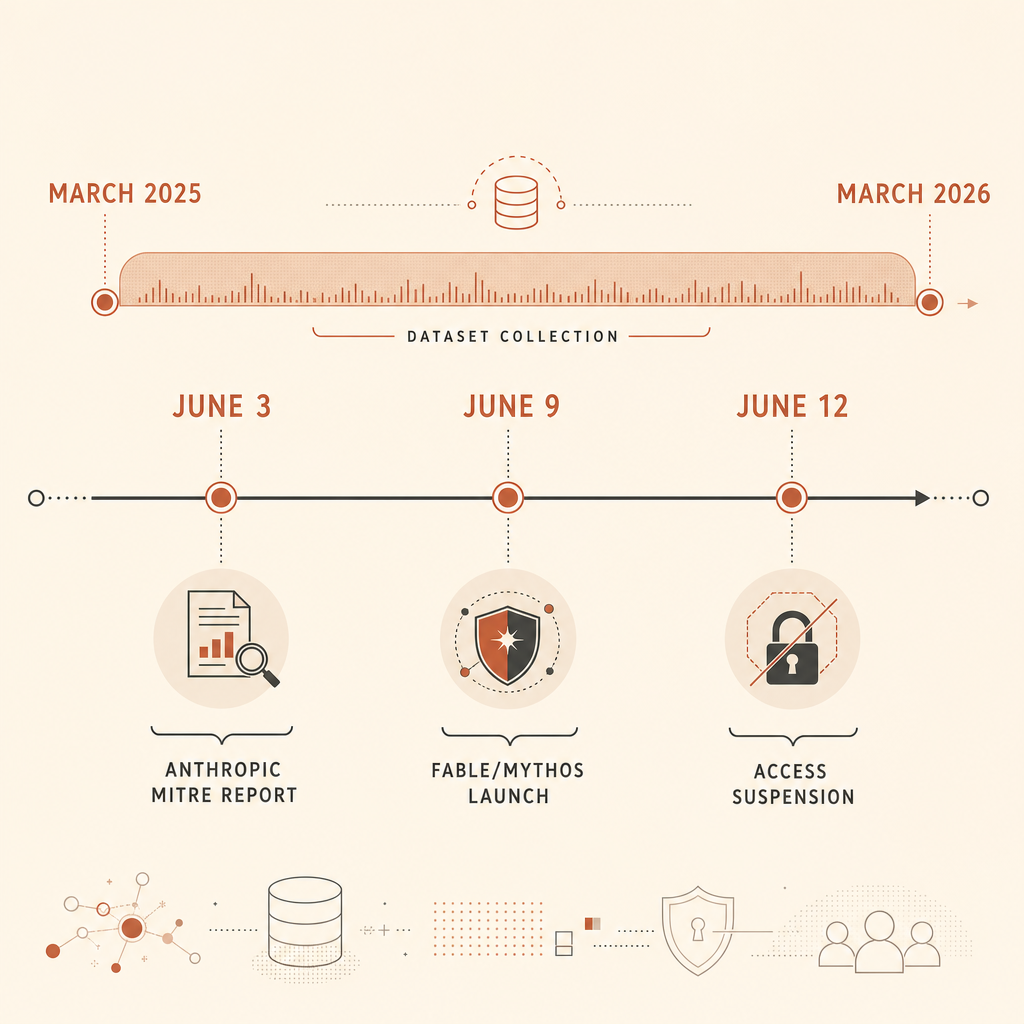
El informe de ciberamenazas del 3 de junio de Anthropic tiene una cifra dura que los equipos de seguridad no deberían ignorar: analizó 832 cuentas de Claude bloqueadas por actividad cibernética maliciosa entre marzo de 2025 y marzo de 2026, y luego mapeó esa actividad a MITRE ATT&CK (Anthropic). El hallazgo principal no fue “la IA escribe malware”. Eso ya lo sabíamos. La afirmación más afilada es que MITRE ATT&CK, el lenguaje compartido que muchos defensores usan para describir el comportamiento adversario, todavía no captura lo que hace distintos a los ataques nativos de IA: la orquestación agéntica.
