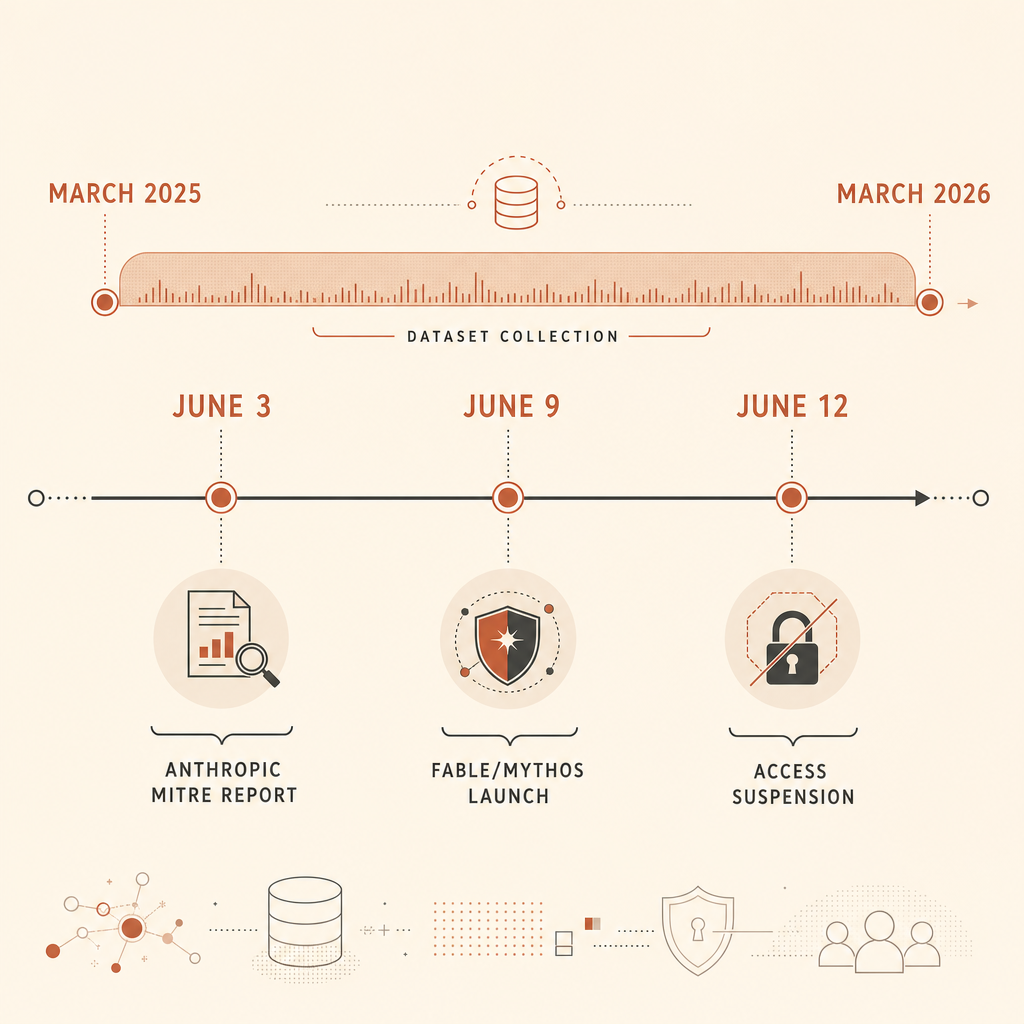
يتضمن تقرير Anthropic عن التهديدات السيبرانية الصادر في 3 يونيو رقمًا صارمًا لا ينبغي لفرق الأمن تجاهله: فقد حلّل 832 حساب Claude حُظرت بسبب نشاط سيبراني خبيث بين مارس 2025 ومارس 2026، ثم ربط هذا النشاط بإطار MITRE ATT&CK (Anthropic). لم تكن الخلاصة الرئيسية هي أن “الذكاء الاصطناعي يكتب برمجيات خبيثة”. كنا نعرف ذلك أصلًا. الادعاء الأكثر حدّة هو أن MITRE ATT&CK، اللغة المشتركة التي يستخدمها كثير من المدافعين لوصف سلوك الخصوم، لا تلتقط بعد الشيء الذي يجعل الهجمات الأصلية بالذكاء الاصطناعي مختلفة: التنسيق الوكيلي.
