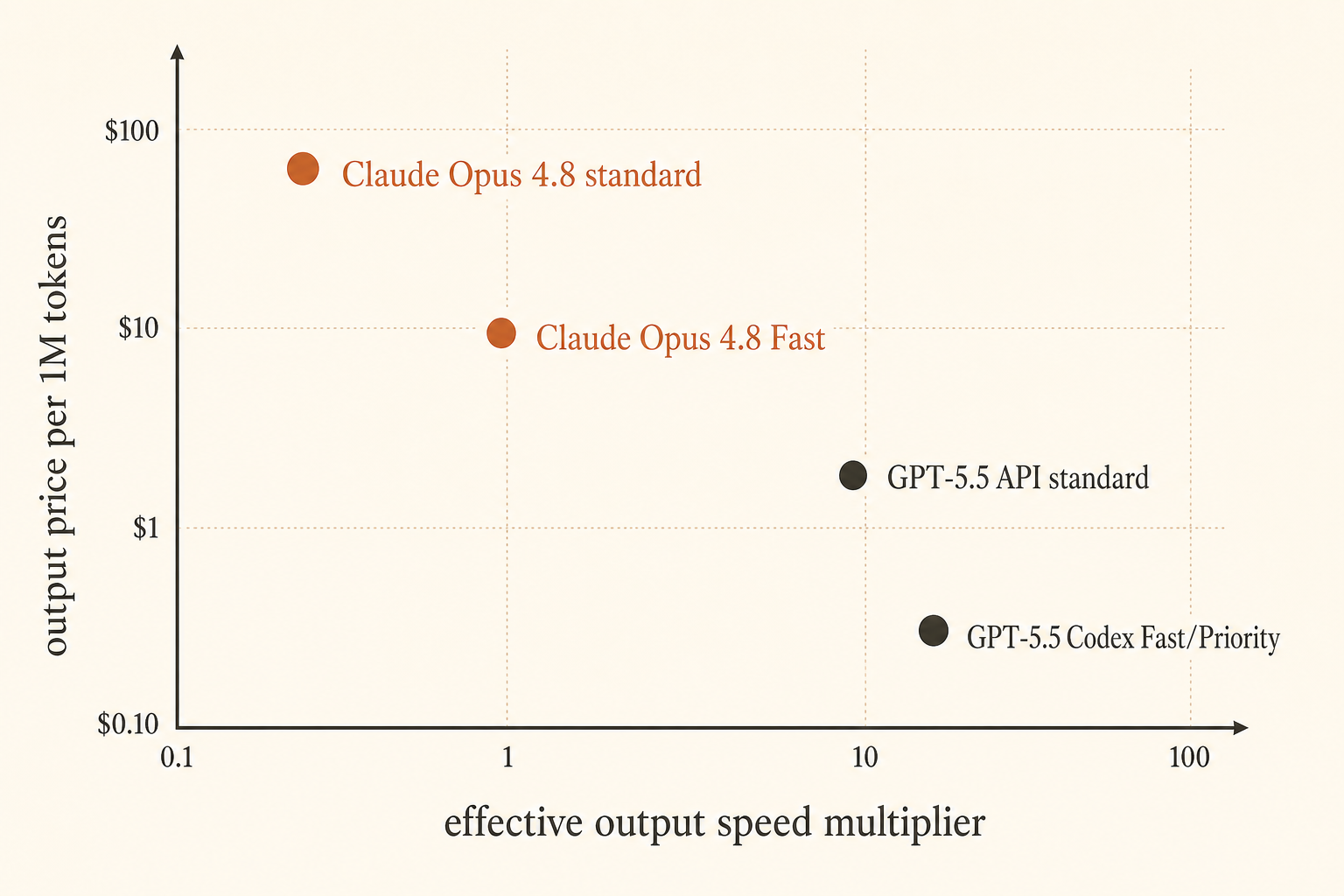
Anthropic 在 2026 年 5 月 28 日把定價問題變得更尖銳:Claude Opus 4.8 Fast Mode 現在最高可達 2.5× 速度,每百萬輸入 token 要價 10 美元、每百萬輸出 token 要價 50 美元(Anthropic)。OpenAI 則從另一個角度回應:Codex Fast Mode 裡的 GPT-5.5 生成 token 快 1.5×,成本是 2.5×;而 API 價格是每百萬 token 輸入 5 美元、輸出 30 美元,並且 1M context window 即將進到 API(OpenAI)。
這聽起來像供應商的數學遊戲,直到你坐在 IDE 裡,等一個 agent 完成第三次失敗的 patch 嘗試。那時延遲就不是 benchmark 的註腳了。它是你能不能維持心流,或乾脆打開 Slack 的分界線。
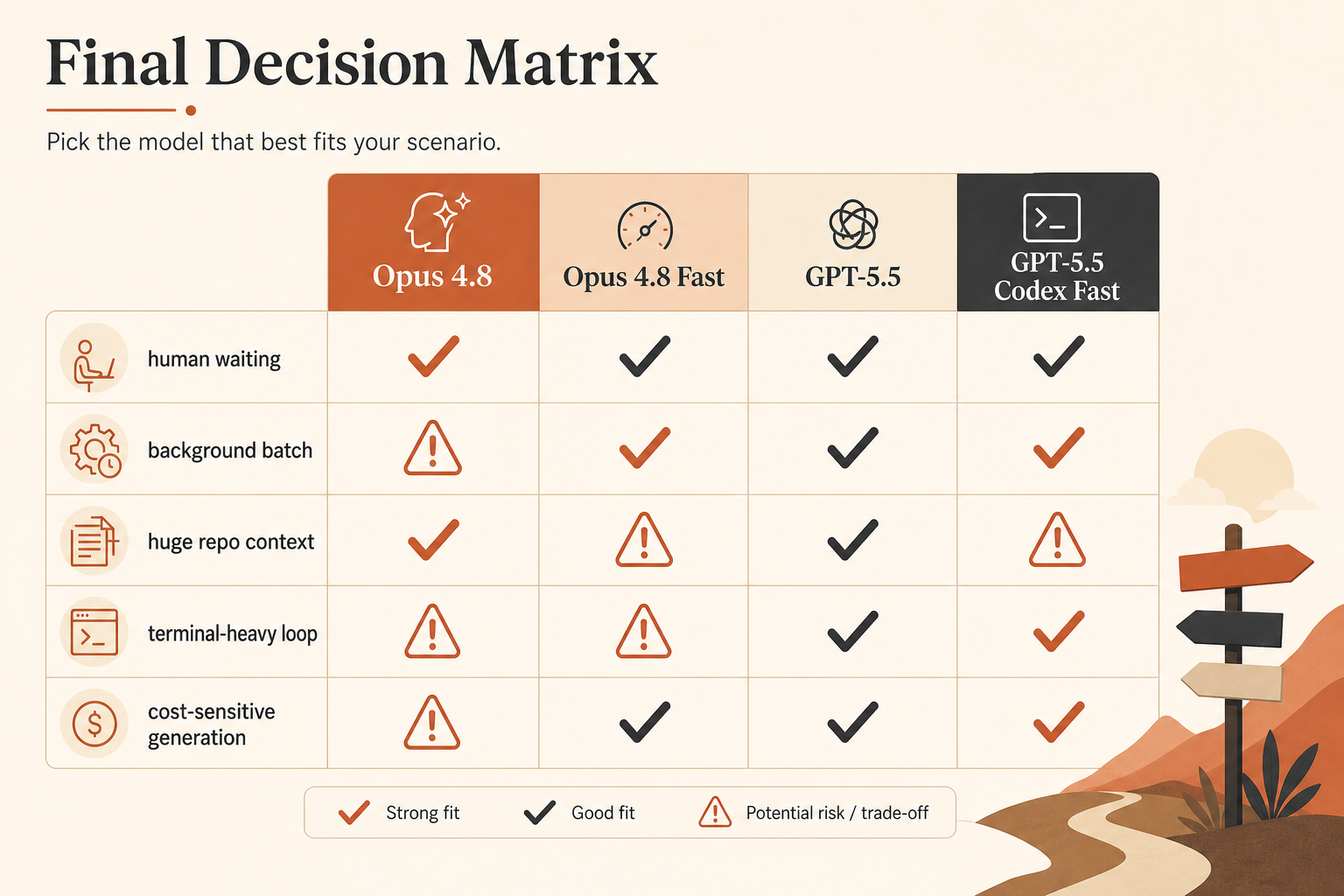
我的看法:對延遲敏感的寫程式工作,Opus 4.8 Fast Mode 是更乾淨俐落的速度購買。GPT-5.5 則是你想要較低輸出成本、強終端表現,以及更緊密 Codex 迴圈時更好的預設選擇。如果你的 agent 大多數時間都花在閱讀、規劃和呼叫工具,不要盲目買速度。先把迴圈修好。
真正該看的比較表
這是我在分流寫程式流量前,真的會拿來用的選擇表。
| Option | Published speed claim | Input price | Output price | Context | Best fit |
|---|---|---|---|---|---|
| Claude Opus 4.8 | 基準線 | $5/M | $25/M | Claude 文件中的 1M | 謹慎的 agentic coding、長 repo 脈絡 |
