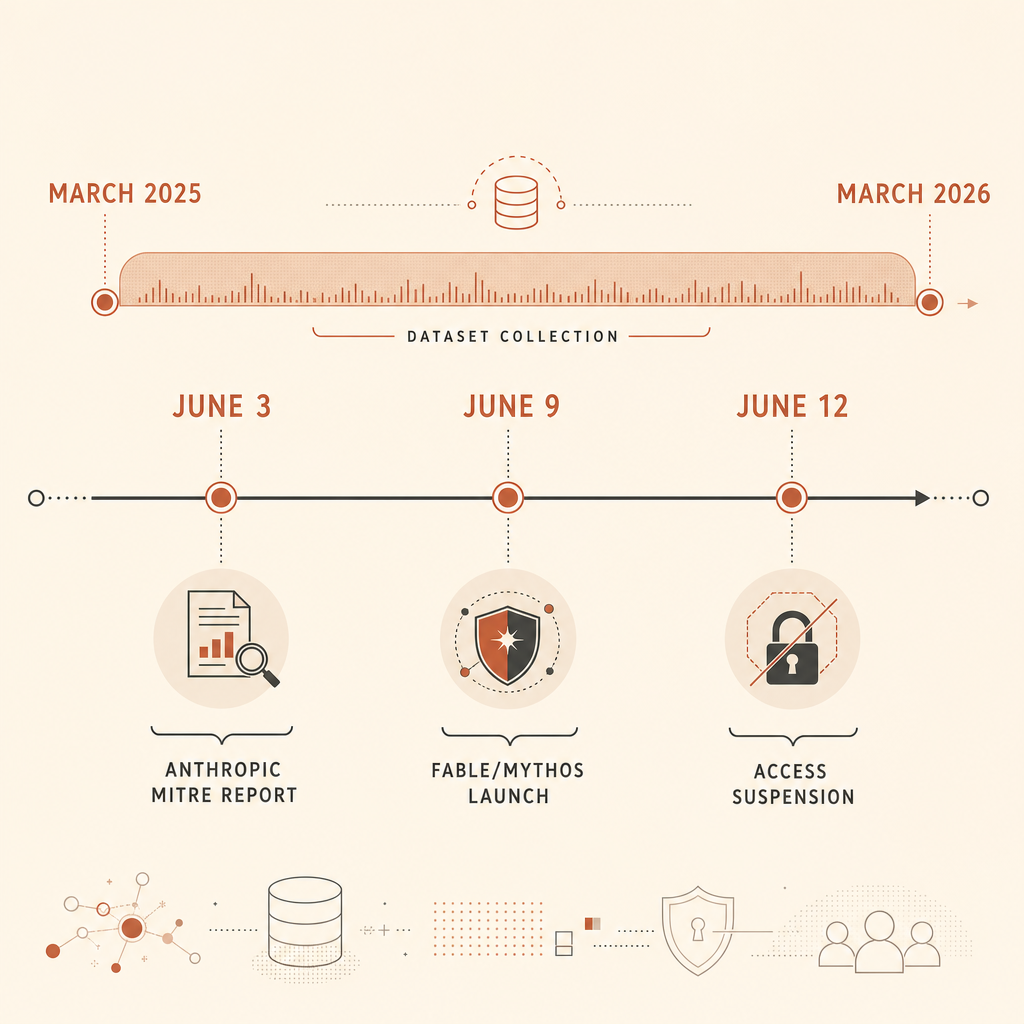
В отчёте Anthropic о киберугрозах от 3 июня есть одна жёсткая цифра, которую командам безопасности нельзя игнорировать: компания проанализировала 832 аккаунта Claude, заблокированных за вредоносную киберактивность в период с марта 2025 по март 2026 года, а затем сопоставила эту активность с MITRE ATT&CK (Anthropic). Главный вывод был не в духе «AI пишет вредоносы». Это мы уже знали. Более точная и неприятная мысль в другом: MITRE ATT&CK, общий язык, которым многие защитники описывают поведение противника, пока не отражает то, что делает AI-native атаки другими: агентную оркестрацию.
