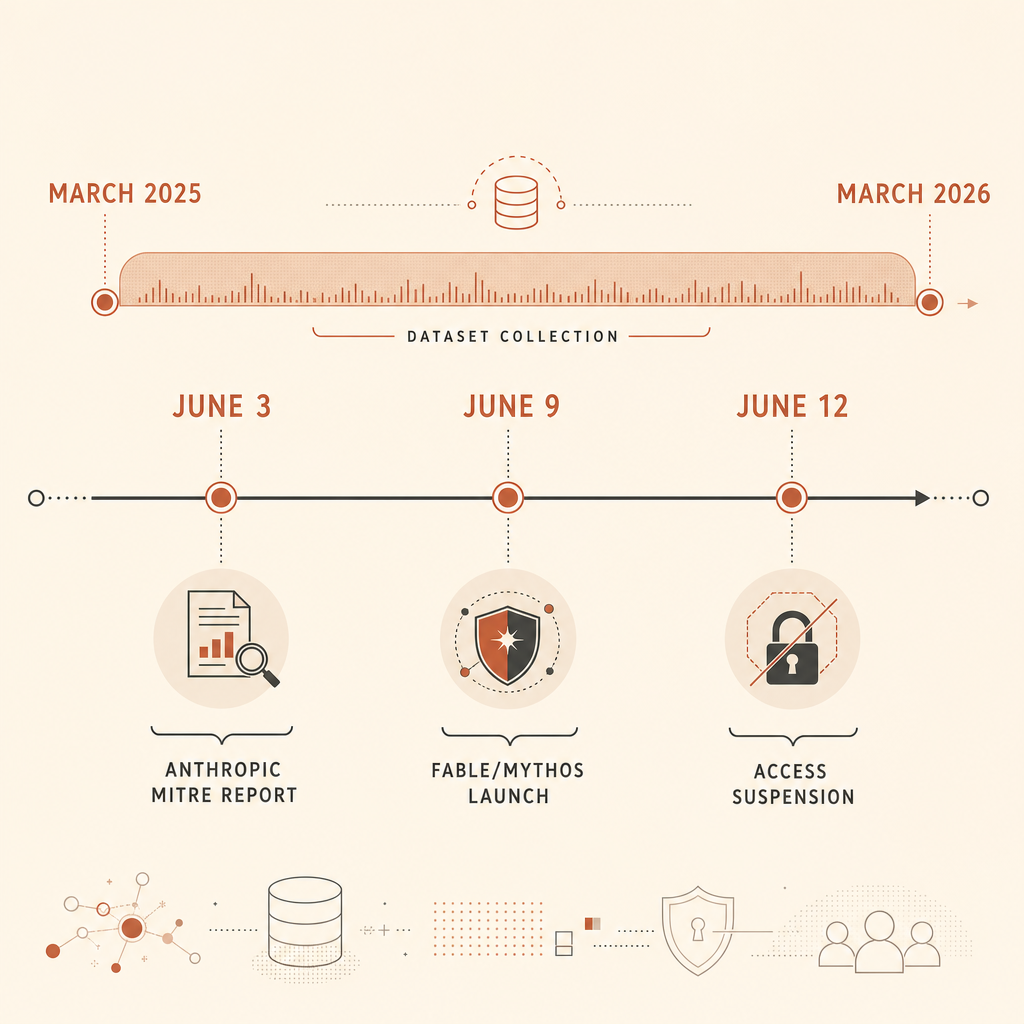
Anthropics Cyberbedrohungsbericht vom 3. Juni enthält eine harte Zahl, die Security-Teams nicht ignorieren sollten: Analysiert wurden 832 Claude-Accounts, die zwischen März 2025 und März 2026 wegen bösartiger Cyberaktivitäten gesperrt wurden; anschließend wurde die Aktivität auf MITRE ATT&CK abgebildet (Anthropic). Die wichtigste Erkenntnis war nicht: „KI schreibt Malware.“ Das wussten wir schon. Die schärfere Aussage lautet: MITRE ATT&CK, die gemeinsame Sprache, mit der viele Verteidiger Angreiferverhalten beschreiben, erfasst noch nicht das, was KI-native Angriffe anders macht: agentische Orchestrierung.
