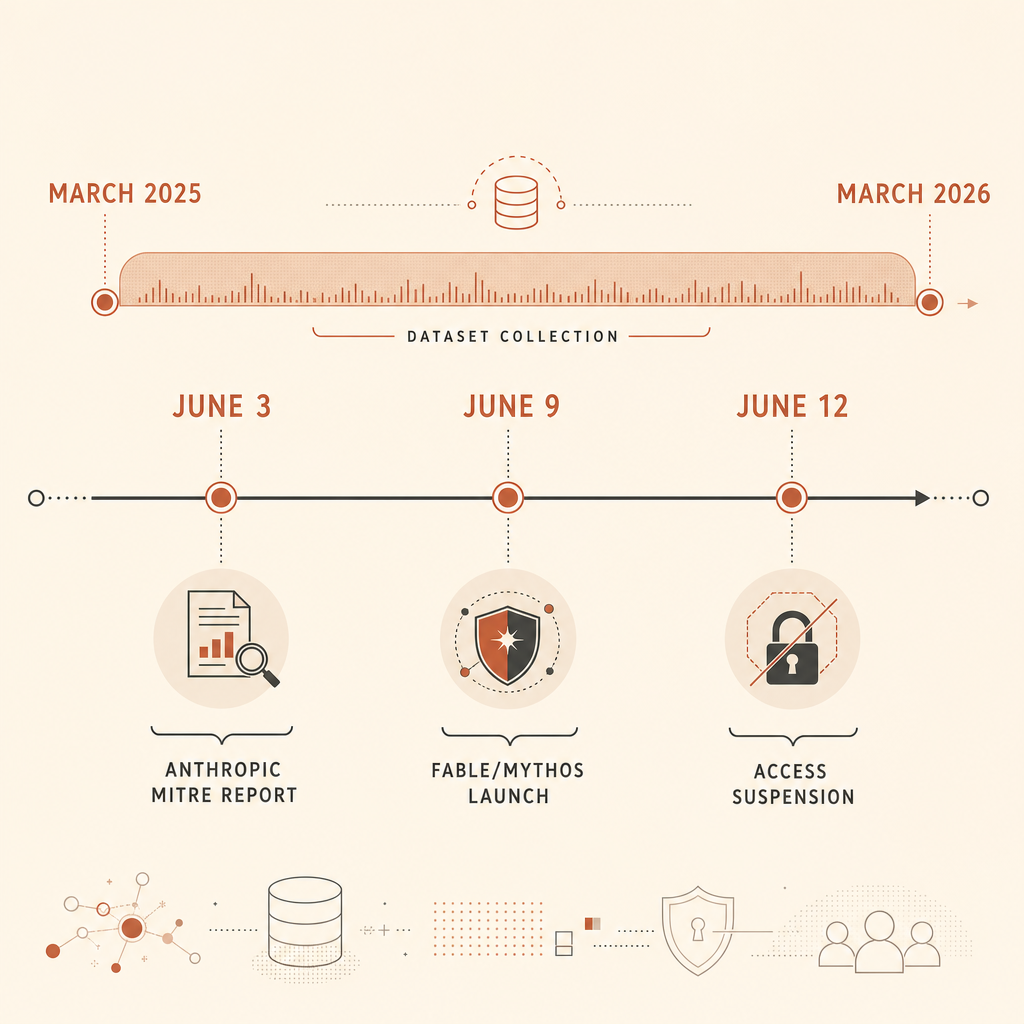
Anthropic’s June 3 cyber threat report has one hard number security teams should not ignore: it analyzed 832 Claude accounts banned for malicious cyber activity between March 2025 and March 2026, then mapped the activity to MITRE ATT&CK (Anthropic). The headline finding was not “AI writes malware.” We already knew that. The sharper claim is that MITRE ATT&CK, the shared language many defenders use to describe adversary behavior, does not yet capture the thing that makes AI-native attacks different: agentic orchestration.
That point landed in the middle of a noisy week. On June 9, Anthropic launched Claude Fable 5 and Claude Mythos 5, describing Fable as the public Mythos-class model with cybersecurity and biology safeguards, and Mythos as the restricted version for vetted defenders (Anthropic). By June 12, Anthropic said it had suspended Fable 5 and Mythos 5 access after a U.S. government directive tied to a reported jailbreak concern (Anthropic). Hacker News and Reddit threads are now arguing about whether those guardrails protect the public, kneecap defenders, or mostly create confusing false positives.
Developers should read the June 3 report separately from the Fable drama. It is not a product launch post. It is a measurement post. And it gives security engineers a practical update to make this quarter: start modeling agent scaffolding as attack infrastructure.
What Anthropic Actually Measured
Anthropic says the 832 accounts were a subset of banned accounts where investigators had enough detail to map observed activity to MITRE ATT&CK. Its Frontier Red Team write-up adds more detail: the team extracted 13,873 malicious activity observations, mapped them to ATT&CK v18, and found activity across all 14 ATT&CK tactics and 482 unique sub-techniques (Anthropic Frontier Red Team).