Этот тезис прозвучал посреди шумной недели. 9 июня Anthropic запустила Claude Fable 5 и Claude Mythos 5, описав Fable как публичную модель класса Mythos с защитами для кибербезопасности и биологии, а Mythos — как ограниченную версию для проверенных защитников (Anthropic). К 12 июня Anthropic заявила, что приостановила доступ к Fable 5 и Mythos 5 после директивы правительства США, связанной с сообщениями о возможном jailbreak (Anthropic). В тредах Hacker News и Reddit теперь спорят, защищают ли эти guardrails общественность, подрезают ли они защитников или в основном создают путаницу из ложных срабатываний.
Разработчикам стоит читать отчёт от 3 июня отдельно от драмы вокруг Fable. Это не пост о запуске продукта. Это пост с измерениями. И он даёт инженерам безопасности практичное обновление на этот квартал: начинайте моделировать агентные обвязки как инфраструктуру атаки.
Что Anthropic на самом деле измерила
Anthropic говорит, что 832 аккаунта были подмножеством заблокированных аккаунтов, по которым у расследователей было достаточно деталей, чтобы сопоставить наблюдаемую активность с MITRE ATT&CK. Материал Frontier Red Team добавляет подробностей: команда извлекла 13 873 наблюдения вредоносной активности, сопоставила их с ATT&CK v18 и нашла активность по всем 14 тактикам ATT&CK и 482 уникальным подтехникам (Anthropic Frontier Red Team).
Это важно, потому что это был не бенчмарк, где модель просят решить синтетический CTF. Это была телеметрия злоупотреблений от реальных пользователей, нарушивших правила использования в киберсфере. Но это также означает, что у датасета есть ограничения. Он видит злоупотребления на поверхностях Anthropic: Claude.ai, Claude Code и API. Он не измеряет весь интернет, других провайдеров моделей, локальные open-weight системы или атаки, которые никогда не касались Claude. Относитесь к нему как к сильному сенсору, а не как ко всему небу.
Самое частое поведение было скучным и важным. Anthropic сообщила, что 560 из 832 аккаунтов, или 67,3%, использовали AI для разработки вредоносов. Более широкое семейство ATT&CK “Develop Capabilities”, T1587, встречалось в 574 аккаунтах, или 69%, согласно посту Frontier Red Team. Это товарный уровень: писать скрипты, дорабатывать payload, автоматизировать обход, генерировать связующий код.
Более интересный сигнал — куда активность смещалась со временем. В первой половине окна исследования 33% акторов были классифицированы системой риск-скоринга ARiES от Anthropic как средний риск или выше. Во второй половине доля выросла до 56%, то есть примерно в 1,7 раза. Anthropic также говорит, что AI-assisted обнаружение аккаунтов выросло на 8,9%, а AI-assisted фишинг снизился на 8,6% (Anthropic).
Вот это защитникам и нужно замечать. Фишинг — это вход. Обнаружение аккаунтов, латеральное перемещение, повышение привилегий и доступ к учётным данным — это работа после компрометации. Она требует контекста, адаптации и тактических решений. Если использование AI дрейфует туда, модель уже не просто генератор payload. Она становится частью операторского цикла.
| Сигнал из датасета Anthropic | Число |
|---|---|
| Проанализированные заблокированные аккаунты с вредоносной киберактивностью | 832 |
| Окно исследования | Март 2025 — март 2026 |
| Сопоставленные наблюдаемые вредоносные действия | 13 873 |
| Уникальные наблюдаемые подтехники ATT&CK | 482 |
| Аккаунты, использовавшие AI для разработки вредоносов | 560, или 67,3% |
| Акторы со средним или более высоким риском, первая половина | 33% |
| Акторы со средним или более высоким риском, вторая половина | 56% |
Почему MITRE ATT&CK начинает прогибаться
MITRE ATT&CK всё ещё ценен. MITRE описывает его как глобально доступную базу знаний о тактиках и техниках противников, основанную на наблюдениях реального мира и используемую для моделей угроз и методологий в индустрии и госструктурах (MITRE). Он даёт командам общие ID для вещей вроде разработки вредоносов T1587.001, дампа учётных данных, обнаружения аккаунтов, выполнения команд и эксфильтрации.
