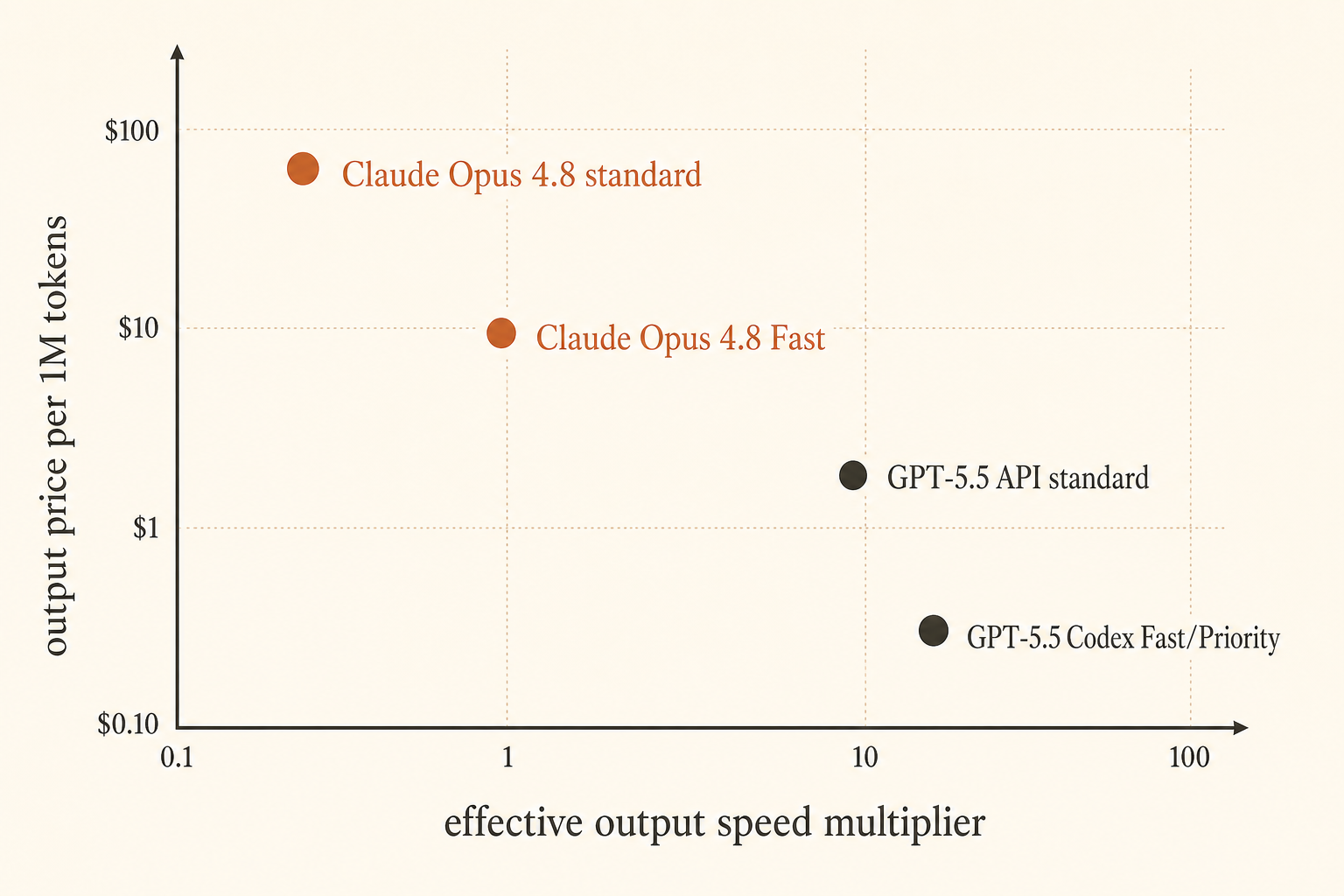
Anthropic afinó el problema de precios el 28 de mayo de 2026: Claude Opus 4.8 Fast Mode ahora corre hasta 2,5× más rápido y cuesta 10 dólares por millón de tokens de entrada y 50 dólares por millón de tokens de salida (Anthropic). OpenAI respondió desde otro ángulo: GPT-5.5 en Codex Fast Mode genera tokens 1,5× más rápido por 2,5× el coste, mientras que el precio de la API es de 5 dólares de entrada y 30 dólares de salida por millón de tokens, con una ventana de contexto de 1M que llegará a la API (OpenAI).