That matters because this was not a benchmark where a model is asked to solve a synthetic CTF. It was abuse telemetry from real users who violated cyber-related usage policy. That also means the dataset has limits. It sees misuse on Anthropic surfaces: Claude.ai, Claude Code, and the API. It does not measure the full internet, other model providers, local open-weight systems, or attacks that never touched Claude. Treat it like a strong sensor, not the whole sky.
The most common behavior was boring and important. Anthropic reported that 560 of the 832 accounts, or 67.3%, used AI for malware development. The broader “Develop Capabilities” ATT&CK family, T1587, appeared in 574 accounts, or 69%, according to the Frontier Red Team post. That is the commodity tier: build scripts, refine payloads, automate evasion, generate glue code.
The more interesting signal is where activity moved over time. In the first half of the study window, 33% of actors were classified by Anthropic’s ARiES risk scoring as medium risk or higher. In the second half, that rose to 56%, a roughly 1.7x increase. Anthropic also says AI-assisted account discovery rose 8.9%, while AI-assisted phishing fell 8.6% (Anthropic).
That is the part defenders should care about. Phishing is entry. Account discovery, lateral movement, privilege escalation, and credential access are post-compromise work. They require context, adaptation, and tactical choices. If AI use is drifting there, the model is no longer just a payload generator. It is becoming part of the operator loop.
| Signal from Anthropic’s dataset | Number |
|---|---|
| Banned malicious-cyber accounts analyzed | 832 |
| Study window | March 2025 to March 2026 |
| Observed malicious actions mapped | 13,873 |
| Unique ATT&CK sub-techniques observed | 482 |
| Accounts using AI for malware development | 560, or 67.3% |
| Medium-or-higher risk actors, first half | 33% |
| Medium-or-higher risk actors, second half | 56% |
Why MITRE ATT&CK Starts to Bend
MITRE ATT&CK is still valuable. MITRE describes it as a globally accessible knowledge base of adversary tactics and techniques based on real-world observations, used for threat models and methodologies across industry and government (MITRE). It gives teams shared IDs for things like T1587.001 malware development, credential dumping, account discovery, command execution, and exfiltration.
The problem is that ATT&CK is best at naming the atomic moves. Anthropic’s claim is that the dangerous AI behavior sits between those moves.
A human operator might decide: scan this host, inspect this result, pivot to these credentials, try this lateral path, then exfiltrate these files. ATT&CK can map each step. But if an agentic harness makes the choices, runs tools, updates its plan, and continues with minimal human input, the ATT&CK map can look ordinary while the operation is qualitatively different.
Anthropic’s example is the cyber espionage campaign it says it disrupted in November 2025. In that case, the actor used Claude Code in an operation Anthropic says attempted to infiltrate targets around the world with little human intervention. Mapped to ATT&CK, it used 30 techniques across 13 tactics, comparable to many medium-risk actors in the dataset. Under Anthropic’s ARiES system, it scored 100, the maximum (Anthropic).
That mismatch is the story. Technique count says “medium-ish.” Agentic execution says “critical.”
The Frontier Red Team post is more specific: the actor, labeled GTG-1002, used Claude Code on Kali Linux and integrated open-source penetration testing tools as MCP servers, turning the model into an autonomous attack platform rather than a code assistant (Anthropic Frontier Red Team). This is exactly the kind of behavior most internal threat models still under-describe.
“Agentic Cyber Risk” in Operational Terms
The phrase sounds abstract. It is not. For an engineering team, agentic cyber risk means the attacker has a loop like this:
observe target state -> choose next tactic -> call tool -> parse result
-> update memory -> pivot or stop -> repeat without waiting for a humanThat loop changes three things.
First, it compresses time. A low-skill actor no longer needs to understand every tool deeply if the model can select commands, interpret output, and recover from errors. Anthropic found weak correlation between apparent actor skill and the number of techniques used: the least-skilled actors averaged about 16 distinct techniques, while the most skilled averaged about 20 (Anthropic).
Second, it makes interface choice less comforting. Anthropic says whether the actor used Claude Code, an API, or a chat interface did not correlate with risk level. The high-risk differentiator was where the actor applied AI in the attack lifecycle and what scaffolding they built around it.
Third, it turns “guardrails” into a runtime systems problem. A blocked prompt is one control. But a long-running agent with tools, memory, retries, shell access, browser access, and MCP servers is a distributed system. The risky action may emerge across many requests. That explains why Anthropic tied Fable 5 and Mythos-class models to 30-day retention for safety monitoring, saying the data helps detect multi-request jailbreaks and misuse patterns (Anthropic).
Developers may dislike that policy. Enterprise buyers with zero-retention commitments really dislike it. But from a detection standpoint, Anthropic’s argument is coherent: a single-turn classifier cannot see an attack graph.
