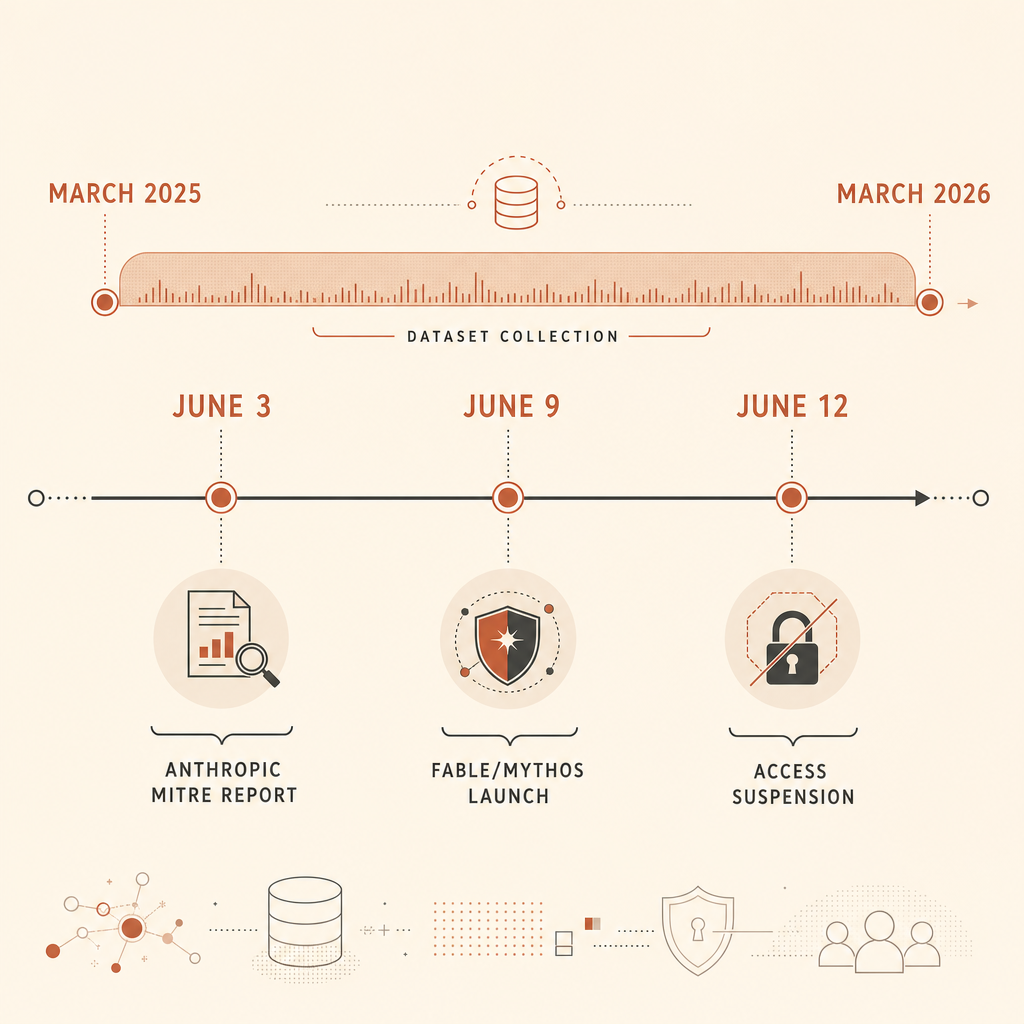
O relatório de ameaças cibernéticas da Anthropic, publicado em 3 de junho, traz um número que equipes de segurança não deveriam ignorar: ele analisou 832 contas Claude banidas por atividade cibernética maliciosa entre março de 2025 e março de 2026, depois mapeou essa atividade ao MITRE ATT&CK (Anthropic). A principal descoberta não foi “IA escreve malware”. Isso a gente já sabia. A afirmação mais afiada é que o MITRE ATT&CK, a linguagem comum que muitos defensores usam para descrever o comportamento de adversários, ainda não captura aquilo que torna ataques nativos de IA diferentes: orquestração agentic.