Eso suena a matemáticas de proveedor hasta que estás en un IDE esperando a que un agente termine el tercer intento fallido de parche. Entonces la latencia no es una nota al pie en un benchmark. Es la diferencia entre seguir en flow y abrir Slack.
Mi lectura: para programación limitada por latencia, Opus 4.8 Fast Mode es la compra de velocidad más limpia. GPT-5.5 es el mejor valor por defecto cuando quieres menor coste de salida, buen rendimiento en terminal y un bucle de Codex más ajustado. Si tu agente pasa la mayor parte del tiempo leyendo, planificando y llamando herramientas, no compres velocidad a ciegas. Arregla el bucle primero.
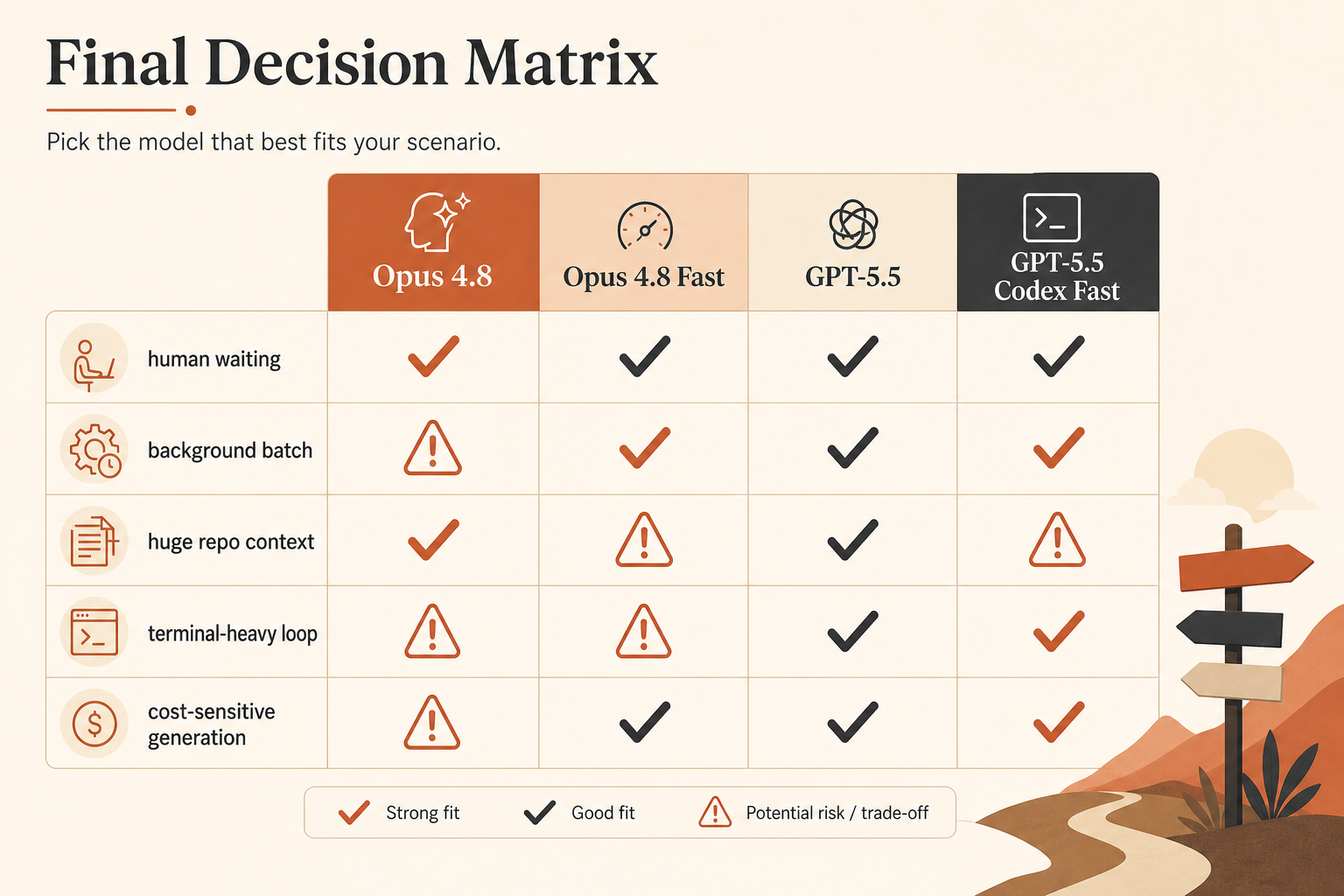
La tabla comparativa real
Esta es la tabla de selección que yo usaría de verdad antes de enrutar tráfico de programación.
