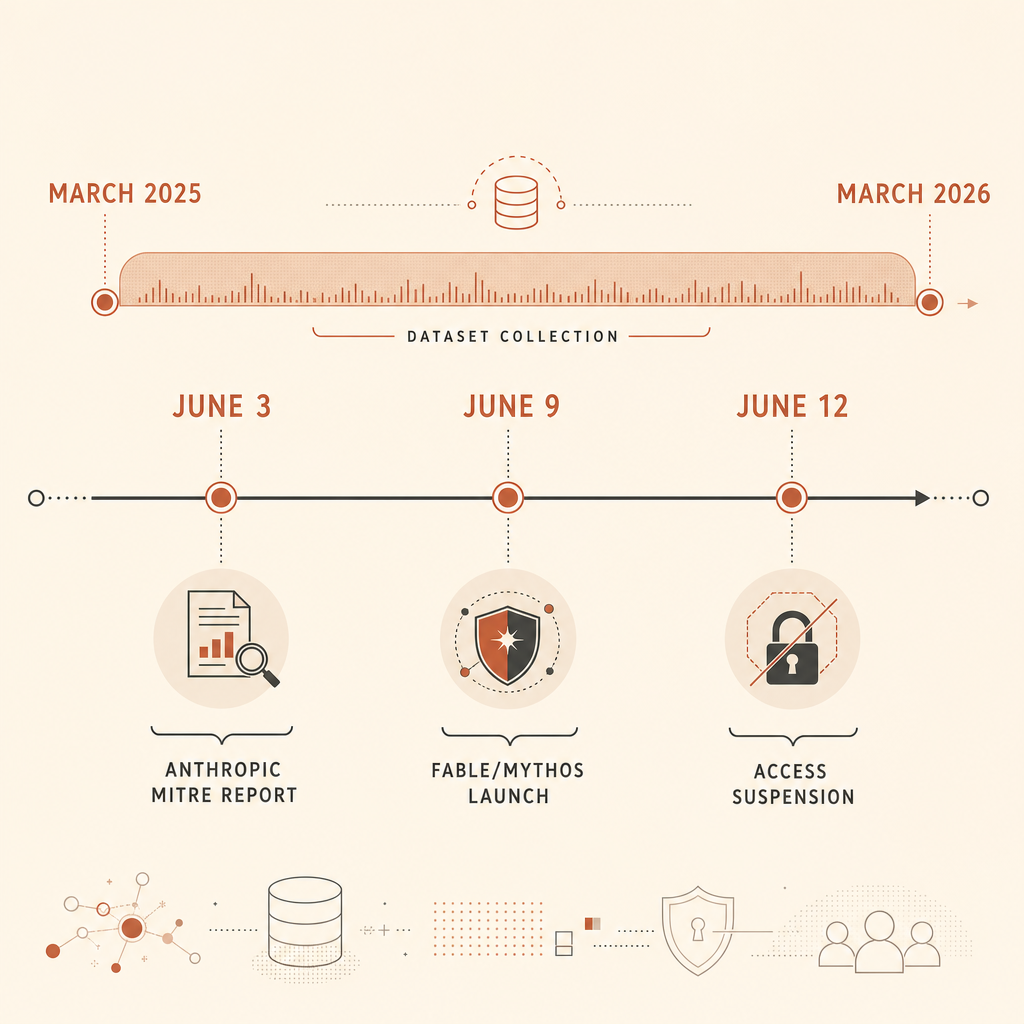
Anthropic’in 3 Haziran tarihli siber tehdit raporunda güvenlik ekiplerinin görmezden gelmemesi gereken net bir sayı var: Mart 2025 ile Mart 2026 arasında kötü amaçlı siber faaliyet nedeniyle yasaklanan 832 Claude hesabı analiz edildi, ardından bu faaliyet MITRE ATT&CK ile eşleştirildi (Anthropic). Manşetlik bulgu “AI zararlı yazılım yazıyor” değildi. Bunu zaten biliyorduk. Daha keskin iddia şu: Birçok savunmacının saldırgan davranışını tarif etmek için kullandığı ortak dil olan MITRE ATT&CK, AI-native saldırıları farklı kılan şeyi henüz yakalayamıyor: agentic orkestrasyon.