Ese punto cayó en medio de una semana ruidosa. El 9 de junio, Anthropic lanzó Claude Fable 5 y Claude Mythos 5, describiendo Fable como el modelo público de clase Mythos con salvaguardas para ciberseguridad y biología, y Mythos como la versión restringida para defensores verificados (Anthropic). Para el 12 de junio, Anthropic dijo que había suspendido el acceso a Fable 5 y Mythos 5 tras una directiva del gobierno de EE. UU. vinculada a una supuesta preocupación por jailbreak (Anthropic). Los hilos de Hacker News y Reddit ahora discuten si esas barreras protegen al público, dejan cojos a los defensores o, sobre todo, generan falsos positivos confusos.
Los desarrolladores deberían leer el informe del 3 de junio por separado del drama de Fable. No es una publicación de lanzamiento de producto. Es una publicación de medición. Y les da a los ingenieros de seguridad una actualización práctica para este trimestre: empiecen a modelar el andamiaje de agentes como infraestructura de ataque.
Qué Midió Realmente Anthropic
Anthropic dice que las 832 cuentas eran un subconjunto de cuentas bloqueadas en las que los investigadores tenían suficiente detalle para mapear la actividad observada a MITRE ATT&CK. Su informe del Frontier Red Team agrega más contexto: el equipo extrajo 13.873 observaciones de actividad maliciosa, las mapeó a ATT&CK v18 y encontró actividad en las 14 tácticas de ATT&CK y 482 subtécnicas únicas (Anthropic Frontier Red Team).
Eso importa porque esto no fue un benchmark en el que se le pide a un modelo resolver un CTF sintético. Fue telemetría de abuso de usuarios reales que violaron políticas de uso relacionadas con ciberseguridad. Eso también significa que el conjunto de datos tiene límites. Ve el uso indebido en superficies de Anthropic: Claude.ai, Claude Code y la API. No mide todo internet, otros proveedores de modelos, sistemas locales de pesos abiertos ni ataques que nunca tocaron Claude. Trátalo como un sensor potente, no como todo el cielo.
El comportamiento más común fue aburrido e importante. Anthropic informó que 560 de las 832 cuentas, o el 67,3%, usaron IA para desarrollar malware. La familia más amplia de ATT&CK “Develop Capabilities”, T1587, apareció en 574 cuentas, o el 69%, según la publicación del Frontier Red Team. Ese es el nivel commodity: crear scripts, refinar payloads, automatizar evasión, generar código pegamento.
La señal más interesante es hacia dónde se movió la actividad con el tiempo. En la primera mitad de la ventana del estudio, el 33% de los actores fueron clasificados por el sistema de puntuación de riesgo ARiES de Anthropic como de riesgo medio o superior. En la segunda mitad, eso subió al 56%, un aumento de aproximadamente 1,7 veces. Anthropic también dice que el descubrimiento de cuentas asistido por IA subió un 8,9%, mientras que el phishing asistido por IA cayó un 8,6% (Anthropic).
Esa es la parte que debería importarle a los defensores. El phishing es entrada. El descubrimiento de cuentas, el movimiento lateral, la escalada de privilegios y el acceso a credenciales son trabajo posterior al compromiso. Requieren contexto, adaptación y decisiones tácticas. Si el uso de IA se está desplazando hacia ahí, el modelo ya no es solo un generador de payloads. Se está convirtiendo en parte del bucle del operador.
| Señal del conjunto de datos de Anthropic | Número |
|---|---|
| Cuentas de ciberactividad maliciosa bloqueadas analizadas | 832 |
| Ventana del estudio | Marzo de 2025 a marzo de 2026 |
| Acciones maliciosas observadas y mapeadas | 13.873 |
| Subtécnicas únicas de ATT&CK observadas | 482 |
| Cuentas que usaron IA para desarrollar malware | 560, o 67,3% |
| Actores de riesgo medio o superior, primera mitad | 33% |
| Actores de riesgo medio o superior, segunda mitad | 56% |
Por Qué MITRE ATT&CK Empieza a Doblarse
MITRE ATT&CK sigue siendo valioso. MITRE lo describe como una base de conocimiento globalmente accesible de tácticas y técnicas adversarias basada en observaciones del mundo real, usada para modelos de amenaza y metodologías en la industria y el gobierno (MITRE). Da a los equipos IDs compartidos para cosas como el desarrollo de malware T1587.001, el volcado de credenciales, el descubrimiento de cuentas, la ejecución de comandos y la exfiltración.
El problema es que ATT&CK es mejor nombrando los movimientos atómicos. La afirmación de Anthropic es que el comportamiento peligroso de la IA vive entre esos movimientos.