| Claude Opus 4.8 Fast Mode | 最高 2.5× 速度 | $10/M | $50/M | 完整 context;Fast 套用於整段 | human-in-the-loop 延遲 |
| GPT-5.5 API | 基準線 | $5/M | $30/M | 已宣布 1M API window | 一般寫程式、輸出價格低於 Opus Fast |
| GPT-5.5 Codex Fast Mode | 1.5× token 生成 | 2.5× Codex 成本 | 2.5× Codex 成本 | Codex 中 400K | UX 重要的快速 Codex sessions |
| GPT-5.5 API Priority-style math | 較高速層級 | $12.50/M | $75/M | 已宣布 1M API window | 佇列延遲重要的 production calls |
Anthropic 的定價文件補了兩個開發者常漏看的細節。第一,Fast Mode 仍在 research preview。第二,它會套用「across the full context window」,包括超過 200K token 的 request(Anthropic docs)。同一份文件也說 Claude Opus 4.8、Opus 4.7、Opus 4.6、Fable 5,以及 Mythos-class models,在標準定價下都包含完整 1M-token context。
OpenAI 的公開定價頁列出 GPT-5.5:每百萬輸入 5 美元、cached input 0.50 美元、輸出 30 美元(OpenAI pricing)。發表文章說 Codex 會拿到 GPT-5.5,搭配 400K context window,Fast Mode 則以 2.5× 成本換 1.5× generation speed。API 的故事是另一條線:GPT-5.5「soon」會在 Responses 和 Chat Completions 提供,並有 1M context window。