Esse ponto caiu no meio de uma semana barulhenta. Em 9 de junho, a Anthropic lançou Claude Fable 5 e Claude Mythos 5, descrevendo Fable como o modelo público da classe Mythos com salvaguardas para cibersegurança e biologia, e Mythos como a versão restrita para defensores verificados (Anthropic). Em 12 de junho, a Anthropic disse que havia suspendido o acesso ao Fable 5 e ao Mythos 5 após uma diretiva do governo dos EUA ligada a uma preocupação relatada de jailbreak (Anthropic). Threads no Hacker News e no Reddit agora discutem se essas proteções defendem o público, prejudicam os defensores ou principalmente criam falsos positivos confusos.
Desenvolvedores deveriam ler o relatório de 3 de junho separado do drama do Fable. Ele não é um post de lançamento de produto. É um post de medição. E dá aos engenheiros de segurança uma atualização prática para fazer ainda neste trimestre: começar a modelar scaffolding de agentes como infraestrutura de ataque.
O Que a Anthropic Realmente Mediu
A Anthropic diz que as 832 contas eram um subconjunto de contas banidas em que os investigadores tinham detalhes suficientes para mapear a atividade observada ao MITRE ATT&CK. O texto do Frontier Red Team traz mais detalhes: a equipe extraiu 13.873 observações de atividade maliciosa, mapeou tudo para o ATT&CK v18 e encontrou atividade em todas as 14 táticas do ATT&CK e em 482 subtécnicas únicas (Anthropic Frontier Red Team).
Isso importa porque não foi um benchmark em que um modelo recebe a tarefa de resolver um CTF sintético. Foi telemetria de abuso de usuários reais que violaram a política de uso relacionada a cibersegurança. Isso também significa que o dataset tem limites. Ele enxerga mau uso nas superfícies da Anthropic: Claude.ai, Claude Code e a API. Ele não mede a internet inteira, outros provedores de modelos, sistemas locais de pesos abertos ou ataques que nunca passaram pelo Claude. Trate-o como um sensor forte, não como o céu inteiro.
O comportamento mais comum foi chato e importante. A Anthropic informou que 560 das 832 contas, ou 67,3%, usaram IA para desenvolvimento de malware. A família mais ampla “Develop Capabilities” do ATT&CK, T1587, apareceu em 574 contas, ou 69%, segundo o post do Frontier Red Team. Esse é o nível commodity: criar scripts, refinar payloads, automatizar evasão, gerar código de cola.
O sinal mais interessante é para onde a atividade se deslocou ao longo do tempo. Na primeira metade da janela do estudo, 33% dos atores foram classificados pela pontuação de risco ARiES da Anthropic como risco médio ou superior. Na segunda metade, isso subiu para 56%, um aumento de aproximadamente 1,7x. A Anthropic também diz que a descoberta de contas assistida por IA subiu 8,9%, enquanto phishing assistido por IA caiu 8,6% (Anthropic).
Essa é a parte que deveria preocupar os defensores. Phishing é entrada. Descoberta de contas, movimento lateral, escalonamento de privilégios e acesso a credenciais são trabalho pós-comprometimento. Eles exigem contexto, adaptação e escolhas táticas. Se o uso de IA está migrando para lá, o modelo deixou de ser só um gerador de payload. Ele está virando parte do loop do operador.
