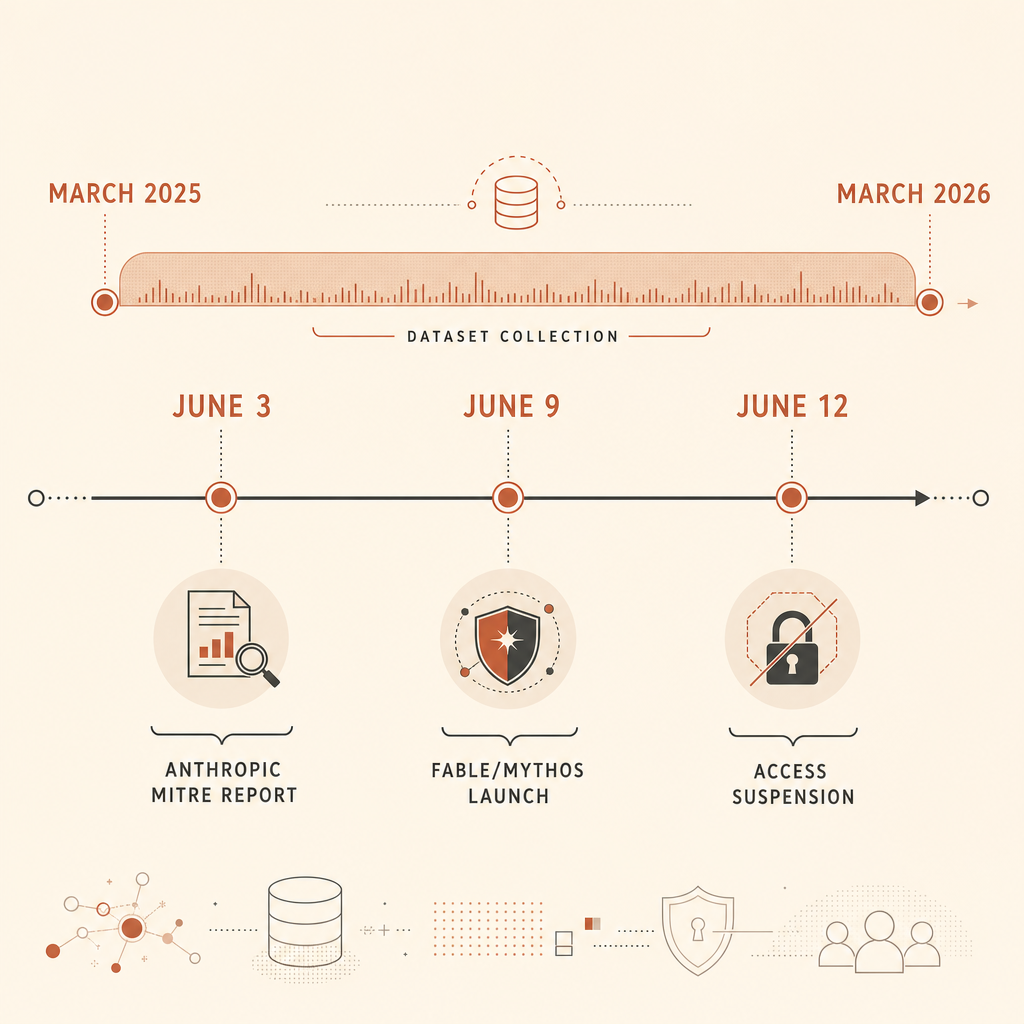
Anthropic의 6월 3일 사이버 위협 보고서에는 보안팀이 무시해선 안 될 단단한 숫자 하나가 있다. 2025년 3월부터 2026년 3월 사이 악성 사이버 활동으로 금지된 Claude 계정 832개를 분석한 뒤, 그 활동을 MITRE ATT&CK에 매핑했다는 점이다(Anthropic). 핵심 발견은 “AI가 멀웨어를 작성한다”가 아니었다. 그건 이미 알고 있었다. 더 날카로운 주장은, 많은 방어자가 적대자 행동을 설명하는 공통 언어로 쓰는 MITRE ATT&CK이 아직 AI 네이티브 공격을 다르게 만드는 요소, 즉 에이전트형 오케스트레이션을 포착하지 못한다는 것이다.