| Opción | Promesa de velocidad publicada | Precio de entrada | Precio de salida | Contexto | Mejor uso |
|---|---|---|---|---|---|
| Claude Opus 4.8 | base | $5/M | $25/M | 1M en la documentación de Claude | programación agéntica cuidadosa, contexto largo de repositorio |
| Claude Opus 4.8 Fast Mode | hasta 2,5× de velocidad | $10/M | $50/M | contexto completo; Fast aplica en toda la ventana | latencia con humano esperando |
| GPT-5.5 API | base | $5/M | $30/M | ventana API de 1M anunciada | programación general, menor precio de salida que Opus Fast |
| GPT-5.5 Codex Fast Mode | generación de tokens 1,5× | 2,5× el coste de Codex | 2,5× el coste de Codex | 400K en Codex | sesiones rápidas de Codex donde la UX importa |
| GPT-5.5 API con lógica tipo Priority | nivel de mayor velocidad | $12.50/M | $75/M | ventana API de 1M anunciada | llamadas de producción donde importa la latencia de cola |
La documentación de precios de Anthropic añade dos detalles que los desarrolladores suelen pasar por alto. Primero, Fast Mode sigue en research preview. Segundo, aplica “en toda la ventana de contexto”, incluidas solicitudes de más de 200K tokens (documentación de Anthropic). Esa misma documentación dice que Claude Opus 4.8, Opus 4.7, Opus 4.6, Fable 5 y modelos de clase Mythos incluyen el contexto completo de 1M tokens al precio estándar.
La página pública de precios de OpenAI lista GPT-5.5 a $5/M de entrada, $0.50/M de entrada cacheada y $30/M de salida (precios de OpenAI). El anuncio dice que Codex recibe GPT-5.5 con una ventana de contexto de 400K y Fast Mode a 1,5× de velocidad de generación por 2,5× el coste. La historia de la API va aparte: GPT-5.5 estará disponible “pronto” en Responses y Chat Completions con una ventana de contexto de 1M.
Esa separación importa. Codex Fast Mode es una decisión de modo de producto. El precio de GPT-5.5 API es una decisión de contador de tokens. No los mezcles en una hoja de cálculo salvo que etiquetes bien las filas.
Por qué se quejan los desarrolladores
La queja en Reddit no es sutil. Un hilo titulado “Why is Opus 4.8 so slow?” dice que el modelo se siente degradado y lento, con un comentarista planteando la ralentización como una forma de monetizar Fast Mode (Reddit). Otro hilo en r/ClaudeCode llama a Opus 4.8 “inteligente, pero cuidadoso y lento”, mientras los usuarios discuten si la verdadera culpa la tienen los ajustes de alto esfuerzo (Reddit). Otro hilo aparte sobre tiempo hasta el primer token dice que la comparación con Codex es “como la noche y el día” en capacidad de respuesta percibida (Reddit).
La comunidad está mezclando cuatro problemas distintos:
- Tiempo hasta el primer token.
- Tokens de salida por segundo.
- Tiempo oculto de razonamiento o esfuerzo.
- Desperdicio en el bucle de herramientas: releer archivos, llamadas redundantes a shell, exceso de planificación.
Fast Mode ataca sobre todo el segundo bloque. Puede ayudar al primero según la capacidad de servicio, pero la promesa pública es velocidad de salida. Si tu agente pasa 80 segundos pensando, leyendo archivos y reintentando comandos rotos antes de imprimir 300 tokens, pagar por salida más rápida es un parche flojo.
