Le rapport d’Anthropic du 3 juin sur les cybermenaces contient un chiffre que les équipes sécurité ne devraient pas ignorer : il analyse 832 comptes Claude bannis pour activité cyber malveillante entre mars 2025 et mars 2026, puis rattache cette activité à MITRE ATT&CK (Anthropic). Le constat principal n’est pas « l’IA écrit des malwares ». Ça, on le savait déjà. L’affirmation la plus intéressante, c’est que MITRE ATT&CK, le langage commun que beaucoup de défenseurs utilisent pour décrire le comportement des adversaires, ne capture pas encore ce qui rend les attaques natives IA différentes : l’orchestration agentique.
Ce point est tombé au milieu d’une semaine bruyante. Le 9 juin, Anthropic a lancé Claude Fable 5 et Claude Mythos 5, présentant Fable comme le modèle public de classe Mythos avec des garde-fous en cybersécurité et en biologie, et Mythos comme la version restreinte réservée aux défenseurs approuvés (Anthropic). Le 12 juin, Anthropic annonçait avoir suspendu l’accès à Fable 5 et Mythos 5 après une directive du gouvernement américain liée à une inquiétude signalée autour d’un jailbreak (Anthropic). Les fils Hacker News et Reddit débattent maintenant pour savoir si ces garde-fous protègent le public, brident les défenseurs, ou créent surtout des faux positifs déroutants.
Les développeurs devraient lire le rapport du 3 juin séparément du feuilleton Fable. Ce n’est pas un billet de lancement produit. C’est un billet de mesure. Et il donne aux ingénieurs sécurité une mise à jour très concrète à faire ce trimestre : commencer à modéliser l’échafaudage agentique comme une infrastructure d’attaque.
Ce qu’Anthropic a réellement mesuré
Anthropic indique que les 832 comptes étaient un sous-ensemble de comptes bannis pour lesquels les enquêteurs disposaient de suffisamment de détails pour rattacher l’activité observée à MITRE ATT&CK. Le billet de sa Frontier Red Team donne plus de précisions : l’équipe a extrait 13 873 observations d’activités malveillantes, les a rattachées à ATT&CK v18, et a trouvé de l’activité dans les 14 tactiques ATT&CK ainsi que 482 sous-techniques uniques (Anthropic Frontier Red Team).
C’est important parce qu’il ne s’agissait pas d’un benchmark où l’on demande à un modèle de résoudre un CTF artificiel. C’était de la télémétrie d’abus provenant de vrais utilisateurs ayant enfreint une politique d’usage liée au cyber. Cela signifie aussi que le jeu de données a ses limites. Il voit les abus sur les surfaces d’Anthropic : Claude.ai, Claude Code et l’API. Il ne mesure pas tout Internet, les autres fournisseurs de modèles, les systèmes locaux à poids ouverts, ni les attaques qui n’ont jamais touché Claude. Prenez-le comme un capteur solide, pas comme le ciel entier.
Le comportement le plus courant était banal, et important. Anthropic rapporte que 560 des 832 comptes, soit 67,3 %, ont utilisé l’IA pour développer des malwares. La famille ATT&CK plus large « Develop Capabilities », T1587, apparaît dans 574 comptes, soit 69 %, selon le billet de la Frontier Red Team. C’est l’étage commoditisé : construire des scripts, affiner des payloads, automatiser l’évasion, générer du code de liaison.
Le signal le plus intéressant est l’évolution de l’activité dans le temps. Dans la première moitié de la période étudiée, 33 % des acteurs étaient classés par le score de risque ARiES d’Anthropic comme présentant un risque moyen ou plus élevé. Dans la seconde moitié, ce chiffre est monté à 56 %, soit une hausse d’environ 1,7x. Anthropic indique aussi que la découverte de comptes assistée par IA a augmenté de 8,9 %, tandis que le phishing assisté par IA a baissé de 8,6 % (Anthropic).