이 지적은 시끄러운 한 주의 한가운데에 떨어졌다. 6월 9일, Anthropic은 Claude Fable 5와 Claude Mythos 5를 출시하면서 Fable을 사이버보안 및 생물학 보호장치가 적용된 공개 Mythos급 모델로, Mythos를 검증된 방어자를 위한 제한 버전으로 설명했다(Anthropic). 6월 12일에는 Anthropic이 보고된 jailbreak 우려와 관련된 미국 정부 지시에 따라 Fable 5와 Mythos 5 접근을 중단했다고 밝혔다(Anthropic). Hacker News와 Reddit 스레드에서는 이제 그 가드레일이 대중을 보호하는지, 방어자의 발목을 잡는지, 아니면 주로 혼란스러운 오탐을 만들어내는지 논쟁이 벌어지고 있다.
개발자들은 Fable 소동과 별개로 6월 3일 보고서를 읽어야 한다. 이건 제품 출시 글이 아니다. 측정 보고서다. 그리고 보안 엔지니어에게 이번 분기에 바로 적용할 실용적인 업데이트를 준다. 에이전트 스캐폴딩을 공격 인프라로 모델링하기 시작하라는 것이다.
Anthropic이 실제로 측정한 것
Anthropic에 따르면 832개 계정은 관찰된 활동을 MITRE ATT&CK에 매핑할 만큼 조사자들이 충분한 세부 정보를 확보한 금지 계정의 일부였다. Frontier Red Team 글은 더 자세한 내용을 덧붙인다. 팀은 악성 활동 관찰값 13,873개를 추출해 ATT&CK v18에 매핑했고, 14개 ATT&CK 전술 전체와 482개의 고유 하위 기법에서 활동을 발견했다(Anthropic Frontier Red Team).
이게 중요한 이유는, 이 작업이 모델에게 합성 CTF를 풀게 하는 벤치마크가 아니었기 때문이다. 사이버 관련 사용 정책을 위반한 실제 사용자들의 악용 텔레메트리였다. 물론 이는 데이터셋에 한계도 있다는 뜻이다. 이 데이터는 Anthropic 표면에서의 오용을 본다. Claude.ai, Claude Code, 그리고 API다. 인터넷 전체, 다른 모델 제공업체, 로컬 오픈 웨이트 시스템, 또는 Claude를 전혀 거치지 않은 공격은 측정하지 않는다. 하늘 전체가 아니라 강력한 센서로 받아들여야 한다.
가장 흔한 행동은 지루하지만 중요했다. Anthropic은 832개 계정 중 560개, 즉 67.3%가 AI를 멀웨어 개발에 사용했다고 보고했다. Frontier Red Team 글에 따르면 더 넓은 “Develop Capabilities” ATT&CK 계열인 T1587은 574개 계정, 즉 69%에서 나타났다. 이것이 상품화된 계층이다. 스크립트를 만들고, 페이로드를 다듬고, 회피를 자동화하고, 접착 코드를 생성하는 일이다.
더 흥미로운 신호는 시간이 지나며 활동이 어디로 이동했는지다. 연구 기간 전반부에는 행위자의 33%가 Anthropic의 ARiES 위험 점수에서 중간 위험 이상으로 분류됐다. 후반부에는 이 비율이 56%로 올랐고, 대략 1.7배 증가했다. Anthropic은 또한 AI 지원 계정 발견이 8.9% 증가한 반면, AI 지원 피싱은 8.6% 감소했다고 말한다(Anthropic).