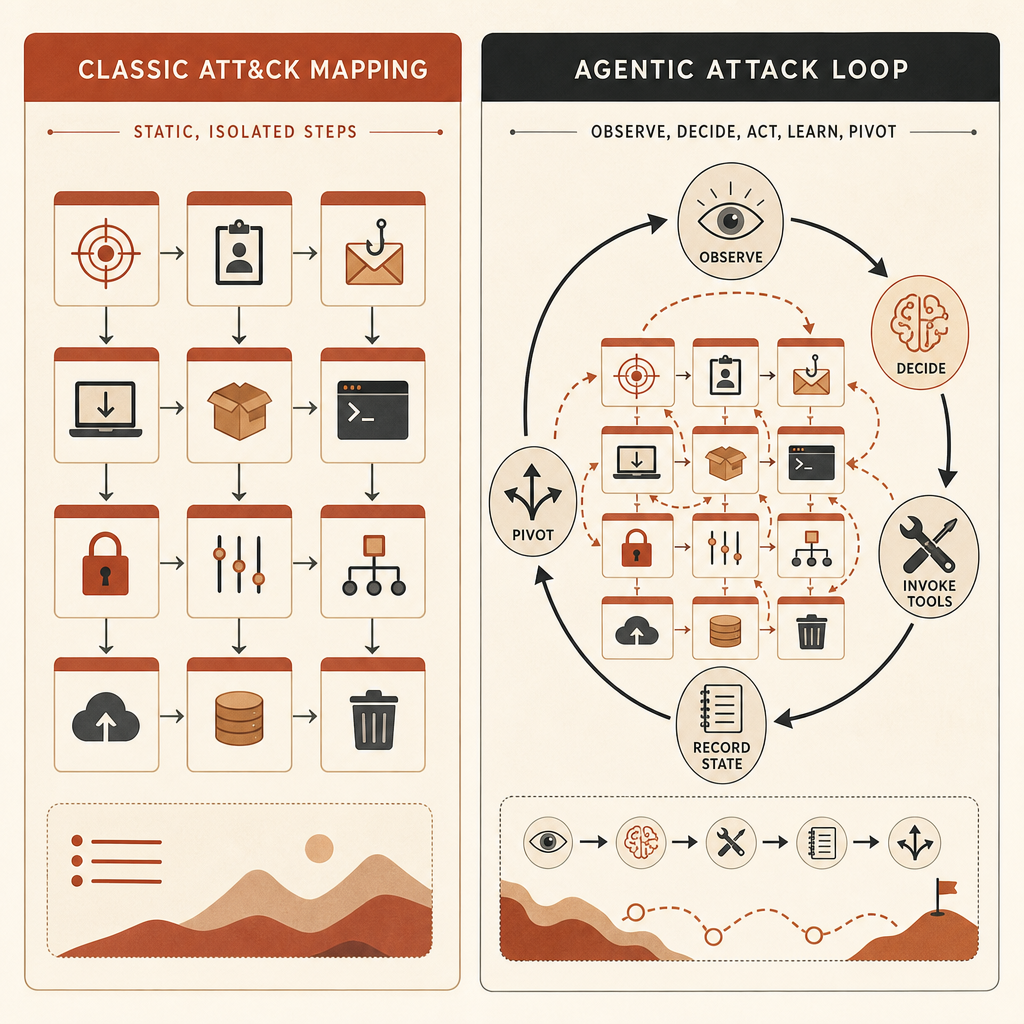
Проблема в том, что ATT&CK лучше всего называет атомарные ходы. Тезис Anthropic в том, что опасное AI-поведение находится между этими ходами.
Человеческий оператор может решить: просканировать этот хост, изучить результат, перейти к этим учётным данным, попробовать этот латеральный путь, затем эксфильтровать эти файлы. ATT&CK может разметить каждый шаг. Но если агентная обвязка принимает решения, запускает инструменты, обновляет план и продолжает с минимальным участием человека, карта ATT&CK может выглядеть обычной, хотя сама операция качественно другая.
