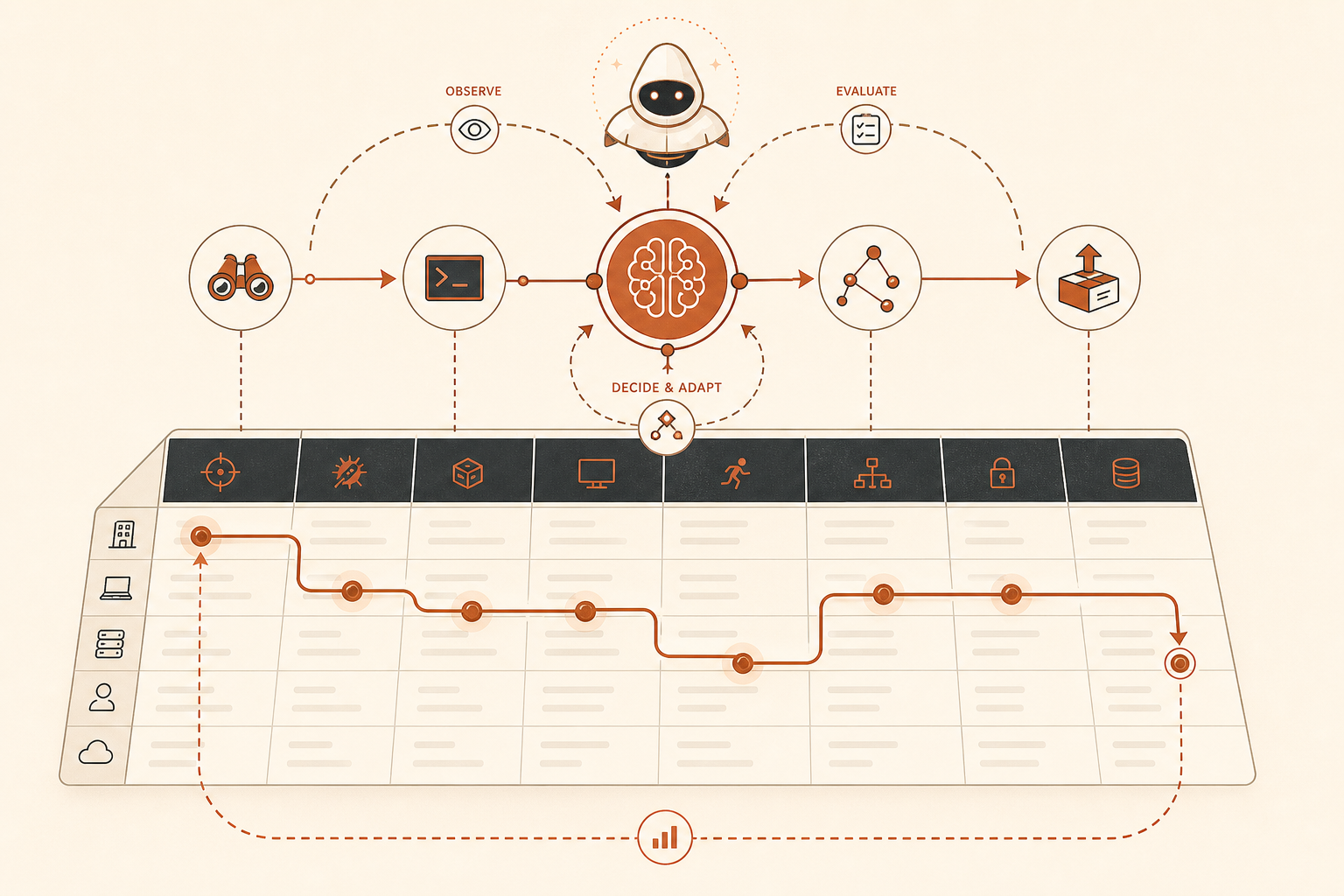
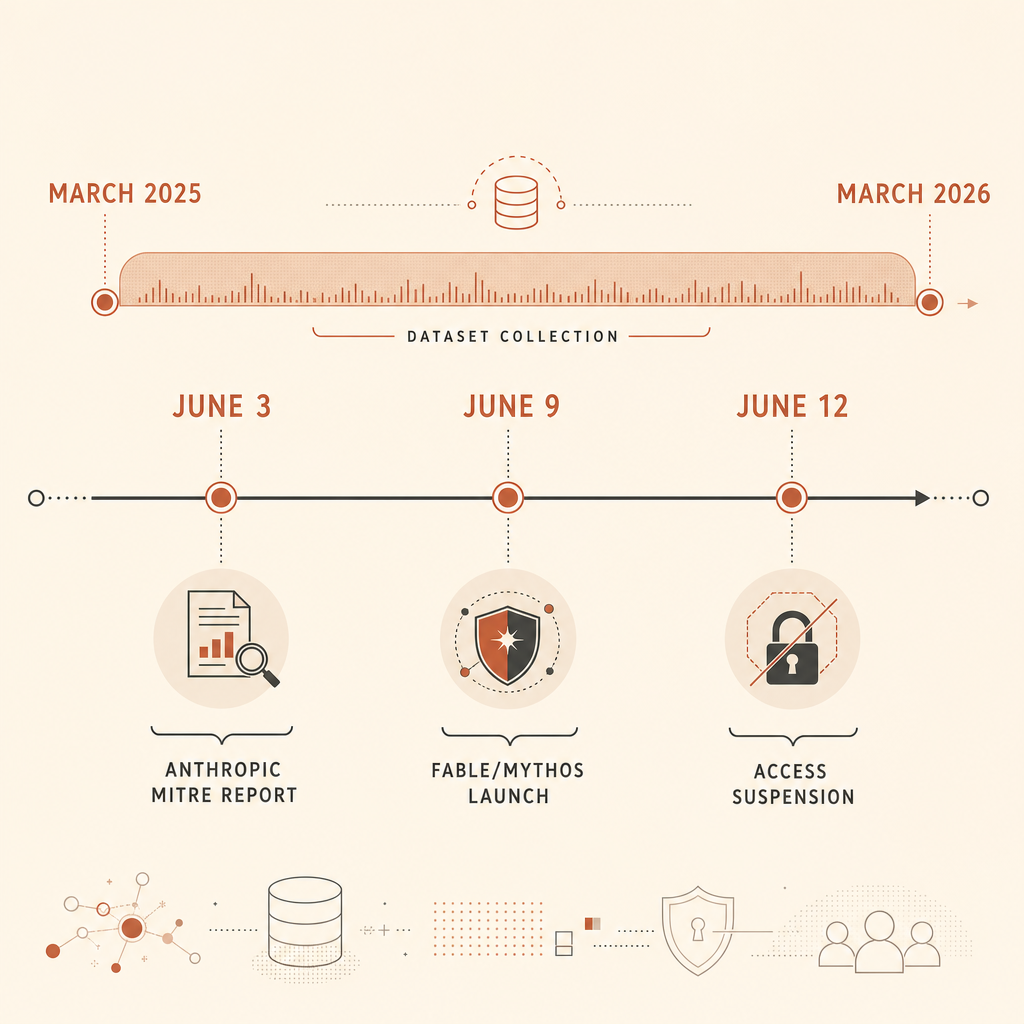
Anthropicの6月3日のサイバー脅威レポートには、セキュリティチームが見逃すべきではない硬い数字がある。2025年3月から2026年3月までに悪意あるサイバー活動で禁止された832件のClaudeアカウントを分析し、その活動をMITRE ATT&CKに対応付けた、というものだ(Anthropic)。見出しになる発見は「AIがマルウェアを書く」ではない。そんなことはもう分かっていた。より鋭い主張は、多くの防御側が攻撃者の振る舞いを説明する共通言語として使っているMITRE ATT&CKが、AIネイティブな攻撃を別物にしている要素、つまりエージェント型オーケストレーションをまだ捉えきれていない、という点だ。
この指摘は、騒がしい1週間の真ん中に投げ込まれた。6月9日、AnthropicはClaude Fable 5とClaude Mythos 5を発表し、Fableをサイバーセキュリティと生物学の安全対策を備えた公開版のMythosクラスモデル、Mythosを審査済みの防御側向けの制限版だと説明した(Anthropic)。6月12日までに、Anthropicは、報告された脱獄懸念に関連する米政府指令を受け、Fable 5とMythos 5へのアクセスを停止したと述べた(Anthropic)。Hacker NewsやRedditのスレッドでは今、そのガードレールが一般利用者を守るのか、防御側の足を引っ張るのか、それとも主に紛らわしい誤検知を生むだけなのかが議論されている。
開発者は、6月3日のレポートをFable騒動とは切り離して読むべきだ。これは製品発表の記事ではない。測定の記事だ。そしてセキュリティエンジニアに対して、今四半期に実行すべき現実的な更新を示している。エージェントの足場づくりを攻撃インフラとしてモデル化し始めろ、ということだ。
Anthropicが実際に測定したもの
Anthropicによると、この832件のアカウントは、観測された活動をMITRE ATT&CKに対応付けられるだけの詳細を調査担当者が得られた禁止アカウントの一部だった。Frontier Red Teamの解説では、さらに詳しい情報が加えられている。チームは13,873件の悪意ある活動観測を抽出し、それらをATT&CK v18にマッピングし、14のATT&CK戦術すべてと482個のユニークなサブテクニックにまたがる活動を確認した(Anthropic Frontier Red Team)。