جاءت هذه النقطة وسط أسبوع صاخب. في 9 يونيو، أطلقت Anthropic كلًا من Claude Fable 5 وClaude Mythos 5، ووصفت Fable بأنه نموذج Mythos-class العام المزود بضوابط حماية في الأمن السيبراني والأحياء، ووصفت Mythos بأنه النسخة المقيّدة للمدافعين الذين جرى التحقق منهم (Anthropic). وبحلول 12 يونيو، قالت Anthropic إنها علّقت الوصول إلى Fable 5 وMythos 5 بعد توجيه من الحكومة الأميركية مرتبط بمخاوف مُبلّغ عنها حول كسر الحماية (Anthropic). والآن تمتلئ نقاشات Hacker News وReddit بالجدل حول ما إذا كانت تلك الحواجز تحمي الجمهور، أو تقصم ظهر المدافعين، أو غالبًا ما تخلق إنذارات كاذبة مربكة.
ينبغي للمطورين قراءة تقرير 3 يونيو بمعزل عن دراما Fable. فهو ليس منشور إطلاق منتج. إنه منشور قياس. ويمنح مهندسي الأمن تحديثًا عمليًا ينبغي تنفيذه هذا الربع: ابدأوا في نمذجة السقالات الوكيلة باعتبارها بنية تحتية للهجوم.
ما الذي قاسَته Anthropic فعلًا
تقول Anthropic إن الحسابات الـ832 كانت مجموعة فرعية من الحسابات المحظورة التي امتلك المحققون عنها تفاصيل كافية لربط النشاط المرصود بـMITRE ATT&CK. ويضيف تقرير Frontier Red Team لديها مزيدًا من التفاصيل: استخرج الفريق 13,873 ملاحظة لنشاط خبيث، وربطها بـATT&CK v18، ووجد نشاطًا عبر كل تكتيكات ATT&CK البالغ عددها 14، و482 تقنية فرعية فريدة (Anthropic Frontier Red Team).
هذا مهم لأن الأمر لم يكن معيار اختبار يُطلب فيه من نموذج حل CTF اصطناعي. كانت هذه قياسات إساءة استخدام من مستخدمين حقيقيين خالفوا سياسة الاستخدام المتعلقة بالأمن السيبراني. وهذا يعني أيضًا أن مجموعة البيانات لها حدود. فهي ترى سوء الاستخدام على واجهات Anthropic: Claude.ai وClaude Code وAPI. ولا تقيس الإنترنت كله، أو مزودي النماذج الآخرين، أو الأنظمة المحلية مفتوحة الأوزان، أو الهجمات التي لم تلمس Claude أصلًا. تعامل معها كحساس قوي، لا كسماء كاملة.
كان السلوك الأكثر شيوعًا مملًا ومهمًا. أفادت Anthropic بأن 560 من أصل 832 حسابًا، أي 67.3%، استخدمت الذكاء الاصطناعي لتطوير برمجيات خبيثة. وظهرت عائلة ATT&CK الأوسع “Develop Capabilities”، وهي T1587، في 574 حسابًا، أي 69%، وفقًا لمنشور Frontier Red Team. هذه هي طبقة السلعة: بناء سكربتات، تحسين الحمولات، أتمتة التهرب، وتوليد كود الربط.