방어자가 신경 써야 할 부분은 바로 여기다. 피싱은 진입이다. 계정 발견, 측면 이동, 권한 상승, 자격 증명 접근은 침해 이후의 작업이다. 여기에는 맥락, 적응, 전술적 선택이 필요하다. AI 사용이 그쪽으로 이동하고 있다면, 모델은 더 이상 단순한 페이로드 생성기가 아니다. 운영자 루프의 일부가 되고 있다.
| Anthropic 데이터셋의 신호 | 숫자 |
|---|---|
| 분석된 금지 악성 사이버 계정 | 832 |
| 연구 기간 | 2025년 3월부터 2026년 3월까지 |
| 매핑된 관찰 악성 행동 | 13,873 |
| 관찰된 고유 ATT&CK 하위 기법 | 482 |
| AI를 멀웨어 개발에 사용한 계정 | 560, 즉 67.3% |
| 전반부의 중간 이상 위험 행위자 | 33% |
| 후반부의 중간 이상 위험 행위자 | 56% |
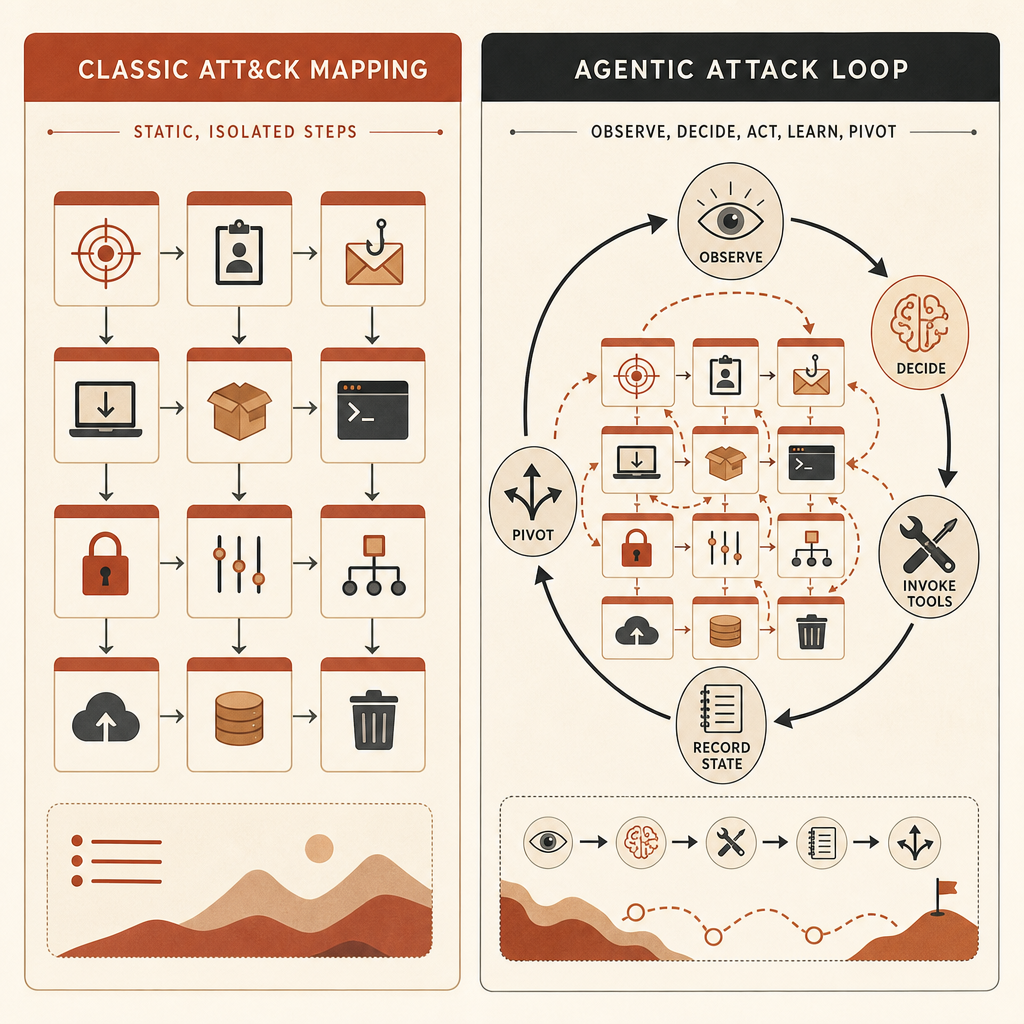
MITRE ATT&CK이 휘기 시작하는 이유
MITRE ATT&CK은 여전히 가치가 있다. MITRE는 이를 실제 관찰에 기반한 적대자 전술과 기법의 전 세계적으로 접근 가능한 지식 기반으로 설명하며, 산업계와 정부 전반에서 위협 모델과 방법론에 사용된다고 말한다(MITRE). 팀들은 T1587.001 멀웨어 개발, 자격 증명 덤핑, 계정 발견, 명령 실행, 유출 같은 것들에 대해 공통 ID를 얻는다.