これが重要なのは、モデルに合成CTFを解かせるベンチマークではなかったからだ。これは、サイバー関連の利用ポリシーに違反した実ユーザーからの悪用テレメトリだった。つまり、このデータセットには限界もある。見えているのはAnthropicの接点、つまりClaude.ai、Claude Code、API上での悪用だ。インターネット全体、他のモデル提供者、ローカルのオープンウェイトシステム、あるいはClaudeに一度も触れなかった攻撃は測っていない。これは強力なセンサーとして扱うべきであって、空全体ではない。
最も多かった振る舞いは、退屈だが重要なものだった。Anthropicは、832件中560件、つまり67.3%のアカウントがマルウェア開発にAIを使っていたと報告した。Frontier Red Teamの投稿によると、より広い「Develop Capabilities」ATT&CKファミリーであるT1587は574件、つまり69%のアカウントに現れた。これはコモディティ層だ。スクリプトを作り、ペイロードを改良し、回避を自動化し、つなぎのコードを生成する。
より興味深いシグナルは、時間とともに活動がどこへ移ったかだ。調査期間の前半では、AnthropicのARiESリスクスコアリングで中リスク以上に分類されたアクターは33%だった。後半ではそれが56%に上がり、およそ1.7倍になった。Anthropicはまた、AI支援のアカウント発見が8.9%増えた一方、AI支援のフィッシングは8.6%減ったとも述べている(Anthropic)。
防御側が気にすべきなのはそこだ。フィッシングは侵入口である。アカウント発見、ラテラルムーブメント、権限昇格、認証情報アクセスは侵害後の作業だ。そこには文脈、適応、戦術的判断が必要になる。AI利用がそこへ流れているなら、モデルはもはや単なるペイロード生成器ではない。オペレーターループの一部になりつつある。
| Anthropicのデータセットからのシグナル | 数値 |
|---|---|
| 分析された悪意あるサイバー関連の禁止アカウント | 832 |
| 調査期間 | 2025年3月から2026年3月 |
| 対応付けられた観測済みの悪意ある行動 | 13,873 |