C’est la partie qui devrait intéresser les défenseurs. Le phishing, c’est l’entrée. La découverte de comptes, le mouvement latéral, l’élévation de privilèges et l’accès aux identifiants, c’est le travail post-compromission. Il faut du contexte, de l’adaptation et des choix tactiques. Si l’usage de l’IA glisse vers là, le modèle n’est plus seulement un générateur de payloads. Il devient une partie de la boucle opérateur.
| Signal issu du jeu de données d’Anthropic | Nombre |
|---|---|
| Comptes cyber malveillants bannis analysés | 832 |
| Période étudiée | Mars 2025 à mars 2026 |
| Actions malveillantes observées et rattachées | 13 873 |
| Sous-techniques ATT&CK uniques observées | 482 |
| Comptes utilisant l’IA pour le développement de malwares | 560, soit 67,3 % |
| Acteurs à risque moyen ou plus, première moitié | 33 % |
| Acteurs à risque moyen ou plus, seconde moitié | 56 % |
Pourquoi MITRE ATT&CK commence à plier
MITRE ATT&CK reste précieux. MITRE le décrit comme une base de connaissances mondiale et accessible sur les tactiques et techniques adverses fondées sur des observations réelles, utilisée pour les modèles de menace et les méthodologies dans l’industrie comme dans les administrations (MITRE). Il donne aux équipes des identifiants communs pour des choses comme le développement de malware T1587.001, le credential dumping, la découverte de comptes, l’exécution de commandes et l’exfiltration.
Le problème, c’est qu’ATT&CK excelle surtout à nommer les gestes atomiques. L’argument d’Anthropic est que le comportement IA dangereux se situe entre ces gestes.
Un opérateur humain pourrait décider : scanner cet hôte, examiner ce résultat, pivoter vers ces identifiants, tenter ce chemin latéral, puis exfiltrer ces fichiers. ATT&CK peut cartographier chaque étape. Mais si un harnais agentique prend les décisions, lance les outils, met à jour son plan et continue avec un minimum d’intervention humaine, la carte ATT&CK peut sembler ordinaire alors que l’opération est qualitativement différente.
L’exemple d’Anthropic est la campagne de cyberespionnage qu’elle dit avoir interrompue en novembre 2025. Dans ce cas, l’acteur a utilisé Claude Code dans une opération qui, selon Anthropic, tentait d’infiltrer des cibles dans le monde entier avec peu d’intervention humaine. Rattachée à ATT&CK, elle utilisait 30 techniques à travers 13 tactiques, comparable à de nombreux acteurs à risque moyen du jeu de données. Dans le système ARiES d’Anthropic, elle a obtenu 100, le maximum (Anthropic).
C’est ce décalage qui compte. Le nombre de techniques dit « plutôt moyen ». L’exécution agentique dit « critique ».
Le billet de la Frontier Red Team est plus précis : l’acteur, baptisé GTG-1002, utilisait Claude Code sur Kali Linux et avait intégré des outils open source de test d’intrusion comme serveurs MCP, transformant le modèle en plateforme d’attaque autonome plutôt qu’en assistant de code (Anthropic Frontier Red Team). C’est exactement le genre de comportement que la plupart des modèles de menace internes décrivent encore trop mal.