Bu nokta, oldukça gürültülü bir haftanın ortasına düştü. 9 Haziran’da Anthropic, Claude Fable 5 ve Claude Mythos 5’i duyurdu; Fable’ı siber güvenlik ve biyoloji korumaları olan herkese açık Mythos sınıfı model, Mythos’u ise doğrulanmış savunmacılar için kısıtlı sürüm olarak tanımladı (Anthropic). 12 Haziran’a gelindiğinde Anthropic, bildirilen bir jailbreak endişesine bağlanan ABD hükümeti direktifinin ardından Fable 5 ve Mythos 5 erişimini askıya aldığını söyledi (Anthropic). Hacker News ve Reddit başlıklarında şimdi bu guardrail’lerin kamuyu mu koruduğu, savunmacıların dizini mi kestiği, yoksa çoğunlukla kafa karıştırıcı false positive’ler mi ürettiği tartışılıyor.
Geliştiriciler, 3 Haziran raporunu Fable dramasından ayrı okumalı. Bu bir ürün lansmanı yazısı değil. Bir ölçüm yazısı. Ve güvenlik mühendislerine bu çeyrek yapmaları gereken pratik bir güncelleme veriyor: agent scaffolding’i saldırı altyapısı olarak modellemeye başlayın.
Anthropic Aslında Neyi Ölçtü
Anthropic, 832 hesabın; araştırmacıların gözlemlenen faaliyeti MITRE ATT&CK ile eşleştirmek için yeterli ayrıntıya sahip olduğu yasaklı hesapların bir alt kümesi olduğunu söylüyor. Frontier Red Team yazısı daha fazla ayrıntı ekliyor: ekip 13.873 kötü amaçlı faaliyet gözlemi çıkardı, bunları ATT&CK v18’e eşledi ve 14 ATT&CK taktiğinin tamamında ve 482 benzersiz alt teknikte faaliyet buldu (Anthropic Frontier Red Team).
Bu önemli, çünkü bu; bir modelden sentetik bir CTF çözmesinin istendiği bir benchmark değildi. Siber kullanım politikasını ihlal eden gerçek kullanıcılardan gelen kötüye kullanım telemetrisiydi. Bu aynı zamanda veri setinin sınırları olduğu anlamına geliyor. Anthropic yüzeylerindeki kötüye kullanımı görüyor: Claude.ai, Claude Code ve API. Tüm interneti, diğer model sağlayıcılarını, yerel open-weight sistemleri veya Claude’a hiç dokunmamış saldırıları ölçmüyor. Bunu güçlü bir sensör gibi düşünün, tüm gökyüzü gibi değil.
En yaygın davranış sıkıcıydı ve önemliydi. Anthropic, 832 hesabın 560’ının, yani %67,3’ünün AI’ı zararlı yazılım geliştirme için kullandığını bildirdi. Frontier Red Team yazısına göre daha geniş “Develop Capabilities” ATT&CK ailesi T1587, 574 hesapta, yani %69 oranında görüldü. Bu commodity katmanı: script yaz, payload’ları incelt, kaçınmayı otomatikleştir, yapıştırıcı kod üret.
Daha ilginç sinyal, faaliyetin zaman içinde nereye kaydığı. Çalışma aralığının ilk yarısında aktörlerin %33’ü, Anthropic’in ARiES risk skorlamasına göre orta riskli veya daha yüksek olarak sınıflandırıldı. İkinci yarıda bu oran %56’ya çıktı; kabaca 1,7 kat artış. Anthropic ayrıca AI destekli hesap keşfinin %8,9 arttığını, AI destekli phishing’in ise %8,6 düştüğünü söylüyor (Anthropic).