الإشارة الأكثر إثارة للاهتمام هي أين انتقل النشاط مع الوقت. في النصف الأول من فترة الدراسة، صنّفت Anthropic نسبة 33% من الفاعلين، عبر نظام تقييم المخاطر ARiES، على أنهم متوسطو الخطورة أو أعلى. وفي النصف الثاني، ارتفعت النسبة إلى 56%، أي زيادة بنحو 1.7 مرة. وتقول Anthropic أيضًا إن اكتشاف الحسابات بمساعدة الذكاء الاصطناعي ارتفع 8.9%، بينما انخفض التصيّد بمساعدة الذكاء الاصطناعي 8.6% (Anthropic).
هذا هو الجزء الذي ينبغي أن يهتم به المدافعون. التصيّد مدخل. أما اكتشاف الحسابات، والحركة الجانبية، ورفع الصلاحيات، والوصول إلى بيانات الاعتماد، فهي أعمال ما بعد الاختراق. تتطلب سياقًا وتكيّفًا واختيارات تكتيكية. إذا كان استخدام الذكاء الاصطناعي ينزاح إلى هناك، فالنموذج لم يعد مجرد مولّد حمولات. بل صار جزءًا من حلقة المشغّل.
| إشارة من مجموعة بيانات Anthropic | الرقم |
|---|---|
| حسابات سيبرانية خبيثة محظورة جرى تحليلها | 832 |
| فترة الدراسة | مارس 2025 إلى مارس 2026 |
| أفعال خبيثة مرصودة جرى ربطها | 13,873 |
| تقنيات ATT&CK فرعية فريدة مرصودة | 482 |
| حسابات تستخدم الذكاء الاصطناعي لتطوير برمجيات خبيثة | 560، أو 67.3% |
| فاعلون بخطورة متوسطة أو أعلى، النصف الأول | 33% |
| فاعلون بخطورة متوسطة أو أعلى، النصف الثاني | 56% |
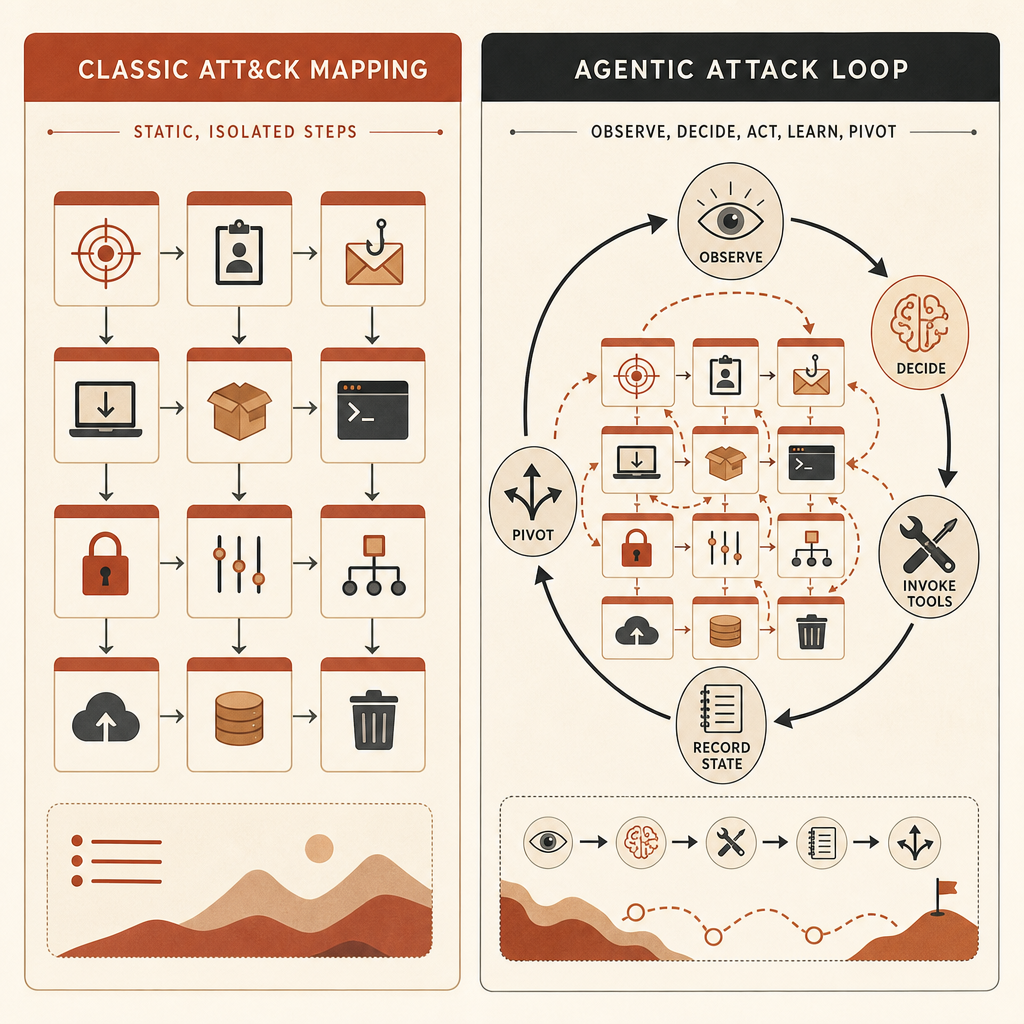
لماذا يبدأ MITRE ATT&CK بالانحناء
لا يزال MITRE ATT&CK ذا قيمة. تصفه MITRE بأنه قاعدة معرفة متاحة عالميًا لتكتيكات وتقنيات الخصوم استنادًا إلى ملاحظات من العالم الحقيقي، وتُستخدم لنماذج التهديد والمنهجيات عبر الصناعة والحكومة (MITRE). وهو يمنح الفرق معرّفات مشتركة لأشياء مثل تطوير البرمجيات الخبيثة T1587.001، واستخراج بيانات الاعتماد، واكتشاف الحسابات، وتنفيذ الأوامر، واستخراج البيانات.