這個切分很重要。Codex Fast Mode 是產品模式的決策。GPT-5.5 API pricing 是 token 計量的決策。不要把它們混在同一張試算表裡,除非你把每一列標清楚。
為什麼開發者在抱怨
Reddit 上的抱怨一點都不含蓄。一串標題叫「Why is Opus 4.8 so slow?」的討論說,這個 model 感覺變差又變慢,其中一位留言者把這種變慢解讀成讓 Fast Mode 變現的手段(Reddit)。另一串 r/ClaudeCode 討論稱 Opus 4.8「smart, but careful and slow」,使用者則在爭論 high effort settings 才是不是真正元兇(Reddit)。另一串談 time-to-first-token 的討論則說,和 Codex 相比,體感回應速度是「night and day」(Reddit)。
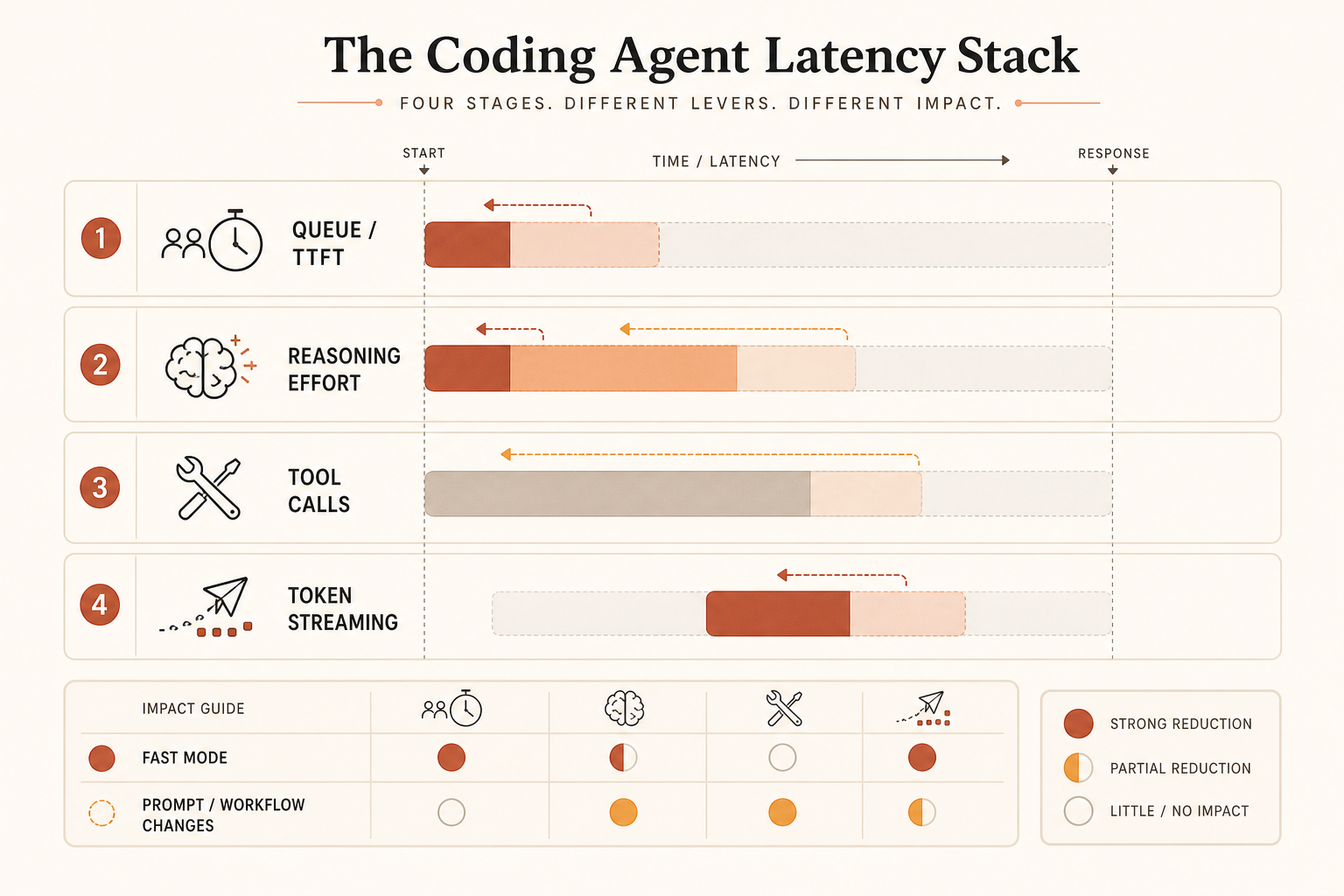
社群其實把四個不同問題混在一起:
- Time to first token。
- 每秒輸出 token 數。
- 隱藏 reasoning 或 effort 時間。
- 工具迴圈浪費:重讀檔案、重複 shell calls、過度規劃。
Fast Mode 主要打的是第二桶。它可能會視 serving capacity 改善第一桶,但公開宣稱的是輸出速度。如果你的 agent 在印出 300 個 token 前,花了 80 秒思考、讀檔、重試壞掉的命令,那花錢買更快輸出只是很弱的修補。
Anthropic 自己的發表文也暗示了這點。Opus 4.8 預設是 high effort,而 higher effort modes 會花更多時間思考,以換取更好的結果。Anthropic 建議在困難任務和長時間非同步工作流程中使用額外 effort(Anthropic)。這對 repo migrations 很合理。對「改名這個 prop 並更新測試」就很痛。
什麼時候花錢買速度是合理的