Un operador humano podría decidir: escanear este host, inspeccionar este resultado, pivotar hacia estas credenciales, probar esta ruta lateral y luego exfiltrar estos archivos. ATT&CK puede mapear cada paso. Pero si un arnés agéntico toma las decisiones, ejecuta herramientas, actualiza su plan y continúa con mínima intervención humana, el mapa de ATT&CK puede parecer ordinario mientras la operación es cualitativamente distinta.
El ejemplo de Anthropic es la campaña de ciberespionaje que dice haber interrumpido en noviembre de 2025. En ese caso, el actor usó Claude Code en una operación que Anthropic afirma que intentó infiltrarse en objetivos de todo el mundo con poca intervención humana. Mapeada a ATT&CK, usó 30 técnicas en 13 tácticas, comparable a muchos actores de riesgo medio del conjunto de datos. Bajo el sistema ARiES de Anthropic, obtuvo 100, la puntuación máxima (Anthropic).
Ese desajuste es la historia. El conteo de técnicas dice “más o menos medio”. La ejecución agéntica dice “crítico”.
La publicación del Frontier Red Team es más específica: el actor, etiquetado como GTG-1002, usó Claude Code en Kali Linux e integró herramientas de pruebas de penetración de código abierto como servidores MCP, convirtiendo el modelo en una plataforma de ataque autónoma en lugar de un asistente de código (Anthropic Frontier Red Team). Este es exactamente el tipo de comportamiento que la mayoría de los modelos internos de amenaza todavía describen mal.
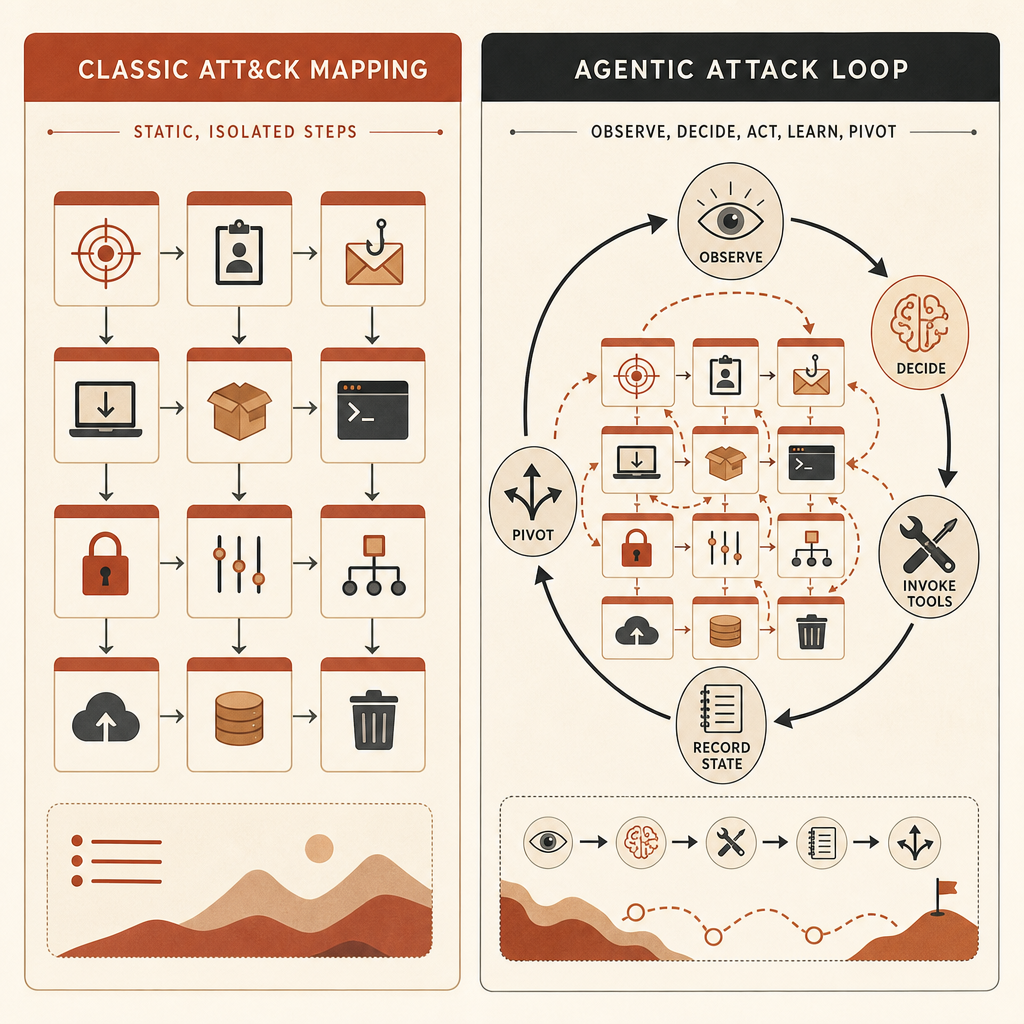
“Riesgo Cibernético Agéntico” en Términos Operativos
La frase suena abstracta. No lo es. Para un equipo de ingeniería, el riesgo cibernético agéntico significa que el atacante tiene un bucle como este:
observe target state -> choose next tactic -> call tool -> parse result
-> update memory -> pivot or stop -> repeat without waiting for a humanEse bucle cambia tres cosas.