Пример Anthropic — кампания кибершпионажа, которую, по словам компании, она пресекла в ноябре 2025 года. В этом случае актор использовал Claude Code в операции, которая, как утверждает Anthropic, пыталась проникнуть в цели по всему миру с малым участием человека. В разметке ATT&CK она использовала 30 техник по 13 тактикам, что сопоставимо со многими акторами среднего риска в датасете. По системе ARiES от Anthropic она получила 100, максимум (Anthropic).
Вот в этом несоответствии и вся история. Количество техник говорит: «примерно средне». Агентное выполнение говорит: «критично».
Пост Frontier Red Team конкретнее: актор, обозначенный как GTG-1002, использовал Claude Code на Kali Linux и подключил open-source инструменты пентеста как MCP-серверы, превратив модель в автономную атакующую платформу, а не в помощника по коду (Anthropic Frontier Red Team). Это ровно тот тип поведения, который большинство внутренних моделей угроз всё ещё описывает недостаточно.
«Агентный киберриск» в операционных терминах
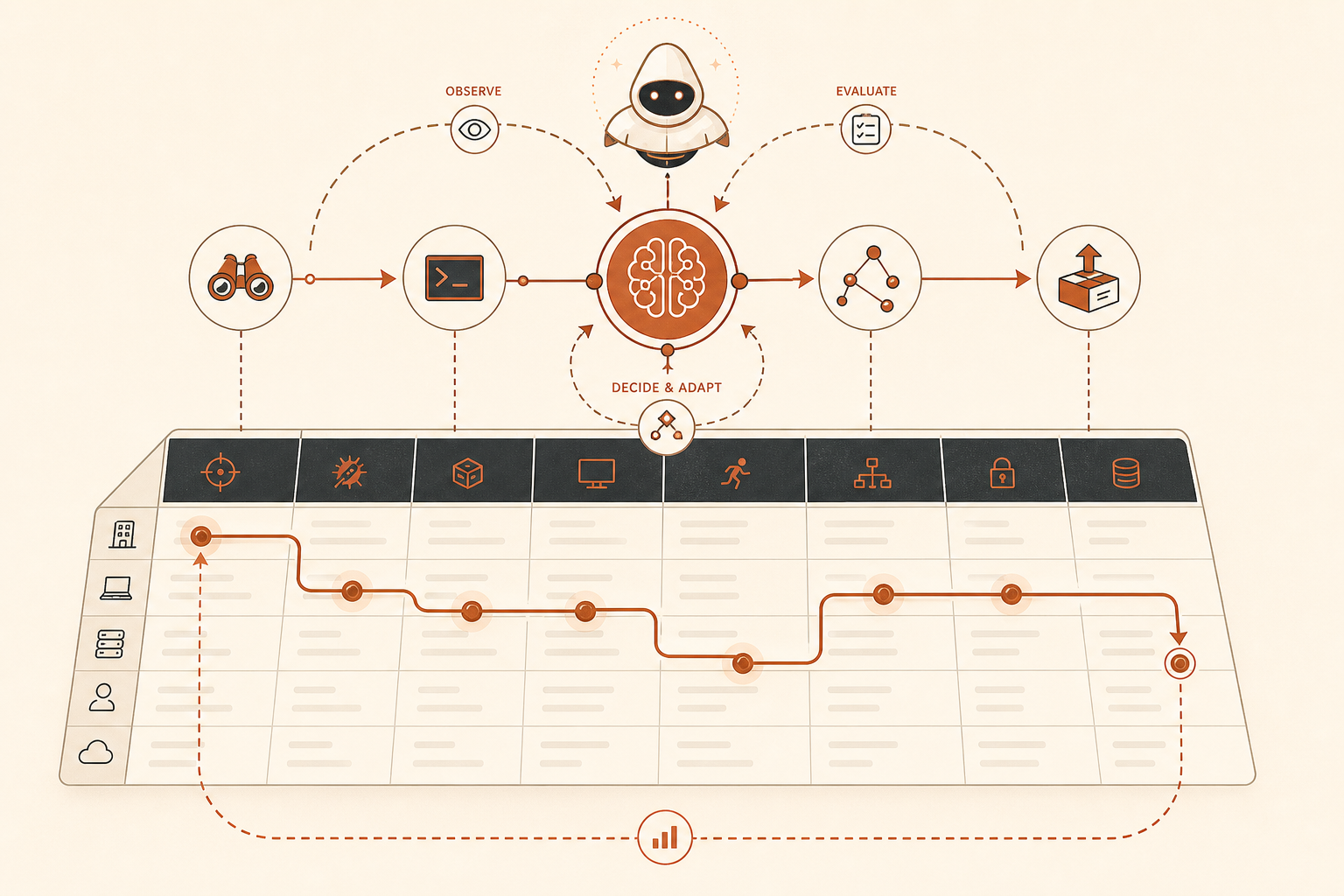
Фраза звучит абстрактно. Но это не так. Для инженерной команды агентный киберриск означает, что у атакующего есть такой цикл:
observe target state -> choose next tactic -> call tool -> parse result
-> update memory -> pivot or stop -> repeat without waiting for a humanЭтот цикл меняет три вещи.