La propia nota de lanzamiento de Anthropic apunta a esto. Opus 4.8 usa alto esfuerzo por defecto, y los modos de mayor esfuerzo pasan más tiempo pensando para lograr mejores resultados. Anthropic recomienda esfuerzo extra para tareas difíciles y flujos asíncronos de larga duración (Anthropic). Tiene sentido para migraciones de repositorios. Es doloroso para “renombra esta prop y actualiza los tests”.
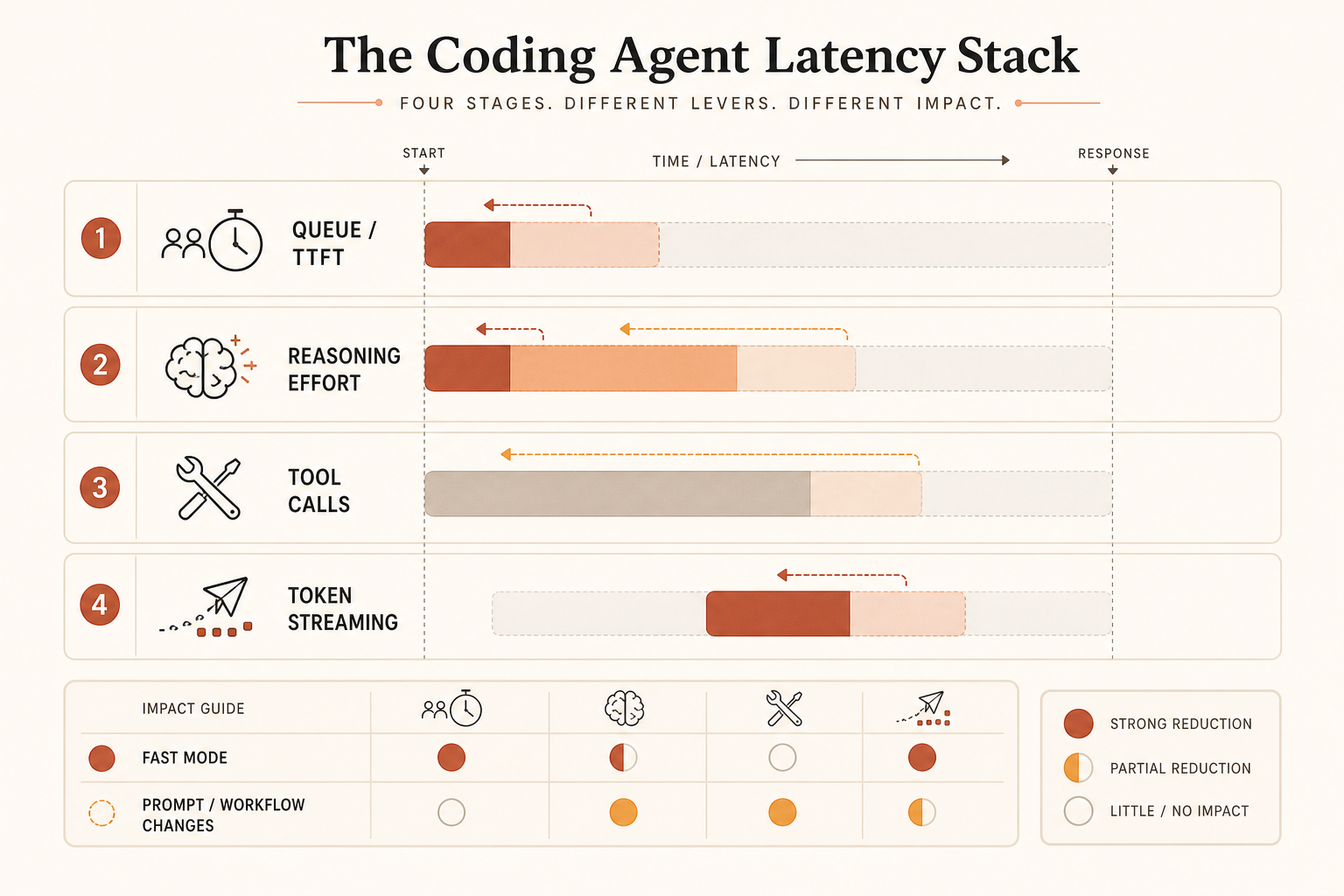
Cuándo tiene sentido pagar por velocidad
Usa una regla simple: compra Fast Mode solo cuando el humano está bloqueado y la salida generada es lo bastante grande como para que el streaming de tokens domine.