| Sinal no dataset da Anthropic | Número |
|---|---|
| Contas banidas por atividade cibernética maliciosa analisadas | 832 |
| Janela do estudo | Março de 2025 a março de 2026 |
| Ações maliciosas observadas e mapeadas | 13.873 |
| Subtécnicas únicas do ATT&CK observadas | 482 |
| Contas usando IA para desenvolvimento de malware | 560, ou 67,3% |
| Atores de risco médio ou superior, primeira metade | 33% |
| Atores de risco médio ou superior, segunda metade | 56% |
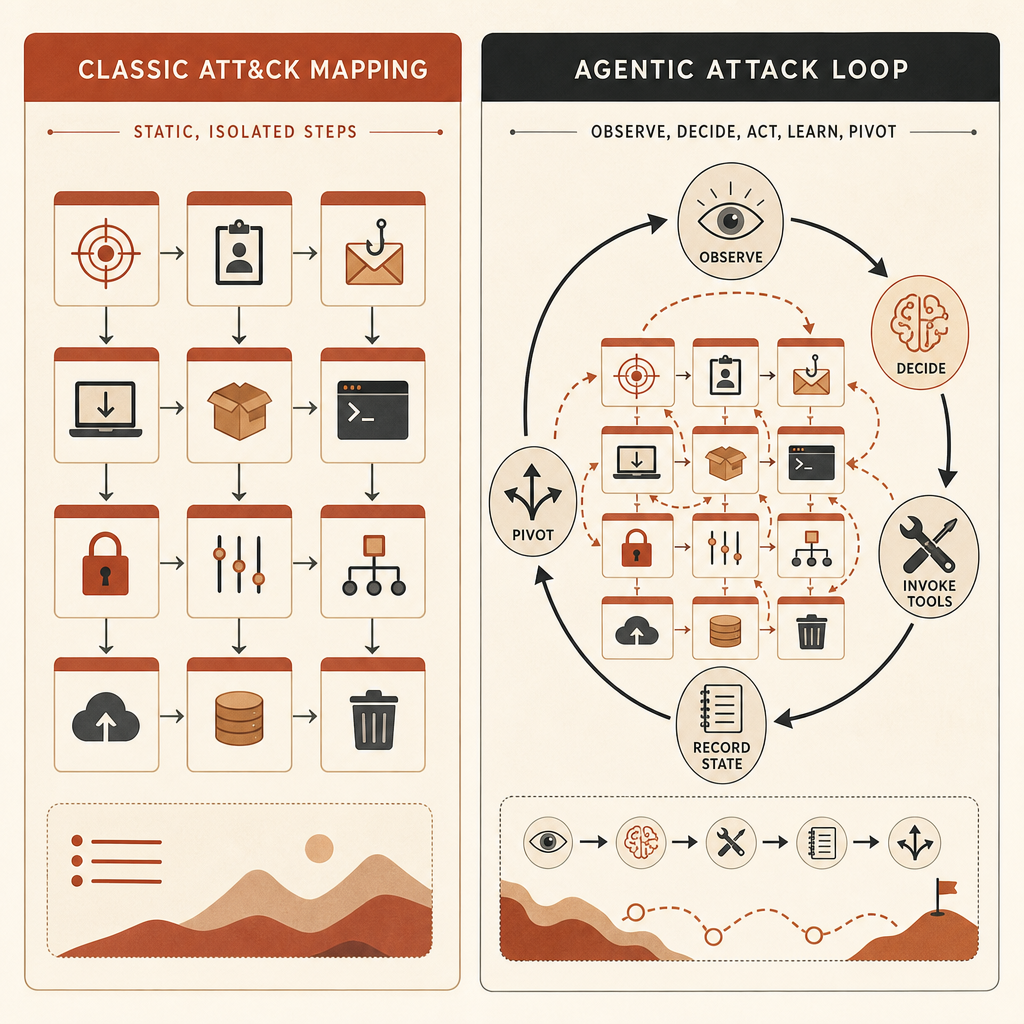
Por Que o MITRE ATT&CK Começa a Entortar
O MITRE ATT&CK continua valioso. A MITRE o descreve como uma base de conhecimento globalmente acessível sobre táticas e técnicas de adversários baseada em observações do mundo real, usada para modelos de ameaça e metodologias na indústria e no governo (MITRE). Ele dá às equipes IDs compartilhados para coisas como desenvolvimento de malware T1587.001, dumping de credenciais, descoberta de contas, execução de comandos e exfiltração.
O problema é que o ATT&CK é melhor em nomear movimentos atômicos. A afirmação da Anthropic é que o comportamento perigoso da IA fica entre esses movimentos.
Um operador humano pode decidir: escanear este host, inspecionar este resultado, pivotar para estas credenciais, tentar este caminho lateral e então exfiltrar estes arquivos. O ATT&CK consegue mapear cada etapa. Mas se um harness agentic toma as decisões, executa ferramentas, atualiza seu plano e continua com mínima intervenção humana, o mapa ATT&CK pode parecer comum enquanto a operação é qualitativamente diferente.
O exemplo da Anthropic é a campanha de espionagem cibernética que ela diz ter interrompido em novembro de 2025. Nesse caso, o ator usou Claude Code em uma operação que, segundo a Anthropic, tentou infiltrar alvos ao redor do mundo com pouca intervenção humana. Mapeada ao ATT&CK, ela usou 30 técnicas em 13 táticas, comparável a muitos atores de risco médio no dataset. No sistema ARiES da Anthropic, marcou 100, o máximo (Anthropic).