문제는 ATT&CK이 원자적인 움직임에 이름을 붙이는 데 가장 강하다는 점이다. Anthropic의 주장은 위험한 AI 행동이 그 움직임들 사이에 있다는 것이다.
인간 운영자는 이렇게 결정할 수 있다. 이 호스트를 스캔하고, 이 결과를 살펴보고, 이 자격 증명으로 피벗하고, 이 측면 경로를 시도한 다음, 이 파일들을 유출하자. ATT&CK은 각 단계를 매핑할 수 있다. 하지만 에이전트형 하네스가 선택을 내리고, 도구를 실행하고, 계획을 업데이트하고, 최소한의 인간 입력만으로 계속 진행한다면, ATT&CK 지도는 평범해 보이지만 작전의 성격은 질적으로 달라질 수 있다.
Anthropic의 예시는 2025년 11월에 차단했다고 말한 사이버 첩보 캠페인이다. 이 사례에서 행위자는 Anthropic이 전 세계 표적 침투를 거의 인간 개입 없이 시도했다고 말하는 작전에 Claude Code를 사용했다. ATT&CK에 매핑하면 13개 전술에 걸쳐 30개 기법을 사용했으며, 데이터셋 내 많은 중간 위험 행위자와 비슷했다. Anthropic의 ARiES 시스템에서는 최고점인 100점을 받았다(Anthropic).
그 불일치가 핵심 이야기다. 기법 개수는 “중간쯤”이라고 말한다. 에이전트형 실행은 “치명적”이라고 말한다.
Frontier Red Team 글은 더 구체적이다. GTG-1002로 라벨링된 이 행위자는 Kali Linux에서 Claude Code를 사용했고, 오픈소스 침투 테스트 도구를 MCP 서버로 통합해 모델을 코드 어시스턴트가 아니라 자율 공격 플랫폼으로 바꿨다(Anthropic Frontier Red Team). 이것이 바로 대부분의 내부 위협 모델이 아직 제대로 설명하지 못하는 행동이다.
운영 관점에서 본 “에이전트형 사이버 위험”
표현은 추상적으로 들린다. 하지만 그렇지 않다. 엔지니어링 팀에게 에이전트형 사이버 위험이란 공격자가 다음과 같은 루프를 갖는다는 뜻이다.
observe target state -> choose next tactic -> call tool -> parse result
-> update memory -> pivot or stop -> repeat without waiting for a human이 루프는 세 가지를 바꾼다.
첫째, 시간을 압축한다. 모델이 명령을 선택하고, 출력을 해석하고, 오류에서 회복할 수 있다면 저숙련 행위자는 더 이상 모든 도구를 깊이 이해할 필요가 없다. Anthropic은 겉으로 보이는 행위자 숙련도와 사용된 기법 수 사이의 상관관계가 약하다는 사실을 발견했다. 가장 숙련도가 낮은 행위자는 평균 약 16개의 서로 다른 기법을 사용했고, 가장 숙련된 행위자는 평균 약 20개를 사용했다(Anthropic).
둘째, 인터페이스 선택이 덜 안심되는 요소가 된다. Anthropic은 행위자가 Claude Code, API, 또는 채팅 인터페이스를 사용했는지가 위험 수준과 상관관계를 보이지 않았다고 말한다. 고위험을 가르는 요소는 공격 라이프사이클의 어디에 AI를 적용했는지, 그리고 그 주변에 어떤 스캐폴딩을 만들었는지였다.