المشكلة أن ATT&CK بارع أكثر في تسمية الحركات الذرّية. وادعاء Anthropic هو أن سلوك الذكاء الاصطناعي الخطر يقع بين تلك الحركات.
قد يقرر مشغّل بشري: افحص هذا المضيف، راجع هذه النتيجة، انتقل إلى بيانات الاعتماد هذه، جرّب هذا المسار الجانبي، ثم استخرج هذه الملفات. يستطيع ATT&CK ربط كل خطوة. لكن إذا كان إطار وكيلي هو الذي يتخذ القرارات، ويشغّل الأدوات، ويحدّث خطته، ويواصل بأقل تدخل بشري، فقد تبدو خريطة ATT&CK عادية بينما تكون العملية مختلفة نوعيًا.
مثال Anthropic هو حملة التجسس السيبراني التي تقول إنها عطّلتها في نوفمبر 2025. في تلك الحالة، استخدم الفاعل Claude Code في عملية تقول Anthropic إنها حاولت اختراق أهداف حول العالم بتدخل بشري ضئيل. عند ربطها بـATT&CK، استخدمت 30 تقنية عبر 13 تكتيكًا، وهي قابلة للمقارنة مع كثير من الفاعلين متوسطي الخطورة في مجموعة البيانات. لكن وفق نظام ARiES لدى Anthropic، سجلت 100، وهو الحد الأقصى (Anthropic).
هذا التباين هو القصة. عدد التقنيات يقول “متوسط تقريبًا”. التنفيذ الوكيلي يقول “حرج”.
منشور Frontier Red Team أكثر تحديدًا: الفاعل، الموسوم GTG-1002، استخدم Claude Code على Kali Linux ودمج أدوات اختبار اختراق مفتوحة المصدر كخوادم MCP، محوّلًا النموذج إلى منصة هجوم ذاتية بدلًا من مساعد كود (Anthropic Frontier Red Team). هذا بالضبط نوع السلوك الذي لا تزال معظم نماذج التهديد الداخلية تصفه وصفًا ناقصًا.