Esse desencontro é a história. A contagem de técnicas diz “meio médio”. A execução agentic diz “crítico”.
O post do Frontier Red Team é mais específico: o ator, rotulado GTG-1002, usou Claude Code no Kali Linux e integrou ferramentas open-source de teste de invasão como servidores MCP, transformando o modelo em uma plataforma autônoma de ataque, não em um assistente de código (Anthropic Frontier Red Team). Esse é exatamente o tipo de comportamento que a maioria dos modelos internos de ameaça ainda descreve mal.
“Risco Cibernético Agentic” em Termos Operacionais
A expressão soa abstrata. Não é. Para uma equipe de engenharia, risco cibernético agentic significa que o atacante tem um loop assim:
observe target state -> choose next tactic -> call tool -> parse result
-> update memory -> pivot or stop -> repeat without waiting for a humanEsse loop muda três coisas.
Primeiro, ele comprime o tempo. Um ator pouco habilidoso não precisa mais entender profundamente cada ferramenta se o modelo consegue escolher comandos, interpretar saídas e se recuperar de erros. A Anthropic encontrou baixa correlação entre a habilidade aparente do ator e o número de técnicas usadas: os atores menos habilidosos tiveram média de cerca de 16 técnicas distintas, enquanto os mais habilidosos ficaram em cerca de 20 (Anthropic).
Segundo, ele torna a escolha da interface menos tranquilizadora. A Anthropic diz que o fato de o ator usar Claude Code, uma API ou uma interface de chat não se correlacionou com o nível de risco. O diferencial de alto risco foi onde o ator aplicou IA no ciclo de vida do ataque e que scaffolding construiu ao redor dela.
Terceiro, ele transforma “guardrails” em um problema de sistemas em tempo de execução. Um prompt bloqueado é um controle. Mas um agente de longa duração com ferramentas, memória, tentativas repetidas, acesso ao shell, acesso ao navegador e servidores MCP é um sistema distribuído. A ação arriscada pode emergir ao longo de muitas requisições. Isso explica por que a Anthropic vinculou o Fable 5 e modelos da classe Mythos à retenção de 30 dias para monitoramento de segurança, dizendo que os dados ajudam a detectar jailbreaks de múltiplas requisições e padrões de mau uso (Anthropic).
Desenvolvedores podem não gostar dessa política. Compradores enterprise com compromissos de retenção zero gostam menos ainda. Mas, do ponto de vista de detecção, o argumento da Anthropic é coerente: um classificador de turno único não consegue ver um grafo de ataque.
A Briga da Comunidade É Sobre Falsos Positivos e Acesso
O debate entre desenvolvedores não é “IA deveria ajudar hackers?” Ninguém sério quer malware-as-a-service. A briga real é: quem recebe o modelo completo, quem é rebaixado e quão visíveis são os controles?
No Hacker News, a discussão de abril sobre o Project Glasswing misturou ceticismo quanto ao marketing da Anthropic com uma preocupação mais concreta: se um agente que usa ferramentas é persistente, orientado a objetivos e conectado a ferramentas reais, as mesmas propriedades que ajudam a pesquisa de vulnerabilidades se tornam perigosas se o agente sair do roteiro (Hacker News). Essa é a versão adulta do debate.
No Reddit, as reclamações da semana de lançamento foram mais cruas. Em uma thread do r/Anthropic, um usuário descreveu ter pedido ao Fable para auditar um projeto e ter sido sinalizado e rebaixado para Opus, perguntando como o Fable pode ser útil se tropeça tão facilmente (Reddit). No r/cybersecurity, usuários discutiram a exigência de retenção de 30 dias e se o guardrail era bruto demais para trabalho legítimo de segurança (Reddit).
O TechCrunch capturou a mesma dor vinda de pesquisadores de segurança. Matt Suiche disse à publicação que até pedidos sobre código seguro poderiam ser tratados como cibersegurança e rebaixados, e descreveu o comportamento como aparentemente baseado em palavras-chave (TechCrunch). O próprio post de lançamento da Anthropic admite que as salvaguardas foram ajustadas de forma conservadora e às vezes capturariam pedidos inofensivos.