| 観測されたユニークなATT&CKサブテクニック | 482 |
| マルウェア開発にAIを使ったアカウント | 560、または67.3% |
| 前半の中リスク以上のアクター | 33% |
| 後半の中リスク以上のアクター | 56% |
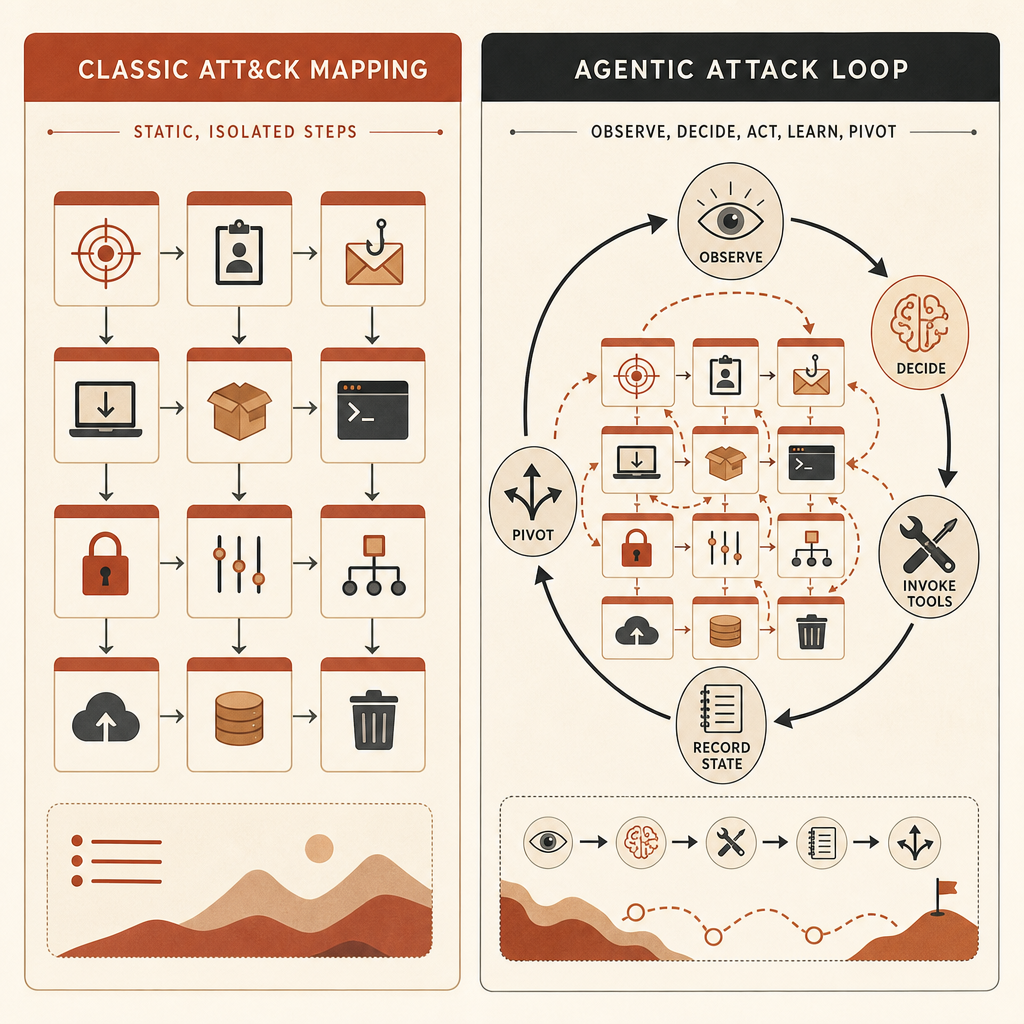
MITRE ATT&CKがきしみ始める理由
MITRE ATT&CKはいまも価値がある。MITREはそれを、実世界の観測に基づく攻撃者の戦術と技術に関する、世界中からアクセス可能な知識ベースであり、産業界と政府全体で脅威モデルや方法論に使われているものだと説明している(MITRE)。T1587.001のマルウェア開発、認証情報ダンプ、アカウント発見、コマンド実行、持ち出しといった行為に、チームが共有できるIDを与えてくれる。
問題は、ATT&CKが原子的な動きに名前を付けるのは得意だということだ。Anthropicの主張は、危険なAIの振る舞いはその動きと動きのあいだに存在する、というものだ。
人間のオペレーターなら、こう判断するかもしれない。このホストをスキャンし、この結果を調べ、この認証情報へピボットし、この横展開ルートを試し、それからこのファイルを持ち出す。ATT&CKは各ステップをマッピングできる。だが、エージェント型ハーネスが判断し、ツールを実行し、計画を更新し、人間の入力を最小限にして進み続けるなら、ATT&CK上の地図は普通に見えても、作戦の質はまったく別物になる。
Anthropicの例は、2025年11月に同社が阻止したというサイバースパイ活動だ。このケースでは、攻撃者はClaude Codeを使い、Anthropicによれば、人間の介入をほとんど伴わず世界中の標的への侵入を試みた。ATT&CKにマッピングすると、13の戦術にまたがる30の技術を使っており、データセット内の多くの中リスクアクターと同程度だった。AnthropicのARiESシステムでは、最大値である100を記録した(Anthropic)。
このズレこそが本題だ。技術数は「中程度っぽい」と言う。エージェント型実行は「重大」と言う。
Frontier Red Teamの投稿はさらに具体的だ。GTG-1002とラベル付けされたそのアクターは、Kali Linux上でClaude Codeを使い、オープンソースのペネトレーションテストツールをMCPサーバーとして統合し、モデルをコードアシスタントではなく自律的な攻撃プラットフォームへ変えていた(Anthropic Frontier Red Team)。これは、ほとんどの社内脅威モデルがいまだ十分に記述できていない種類の振る舞いそのものだ。