The Community Fight Is About False Positives and Access
The developer debate is not “should AI help hackers?” Nobody serious wants malware-as-a-service. The real fight is: who gets the full model, who gets downgraded, and how visible are the controls?
On Hacker News, the April Project Glasswing discussion mixed skepticism about Anthropic’s marketing with a more concrete concern: if a tool-using agent is persistent, goal-directed, and connected to real tools, the same properties that help vulnerability research become dangerous if the agent goes off-script (Hacker News). That is the adult version of the debate.
On Reddit, the launch-week complaints were more raw. In one r/Anthropic thread, a user described asking Fable to audit a project and being flagged and demoted to Opus, asking how Fable is useful if it trips that easily (Reddit). In r/cybersecurity, users discussed the 30-day retention requirement and whether the guardrail was too blunt for legitimate security work (Reddit).
TechCrunch captured the same pain from security researchers. Matt Suiche told the publication that even secure-code requests could be treated as cybersecurity and downgraded, and described the behavior as seemingly keyword-based (TechCrunch). Anthropic’s own launch post admits the safeguards were tuned conservatively and would sometimes catch harmless requests.
Then came the June 12 suspension. Anthropic said the government directive forced it to disable Fable 5 and Mythos 5 for all customers, even though it disagreed that a narrow potential jailbreak should justify recalling a commercial model (Anthropic). That turned the community argument from “false positives are annoying” into “model access is now part of cyber policy.”
My position: Anthropic is right that agentic cyber risk is real, and also right that perfect jailbreak resistance is fantasy. But blunt downgrades are a bad developer experience and a bad security control if defenders cannot predict when their tools will change behavior. Security teams need transparent routing, audit logs, approved high-risk workflows, and scoped tool permissions. They do not need surprise model swaps in the middle of incident response.
How to Update Your Internal Threat Model
If your company allows Claude Code-style tools, Cursor-like agents, internal coding agents, or API-driven LLM automation, update the threat model now. Do not wait for MITRE to mint new IDs.
Start with agent inventory. Track which agents can read repositories, run shell commands, browse internal systems, call scanners, open tickets, or access secrets. The unit of risk is no longer “user pasted code into chat.” It is “agent has tools plus state plus a goal.”
Add scaffold detection to your telemetry. Log tool calls, command sequences, MCP server usage, retries, file reads, network requests, and permission changes. A single nmap invocation may be normal in a lab. A loop that scans, parses, selects credentials, pivots hosts, and writes findings to memory should page someone.
Separate defensive workflows from open-ended autonomy. A good pattern is a bounded job: “scan this repo for SQL injection sinks and produce candidate patches,” with read-only credentials and no network egress. A bad pattern is “investigate our staging environment and fix whatever you find,” with broad shell access and persistent memory.
Map ATT&CK techniques, but add an internal “agentic layer” on top:
| Internal label | What to record |
|---|---|
| Autonomous chaining | Did the model sequence multiple ATT&CK steps without human approval? |
| Tactical pivoting | Did it choose a new target, credential, exploit path, or tool based on live output? |
| Tool privilege | What could the agent execute, read, modify, or exfiltrate? |
| Memory use | Did it persist target state, credentials, hypotheses, or plans? |
| Human checkpoints | Which steps required explicit approval, and were approvals meaningful? |
For AI platform teams, the practical control is policy at the tool boundary. Do not rely only on model refusals. Enforce allowlists for commands. Require approvals for network scanning, credential access, exploit proof-of-concept generation, and destructive changes. Put secrets behind brokers that can deny agent access by default. Rate-limit autonomous loops. Keep per-run provenance so a security reviewer can replay what the agent saw and did.
For security engineers, the new detection question is simple: “Could a junior attacker with this agent behave like a senior operator for one hour?” If the answer is yes, classify the workflow as high-risk even when each individual technique looks ordinary.
The Useful Takeaway
Anthropic’s report is easy to misread as a complaint that MITRE ATT&CK is outdated. That is too shallow. ATT&CK still names the moves. The missing vocabulary is for the conductor.
The June 3 dataset shows AI misuse moving deeper into the kill chain, from preparation into post-compromise activity. The Fable/Mythos fight shows why shipping defenses for that world is messy: developers want powerful tools, defenders need access, vendors need monitoring, and governments are now willing to intervene.
The right response is not panic, and it is not pretending guardrails are enough. Treat agent scaffolding as infrastructure. Threat model it. Log it. Put policy around tool use. Add “autonomous orchestration” and “real-time tactical pivoting” to your internal detection language today, even before MITRE gives them official technique IDs.
Small footer: Readers who want to try Claude Fable 5 themselves, when access is available, can use it through Claude Fable 5 on OneHop, a drop-in endpoint at about 30% under list price. New accounts get $10 free with no card through start with $10 free.
Further reading: Getting started with Claude Fable 5.