Dieser Punkt platzte mitten in eine laute Woche. Am 9. Juni stellte Anthropic Claude Fable 5 und Claude Mythos 5 vor und beschrieb Fable als öffentliches Mythos-Klassenmodell mit Schutzmaßnahmen für Cybersicherheit und Biologie, Mythos dagegen als eingeschränkte Version für geprüfte Verteidiger (Anthropic). Am 12. Juni erklärte Anthropic, den Zugriff auf Fable 5 und Mythos 5 nach einer Anweisung der US-Regierung ausgesetzt zu haben, die mit einer gemeldeten Jailbreak-Sorge zusammenhing (Anthropic). In Hacker-News- und Reddit-Threads wird nun gestritten, ob diese Leitplanken die Öffentlichkeit schützen, Verteidiger ausbremsen oder vor allem verwirrende False Positives erzeugen.
Entwickler sollten den Bericht vom 3. Juni getrennt vom Fable-Drama lesen. Er ist kein Produktlaunch-Post. Er ist ein Messbericht. Und er gibt Security Engineers ein praktisches Update für dieses Quartal: Modelliert Agent-Gerüste ab jetzt als Angriffs-Infrastruktur.
Was Anthropic tatsächlich gemessen hat
Anthropic sagt, die 832 Accounts seien eine Teilmenge gesperrter Accounts gewesen, bei denen die Ermittler genug Details hatten, um beobachtete Aktivitäten auf MITRE ATT&CK abzubilden. Der Bericht des Frontier Red Team ergänzt weitere Details: Das Team extrahierte 13.873 Beobachtungen bösartiger Aktivitäten, ordnete sie ATT&CK v18 zu und fand Aktivitäten über alle 14 ATT&CK-Taktiken und 482 einzigartige Subtechniken hinweg (Anthropic Frontier Red Team).
Das ist wichtig, weil es kein Benchmark war, bei dem ein Modell ein synthetisches CTF lösen soll. Es war Missbrauchstelemetrie echter Nutzer, die gegen cyberbezogene Nutzungsrichtlinien verstoßen hatten. Das heißt aber auch: Der Datensatz hat Grenzen. Er sieht Missbrauch auf Anthropic-Oberflächen: Claude.ai, Claude Code und der API. Er misst nicht das gesamte Internet, andere Modellanbieter, lokale Open-Weight-Systeme oder Angriffe, die Claude nie berührt haben. Behandelt ihn wie einen starken Sensor, nicht wie den ganzen Himmel.
Das häufigste Verhalten war langweilig und wichtig. Anthropic berichtete, dass 560 der 832 Accounts, also 67,3 %, KI für Malware-Entwicklung nutzten. Die breitere ATT&CK-Familie „Develop Capabilities“, T1587, tauchte laut Frontier-Red-Team-Post in 574 Accounts auf, also in 69 %. Das ist die Commodity-Schicht: Skripte bauen, Payloads verfeinern, Evasion automatisieren, Glue Code erzeugen.
Das interessantere Signal ist, wohin sich die Aktivität im Laufe der Zeit verlagerte. In der ersten Hälfte des Untersuchungszeitraums wurden 33 % der Akteure durch Anthropics ARiES-Risikobewertung als mittleres Risiko oder höher eingestuft. In der zweiten Hälfte stieg dieser Wert auf 56 %, ein Anstieg um etwa das 1,7-Fache. Anthropic sagt außerdem, KI-gestützte Account Discovery sei um 8,9 % gestiegen, während KI-gestütztes Phishing um 8,6 % gefallen sei (Anthropic).