「エージェント型サイバーリスク」を運用用語で言うと
この言葉は抽象的に聞こえる。だがそうではない。エンジニアリングチームにとって、エージェント型サイバーリスクとは、攻撃者が次のようなループを持つことを意味する。
observe target state -> choose next tactic -> call tool -> parse result
-> update memory -> pivot or stop -> repeat without waiting for a humanこのループは3つのものを変える。
第一に、時間を圧縮する。モデルがコマンドを選び、出力を解釈し、エラーから復帰できるなら、低スキルのアクターは各ツールを深く理解している必要がなくなる。Anthropicは、見かけ上のアクタースキルと使用された技術数の相関が弱いことを発見した。最も低スキルのアクターは平均約16種類の技術を使い、最も熟練したアクターは平均約20種類だった(Anthropic)。
第二に、インターフェース選択による安心感を薄くする。Anthropicによると、アクターがClaude Code、API、チャットインターフェースのどれを使ったかは、リスクレベルと相関しなかった。高リスクを分ける要因は、攻撃ライフサイクルのどこにAIを適用したか、そしてその周りにどんな足場を組んだかだった。
第三に、「ガードレール」をランタイムシステムの問題に変える。ブロックされたプロンプトは1つの制御にすぎない。だが、ツール、メモリ、リトライ、シェルアクセス、ブラウザアクセス、MCPサーバーを持つ長時間稼働のエージェントは分散システムだ。危険な行為は多くのリクエストをまたいで現れるかもしれない。だからこそAnthropicは、Fable 5とMythosクラスのモデルを安全監視のための30日間保持と結び付け、そのデータが複数リクエストにまたがる脱獄や悪用パターンの検出に役立つと述べた(Anthropic)。
開発者はそのポリシーを嫌がるかもしれない。ゼロ保持の約束を持つエンタープライズ顧客は本当に嫌がる。だが検出の観点では、Anthropicの主張は筋が通っている。単発の分類器に攻撃グラフは見えない。
コミュニティの争点は誤検知とアクセスだ