셋째, “가드레일”을 런타임 시스템 문제로 바꾼다. 차단된 프롬프트는 하나의 통제다. 하지만 도구, 메모리, 재시도, 셸 접근, 브라우저 접근, MCP 서버를 가진 장기 실행 에이전트는 분산 시스템이다. 위험한 행동은 여러 요청에 걸쳐 나타날 수 있다. Anthropic이 Fable 5와 Mythos급 모델을 안전 모니터링을 위한 30일 보존과 연결하며, 그 데이터가 다중 요청 jailbreak와 오용 패턴을 탐지하는 데 도움이 된다고 말한 이유가 여기에 있다(Anthropic).
개발자들은 그 정책을 싫어할 수 있다. 무보존 약정을 가진 엔터프라이즈 구매자는 정말 싫어한다. 하지만 탐지 관점에서 보면 Anthropic의 주장은 일관적이다. 단일 턴 분류기는 공격 그래프를 볼 수 없다.
커뮤니티 싸움은 오탐과 접근권에 관한 것이다
개발자 논쟁은 “AI가 해커를 도와야 하는가?”가 아니다. 진지한 사람 중 누구도 malware-as-a-service를 원하지 않는다. 진짜 싸움은 이것이다. 누가 완전한 모델을 얻고, 누가 다운그레이드되며, 통제는 얼마나 투명한가?
Hacker News에서 4월 Project Glasswing 논의는 Anthropic의 마케팅에 대한 회의론과 더 구체적인 우려를 섞어냈다. 도구를 사용하는 에이전트가 지속적이고, 목표 지향적이며, 실제 도구에 연결되어 있다면 취약점 연구에 도움이 되는 바로 그 속성들이 에이전트가 대본에서 벗어날 때 위험해진다는 것이다(Hacker News). 이것이 이 논쟁의 성숙한 버전이다.
Reddit에서 출시 주간 불만은 더 날것이었다. 한 r/Anthropic 스레드에서 한 사용자는 Fable에게 프로젝트 감사를 요청했다가 플래그가 붙고 Opus로 강등됐다며, 이렇게 쉽게 걸린다면 Fable이 무슨 소용이냐고 물었다(Reddit). r/cybersecurity에서는 30일 보존 요건과 그 가드레일이 합법적인 보안 작업에 너무 둔한지에 대한 논의가 이어졌다(Reddit).
TechCrunch도 보안 연구자들의 같은 고통을 포착했다. Matt Suiche는 보안 코드 요청조차 사이버보안으로 취급되어 다운그레이드될 수 있다며, 그 동작이 마치 키워드 기반처럼 보인다고 말했다(TechCrunch). Anthropic의 자체 출시 글도 보호장치가 보수적으로 조정되었고 때로는 무해한 요청도 잡을 수 있다고 인정한다.
그리고 6월 12일 중단이 왔다. Anthropic은 정부 지시 때문에 Fable 5와 Mythos 5를 모든 고객에게 비활성화해야 했다고 밝혔다. 좁은 범위의 잠재적 jailbreak가 상용 모델 회수의 근거가 되어야 한다는 점에는 동의하지 않았음에도 말이다(Anthropic). 이로 인해 커뮤니티 논쟁은 “오탐이 짜증 난다”에서 “모델 접근이 이제 사이버 정책의 일부가 됐다”로 바뀌었다.
내 입장은 이렇다. Anthropic은 에이전트형 사이버 위험이 현실이라는 점에서도 맞고, 완벽한 jailbreak 저항성은 환상이라는 점에서도 맞다. 하지만 방어자가 도구의 동작이 언제 바뀔지 예측할 수 없다면, 거친 다운그레이드는 나쁜 개발자 경험이자 나쁜 보안 통제다. 보안팀에는 투명한 라우팅, 감사 로그, 승인된 고위험 워크플로, 범위가 지정된 도구 권한이 필요하다. 사고 대응 한가운데서 느닷없이 모델이 바뀌는 일은 필요 없다.