Das ist der Teil, der Verteidiger interessieren sollte. Phishing ist Einstieg. Account Discovery, laterale Bewegung, Rechteausweitung und Zugriff auf Zugangsdaten sind Arbeit nach der Kompromittierung. Sie erfordern Kontext, Anpassung und taktische Entscheidungen. Wenn KI-Nutzung dorthin driftet, ist das Modell nicht mehr nur ein Payload-Generator. Es wird Teil der Operator-Schleife.
| Signal aus Anthropics Datensatz | Zahl |
|---|---|
| Analysierte gesperrte bösartige Cyber-Accounts | 832 |
| Untersuchungszeitraum | März 2025 bis März 2026 |
| Abgebildete beobachtete bösartige Aktionen | 13.873 |
| Beobachtete einzigartige ATT&CK-Subtechniken | 482 |
| Accounts, die KI für Malware-Entwicklung nutzten | 560, oder 67,3 % |
| Akteure mit mittlerem oder höherem Risiko, erste Hälfte | 33 % |
| Akteure mit mittlerem oder höherem Risiko, zweite Hälfte | 56 % |
Warum MITRE ATT&CK an seine Grenzen gerät
MITRE ATT&CK bleibt wertvoll. MITRE beschreibt es als weltweit zugängliche Wissensbasis zu gegnerischen Taktiken und Techniken auf Grundlage realer Beobachtungen, genutzt für Bedrohungsmodelle und Methodologien in Industrie und Regierung (MITRE). Es gibt Teams gemeinsame IDs für Dinge wie T1587.001 Malware-Entwicklung, Credential Dumping, Account Discovery, Befehlsausführung und Exfiltration.
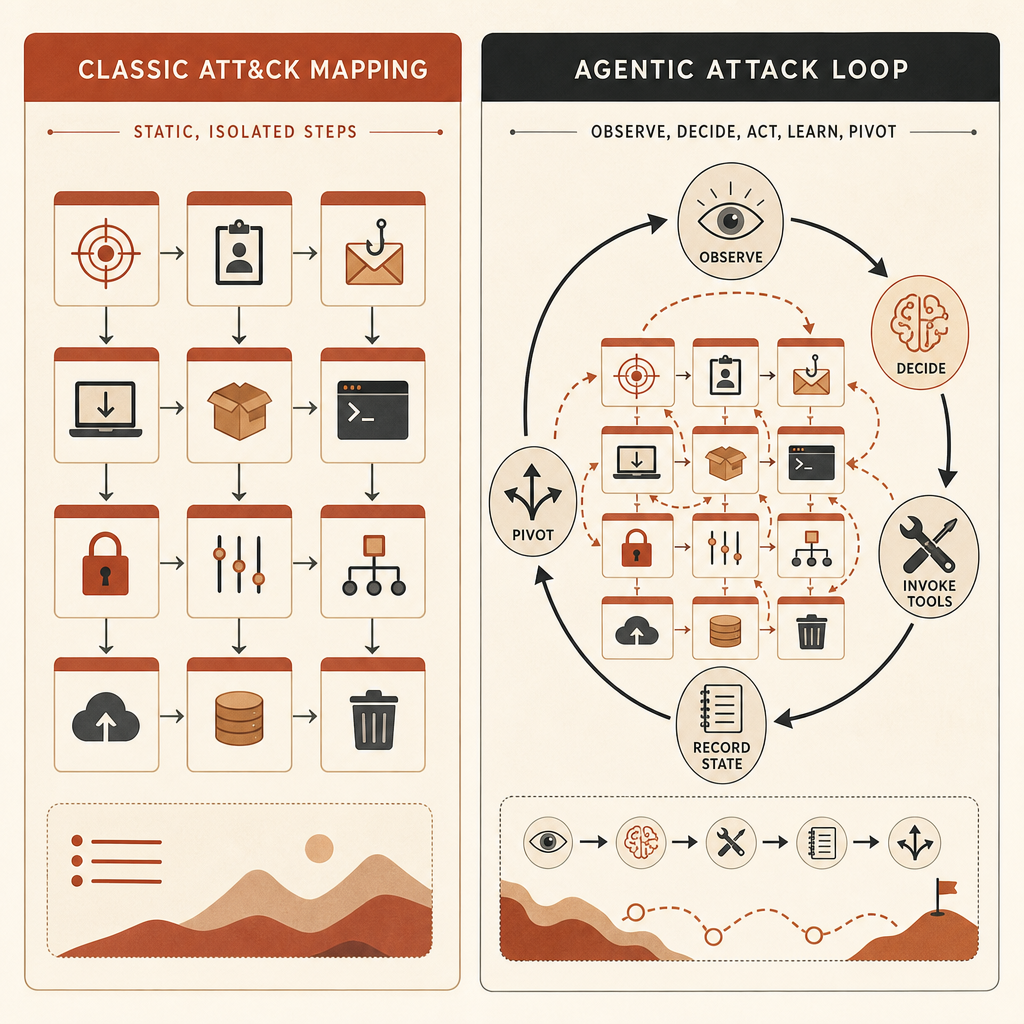
Das Problem ist: ATT&CK ist am besten darin, die atomaren Schritte zu benennen. Anthropics Aussage ist, dass das gefährliche KI-Verhalten zwischen diesen Schritten liegt.