開発者の議論は「AIはハッカーを助けるべきか」ではない。真面目な人間で、マルウェア・アズ・ア・サービスを望む者はいない。本当の争点は、誰がフルモデルを使えるのか、誰がダウングレードされるのか、そして制御がどれだけ見えるのかだ。
Hacker Newsでは、4月のProject Glasswingに関する議論で、Anthropicのマーケティングへの懐疑と、より具体的な懸念が混ざっていた。ツールを使うエージェントが永続的で、目標指向で、実際のツールにつながっているなら、脆弱性調査に役立つ同じ性質が、エージェントが台本から外れたときに危険になる、という懸念だ(Hacker News)。これが、この議論の大人版である。
Redditでは、ローンチ週の不満はもっと生々しかった。あるr/Anthropicスレッドでは、Fableにプロジェクトの監査を頼んだらフラグが立ち、Opusに降格されたというユーザーが、そんなに簡単に引っかかるならFableは何の役に立つのかと問いかけていた(Reddit)。r/cybersecurityでは、30日間保持の要件や、正当なセキュリティ業務に対してガードレールが粗すぎるのではないかが議論された(Reddit)。
TechCrunchも、セキュリティ研究者側の同じ痛みを捉えている。Matt Suicheは同媒体に対し、安全なコードに関するリクエストでさえサイバーセキュリティ扱いされてダウングレードされる可能性があると語り、その挙動はキーワードベースに見えると述べた(TechCrunch)。Anthropic自身のローンチ投稿も、安全対策は保守的に調整されており、無害なリクエストを捕まえることがあると認めている。
そして6月12日の停止が来た。Anthropicは、狭い範囲の潜在的な脱獄が商用モデルのリコールを正当化するという見解には同意しないものの、政府指令により全顧客に対してFable 5とMythos 5を無効化せざるを得なかったと述べた(Anthropic)。これにより、コミュニティの議論は「誤検知はうっとうしい」から「モデルアクセスはサイバー政策の一部になった」へと変わった。
私の立場はこうだ。Anthropicは、エージェント型サイバーリスクが現実だという点で正しいし、完全な脱獄耐性など幻想だという点でも正しい。だが、開発者が自分のツールの挙動がいつ変わるのか予測できないなら、乱暴なダウングレードは悪い開発者体験であり、悪いセキュリティ制御でもある。セキュリティチームに必要なのは、透明なルーティング、監査ログ、承認済みの高リスクワークフロー、そしてスコープを絞ったツール権限だ。インシデント対応の途中で突然モデルが差し替わることではない。