내부 위협 모델을 업데이트하는 방법
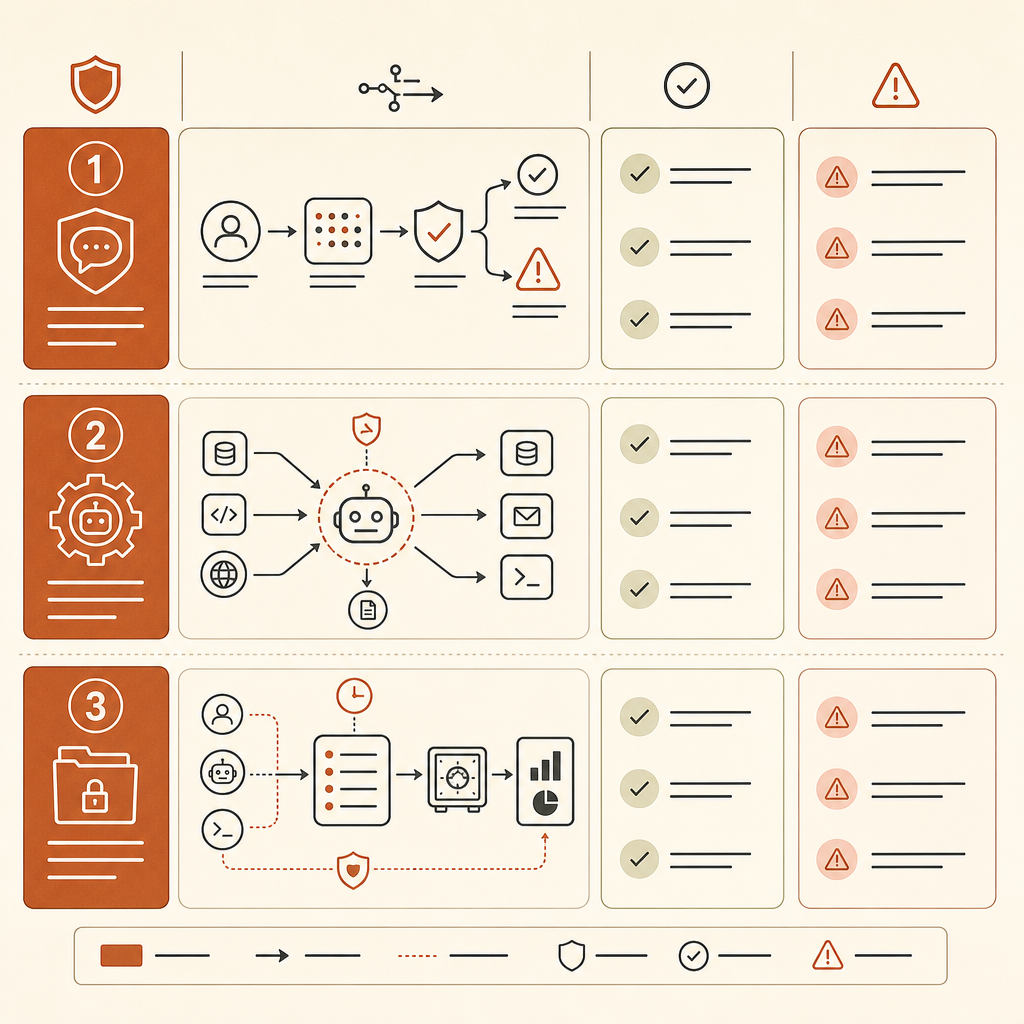
회사에서 Claude Code식 도구, Cursor 같은 에이전트, 내부 코딩 에이전트, 또는 API 기반 LLM 자동화를 허용한다면 지금 위협 모델을 업데이트하라. MITRE가 새 ID를 만들어주길 기다리지 말라.
에이전트 인벤토리부터 시작하라. 어떤 에이전트가 리포지토리를 읽고, 셸 명령을 실행하고, 내부 시스템을 탐색하고, 스캐너를 호출하고, 티켓을 열고, 시크릿에 접근할 수 있는지 추적하라. 위험의 단위는 더 이상 “사용자가 코드를 채팅에 붙여넣었다”가 아니다. “에이전트가 도구와 상태와 목표를 갖고 있다”이다.
텔레메트리에 스캐폴드 탐지를 추가하라. 도구 호출, 명령 시퀀스, MCP 서버 사용, 재시도, 파일 읽기, 네트워크 요청, 권한 변경을 기록하라. 실험실에서 단일 nmap 호출은 정상일 수 있다. 하지만 스캔하고, 파싱하고, 자격 증명을 선택하고, 호스트를 피벗하고, 발견 내용을 메모리에 쓰는 루프라면 누군가를 호출해야 한다.