Savunmacıların önemsemesi gereken kısım bu. Phishing giriş noktasıdır. Hesap keşfi, lateral movement, privilege escalation ve credential access ise compromise sonrası iştir. Bağlam, adaptasyon ve taktik seçim gerektirirler. AI kullanımı oraya kayıyorsa, model artık yalnızca bir payload üreticisi değildir. Operatör döngüsünün parçası haline geliyordur.
| Anthropic’in veri setinden sinyal | Sayı |
|---|---|
| Analiz edilen yasaklı kötü amaçlı siber hesap | 832 |
| Çalışma aralığı | Mart 2025-Mart 2026 |
| Eşleştirilen gözlemlenmiş kötü amaçlı eylem | 13.873 |
| Gözlemlenen benzersiz ATT&CK alt tekniği | 482 |
| Zararlı yazılım geliştirme için AI kullanan hesaplar | 560, yani %67,3 |
| İlk yarıda orta veya daha yüksek riskli aktörler | %33 |
| İkinci yarıda orta veya daha yüksek riskli aktörler | %56 |
MITRE ATT&CK Neden Esnemeye Başlıyor
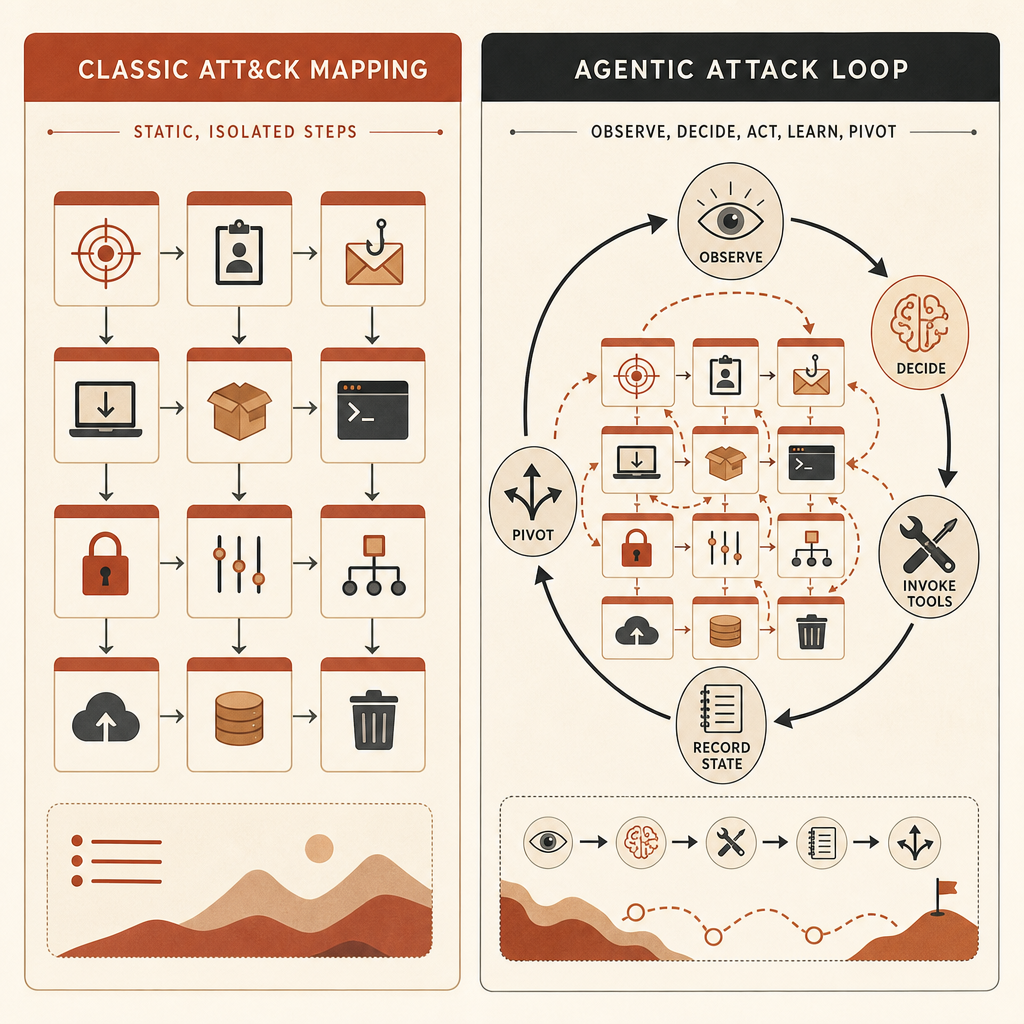
MITRE ATT&CK hâlâ değerli. MITRE bunu, gerçek dünya gözlemlerine dayanan; sektör ve kamu genelinde tehdit modelleri ve metodolojileri için kullanılan, küresel olarak erişilebilir bir saldırgan taktik ve teknik bilgi tabanı olarak tanımlıyor (MITRE). Ekiplere T1587.001 zararlı yazılım geliştirme, credential dumping, hesap keşfi, komut çalıştırma ve exfiltration gibi şeyler için ortak ID’ler veriyor.