Во-первых, он сжимает время. Низкоквалифицированному актору больше не нужно глубоко понимать каждый инструмент, если модель может выбирать команды, интерпретировать вывод и восстанавливаться после ошибок. Anthropic обнаружила слабую корреляцию между видимым уровнем навыка актора и количеством использованных техник: наименее квалифицированные акторы в среднем применяли около 16 разных техник, а самые опытные — около 20 (Anthropic).
Во-вторых, выбор интерфейса перестаёт успокаивать. Anthropic говорит, что то, использовал ли актор Claude Code, API или чат-интерфейс, не коррелировало с уровнем риска. Высокий риск отличался тем, где актор применял AI в жизненном цикле атаки и какую обвязку строил вокруг него.
В-третьих, это превращает «guardrails» в проблему runtime-систем. Заблокированный prompt — один контроль. Но долго работающий агент с инструментами, памятью, повторами, доступом к shell, доступом к браузеру и MCP-серверами — это распределённая система. Рискованное действие может возникнуть через множество запросов. Это объясняет, почему Anthropic привязала Fable 5 и модели класса Mythos к 30-дневному хранению данных для мониторинга безопасности, заявив, что эти данные помогают выявлять многоходовые jailbreak и паттерны злоупотреблений (Anthropic).
Разработчикам такая политика может не нравиться. Корпоративным покупателям с обязательствами zero-retention она очень не нравится. Но с точки зрения детекта аргумент Anthropic логичен: одноходовой классификатор не видит граф атаки.
Спор в сообществе — о ложных срабатываниях и доступе
Дебаты среди разработчиков не про «должен ли AI помогать хакерам?». Никто серьёзный не хочет malware-as-a-service. Настоящий спор в другом: кто получает полную модель, кого понижают, и насколько видимы эти контроли?
На Hacker News обсуждение апрельского Project Glasswing смешало скепсис к маркетингу Anthropic с более конкретной тревогой: если агент, использующий инструменты, настойчив, целеориентирован и подключён к реальным инструментам, те же свойства, которые помогают исследованию уязвимостей, становятся опасными, если агент уходит не по сценарию (Hacker News). Это взрослая версия спора.
На Reddit жалобы недели запуска были более сырыми. В одном треде r/Anthropic пользователь описал, как попросил Fable провести аудит проекта, получил флаг и был понижен до Opus, после чего спросил, чем Fable полезен, если он так легко срабатывает (Reddit). В r/cybersecurity пользователи обсуждали требование 30-дневного хранения и вопрос, не слишком ли грубый этот guardrail для легитимной работы по безопасности (Reddit).
TechCrunch зафиксировал ту же боль со стороны исследователей безопасности. Matt Suiche сказал изданию, что даже запросы про безопасный код могли трактоваться как кибербезопасность и понижаться, и описал поведение как, похоже, основанное на ключевых словах (TechCrunch). Собственный пост Anthropic о запуске признаёт, что safeguards были настроены консервативно и иногда будут ловить безвредные запросы.