用一條簡單規則:只有在人被卡住,而且生成輸出夠大、足以讓 token streaming 成為主導因素時,才買 Fast Mode。
假設一段寫程式回應輸出 2,000 個 output tokens。如果標準 Opus 要花 100 秒串流這段輸出,而 Fast Mode 接近宣稱的 2.5×,串流時間會降到約 40 秒。你買回了一分鐘。以 Opus 4.8 的價格來看,該回應的輸出部分會從 0.05 美元變成 0.10 美元。當一位資深開發者正在等待時,這個交易很容易合理化。
現在換一種工作負載。model 花 70 秒讀檔和規劃,接著用 20 秒串流 400 個 token。2.5× 的串流改善大概只省 12 秒,不是 60 秒。你仍然付兩倍。Reddit 上的挫折感就是從這裡來的:大家感受到完整的延遲帳單,但付費速度功能可能只涵蓋其中一部分。
GPT-5.5 Codex Fast Mode 的形狀不同。公開倍數比較小:Codex 中以 2.5× 成本換 1.5× generation speed(OpenAI)。如果你是在最佳化每個串流 token 的純美元成本,這不誘人。但如果 Codex 有更好的 TTFT、更少 tool stalls,或對你的專案有更緊密的 edit-test loop,它仍然說得通。紙面上比較慢的 model,只要 harness 更好,體感就可能更快。
對延遲敏感的寫程式工作,量 wall-clock task time,不要量 tokens per second。指標應該是:
time_from_prompt_to_accepted_patch = planning + tool_calls + streaming + test_fix_retries如果 Fast Mode 只改善其中一項,它就不是完整答案。
什麼時候用 Opus 4.8 Fast
當任務需要 Opus 風格的判斷力,而你正坐在那裡等,就選 Claude Opus 4.8 Fast Mode。
好例子:
- merge 前審查高風險資料庫 migration。
- 重構大型 TypeScript surface,而且風格一致性很重要。