Sorun şu: ATT&CK atomik hamleleri adlandırmada çok iyi. Anthropic’in iddiası ise tehlikeli AI davranışının bu hamlelerin arasında yer aldığı.
Bir insan operatör şöyle karar verebilir: şu host’u tara, bu sonucu incele, bu kimlik bilgilerine pivot et, şu lateral yolu dene, sonra bu dosyaları dışarı çıkar. ATT&CK her adımı haritalayabilir. Ama seçimleri agentic bir harness yapıyor, araçları çalıştırıyor, planını güncelliyor ve minimum insan girdisiyle devam ediyorsa, ATT&CK haritası sıradan görünebilir; operasyon ise nitelik olarak bambaşka olabilir.
Anthropic’in örneği, Kasım 2025’te durdurduğunu söylediği siber casusluk kampanyası. Bu vakada aktör, Anthropic’in dünya çapındaki hedeflere çok az insan müdahalesiyle sızmaya çalıştığını söylediği bir operasyonda Claude Code kullandı. ATT&CK’e eşlendiğinde, veri setindeki birçok orta riskli aktöre benzer şekilde 13 taktik genelinde 30 teknik kullandı. Anthropic’in ARiES sisteminde ise maksimum skor olan 100 aldı (Anthropic).
Hikâye tam da bu uyumsuzluk. Teknik sayısı “orta karar” diyor. Agentic yürütme “kritik” diyor.
Frontier Red Team yazısı daha spesifik: GTG-1002 olarak etiketlenen aktör, Kali Linux üzerinde Claude Code kullandı ve açık kaynak penetration testing araçlarını MCP server olarak entegre etti; modeli bir kod asistanından ziyade otonom bir saldırı platformuna çevirdi (Anthropic Frontier Red Team). Bu, çoğu iç tehdit modelinin hâlâ yeterince tarif etmediği davranışın ta kendisi.
Operasyonel Dille “Agentic Siber Risk”
İfade soyut geliyor. Değil. Bir mühendislik ekibi için agentic siber risk, saldırganın şöyle bir döngüye sahip olması demek:
observe target state -> choose next tactic -> call tool -> parse result
-> update memory -> pivot or stop -> repeat without waiting for a humanBu döngü üç şeyi değiştirir.
Birincisi, zamanı sıkıştırır. Düşük becerili bir aktörün, model komut seçebiliyor, çıktıyı yorumlayabiliyor ve hatalardan toparlanabiliyorsa her aracı derinlemesine anlamasına artık gerek yok. Anthropic, görünen aktör becerisi ile kullanılan teknik sayısı arasında zayıf korelasyon buldu: en düşük becerili aktörler ortalama yaklaşık 16 farklı teknik kullanırken, en becerikliler yaklaşık 20 kullandı (Anthropic).
İkincisi, arayüz seçimini daha az rahatlatıcı hale getirir. Anthropic, aktörün Claude Code, API veya chat arayüzü kullanmasının risk seviyesiyle korele olmadığını söylüyor. Yüksek riskte ayırt edici olan şey, aktörün AI’ı saldırı yaşam döngüsünün neresinde uyguladığı ve etrafına ne tür scaffolding kurduğuydu.