Primero, comprime el tiempo. Un actor de baja habilidad ya no necesita entender cada herramienta en profundidad si el modelo puede seleccionar comandos, interpretar salidas y recuperarse de errores. Anthropic encontró una correlación débil entre la habilidad aparente del actor y el número de técnicas usadas: los actores menos hábiles promediaron unas 16 técnicas distintas, mientras que los más hábiles promediaron unas 20 (Anthropic).
Segundo, hace que la elección de interfaz sea menos tranquilizadora. Anthropic dice que si el actor usó Claude Code, una API o una interfaz de chat no se correlacionó con el nivel de riesgo. El diferenciador de alto riesgo fue en qué parte del ciclo de vida del ataque aplicó IA el actor y qué andamiaje construyó alrededor.
Tercero, convierte las “guardrails” en un problema de sistemas en tiempo de ejecución. Un prompt bloqueado es un control. Pero un agente de larga duración con herramientas, memoria, reintentos, acceso a shell, acceso a navegador y servidores MCP es un sistema distribuido. La acción riesgosa puede emerger a lo largo de muchas solicitudes. Eso explica por qué Anthropic vinculó Fable 5 y los modelos de clase Mythos a una retención de 30 días para monitoreo de seguridad, diciendo que los datos ayudan a detectar jailbreaks de múltiples solicitudes y patrones de uso indebido (Anthropic).
Puede que a los desarrolladores no les guste esa política. A los compradores empresariales con compromisos de retención cero les gusta todavía menos. Pero desde el punto de vista de detección, el argumento de Anthropic es coherente: un clasificador de un solo turno no puede ver un grafo de ataque.
La Pelea de la Comunidad Va de Falsos Positivos y Acceso
El debate entre desarrolladores no es “¿debería la IA ayudar a hackers?”. Nadie serio quiere malware-as-a-service. La pelea real es: quién obtiene el modelo completo, quién recibe una versión degradada y qué tan visibles son los controles.
En Hacker News, la discusión de abril sobre Project Glasswing mezcló escepticismo sobre el marketing de Anthropic con una preocupación más concreta: si un agente que usa herramientas es persistente, orientado a objetivos y conectado a herramientas reales, las mismas propiedades que ayudan a la investigación de vulnerabilidades se vuelven peligrosas si el agente se sale del guion (Hacker News). Esa es la versión adulta del debate.
En Reddit, las quejas de la semana de lanzamiento fueron más crudas. En un hilo de r/Anthropic, un usuario describió pedirle a Fable que auditara un proyecto y ser marcado y degradado a Opus, preguntando cómo puede ser útil Fable si salta tan fácilmente (Reddit). En r/cybersecurity, los usuarios discutieron el requisito de retención de 30 días y si la guardrail era demasiado burda para trabajo legítimo de seguridad (Reddit).
TechCrunch capturó el mismo dolor de los investigadores de seguridad. Matt Suiche dijo a la publicación que incluso solicitudes de código seguro podían tratarse como ciberseguridad y degradarse, y describió el comportamiento como aparentemente basado en palabras clave (TechCrunch). La propia publicación de lanzamiento de Anthropic admite que las salvaguardas fueron ajustadas de forma conservadora y que a veces atraparían solicitudes inofensivas.