“الخطر السيبراني الوكيلي” بمصطلحات تشغيلية
تبدو العبارة مجردة. ليست كذلك. بالنسبة إلى فريق هندسي، يعني الخطر السيبراني الوكيلي أن لدى المهاجم حلقة كهذه:
observe target state -> choose next tactic -> call tool -> parse result
-> update memory -> pivot or stop -> repeat without waiting for a humanتغيّر هذه الحلقة ثلاثة أشياء.
أولًا، تضغط الزمن. لم يعد الفاعل محدود المهارة بحاجة إلى فهم كل أداة بعمق إذا كان النموذج يستطيع اختيار الأوامر، وتفسير المخرجات، والتعافي من الأخطاء. وجدت Anthropic ارتباطًا ضعيفًا بين مهارة الفاعل الظاهرة وعدد التقنيات المستخدمة: إذ بلغ متوسط الفاعلين الأقل مهارة نحو 16 تقنية مميزة، بينما بلغ متوسط الأكثر مهارة نحو 20 (Anthropic).
ثانيًا، تجعل اختيار الواجهة أقل طمأنة. تقول Anthropic إن ما إذا كان الفاعل استخدم Claude Code أو API أو واجهة دردشة لم يرتبط بمستوى الخطورة. كان الفارق عالي الخطورة هو موضع تطبيق الفاعل للذكاء الاصطناعي داخل دورة حياة الهجوم، وما السقالات التي بناها حوله.
ثالثًا، تحوّل “الحواجز” إلى مشكلة أنظمة وقت تشغيل. الطلب المحجوب ضابط واحد. لكن وكيلًا طويل التشغيل لديه أدوات، وذاكرة، ومحاولات إعادة، ووصول إلى الصدفة، ووصول إلى المتصفح، وخوادم MCP، هو نظام موزع. قد يظهر الفعل الخطر عبر طلبات كثيرة. وهذا يفسر سبب ربط Anthropic لنماذج Fable 5 وMythos-class باحتفاظ بالبيانات لمدة 30 يومًا لأغراض مراقبة السلامة، قائلة إن البيانات تساعد على اكتشاف كسر الحماية متعدد الطلبات وأنماط سوء الاستخدام (Anthropic).
قد لا يعجب المطورين هذا النهج. ومشترو المؤسسات الذين لديهم التزامات بعدم الاحتفاظ بالبيانات يكرهونه حقًا. لكن من زاوية الكشف، حجة Anthropic متماسكة: المصنّف أحادي الدور لا يستطيع رؤية مخطط هجوم.
معركة المجتمع تدور حول الإنذارات الكاذبة والوصول
نقاش المطورين ليس “هل ينبغي للذكاء الاصطناعي أن يساعد المخترقين؟” لا أحد جاد يريد برمجيات خبيثة كخدمة. المعركة الحقيقية هي: من يحصل على النموذج الكامل، ومن يُخفَّض مستواه، وما مدى وضوح أدوات التحكم؟
على Hacker News، مزج نقاش Project Glasswing في أبريل بين التشكيك في تسويق Anthropic ومخاوف أكثر تحديدًا: إذا كان الوكيل المستخدم للأدوات مستمرًا، وموجهًا نحو هدف، ومتصلًا بأدوات حقيقية، فإن الخصائص نفسها التي تساعد أبحاث الثغرات تصبح خطرة إذا خرج الوكيل عن النص (Hacker News). هذه هي النسخة الناضجة من النقاش.