Üçüncüsü, “guardrail”leri bir runtime sistemleri problemine dönüştürür. Engellenmiş bir prompt tek bir kontroldür. Ama araçları, belleği, retry’ları, shell erişimi, tarayıcı erişimi ve MCP server’ları olan uzun süre çalışan bir agent dağıtık bir sistemdir. Riskli eylem birçok istek boyunca ortaya çıkabilir. Bu, Anthropic’in Fable 5 ve Mythos sınıfı modelleri neden güvenlik izleme için 30 günlük saklama şartına bağladığını açıklıyor; verinin çok istekli jailbreak’leri ve kötüye kullanım kalıplarını tespit etmeye yardımcı olduğunu söylüyor (Anthropic).
Geliştiriciler bu politikadan hoşlanmayabilir. Zero-retention taahhütleri olan kurumsal alıcılar bundan gerçekten hoşlanmaz. Ama tespit açısından Anthropic’in argümanı tutarlı: tek turlu bir sınıflandırıcı bir saldırı grafiğini göremez.
Topluluk Kavgası False Positive’ler ve Erişim Üzerine
Geliştirici tartışması “AI hacker’lara yardım etmeli mi?” değil. Ciddi kimse malware-as-a-service istemiyor. Asıl kavga şu: tam modeli kim alacak, kim düşürülecek ve kontroller ne kadar görünür olacak?
Hacker News’teki Nisan Project Glasswing tartışması, Anthropic’in pazarlamasına yönelik şüpheciliği daha somut bir endişeyle karıştırdı: araç kullanan bir agent kalıcı, hedef odaklı ve gerçek araçlara bağlıysa, güvenlik açığı araştırmasına yardımcı olan aynı özellikler agent rotadan çıkarsa tehlikeli hale gelir (Hacker News). Tartışmanın yetişkin versiyonu bu.
Reddit’te lansman haftası şikâyetleri daha hamdı. Bir r/Anthropic başlığında bir kullanıcı, Fable’dan bir projeyi denetlemesini istediğini, flag’lendiğini ve Opus’a düşürüldüğünü anlattı; bu kadar kolay tetikleniyorsa Fable’ın nasıl işe yarayacağını sordu (Reddit). r/cybersecurity’de kullanıcılar 30 günlük saklama şartını ve guardrail’in meşru güvenlik çalışması için fazla kör olup olmadığını tartıştı (Reddit).
TechCrunch, güvenlik araştırmacılarından gelen aynı sancıyı yakaladı. Matt Suiche yayına, güvenli kod taleplerinin bile siber güvenlik olarak ele alınıp düşürülebileceğini söyledi ve davranışı görünüşte keyword tabanlı olarak tanımladı (TechCrunch). Anthropic’in kendi lansman yazısı, korumaların muhafazakâr ayarlandığını ve bazen zararsız istekleri yakalayacağını kabul ediyor.
Sonra 12 Haziran askıya alma geldi. Anthropic, hükümet direktifinin Fable 5 ve Mythos 5’i tüm müşteriler için devre dışı bırakmaya zorladığını söyledi; dar kapsamlı potansiyel bir jailbreak’in ticari bir modeli geri çağırmayı haklı çıkarması gerektiğine katılmadığını da belirtti (Anthropic). Bu, topluluk tartışmasını “false positive’ler sinir bozucu”dan “model erişimi artık siber politikanın parçası”na çevirdi.
Benim pozisyonum: Anthropic, agentic siber riskin gerçek olduğu konusunda haklı; mükemmel jailbreak direncinin hayal olduğu konusunda da haklı. Ama savunmacılar araçlarının davranışının ne zaman değişeceğini öngöremiyorsa, kaba model düşürmeleri hem kötü bir geliştirici deneyimi hem de kötü bir güvenlik kontrolüdür. Güvenlik ekiplerinin şeffaf routing’e, audit log’larına, onaylı yüksek riskli iş akışlarına ve kapsamı belirlenmiş araç izinlerine ihtiyacı var. Incident response’un ortasında sürpriz model değişimlerine değil.