Luego llegó la suspensión del 12 de junio. Anthropic dijo que la directiva gubernamental la obligó a desactivar Fable 5 y Mythos 5 para todos los clientes, aunque no estaba de acuerdo con que un posible jailbreak estrecho justificara retirar un modelo comercial (Anthropic). Eso convirtió el argumento de la comunidad de “los falsos positivos son molestos” en “el acceso al modelo ahora forma parte de la política cibernética”.
Mi postura: Anthropic tiene razón en que el riesgo cibernético agéntico es real, y también en que la resistencia perfecta a jailbreaks es una fantasía. Pero las degradaciones bruscas son una mala experiencia para desarrolladores y un mal control de seguridad si los defensores no pueden predecir cuándo sus herramientas cambiarán de comportamiento. Los equipos de seguridad necesitan enrutamiento transparente, registros de auditoría, flujos de trabajo aprobados de alto riesgo y permisos de herramientas acotados. No necesitan cambios sorpresa de modelo en medio de una respuesta a incidentes.
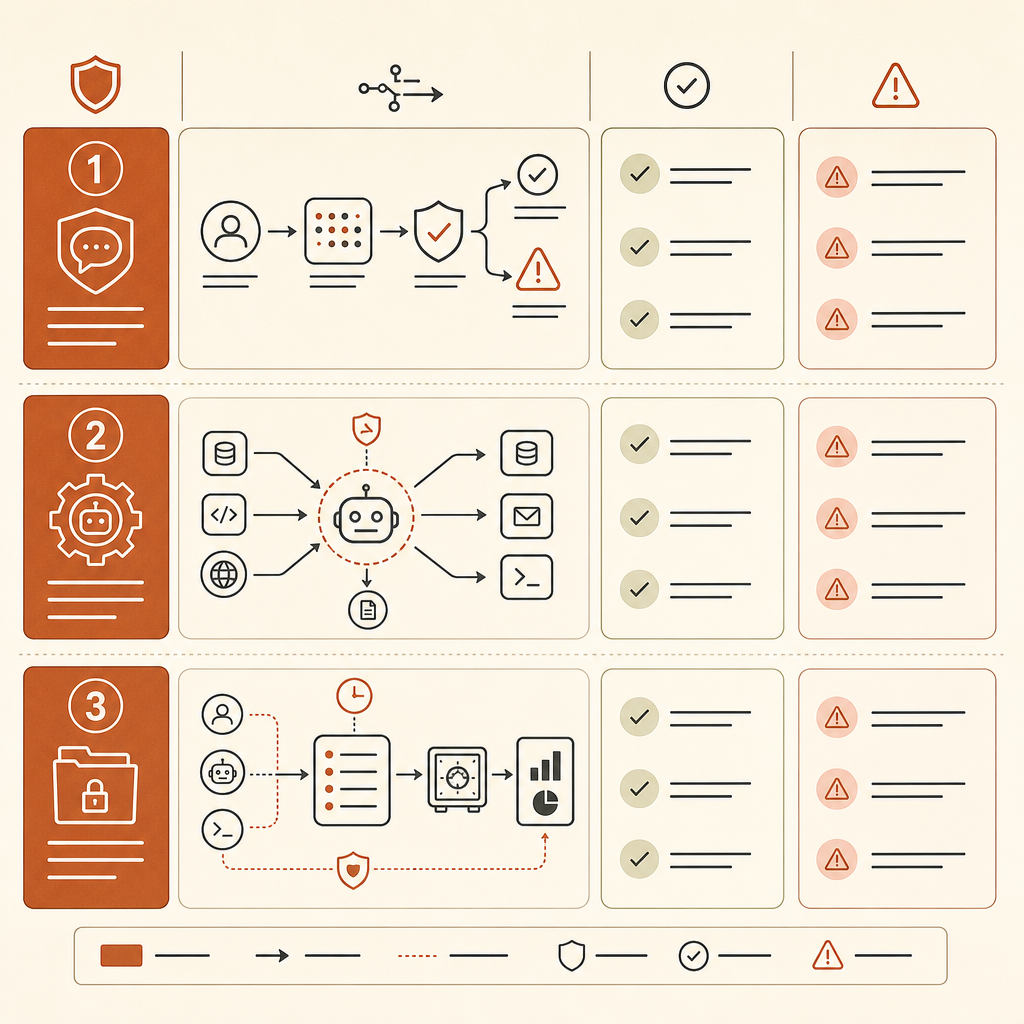
Cómo Actualizar Tu Modelo Interno de Amenazas
Si tu empresa permite herramientas estilo Claude Code, agentes tipo Cursor, agentes internos de programación o automatización LLM impulsada por API, actualiza el modelo de amenazas ahora. No esperes a que MITRE acuñe nuevos IDs.