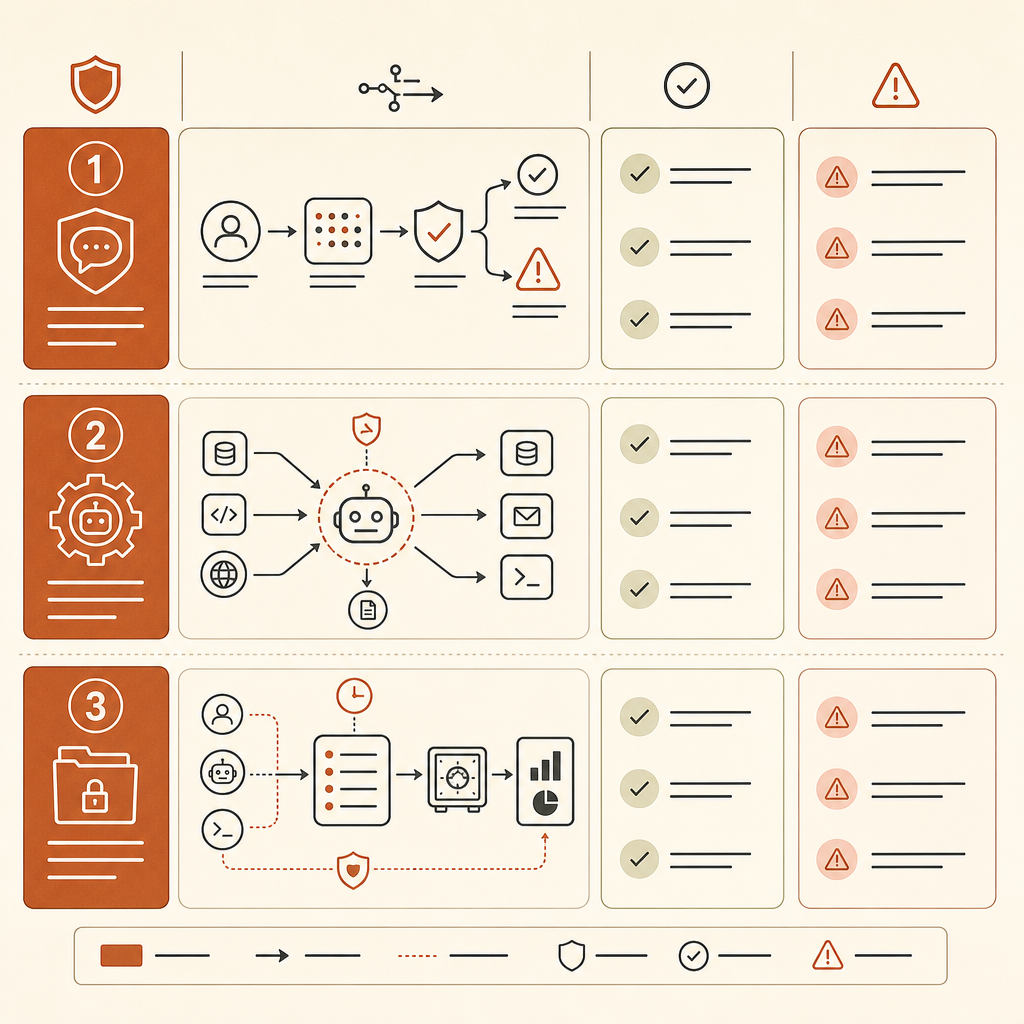
社内脅威モデルをどう更新するか
あなたの会社がClaude Code風のツール、Cursorのようなエージェント、社内コーディングエージェント、あるいはAPI駆動のLLM自動化を許可しているなら、今すぐ脅威モデルを更新すべきだ。MITREが新しいIDを作るのを待ってはいけない。
まずはエージェントの棚卸しから始める。どのエージェントがリポジトリを読めるのか、シェルコマンドを実行できるのか、社内システムをブラウズできるのか、スキャナーを呼び出せるのか、チケットを開けるのか、シークレットにアクセスできるのかを追跡する。リスクの単位はもはや「ユーザーがチャットにコードを貼り付けた」ではない。「エージェントがツールと状態と目標を持っている」だ。
テレメトリに足場検出を加える。ツール呼び出し、コマンド列、MCPサーバーの使用、リトライ、ファイル読み取り、ネットワークリクエスト、権限変更をログに残す。ラボでの単発のnmap実行は普通かもしれない。だが、スキャンし、解析し、認証情報を選び、ホストをピボットし、結果をメモリに書き込むループは、誰かを呼び出すべきだ。
防御的ワークフローとオープンエンドな自律性を分ける。良いパターンは境界のあるジョブだ。「このリポジトリをSQLインジェクションのシンクについてスキャンし、候補パッチを作成する」。読み取り専用の認証情報とネットワーク外向き通信なしで行う。悪いパターンは「ステージング環境を調査して、見つけたものを何でも直して」。広いシェルアクセスと永続メモリ付きで、だ。
ATT&CK技術をマッピングしつつ、その上に社内の「エージェント型レイヤー」を追加する。
| 社内ラベル | 記録すべきこと |
|---|---|
| 自律的な連鎖 | モデルは人間の承認なしに複数のATT&CKステップを順序付けたか? |
| 戦術的ピボット | ライブ出力に基づいて、新しい標的、認証情報、エクスプロイト経路、ツールを選んだか? |
| ツール権限 | エージェントは何を実行、読み取り、変更、持ち出しできたか? |
| メモリ使用 | 標的状態、認証情報、仮説、計画を永続化したか? |