على Reddit، كانت شكاوى أسبوع الإطلاق أكثر خشونة. في أحد خيوط r/Anthropic، وصف مستخدم أنه طلب من Fable تدقيق مشروع، فجرى وسمه وخفضه إلى Opus، متسائلًا كيف يكون Fable مفيدًا إذا كان يتعثر بهذه السهولة (Reddit). وفي r/cybersecurity، ناقش المستخدمون شرط الاحتفاظ لمدة 30 يومًا وما إذا كان الحاجز فظًا أكثر من اللازم للعمل الأمني المشروع (Reddit).
التقطت TechCrunch الألم نفسه من باحثي الأمن. قال Matt Suiche للمنشور إن حتى طلبات الكود الآمن يمكن أن تُعامل كأمن سيبراني وتُخفّض، ووصف السلوك بأنه يبدو قائمًا على الكلمات المفتاحية (TechCrunch). ويقر منشور الإطلاق نفسه من Anthropic بأن الضوابط ضُبطت بتحفظ، وأنها ستلتقط أحيانًا طلبات غير ضارة.
ثم جاء تعليق 12 يونيو. قالت Anthropic إن التوجيه الحكومي أجبرها على تعطيل Fable 5 وMythos 5 لكل العملاء، رغم أنها لا توافق على أن احتمال كسر حماية ضيق ينبغي أن يبرر استدعاء نموذج تجاري (Anthropic). حوّل ذلك جدل المجتمع من “الإنذارات الكاذبة مزعجة” إلى “الوصول إلى النماذج أصبح الآن جزءًا من السياسة السيبرانية”.
موقفي: Anthropic محقة في أن الخطر السيبراني الوكيلي حقيقي، ومحقة أيضًا في أن مقاومة كسر الحماية الكاملة خيال. لكن التخفيضات الفظة تجربة مطور سيئة وضابط أمني سيئ إذا لم يستطع المدافعون توقع متى ستغيّر أدواتهم سلوكها. تحتاج فرق الأمن إلى توجيه شفاف، وسجلات تدقيق، وسير عمل عالي الخطورة معتمد، وأذونات أدوات محددة النطاق. لا تحتاج إلى تبديلات مفاجئة للنموذج في منتصف الاستجابة لحادث.
كيف تحدّث نموذج التهديد الداخلي لديك
إذا كانت شركتك تسمح بأدوات على نمط Claude Code، أو وكلاء شبيهين بـCursor، أو وكلاء ترميز داخليين، أو أتمتة LLM مدفوعة عبر API، فحدّث نموذج التهديد الآن. لا تنتظر MITRE حتى تصك معرّفات جديدة.
ابدأ بجرد الوكلاء. تتبع أي الوكلاء يمكنه قراءة المستودعات، وتشغيل أوامر الصدفة، وتصفح الأنظمة الداخلية، واستدعاء أدوات الفحص، وفتح التذاكر، أو الوصول إلى الأسرار. وحدة الخطر لم تعد “مستخدمًا لصق كودًا في الدردشة”. بل أصبحت “وكيلًا لديه أدوات وحالة وهدف”.
أضف كشف السقالات إلى القياسات لديك. سجّل استدعاءات الأدوات، وتسلسلات الأوامر، واستخدام خوادم MCP، وإعادات المحاولة، وقراءات الملفات، وطلبات الشبكة، وتغييرات الأذونات. قد يكون استدعاء nmap واحد طبيعيًا في مختبر. أما حلقة تفحص، وتفسّر، وتختار بيانات اعتماد، وتنتقل بين المضيفين، وتكتب النتائج إلى الذاكرة، فينبغي أن توقظ أحدًا.
افصل سير العمل الدفاعية عن الاستقلالية المفتوحة. النمط الجيد هو مهمة محدودة: “افحص هذا المستودع بحثًا عن مواضع SQL injection وقدّم ترقيعات مرشحة”، مع بيانات اعتماد للقراءة فقط ودون خروج شبكي. النمط السيئ هو “حقق في بيئة الاختبار لدينا وأصلح ما تجده”، مع وصول واسع إلى الصدفة وذاكرة مستمرة.