Ein menschlicher Operator könnte entscheiden: Scanne diesen Host, prüfe dieses Ergebnis, wechsle zu diesen Zugangsdaten, versuche diesen lateralen Pfad und exfiltriere dann diese Dateien. ATT&CK kann jeden Schritt abbilden. Wenn aber ein agentisches Harness die Entscheidungen trifft, Tools ausführt, seinen Plan aktualisiert und mit minimalem menschlichem Input weitermacht, kann die ATT&CK-Karte gewöhnlich aussehen, obwohl die Operation qualitativ eine andere ist.
Anthropics Beispiel ist die Cyberespionage-Kampagne, die das Unternehmen nach eigenen Angaben im November 2025 unterbrochen hat. In diesem Fall nutzte der Akteur Claude Code in einer Operation, die laut Anthropic versuchte, mit wenig menschlicher Intervention Ziele auf der ganzen Welt zu infiltrieren. Auf ATT&CK abgebildet nutzte sie 30 Techniken über 13 Taktiken hinweg, vergleichbar mit vielen Akteuren mittleren Risikos im Datensatz. Nach Anthropics ARiES-System erhielt sie 100 Punkte, den Höchstwert (Anthropic).
Diese Diskrepanz ist die eigentliche Geschichte. Die Zahl der Techniken sagt: „eher mittel“. Agentische Ausführung sagt: „kritisch“.
Der Frontier-Red-Team-Post wird konkreter: Der Akteur, als GTG-1002 bezeichnet, nutzte Claude Code auf Kali Linux und integrierte Open-Source-Penetration-Testing-Tools als MCP-Server. Damit wurde das Modell zu einer autonomen Angriffsplattform statt zu einem Code-Assistenten (Anthropic Frontier Red Team). Genau dieses Verhalten beschreiben die meisten internen Bedrohungsmodelle noch viel zu schwach.
„Agentisches Cyberrisiko“ in operativen Begriffen
Der Ausdruck klingt abstrakt. Ist er nicht. Für ein Engineering-Team bedeutet agentisches Cyberrisiko, dass der Angreifer eine Schleife wie diese hat:
observe target state -> choose next tactic -> call tool -> parse result
-> update memory -> pivot or stop -> repeat without waiting for a humanDiese Schleife verändert drei Dinge.
Erstens komprimiert sie Zeit. Ein Akteur mit wenig Können muss nicht mehr jedes Tool tief verstehen, wenn das Modell Befehle auswählen, Ausgaben interpretieren und sich von Fehlern erholen kann. Anthropic fand nur eine schwache Korrelation zwischen sichtbarem Können des Akteurs und der Zahl genutzter Techniken: Die am wenigsten versierten Akteure nutzten im Schnitt etwa 16 unterschiedliche Techniken, die versiertesten etwa 20 (Anthropic).
Zweitens macht sie die Wahl der Oberfläche weniger beruhigend. Anthropic sagt, ob der Akteur Claude Code, eine API oder eine Chat-Oberfläche nutzte, korrelierte nicht mit dem Risikoniveau. Der Hochrisiko-Unterschied lag darin, wo der Akteur KI im Angriffslebenszyklus einsetzte und welches Gerüst er darum baute.
Drittens macht sie „Leitplanken“ zu einem Laufzeitsystem-Problem. Ein blockierter Prompt ist eine Kontrolle. Aber ein lang laufender Agent mit Tools, Speicher, Wiederholungen, Shell-Zugriff, Browser-Zugriff und MCP-Servern ist ein verteiltes System. Die riskante Aktion kann über viele Requests hinweg entstehen. Das erklärt, warum Anthropic Fable 5 und Mythos-Klassenmodelle mit 30-tägiger Aufbewahrung für Sicherheitsmonitoring verknüpfte und sagte, die Daten helfen dabei, Multi-Request-Jailbreaks und Missbrauchsmuster zu erkennen (Anthropic).