- 要 agent 檢查多個檔案、提出計畫,然後套用。
- 除錯 production 行為,錯誤但自信的 patch 比 token 更貴。
- 互動式 pair,你會一邊讀一邊看回應串流出來。
Anthropic 宣稱 Opus 4.8 相比前代,讓自己寫出的程式碼缺陷未經評論就通過的機率大約低四倍(Anthropic)。這才是對寫程式重要的品質宣稱。Fast Mode 不會讓粗心的 model 變謹慎。它是讓謹慎的 model 用起來沒那麼煩。
問題是價格。每百萬輸出 50 美元的 Opus 4.8 Fast,對冗長 agent traces、生成文件、反覆失敗 patch 來說很貴。你應該把它搭配嚴格 harness controls:小 diff、精簡回應、cached repo summaries,以及一條硬規則:model 必須先檢查再編輯。
如果你透過 aggregator 分流,上線前請檢查真正的協定和可用性。OneHop 的 Claude Fable 5 頁面目前列出官方價格為每百萬輸入 10 美元、輸出 50 美元,OneHop 折扣價為 3 美元與 15 美元,新帳號有 10 美元免費額度,並提供 Anthropic Messages endpoint:https://api.onehop.ai/anthropic;同一頁在我檢查時也標示該 model 暫時不可用(OneHop)。這表示安全做法是在切換 production traffic 前,先用你自己的帳號測試可用性。
真正的 Anthropic SDK 形狀:
from anthropic import Anthropic
client = Anthropic(
api_key="ONEHOP_KEY",
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Review this patch for risky edge cases."}],
)