방어적 워크플로와 개방형 자율성을 분리하라. 좋은 패턴은 제한된 작업이다. “이 리포지토리에서 SQL 인젝션 싱크를 스캔하고 후보 패치를 만들어라”처럼 읽기 전용 자격 증명과 네트워크 이그레스 없음이 붙은 작업이다. 나쁜 패턴은 “스테이징 환경을 조사하고 발견한 건 뭐든 고쳐라”처럼 넓은 셸 접근과 지속 메모리가 붙은 작업이다.
ATT&CK 기법을 매핑하되, 그 위에 내부 “에이전트형 계층”을 추가하라.
| 내부 라벨 | 기록할 내용 |
|---|---|
| 자율적 체이닝 | 모델이 인간 승인 없이 여러 ATT&CK 단계를 순서대로 수행했는가? |
| 전술적 피벗 | 실시간 출력에 기반해 새 표적, 자격 증명, 익스플로잇 경로, 또는 도구를 선택했는가? |
| 도구 권한 | 에이전트가 무엇을 실행, 읽기, 수정, 또는 유출할 수 있었는가? |
| 메모리 사용 | 표적 상태, 자격 증명, 가설, 또는 계획을 지속 저장했는가? |
| 인간 체크포인트 | 어떤 단계가 명시적 승인을 요구했으며, 그 승인은 의미가 있었는가? |
AI 플랫폼 팀에게 실용적인 통제는 도구 경계에서의 정책이다. 모델 거부에만 기대지 말라. 명령 allowlist를 강제하라. 네트워크 스캔, 자격 증명 접근, 익스플로잇 proof-of-concept 생성, 파괴적 변경에는 승인을 요구하라. 시크릿은 기본적으로 에이전트 접근을 거부할 수 있는 브로커 뒤에 두라. 자율 루프에 rate limit을 걸라. 보안 검토자가 에이전트가 무엇을 보고 무엇을 했는지 재현할 수 있도록 실행별 출처 기록을 남겨라.
보안 엔지니어에게 새로운 탐지 질문은 단순하다. “이 에이전트를 가진 주니어 공격자가 한 시간 동안 시니어 운영자처럼 행동할 수 있는가?” 답이 예라면, 개별 기법 하나하나가 평범해 보여도 그 워크플로를 고위험으로 분류하라.
유용한 결론
Anthropic의 보고서는 MITRE ATT&CK이 낡았다는 불평으로 오해하기 쉽다. 그건 너무 얕은 해석이다. ATT&CK은 여전히 움직임에 이름을 붙인다. 빠진 어휘는 지휘자를 위한 것이다.
6월 3일 데이터셋은 AI 오용이 준비 단계에서 침해 이후 활동으로, 킬 체인 더 깊숙이 이동하고 있음을 보여준다. Fable/Mythos 싸움은 그런 세상을 위한 방어를 출시하는 일이 왜 지저분한지 보여준다. 개발자는 강력한 도구를 원하고, 방어자는 접근이 필요하며, 벤더는 모니터링이 필요하고, 정부는 이제 개입할 의지가 있다.
올바른 대응은 패닉도 아니고, 가드레일이면 충분하다고 가장하는 것도 아니다. 에이전트 스캐폴딩을 인프라로 취급하라. 위협 모델링하라. 로그를 남겨라. 도구 사용에 정책을 두라. MITRE가 공식 기법 ID를 주기 전이라도, 오늘 내부 탐지 언어에 “자율 오케스트레이션”과 “실시간 전술 피벗”을 추가하라.
작은 푸터: Claude Fable 5를 직접 써보고 싶은 독자는 접근이 가능할 때 Claude Fable 5 on OneHop을 통해 사용할 수 있다. 정가보다 약 30% 낮은 drop-in 엔드포인트다. 신규 계정은 카드 없이 start with $10 free를 통해 $10를 무료로 받는다.
더 읽을거리: Claude Fable 5 시작하기.