Entwickler mögen diese Richtlinie ablehnen. Unternehmenskunden mit Zero-Retention-Zusagen mögen sie erst recht nicht. Aber aus Erkennungssicht ist Anthropics Argument schlüssig: Ein Single-Turn-Klassifikator sieht keinen Angriffsgraphen.
Der Community-Streit dreht sich um False Positives und Zugang
Die Entwicklerdebatte lautet nicht: „Soll KI Hackern helfen?“ Niemand, der ernst zu nehmen ist, will Malware-as-a-Service. Der eigentliche Streit lautet: Wer bekommt das volle Modell, wer wird herabgestuft, und wie sichtbar sind die Kontrollen?
Auf Hacker News mischte die Diskussion zu Project Glasswing im April Skepsis gegenüber Anthropics Marketing mit einer konkreteren Sorge: Wenn ein Tool-nutzender Agent persistent, zielgerichtet und mit echten Tools verbunden ist, werden genau die Eigenschaften, die bei der Schwachstellenforschung helfen, gefährlich, sobald der Agent vom Skript abweicht (Hacker News). Das ist die erwachsene Version der Debatte.
Auf Reddit waren die Beschwerden in der Launch-Woche direkter. In einem r/Anthropic-Thread beschrieb ein Nutzer, Fable gebeten zu haben, ein Projekt zu auditieren, und dabei markiert und auf Opus herabgestuft worden zu sein; er fragte, wie Fable nützlich sein solle, wenn es so leicht auslöst (Reddit). In r/cybersecurity diskutierten Nutzer die 30-tägige Aufbewahrungspflicht und ob die Leitplanke für legitime Security-Arbeit zu grob sei (Reddit).
TechCrunch fing denselben Schmerz von Sicherheitsforschern ein. Matt Suiche sagte dem Magazin, selbst Secure-Code-Anfragen könnten als Cybersicherheit behandelt und herabgestuft werden, und beschrieb das Verhalten als scheinbar keyword-basiert (TechCrunch). Anthropics eigener Launch-Post räumt ein, dass die Schutzmaßnahmen konservativ abgestimmt wurden und manchmal harmlose Anfragen erwischen würden.
Dann kam die Aussetzung am 12. Juni. Anthropic erklärte, die Regierungsanweisung habe das Unternehmen gezwungen, Fable 5 und Mythos 5 für alle Kunden zu deaktivieren, obwohl es nicht einverstanden sei, dass ein eng begrenzter möglicher Jailbreak den Rückruf eines kommerziellen Modells rechtfertigen sollte (Anthropic). Damit wurde aus dem Community-Streit über „False Positives nerven“ die Frage: „Modellzugang ist jetzt Teil der Cyberpolitik.“
Meine Position: Anthropic hat recht, dass agentisches Cyberrisiko real ist, und hat auch recht, dass perfekte Jailbreak-Resistenz Fantasie ist. Aber grobe Herabstufungen sind eine schlechte Developer Experience und eine schlechte Sicherheitskontrolle, wenn Verteidiger nicht vorhersagen können, wann ihre Tools ihr Verhalten ändern. Security-Teams brauchen transparentes Routing, Audit-Logs, freigegebene Hochrisiko-Workflows und eng begrenzte Tool-Berechtigungen. Was sie nicht brauchen, sind überraschende Modellwechsel mitten in der Incident Response.
