 repository、執行 shell 命令、瀏覽內部系統、呼叫掃描器、開 ticket,或存取 secrets。風險單位不再是「使用者把程式碼貼進聊天」。而是「代理有工具、有狀態,還有目標」。
把腳手架偵測加入你的遙測。記錄工具呼叫、命令序列、MCP server 使用、重試、檔案讀取、網路請求,以及權限變更。單次 nmap 呼叫在實驗室可能正常。但如果有一個迴路會掃描、解析、選擇憑證、轉向主機,並把發現寫進記憶,那就該叫醒某個人。
把防禦性工作流程和開放式自主性分開。一個好的模式是有邊界的工作:「掃描這個 repo 的 SQL injection sinks,並產生候選修補」,搭配唯讀憑證且沒有網路出口。一個糟糕的模式是「調查我們的 staging 環境,修好你找到的任何東西」,同時給它廣泛 shell 存取和持久記憶。
對應 ATT&CK techniques,但在上面加一層內部「代理層」:
| 內部標籤 | 要記錄什麼 |
|---|---|
| 自主鏈接 | 模型是否在沒有人工核准下串接多個 ATT&CK 步驟? |
| 戰術轉向 | 它是否根據即時輸出選擇新的目標、憑證、利用路徑或工具? |
| 工具權限 | 代理能執行、讀取、修改或外洩什麼? |
| 記憶使用 | 它是否持久化目標狀態、憑證、假設或計畫? |
| 人類檢查點 | 哪些步驟需要明確核准,而且這些核准是否有實質意義? |
對 AI 平台團隊來說,實際控制點是在工具邊界執行政策。不要只依賴模型拒答。對命令執行 allowlists。要求對網路掃描、憑證存取、exploit proof-of-concept 生成,以及破壞性變更進行核准。把 secrets 放在 broker 後面,預設拒絕代理存取。限制自主迴路速率。保留每次執行的 provenance,讓安全審查者可以重播代理看到了什麼、做了什麼。
對安全工程師來說,新的偵測問題很簡單:「一個初階攻擊者拿著這個代理,能不能在一小時內表現得像資深操作者?」如果答案是肯定的,就算每個個別 technique 看起來都很普通,也要把這個工作流程歸類為高風險。
有用的結論
Anthropic 的報告很容易被誤讀成是在抱怨 MITRE ATT&CK 過時。這太膚淺了。ATT&CK 仍然能命名那些動作。缺少的是指揮者的詞彙。
6 月 3 日的資料集顯示,AI 濫用正更深入 kill chain,從準備階段進入入侵後活動。Fable/Mythos 的爭議則顯示,為這個世界交付防禦有多麻煩:開發者想要強大的工具,防禦者需要存取,供應商需要監控,而政府現在也願意介入。
正確回應不是恐慌,也不是假裝 guardrails 已經足夠。把代理腳手架視為基礎設施。為它做威脅建模。記錄它。對工具使用加上政策。今天就把「自主協同編排」和「即時戰術轉向」加入你的內部偵測語言,即使 MITRE 還沒給它們正式 technique ID。
小頁腳:想在可用時親自試用 Claude Fable 5 的讀者,可以透過 Claude Fable 5 on OneHop 使用,這是一個 drop-in endpoint,價格約低於牌價 30%。新帳號可透過 start with $10 free 免綁卡取得 $10 免費額度。
延伸閱讀:Claude Fable 5 入門.