Потом пришла приостановка 12 июня. Anthropic заявила, что правительственная директива вынудила её отключить Fable 5 и Mythos 5 для всех клиентов, хотя компания не соглашалась с тем, что узкий потенциальный jailbreak должен оправдывать отзыв коммерческой модели (Anthropic). Это превратило спор сообщества из «ложные срабатывания раздражают» в «доступ к модели теперь часть киберполитики».
Моя позиция: Anthropic права, что агентный киберриск реален, и также права, что идеальная устойчивость к jailbreak — фантазия. Но грубые понижения — плохой developer experience и плохой контроль безопасности, если защитники не могут предсказать, когда их инструменты изменят поведение. Командам безопасности нужны прозрачная маршрутизация, audit logs, утверждённые high-risk workflows и ограниченные разрешения для инструментов. Им не нужны внезапные замены модели посреди реагирования на инцидент.
Как обновить внутреннюю модель угроз
Если ваша компания разрешает инструменты в стиле Claude Code, Cursor-подобных агентов, внутренних coding agents или API-driven LLM-автоматизацию, обновите модель угроз сейчас. Не ждите, пока MITRE выпустит новые ID.
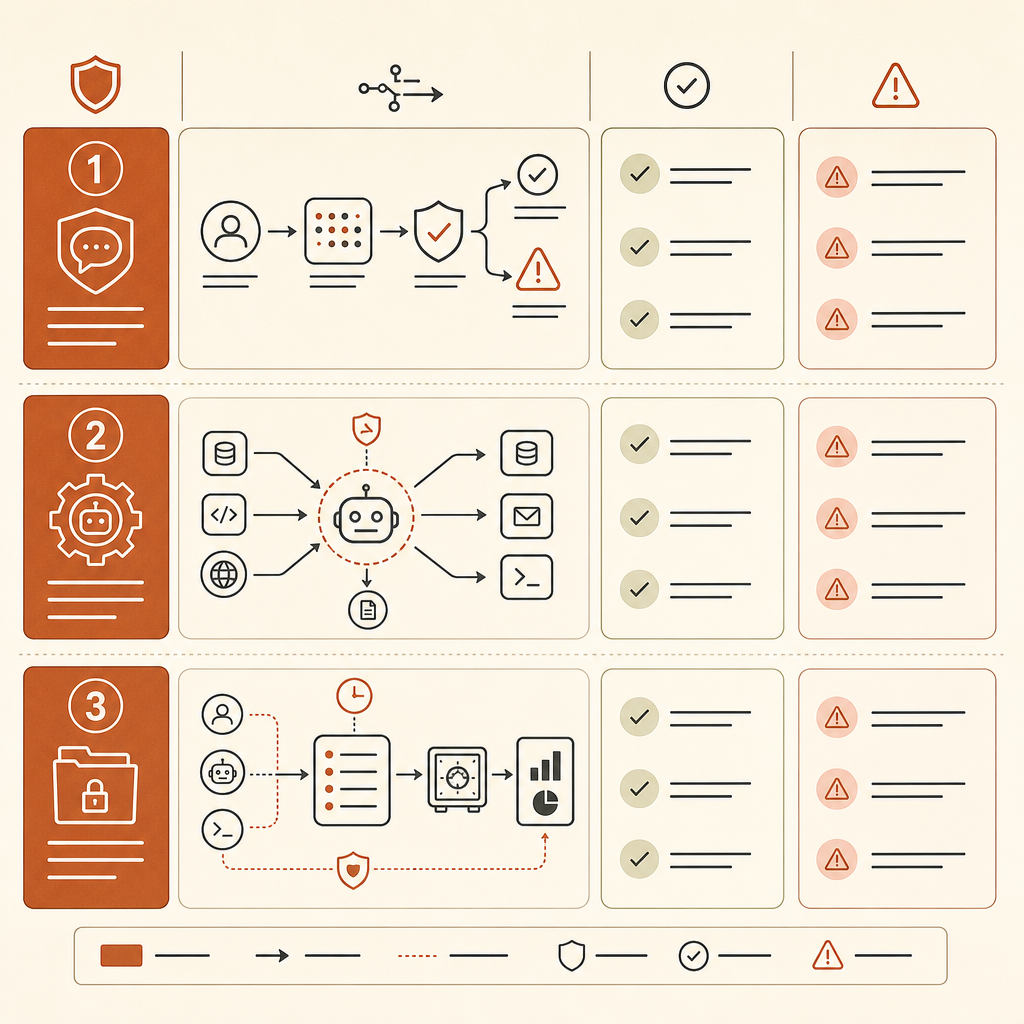
Начните с инвентаризации агентов. Отслеживайте, какие агенты могут читать репозитории, запускать shell-команды, просматривать внутренние системы, вызывать сканеры, открывать тикеты или получать доступ к секретам. Единица риска больше не «пользователь вставил код в чат». Это «у агента есть инструменты плюс состояние плюс цель».