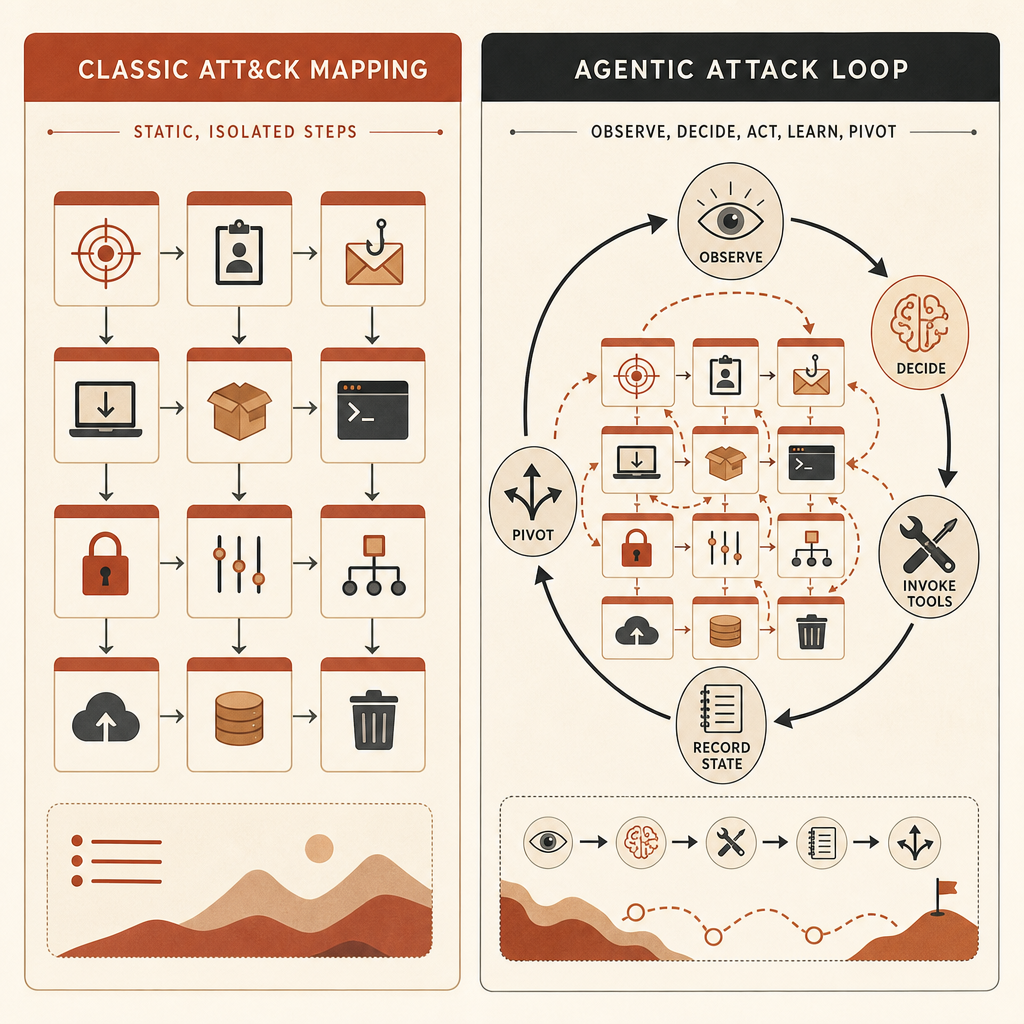
Le « risque cyber agentique » en termes opérationnels
L’expression paraît abstraite. Elle ne l’est pas. Pour une équipe d’ingénierie, le risque cyber agentique signifie que l’attaquant dispose d’une boucle comme celle-ci :
observe target state -> choose next tactic -> call tool -> parse result
-> update memory -> pivot or stop -> repeat without waiting for a humanCette boucle change trois choses.
D’abord, elle compresse le temps. Un acteur peu compétent n’a plus besoin de comprendre chaque outil en profondeur si le modèle peut choisir les commandes, interpréter la sortie et se remettre des erreurs. Anthropic a constaté une faible corrélation entre le niveau apparent de l’acteur et le nombre de techniques utilisées : les acteurs les moins compétents utilisaient en moyenne environ 16 techniques distinctes, contre environ 20 pour les plus compétents (Anthropic).
Ensuite, elle rend le choix de l’interface moins rassurant. Anthropic indique que le fait qu’un acteur utilise Claude Code, une API ou une interface de chat n’était pas corrélé au niveau de risque. Ce qui distingue le haut risque, c’est l’endroit où l’acteur applique l’IA dans le cycle de vie de l’attaque, et l’échafaudage qu’il construit autour.
Enfin, elle transforme les « garde-fous » en problème de systèmes à l’exécution. Un prompt bloqué est un contrôle. Mais un agent de longue durée avec outils, mémoire, reprises, accès shell, accès navigateur et serveurs MCP est un système distribué. L’action risquée peut émerger à travers de nombreuses requêtes. Cela explique pourquoi Anthropic a associé Fable 5 et les modèles de classe Mythos à une rétention de 30 jours pour la surveillance de sécurité, en expliquant que ces données aident à détecter les jailbreaks multi-requêtes et les schémas d’abus (Anthropic).