| 人間のチェックポイント | どのステップに明示的な承認が必要で、その承認は意味のあるものだったか? |
AIプラットフォームチームにとって、実際的な制御はツール境界でのポリシーだ。モデルの拒否だけに頼ってはいけない。コマンドの許可リストを強制する。ネットワークスキャン、認証情報アクセス、エクスプロイトの概念実証生成、破壊的変更には承認を必須にする。シークレットは、デフォルトでエージェントアクセスを拒否できるブローカーの背後に置く。自律ループにレート制限をかける。セキュリティレビュー担当者がエージェントの見たもの、行ったことを再現できるよう、実行ごとの来歴を残す。
セキュリティエンジニアにとって、新しい検出の問いはシンプルだ。「このエージェントを持ったジュニア攻撃者は、1時間だけシニアオペレーターのように振る舞えるか?」。答えがイエスなら、各個別技術が普通に見えても、そのワークフローは高リスクに分類すべきだ。
役に立つ結論
Anthropicのレポートは、MITRE ATT&CKが時代遅れだという不満として誤読されやすい。それは浅すぎる。ATT&CKはいまも動きに名前を付けている。足りない語彙は、指揮者のためのものだ。
6月3日のデータセットは、AI悪用がキルチェーンのより深いところへ、準備から侵害後の活動へ移っていることを示している。Fable/Mythosをめぐる争いは、その世界に向けた防御を出荷することがなぜ厄介なのかを示している。開発者は強力なツールを求め、防御側はアクセスを必要とし、ベンダーは監視を必要とし、政府はいまや介入する意思を持っている。
正しい反応はパニックではない。そして、ガードレールだけで十分なふりをすることでもない。エージェントの足場をインフラとして扱うことだ。脅威モデルに入れる。ログを取る。ツール利用の周りにポリシーを置く。MITREが公式の技術IDを与える前であっても、今日から社内の検出言語に「自律的オーケストレーション」と「リアルタイムの戦術的ピボット」を加えるべきだ。
小さなフッター: アクセス可能になったときにClaude Fable 5を自分で試したい読者は、Claude Fable 5 on OneHop経由で使える。定価より約30%安いドロップインエンドポイントだ。新規アカウントはカード不要で、start with $10 freeから10ドル分を無料で受け取れる。
さらに読む: Claude Fable 5を始める.