Supón que una respuesta de programación emite 2.000 tokens de salida. Si Opus estándar tarda 100 segundos en transmitir esa salida y Fast Mode se acerca al 2,5× anunciado, el tiempo de streaming baja a unos 40 segundos. Recuperaste un minuto. Con los precios de Opus 4.8, la parte de salida pasa de $0.05 a $0.10 para esa respuesta. Ese intercambio es fácil de justificar cuando un desarrollador senior está esperando.
Ahora cambia la carga de trabajo. El modelo pasa 70 segundos leyendo archivos y planificando, luego transmite 400 tokens en 20 segundos. Una mejora de 2,5× en streaming ahorra unos 12 segundos, no 60. Sigues pagando el doble. De ahí viene la frustración en Reddit: la gente siente toda la factura de latencia, pero la función de velocidad de pago quizá solo cubra una parte.
GPT-5.5 Codex Fast Mode tiene otra forma. El multiplicador publicado es menor: generación 1,5× más rápida por 2,5× el coste en Codex (OpenAI). No es atractivo si optimizas dólares puros por token transmitido. Aun así puede tener sentido si Codex tiene mejor TTFT, menos atascos de herramientas o un bucle de edición-test más ajustado para tu proyecto. Un modelo más lento sobre el papel puede sentirse más rápido cuando el harness es mejor.
Para programación limitada por latencia, mide el tiempo real de tarea, no tokens por segundo. La métrica debería ser:
time_from_prompt_to_accepted_patch = planning + tool_calls + streaming + test_fix_retriesSi Fast Mode solo mejora un término, no es toda la respuesta.
Usa Opus 4.8 Fast cuando…
Elige Claude Opus 4.8 Fast Mode cuando la tarea necesita criterio tipo Opus y tú estás ahí esperando.
Buenos ejemplos:
- Revisar una migración de base de datos arriesgada antes de hacer merge.
- Refactorizar una superficie grande de TypeScript donde importa la consistencia de estilo.
- Pedirle a un agente que inspeccione varios archivos, proponga un plan y luego lo aplique.
- Depurar comportamiento de producción donde un parche equivocado pero seguro de sí mismo cuesta más que los tokens.
- Programar en pareja de forma interactiva, leyendo la respuesta mientras se transmite.
Anthropic afirma que Opus 4.8 tiene unas cuatro veces menos probabilidades que su predecesor de dejar pasar sin comentario fallos en código que él mismo escribió (Anthropic). Esa es la afirmación de calidad importante para programación. Fast Mode no vuelve cuidadoso a un modelo descuidado. Hace que el modelo cuidadoso sea menos molesto de usar.
El precio es la trampa. A $50/M de salida, Opus 4.8 Fast es caro para trazas verbosas de agentes, documentación generada y parches fallidos repetidos. Deberías combinarlo con controles estrictos del harness: diffs pequeños, respuestas concisas, resúmenes cacheados del repo y una regla dura de que el modelo debe inspeccionar antes de editar.
Si enrutas mediante un agregador, comprueba el protocolo real y la disponibilidad antes de lanzar. La página de Claude Fable 5 de OneHop actualmente lista precios oficiales de $10/M de entrada y $50/M de salida, un precio con descuento de OneHop de $3/M y $15/M, $10 de crédito gratis para cuentas nuevas y un endpoint de Anthropic Messages en https://api.onehop.ai/anthropic; la misma página también marca el modelo como temporalmente no disponible en el momento en que la revisé (OneHop). Eso significa que lo seguro es probar disponibilidad en tu propia cuenta antes de cambiar tráfico de producción.