Les développeurs peuvent ne pas aimer cette politique. Les acheteurs entreprise avec des engagements de rétention zéro l’aiment vraiment encore moins. Mais du point de vue de la détection, l’argument d’Anthropic se tient : un classificateur sur un seul tour ne peut pas voir un graphe d’attaque.
Le débat communautaire porte sur les faux positifs et l’accès
Le débat développeur n’est pas « l’IA devrait-elle aider les hackers ? » Personne de sérieux ne veut du malware-as-a-service. Le vrai débat est : qui obtient le modèle complet, qui est rétrogradé, et à quel point les contrôles sont-ils visibles ?
Sur Hacker News, la discussion d’avril autour de Project Glasswing mêlait scepticisme envers le marketing d’Anthropic et inquiétude plus concrète : si un agent utilisant des outils est persistant, orienté objectif et connecté à de vrais outils, les mêmes propriétés qui aident la recherche de vulnérabilités deviennent dangereuses si l’agent sort du script (Hacker News). C’est la version adulte du débat.
Sur Reddit, les plaintes de la semaine de lancement étaient plus brutes. Dans un fil r/Anthropic, un utilisateur expliquait avoir demandé à Fable d’auditer un projet, avant d’être signalé et rétrogradé vers Opus, en demandant à quoi sert Fable s’il déclenche aussi facilement les filtres (Reddit). Dans r/cybersecurity, des utilisateurs discutaient de l’obligation de rétention de 30 jours et se demandaient si le garde-fou était trop brutal pour le travail de sécurité légitime (Reddit).
TechCrunch a capturé la même douleur chez les chercheurs en sécurité. Matt Suiche a déclaré à la publication que même des demandes de code sécurisé pouvaient être traitées comme de la cybersécurité et rétrogradées, décrivant un comportement qui semblait fondé sur des mots-clés (TechCrunch). Le propre billet de lancement d’Anthropic reconnaît que les protections ont été réglées de manière conservatrice et attraperaient parfois des requêtes inoffensives.
Puis est venue la suspension du 12 juin. Anthropic a déclaré que la directive gouvernementale l’obligeait à désactiver Fable 5 et Mythos 5 pour tous les clients, même si l’entreprise contestait qu’un potentiel jailbreak étroit justifie le rappel d’un modèle commercial (Anthropic). Cela a fait passer le débat communautaire de « les faux positifs sont agaçants » à « l’accès aux modèles fait maintenant partie de la politique cyber ».
Ma position : Anthropic a raison de dire que le risque cyber agentique est réel, et a aussi raison de dire qu’une résistance parfaite aux jailbreaks relève du fantasme. Mais les rétrogradations brutales sont une mauvaise expérience développeur et un mauvais contrôle de sécurité si les défenseurs ne peuvent pas prévoir quand leurs outils vont changer de comportement. Les équipes sécurité ont besoin de routage transparent, de journaux d’audit, de workflows à haut risque approuvés et de permissions d’outils cadrées. Elles n’ont pas besoin de changements de modèle surprise au milieu d’une réponse à incident.
Comment mettre à jour votre modèle de menace interne
Si votre entreprise autorise des outils à la Claude Code, des agents façon Cursor, des agents de codage internes ou de l’automatisation LLM pilotée par API, mettez à jour le modèle de menace maintenant. N’attendez pas que MITRE crée de nouveaux identifiants.
Commencez par l’inventaire des agents. Suivez quels agents peuvent lire des dépôts, exécuter des commandes shell, parcourir des systèmes internes, appeler des scanners, ouvrir des tickets ou accéder à des secrets. L’unité de risque n’est plus « un utilisateur a collé du code dans un chat ». C’est « un agent a des outils, de l’état et un objectif ».