Добавьте детект обвязки в телеметрию. Логируйте вызовы инструментов, последовательности команд, использование MCP-серверов, повторы, чтение файлов, сетевые запросы и изменения разрешений. Один запуск nmap может быть нормой в лаборатории. Цикл, который сканирует, парсит, выбирает учётные данные, переходит между хостами и записывает findings в память, должен поднимать людей.
Отделяйте защитные workflow от открытой автономности. Хороший паттерн — ограниченная задача: «просканируй этот репозиторий на SQL injection sinks и подготовь candidate patches», с read-only учётными данными и без сетевого egress. Плохой паттерн — «исследуй наш staging environment и исправь всё, что найдёшь», с широким shell-доступом и постоянной памятью.
Мапьте техники ATT&CK, но добавьте сверху внутренний «агентный слой»:
| Внутренняя метка | Что записывать |
|---|---|
| Автономное сцепление | Выстроила ли модель несколько шагов ATT&CK без одобрения человека? |
| Тактический pivot | Выбрала ли она новую цель, учётные данные, путь эксплуатации или инструмент на основе живого вывода? |
| Привилегии инструментов | Что агент мог выполнять, читать, изменять или эксфильтровать? |
| Использование памяти | Сохранял ли он состояние цели, учётные данные, гипотезы или планы? |
| Человеческие checkpoints | Какие шаги требовали явного одобрения, и были ли эти одобрения осмысленными? |
Для команд AI-платформ практический контроль — это policy на границе инструмента. Не полагайтесь только на отказы модели. Вводите allowlists для команд. Требуйте одобрения для сетевого сканирования, доступа к учётным данным, генерации exploit proof-of-concept и разрушительных изменений. Прячьте секреты за brokers, которые по умолчанию могут запрещать агентам доступ. Ограничивайте скорость автономных циклов. Сохраняйте provenance по каждому запуску, чтобы security reviewer мог воспроизвести, что агент видел и сделал.
Для инженеров безопасности новый вопрос детекта прост: «Может ли junior attacker с этим агентом один час вести себя как senior operator?» Если ответ да, классифицируйте workflow как high-risk, даже когда каждая отдельная техника выглядит обычной.
Полезный вывод
Отчёт Anthropic легко неверно прочитать как жалобу на устаревший MITRE ATT&CK. Это слишком поверхностно. ATT&CK всё ещё называет ходы. Не хватает словаря для дирижёра.
Датасет от 3 июня показывает, что злоупотребление AI уходит глубже в kill chain: от подготовки к post-compromise активности. Спор вокруг Fable/Mythos показывает, почему выпуск защит для такого мира грязный и сложный: разработчики хотят мощные инструменты, защитникам нужен доступ, вендорам нужен мониторинг, а правительства теперь готовы вмешиваться.
Правильная реакция — не паника и не притворство, что guardrails достаточно. Относитесь к агентной обвязке как к инфраструктуре. Моделируйте её в угрозах. Логируйте её. Обкладывайте policy использование инструментов. Добавьте «автономную оркестрацию» и «тактический pivot в реальном времени» во внутренний язык детекта уже сегодня, даже до того, как MITRE даст им официальные ID техник.
Небольшой footer: читатели, которые хотят сами попробовать Claude Fable 5, когда доступ будет доступен, могут использовать его через Claude Fable 5 на OneHop, drop-in endpoint примерно на 30% ниже list price. Новые аккаунты получают $10 бесплатно без карты через начать с $10 бесплатно.
Дополнительно: Getting started with Claude Fable 5.