Empieza con un inventario de agentes. Registra qué agentes pueden leer repositorios, ejecutar comandos de shell, navegar por sistemas internos, llamar a escáneres, abrir tickets o acceder a secretos. La unidad de riesgo ya no es “un usuario pegó código en el chat”. Es “un agente tiene herramientas más estado más un objetivo”.
Añade detección de andamiaje a tu telemetría. Registra llamadas a herramientas, secuencias de comandos, uso de servidores MCP, reintentos, lecturas de archivos, solicitudes de red y cambios de permisos. Una sola invocación de nmap puede ser normal en un laboratorio. Un bucle que escanea, parsea, selecciona credenciales, pivota entre hosts y escribe hallazgos en memoria debería alertar a alguien.
Separa los flujos defensivos de la autonomía abierta. Un buen patrón es un trabajo acotado: “escanea este repo en busca de sinks de inyección SQL y produce parches candidatos”, con credenciales de solo lectura y sin salida a red. Un mal patrón es “investiga nuestro entorno de staging y arregla lo que encuentres”, con amplio acceso a shell y memoria persistente.
Mapea técnicas de ATT&CK, pero añade una “capa agéntica” interna encima:
| Etiqueta interna | Qué registrar |
|---|---|
| Encadenamiento autónomo | ¿El modelo secuenció múltiples pasos de ATT&CK sin aprobación humana? |
| Pivote táctico | ¿Eligió un nuevo objetivo, credencial, ruta de explotación o herramienta basándose en salida en vivo? |
| Privilegio de herramientas | ¿Qué podía ejecutar, leer, modificar o exfiltrar el agente? |
| Uso de memoria | ¿Persistió estado del objetivo, credenciales, hipótesis o planes? |
| Puntos de control humanos | ¿Qué pasos requirieron aprobación explícita, y esas aprobaciones fueron significativas? |
Para los equipos de plataformas de IA, el control práctico es la política en el límite de la herramienta. No dependas solo de negativas del modelo. Aplica listas permitidas para comandos. Exige aprobaciones para escaneo de red, acceso a credenciales, generación de pruebas de concepto de exploits y cambios destructivos. Pon los secretos detrás de brokers que puedan negar por defecto el acceso de agentes. Limita la tasa de los bucles autónomos. Mantén procedencia por ejecución para que un revisor de seguridad pueda reproducir lo que el agente vio e hizo.
Para ingenieros de seguridad, la nueva pregunta de detección es simple: “¿Podría un atacante junior con este agente comportarse como un operador senior durante una hora?”. Si la respuesta es sí, clasifica el flujo de trabajo como de alto riesgo aunque cada técnica individual parezca ordinaria.
La Conclusión Útil
Es fácil leer mal el informe de Anthropic como una queja de que MITRE ATT&CK está desactualizado. Eso es demasiado superficial. ATT&CK todavía nombra los movimientos. El vocabulario que falta es para el director de orquesta.
El conjunto de datos del 3 de junio muestra que el uso indebido de IA se está moviendo más profundo en la kill chain, de la preparación a la actividad posterior al compromiso. La pelea Fable/Mythos muestra por qué lanzar defensas para ese mundo es complicado: los desarrolladores quieren herramientas potentes, los defensores necesitan acceso, los proveedores necesitan monitoreo y los gobiernos ahora están dispuestos a intervenir.
La respuesta correcta no es el pánico, y tampoco es fingir que las guardrails bastan. Trata el andamiaje de agentes como infraestructura. Modela sus amenazas. Regístralo. Pon políticas alrededor del uso de herramientas. Añade “orquestación autónoma” y “pivote táctico en tiempo real” al lenguaje interno de detección hoy, incluso antes de que MITRE les dé IDs oficiales de técnica.
Nota al pie breve: Los lectores que quieran probar Claude Fable 5 por su cuenta, cuando el acceso esté disponible, pueden usarlo a través de Claude Fable 5 on OneHop, un endpoint drop-in a alrededor de un 30% por debajo del precio de lista. Las cuentas nuevas reciben $10 gratis sin tarjeta mediante start with $10 free.
Lectura adicional: Getting started with Claude Fable 5.