print(message.content[0].text)如果你的帳號可用 Fable 5,Claude Fable 5 on OneHop 值得測,因為設定成本低,而且新帳號可以從 10 美元免費額度開始。只是別從一張定價卡就假設可用。呼叫 endpoint。
什麼時候用 GPT-5.5 Codex Fast
當你主要待在 Codex 裡,而且在乎整個迴圈勝過 token stream,就選 GPT-5.5 Codex Fast Mode。
OpenAI 的發表文回報 GPT-5.5 在 Terminal-Bench 2.0 達到 82.7%,相比之下 OpenAI 表格中的 GPT-5.4 是 75.1%,Claude Opus 4.7 是 69.4%(OpenAI)。供應商 benchmark 要小心看,但 Terminal-Bench 對 coding agents 有相關性,因為 shell 工作、環境處理、修復迴圈,正是很多「聰明」models 浪費時間的地方。
GPT-5.5 在標準 API 費率下,輸出也比 Opus Fast 便宜:每百萬 30 美元對 50 美元。如果你會生成大量程式碼、log、解釋和測試輸出,這個差距會複利。1M API context window 讓它在 API access 上線後可用於大型 repo workflows,而 Codex 的 400K window 對許多互動式 sessions 已經夠大。
GPT-5.5 Fast 較弱的情境是純速度經濟學。如果其他條件都一樣,為 1.5× 較快 generation 付 2.5× 費用不是好交換。但其他條件很少一樣。Codex 可能因為編輯更乾淨、命令跑得更好,或讓開發者維持更順的 review loop 而勝出。
用 GPT-5.5 Codex Fast 來處理:
- 有大量終端互動的 edit-test-fix loops。
- 生成輸出量很高的工作。
- 已經標準化使用 Codex 的團隊。
- 400K context 足夠的任務。
- Opus high-effort 行為感覺太慢或太謹慎的情況。