اربط تقنيات ATT&CK، لكن أضف فوقها “طبقة وكيلية” داخلية:
| الوسم الداخلي | ما الذي يجب تسجيله |
|---|---|
| تسلسل ذاتي | هل رتّب النموذج خطوات ATT&CK متعددة دون موافقة بشرية؟ |
| انتقال تكتيكي | هل اختار هدفًا جديدًا، أو بيانات اعتماد، أو مسار استغلال، أو أداة بناءً على مخرجات حية؟ |
| امتياز الأداة | ماذا كان يمكن للوكيل أن ينفذ، أو يقرأ، أو يعدل، أو يستخرج؟ |
| استخدام الذاكرة | هل ثبّت حالة الهدف، أو بيانات اعتماد، أو فرضيات، أو خطط؟ |
| نقاط تحقق بشرية | أي الخطوات تطلبت موافقة صريحة، وهل كانت الموافقات ذات معنى؟ |
بالنسبة إلى فرق منصات الذكاء الاصطناعي، الضابط العملي هو السياسة عند حد الأداة. لا تعتمد فقط على رفض النموذج. افرض قوائم سماح للأوامر. اطلب موافقات لفحص الشبكات، والوصول إلى بيانات الاعتماد، وتوليد إثباتات مفهوم للاستغلال، والتغييرات التدميرية. ضع الأسرار خلف وسطاء يمكنهم رفض وصول الوكيل افتراضيًا. حدّد معدل الحلقات الذاتية. احتفظ بسجل منشأ لكل تشغيل حتى يستطيع مراجع أمني إعادة تشغيل ما رآه الوكيل وما فعله.
بالنسبة إلى مهندسي الأمن، سؤال الكشف الجديد بسيط: “هل يستطيع مهاجم مبتدئ مع هذا الوكيل أن يتصرف كمشغّل خبير لمدة ساعة؟” إذا كانت الإجابة نعم، فصنّف سير العمل عالي الخطورة حتى عندما تبدو كل تقنية منفردة عادية.
الخلاصة المفيدة
من السهل إساءة قراءة تقرير Anthropic كشكوى من أن MITRE ATT&CK صار قديمًا. هذا تبسيط مخل. لا يزال ATT&CK يسمّي الحركات. المفردات الناقصة تخص قائد الأوركسترا.
تُظهر مجموعة بيانات 3 يونيو أن إساءة استخدام الذكاء الاصطناعي تتحرك أعمق داخل سلسلة القتل، من التحضير إلى نشاط ما بعد الاختراق. وتُظهر معركة Fable/Mythos لماذا يكون شحن دفاعات لهذا العالم فوضويًا: المطورون يريدون أدوات قوية، والمدافعون يحتاجون إلى وصول، والمورّدون يحتاجون إلى مراقبة، والحكومات باتت مستعدة للتدخل.
الرد الصحيح ليس الذعر، وليس التظاهر بأن الحواجز كافية. عامل السقالات الوكيلة كبنية تحتية. نمذج تهديدها. سجّلها. ضع سياسة حول استخدام الأدوات. أضف “التنسيق الذاتي” و“الانتقال التكتيكي في الوقت الحقيقي” إلى لغة الكشف الداخلية لديك اليوم، حتى قبل أن تمنحهما MITRE معرّفات تقنيات رسمية.
هامش صغير: يمكن للقراء الذين يريدون تجربة Claude Fable 5 بأنفسهم، عندما يتاح الوصول، استخدامه عبر Claude Fable 5 on OneHop، وهي نقطة نهاية بديلة مباشرة بسعر أقل بنحو 30% من السعر المعلن. تحصل الحسابات الجديدة على 10 دولارات مجانًا دون بطاقة عبر ابدأ مع 10 دولارات مجانًا.
قراءة إضافية: البدء مع Claude Fable 5.