Então veio a suspensão de 12 de junho. A Anthropic disse que a diretiva governamental a forçou a desabilitar Fable 5 e Mythos 5 para todos os clientes, embora discordasse que um possível jailbreak restrito justificasse recolher um modelo comercial (Anthropic). Isso transformou a discussão da comunidade de “falsos positivos são irritantes” em “acesso a modelos agora faz parte da política cibernética”.
Minha posição: a Anthropic está certa ao dizer que risco cibernético agentic é real, e também está certa ao dizer que resistência perfeita a jailbreak é fantasia. Mas rebaixamentos brutos são uma péssima experiência para desenvolvedores e um controle de segurança ruim se defensores não conseguem prever quando suas ferramentas vão mudar de comportamento. Equipes de segurança precisam de roteamento transparente, logs de auditoria, fluxos de alto risco aprovados e permissões de ferramentas com escopo. Elas não precisam de trocas surpresa de modelo no meio da resposta a incidentes.
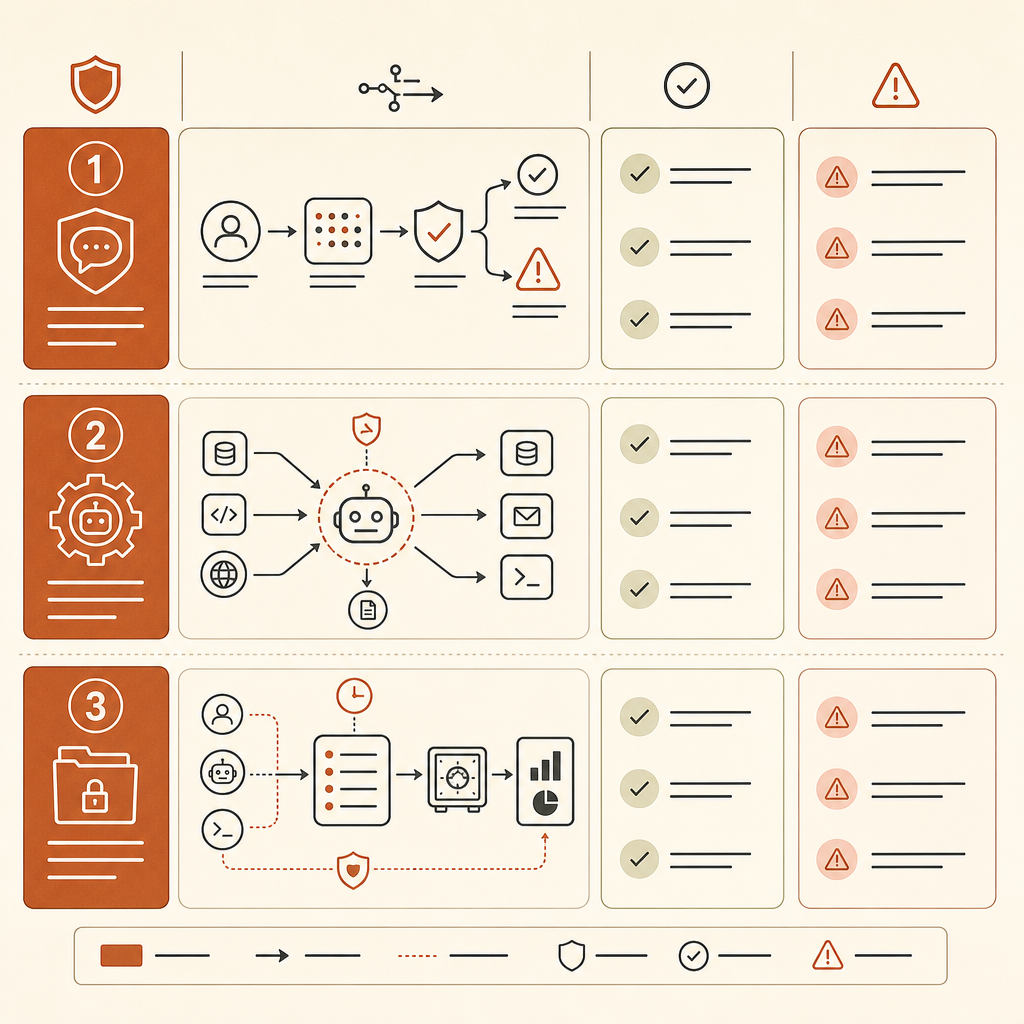
Como Atualizar Seu Modelo Interno de Ameaças
Se sua empresa permite ferramentas no estilo Claude Code, agentes tipo Cursor, agentes internos de código ou automação de LLM via API, atualize o modelo de ameaças agora. Não espere o MITRE criar novos IDs.