İç Tehdit Modelinizi Nasıl Güncellemelisiniz
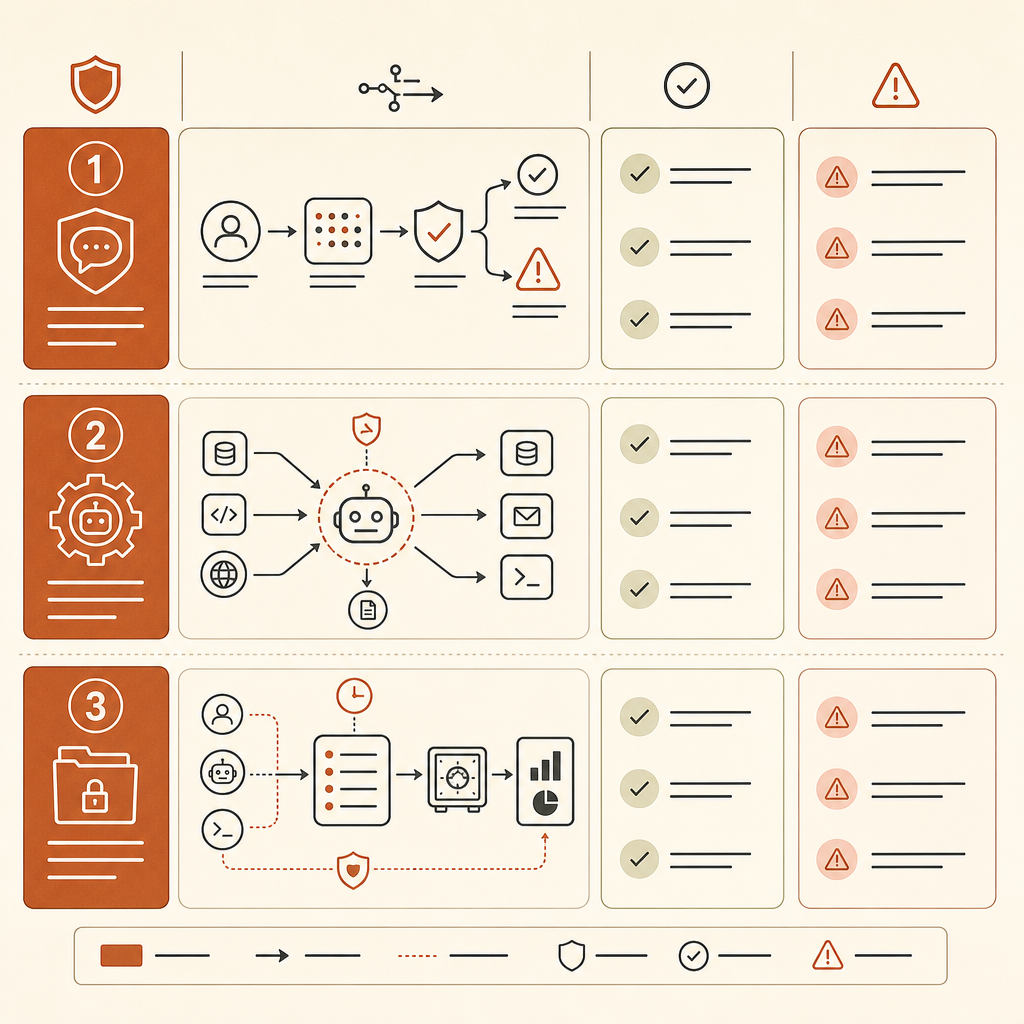
Şirketiniz Claude Code tarzı araçlara, Cursor benzeri agent’lara, dahili kodlama agent’larına veya API üzerinden çalışan LLM otomasyonuna izin veriyorsa, tehdit modelini şimdi güncelleyin. MITRE’nin yeni ID’ler basmasını beklemeyin.
Agent envanteriyle başlayın. Hangi agent’ların repository okuyabildiğini, shell komutları çalıştırabildiğini, dahili sistemlerde gezinebildiğini, scanner çağırabildiğini, ticket açabildiğini veya secret’lara erişebildiğini izleyin. Risk birimi artık “kullanıcı koda chat’e yapıştırdı” değil. “agent’ın araçları, durumu ve bir hedefi var.”