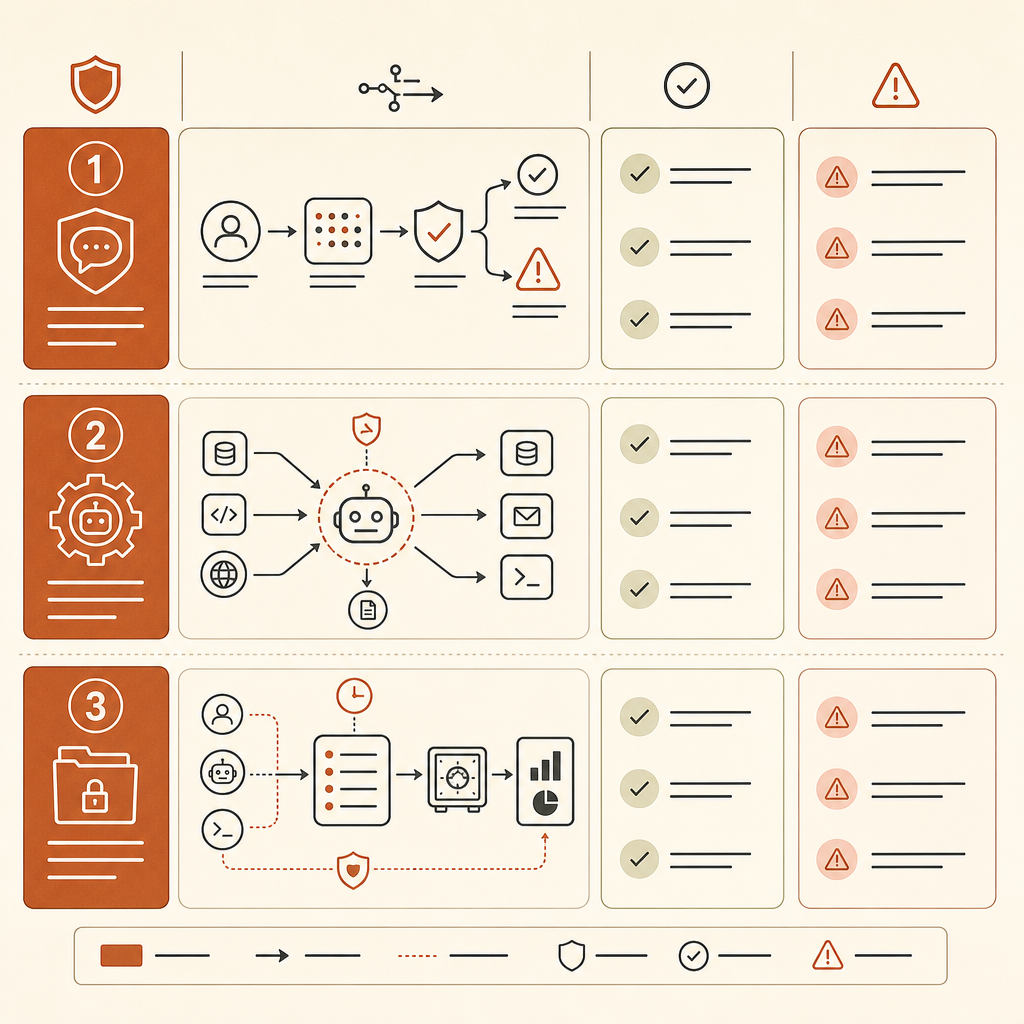
So aktualisiert ihr euer internes Bedrohungsmodell
Wenn euer Unternehmen Tools im Stil von Claude Code, Cursor-ähnliche Agenten, interne Coding-Agenten oder API-getriebene LLM-Automatisierung erlaubt, aktualisiert jetzt das Bedrohungsmodell. Wartet nicht darauf, dass MITRE neue IDs prägt.
Beginnt mit einem Agent-Inventar. Erfasst, welche Agenten Repositories lesen, Shell-Befehle ausführen, interne Systeme durchsuchen, Scanner aufrufen, Tickets öffnen oder auf Secrets zugreifen können. Die Risikoeinheit ist nicht mehr: „Nutzer hat Code in den Chat kopiert.“ Sie lautet: „Agent hat Tools plus Zustand plus Ziel.“
Fügt eurer Telemetrie Gerüst-Erkennung hinzu. Loggt Tool-Aufrufe, Befehlssequenzen, MCP-Server-Nutzung, Wiederholungen, Dateizugriffe, Netzwerk-Requests und Berechtigungsänderungen. Ein einzelner nmap-Aufruf kann in einem Lab normal sein. Eine Schleife, die scannt, parst, Zugangsdaten auswählt, Hosts pivotiert und Ergebnisse ins Gedächtnis schreibt, sollte jemanden alarmieren.