Ajoutez la détection d’échafaudage à votre télémétrie. Journalisez les appels d’outils, les séquences de commandes, l’usage de serveurs MCP, les reprises, les lectures de fichiers, les requêtes réseau et les changements de permissions. Une seule invocation nmap peut être normale dans un lab. Une boucle qui scanne, parse, sélectionne des identifiants, pivote entre hôtes et écrit ses conclusions en mémoire devrait déclencher une alerte.
Séparez les workflows défensifs de l’autonomie ouverte. Un bon schéma est une tâche bornée : « scanne ce dépôt pour trouver des sinks d’injection SQL et produire des correctifs candidats », avec des identifiants en lecture seule et aucune sortie réseau. Un mauvais schéma est « enquête sur notre environnement de staging et corrige ce que tu trouves », avec un accès shell large et une mémoire persistante.
Cartographiez les techniques ATT&CK, mais ajoutez par-dessus une « couche agentique » interne :
| Libellé interne | Ce qu’il faut enregistrer |
|---|---|
| Chaînage autonome | Le modèle a-t-il enchaîné plusieurs étapes ATT&CK sans approbation humaine ? |
| Pivot tactique | A-t-il choisi une nouvelle cible, un identifiant, un chemin d’exploitation ou un outil en fonction d’une sortie live ? |
| Privilège d’outil | Que pouvait exécuter, lire, modifier ou exfiltrer l’agent ? |
| Usage de la mémoire | A-t-il persisté l’état des cibles, des identifiants, des hypothèses ou des plans ? |
| Points de contrôle humains | Quelles étapes exigeaient une approbation explicite, et ces approbations étaient-elles significatives ? |
Pour les équipes de plateformes IA, le contrôle pratique se situe à la frontière des outils. Ne comptez pas uniquement sur les refus du modèle. Imposez des listes d’autorisation pour les commandes. Exigez des approbations pour le scan réseau, l’accès aux identifiants, la génération de preuves de concept d’exploitation et les changements destructeurs. Placez les secrets derrière des courtiers capables de refuser par défaut l’accès aux agents. Limitez le débit des boucles autonomes. Conservez la provenance par exécution afin qu’un relecteur sécurité puisse rejouer ce que l’agent a vu et fait.
Pour les ingénieurs sécurité, la nouvelle question de détection est simple : « Un attaquant junior avec cet agent pourrait-il se comporter comme un opérateur senior pendant une heure ? » Si la réponse est oui, classez le workflow comme à haut risque, même lorsque chaque technique individuelle semble ordinaire.
Ce qu’il faut vraiment retenir
Le rapport d’Anthropic se lit facilement comme une plainte selon laquelle MITRE ATT&CK serait dépassé. C’est trop superficiel. ATT&CK nomme toujours les gestes. Le vocabulaire manquant concerne le chef d’orchestre.
Le jeu de données du 3 juin montre que l’usage malveillant de l’IA descend plus profondément dans la kill chain, de la préparation vers l’activité post-compromission. Le débat Fable/Mythos montre pourquoi livrer des défenses pour ce monde est compliqué : les développeurs veulent des outils puissants, les défenseurs ont besoin d’accès, les fournisseurs ont besoin de surveillance, et les gouvernements sont maintenant prêts à intervenir.
La bonne réponse n’est pas la panique, ni le fait de prétendre que les garde-fous suffisent. Traitez l’échafaudage agentique comme une infrastructure. Modélisez-le dans vos menaces. Journalisez-le. Encadrez l’usage des outils par des politiques. Ajoutez dès aujourd’hui « orchestration autonome » et « pivot tactique en temps réel » à votre langage de détection interne, même avant que MITRE leur donne des identifiants de techniques officiels.
Petit pied de page : les lecteurs qui veulent essayer Claude Fable 5 eux-mêmes, lorsque l’accès est disponible, peuvent l’utiliser via Claude Fable 5 on OneHop, un endpoint compatible en remplacement direct à environ 30 % sous le prix catalogue. Les nouveaux comptes reçoivent 10 $ gratuits sans carte via start with $10 free.
À lire aussi : Bien démarrer avec Claude Fable 5.