避免把它用在需要你能取得的最強長線審查判斷力的任務,或是把 2.5× Fast surcharge 套到大量背景工作。那些請 batch。OpenAI 說 Batch 和 Flex 可用標準 API 費率的一半,而 Priority processing 是標準的 2.5×(OpenAI)。這是很明顯的提示:sync paths 為 priority 付費;async paths 不該付。
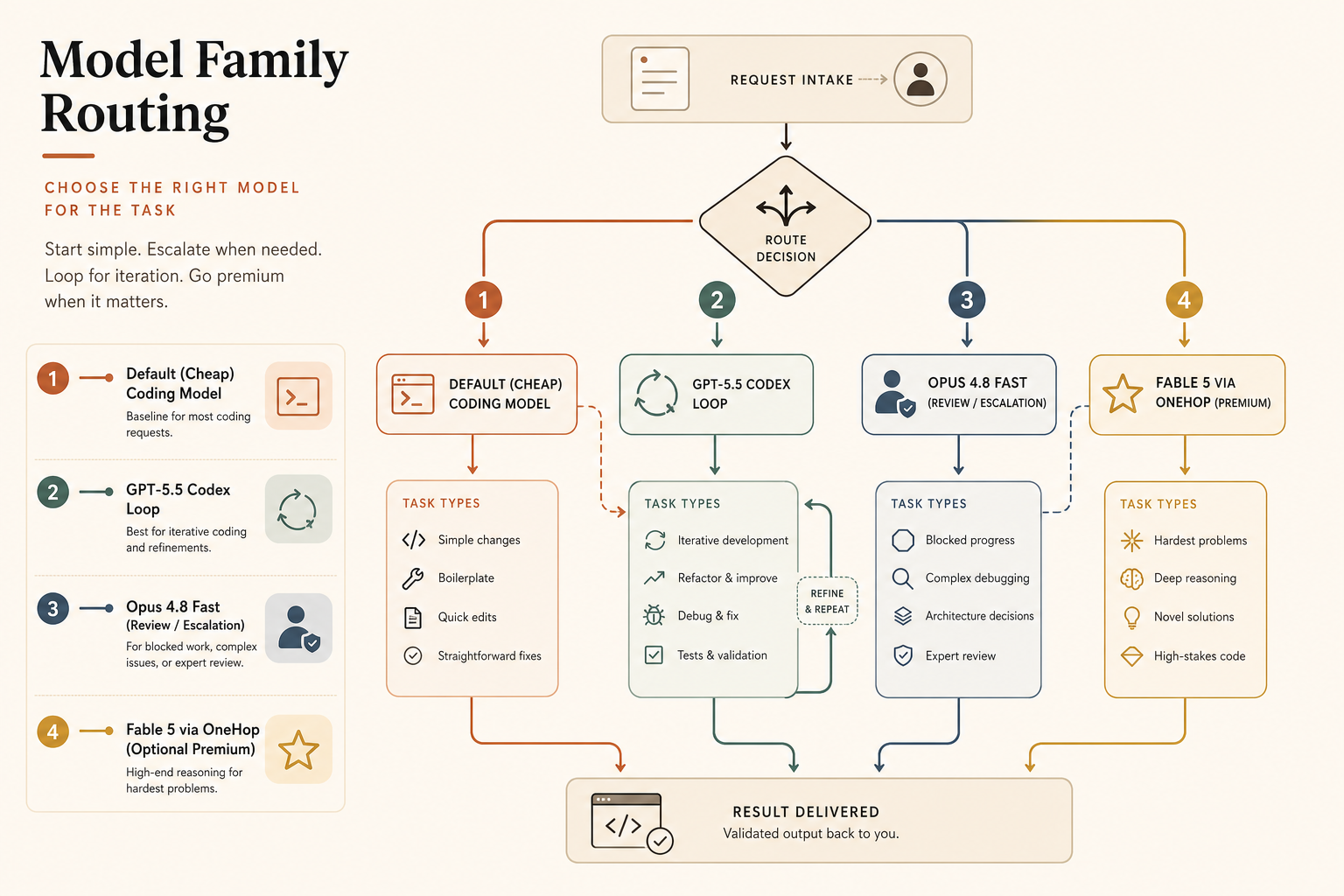
建議
大多數寫程式流量,預設用 GPT-5.5。它的 API list price 在輸出上低於 Opus 4.8 Fast,Codex 有聚焦寫程式的 UX,而且 1M API context window 移除了過去把所有長 context 都導向 Claude 的一個主要理由。
當人被卡住,而且品質比相較 GPT-5.5 standard 多出的每百萬輸出 20 美元更重要時,再升級到 Claude Opus 4.8 Fast。最佳使用情境不是「讓每個寫程式回應更快」。而是「讓昂貴、謹慎的答案在我失去脈絡前抵達」。
非同步深度工作保留標準 Opus 4.8。如果 model 正在跑 codebase migration、啟動 subagents,或分析數十萬行程式,速度不如正確性、快取和重試紀律重要。Anthropic 的 Dynamic Workflows feature 就是為這種大型任務打造的,包括跨數十萬行、以測試作為門檻的 migrations(Anthropic)。
把 OneHop-style routing 當成測試捷徑,不要當成跳過量測的藉口。如果你想用低設定摩擦試試高階 Claude routing,查看 Claude Fable 5 on OneHop,確認目前可用性,並從 10 美元免費額度開始。量每美元 accepted patches 和 prompt-to-merge time。那才是你的團隊下週仍然會在乎的唯一 benchmark。