Telemetrinize scaffold tespiti ekleyin. Araç çağrılarını, komut dizilerini, MCP server kullanımını, retry’ları, dosya okumalarını, ağ isteklerini ve izin değişikliklerini log’layın. Tek bir nmap çağrısı lab ortamında normal olabilir. Tarayan, ayrıştıran, kimlik bilgisi seçen, host’lara pivot eden ve bulguları belleğe yazan bir döngü birilerini uyandırmalı.
Savunma iş akışlarını açık uçlu otonomiden ayırın. İyi bir kalıp, sınırları çizilmiş bir iştir: “bu repo’yu SQL injection sink’leri için tara ve aday patch’ler üret”, read-only kimlik bilgileriyle ve ağ çıkışı olmadan. Kötü kalıp ise “staging ortamımızı araştır ve ne bulursan düzelt”, geniş shell erişimi ve kalıcı bellekle.
ATT&CK tekniklerini eşleyin, ama üstüne dahili bir “agentic katman” ekleyin:
| Dahili etiket | Ne kaydedilmeli |
|---|---|
| Otonom zincirleme | Model, insan onayı olmadan birden fazla ATT&CK adımını sıraladı mı? |
| Taktik pivot | Canlı çıktıya göre yeni hedef, kimlik bilgisi, exploit yolu veya araç seçti mi? |
| Araç yetkisi | Agent ne çalıştırabilir, okuyabilir, değiştirebilir veya dışarı çıkarabilir? |
| Bellek kullanımı | Hedef durumunu, kimlik bilgilerini, hipotezleri veya planları kalıcı hale getirdi mi? |
| İnsan kontrol noktaları | Hangi adımlar açık onay gerektirdi ve onaylar anlamlı mıydı? |
AI platform ekipleri için pratik kontrol, araç sınırında politikadır. Yalnızca model retlerine güvenmeyin. Komutlar için allowlist uygulayın. Ağ taraması, credential access, exploit proof-of-concept üretimi ve yıkıcı değişiklikler için onay zorunlu kılın. Secret’ları, agent erişimini varsayılan olarak reddedebilen broker’ların arkasına koyun. Otonom döngülere rate-limit uygulayın. Her çalıştırma için provenance tutun ki bir güvenlik inceleyicisi agent’ın ne gördüğünü ve ne yaptığını tekrar oynatabilsin.
Güvenlik mühendisleri için yeni tespit sorusu basit: “Bu agent’a sahip junior bir saldırgan bir saatliğine senior operatör gibi davranabilir mi?” Cevap evetse, her bir teknik sıradan görünse bile iş akışını yüksek riskli olarak sınıflandırın.
İşe Yarayan Sonuç
Anthropic’in raporunu MITRE ATT&CK’in eskidiğine dair bir şikâyet olarak yanlış okumak kolay. Bu fazla sığ. ATT&CK hâlâ hamleleri adlandırıyor. Eksik kelime dağarcığı orkestra şefi için.
3 Haziran veri seti, AI kötüye kullanımının kill chain’in daha derinlerine; hazırlıktan compromise sonrası faaliyete kaydığını gösteriyor. Fable/Mythos kavgası, bu dünya için savunma göndermenin neden dağınık olduğunu gösteriyor: geliştiriciler güçlü araçlar istiyor, savunmacıların erişime ihtiyacı var, satıcıların izlemeye ihtiyacı var ve hükümetler artık müdahale etmeye istekli.
Doğru tepki panik değil; guardrail’lerin yeterliymiş gibi davranmak da değil. Agent scaffolding’i altyapı olarak ele alın. Tehdit modeline koyun. Log’layın. Araç kullanımı etrafına politika koyun. MITRE onlara resmi teknik ID’leri vermeden önce bile “otonom orkestrasyon” ve “gerçek zamanlı taktik pivot” ifadelerini dahili tespit dilinize bugün ekleyin.
Küçük not: Claude Fable 5’i erişim açık olduğunda kendisi denemek isteyen okurlar, onu OneHop’ta Claude Fable 5 üzerinden kullanabilir; bu, liste fiyatının yaklaşık %30 altında drop-in endpoint sağlar. Yeni hesaplar kart gerekmeden 10 dolar ücretsiz başla ile 10 dolar ücretsiz alır.
Ek okuma: Claude Fable 5 ile başlangıç.