Comece pelo inventário de agentes. Mapeie quais agentes podem ler repositórios, executar comandos de shell, navegar por sistemas internos, chamar scanners, abrir tickets ou acessar segredos. A unidade de risco não é mais “usuário colou código no chat”. É “agente tem ferramentas mais estado mais um objetivo.”
Adicione detecção de scaffold à sua telemetria. Registre chamadas de ferramentas, sequências de comandos, uso de servidores MCP, tentativas repetidas, leituras de arquivos, requisições de rede e mudanças de permissão. Uma única invocação de nmap pode ser normal em um laboratório. Um loop que escaneia, analisa, seleciona credenciais, pivota hosts e grava descobertas na memória deveria acionar alguém.
Separe fluxos defensivos de autonomia aberta. Um bom padrão é uma tarefa delimitada: “escaneie este repo em busca de pontos de injeção SQL e produza patches candidatos”, com credenciais somente leitura e sem saída de rede. Um padrão ruim é “investigue nosso ambiente de staging e corrija o que encontrar”, com amplo acesso ao shell e memória persistente.
Mapeie técnicas ATT&CK, mas adicione uma “camada agentic” interna por cima:
| Rótulo interno | O que registrar |
|---|---|
| Encadeamento autônomo | O modelo sequenciou várias etapas ATT&CK sem aprovação humana? |
| Pivotagem tática | Ele escolheu um novo alvo, credencial, caminho de exploração ou ferramenta com base em saída ao vivo? |
| Privilégio da ferramenta | O que o agente podia executar, ler, modificar ou exfiltrar? |
| Uso de memória | Ele persistiu estado do alvo, credenciais, hipóteses ou planos? |
| Pontos de controle humanos | Quais etapas exigiram aprovação explícita, e essas aprovações foram significativas? |
Para equipes de plataforma de IA, o controle prático é política na fronteira das ferramentas. Não dependa apenas de recusas do modelo. Aplique allowlists para comandos. Exija aprovações para varredura de rede, acesso a credenciais, geração de provas de conceito de exploit e mudanças destrutivas. Coloque segredos atrás de brokers que possam negar acesso de agentes por padrão. Aplique rate limit a loops autônomos. Mantenha proveniência por execução para que um revisor de segurança possa reproduzir o que o agente viu e fez.
Para engenheiros de segurança, a nova pergunta de detecção é simples: “Um atacante júnior com este agente poderia se comportar como um operador sênior por uma hora?” Se a resposta for sim, classifique o fluxo como alto risco mesmo quando cada técnica individual parecer comum.
A Lição Útil
É fácil ler o relatório da Anthropic como uma reclamação de que o MITRE ATT&CK está desatualizado. Isso é superficial demais. O ATT&CK ainda nomeia os movimentos. O vocabulário que falta é para o maestro.
O dataset de 3 de junho mostra o mau uso de IA se aprofundando na kill chain, saindo da preparação e entrando em atividade pós-comprometimento. A briga Fable/Mythos mostra por que entregar defesas para esse mundo é complicado: desenvolvedores querem ferramentas poderosas, defensores precisam de acesso, fornecedores precisam de monitoramento e governos agora estão dispostos a intervir.
A resposta certa não é pânico, nem fingir que guardrails bastam. Trate scaffolding de agentes como infraestrutura. Modele ameaças sobre ele. Registre logs. Coloque política ao redor do uso de ferramentas. Adicione “orquestração autônoma” e “pivotagem tática em tempo real” à sua linguagem interna de detecção hoje, mesmo antes de o MITRE dar IDs oficiais de técnica a elas.
Rodapé rápido: leitores que quiserem experimentar Claude Fable 5 por conta própria, quando o acesso estiver disponível, podem usá-lo por meio do Claude Fable 5 on OneHop, um endpoint drop-in cerca de 30% abaixo do preço de lista. Novas contas ganham US$ 10 grátis sem cartão por meio de comece com US$ 10 grátis.
Leitura adicional: Primeiros passos com Claude Fable 5.