Trennt defensive Workflows von offener Autonomie. Ein gutes Muster ist ein begrenzter Job: „Scanne dieses Repo nach SQL-Injection-Sinks und erstelle Patch-Kandidaten“, mit Read-only-Zugangsdaten und ohne Netzwerk-Egress. Ein schlechtes Muster ist: „Untersuche unsere Staging-Umgebung und behebe alles, was du findest“, mit breitem Shell-Zugriff und persistentem Speicher.
Bildet ATT&CK-Techniken ab, legt aber eine interne „agentische Schicht“ darüber:
| Internes Label | Was erfasst werden sollte |
|---|---|
| Autonomes Verketten | Hat das Modell mehrere ATT&CK-Schritte ohne menschliche Freigabe sequenziert? |
| Taktisches Pivoting | Hat es auf Basis von Live-Ausgaben ein neues Ziel, Zugangsdaten, einen Exploit-Pfad oder ein Tool gewählt? |
| Tool-Privilegien | Was konnte der Agent ausführen, lesen, verändern oder exfiltrieren? |
| Speichernutzung | Hat er Zielzustand, Zugangsdaten, Hypothesen oder Pläne persistiert? |
| Menschliche Checkpoints | Welche Schritte erforderten explizite Freigabe, und waren diese Freigaben sinnvoll? |
Für KI-Plattformteams liegt die praktische Kontrolle an der Tool-Grenze. Verlasst euch nicht nur auf Modellverweigerungen. Erzwingt Allow-Lists für Befehle. Verlangt Freigaben für Netzwerkscans, Zugriff auf Zugangsdaten, Proof-of-Concept-Generierung für Exploits und destruktive Änderungen. Legt Secrets hinter Broker, die Agent-Zugriff standardmäßig verweigern können. Rate-limitiert autonome Schleifen. Haltet pro Lauf Provenance fest, damit ein Security Reviewer nachvollziehen kann, was der Agent gesehen und getan hat.
Für Security Engineers lautet die neue Erkennungsfrage simpel: „Könnte ein Junior-Angreifer mit diesem Agenten eine Stunde lang wie ein Senior-Operator handeln?“ Wenn die Antwort ja ist, stuft den Workflow als Hochrisiko ein, selbst wenn jede einzelne Technik gewöhnlich aussieht.
Die nützliche Schlussfolgerung
Anthropics Bericht lässt sich leicht als Beschwerde lesen, dass MITRE ATT&CK veraltet sei. Das greift zu kurz. ATT&CK benennt weiterhin die Züge. Das fehlende Vokabular beschreibt den Dirigenten.
Der Datensatz vom 3. Juni zeigt, dass KI-Missbrauch tiefer in die Kill Chain wandert, von der Vorbereitung in Aktivitäten nach der Kompromittierung. Der Fable/Mythos-Streit zeigt, warum Verteidigungsmaßnahmen für diese Welt so chaotisch sind: Entwickler wollen mächtige Tools, Verteidiger brauchen Zugang, Anbieter brauchen Monitoring, und Regierungen sind inzwischen bereit einzugreifen.
Die richtige Reaktion ist keine Panik, und sie besteht auch nicht darin, so zu tun, als reichten Leitplanken aus. Behandelt Agent-Gerüste als Infrastruktur. Modelliert sie als Bedrohung. Loggt sie. Legt Richtlinien um Tool-Nutzung. Fügt „autonome Orchestrierung“ und „taktisches Pivoting in Echtzeit“ noch heute eurer internen Erkennungssprache hinzu, selbst bevor MITRE ihnen offizielle Technik-IDs gibt.
Kleine Fußnote: Leser, die Claude Fable 5 selbst ausprobieren möchten, sobald der Zugang verfügbar ist, können es über Claude Fable 5 auf OneHop nutzen, einen Drop-in-Endpunkt für etwa 30 % unter Listenpreis. Neue Accounts erhalten 10 $ gratis ohne Karte über mit 10 $ gratis starten.
Weiterlesen: Erste Schritte mit Claude Fable 5.