Forma real del SDK de Anthropic:
from anthropic import Anthropic
client = Anthropic(
api_key="ONEHOP_KEY",
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Review this patch for risky edge cases."}],
)
print(message.content[0].text)Si Fable 5 está disponible en tu cuenta, Claude Fable 5 en OneHop merece una prueba porque el coste de configuración es bajo y las cuentas nuevas pueden empezar con $10 gratis. Simplemente no asumas disponibilidad por una tarjeta de precios. Llama al endpoint.
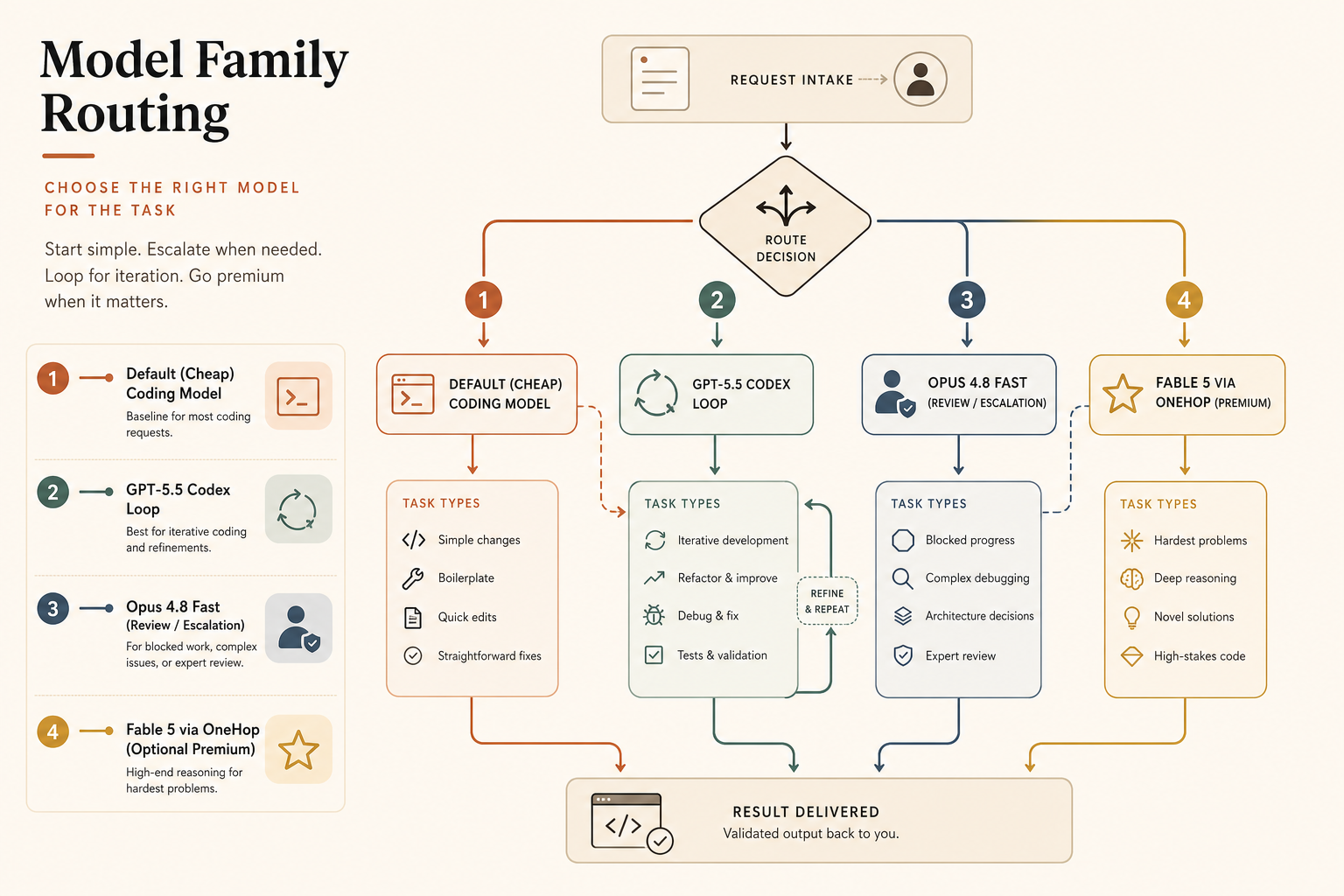
Usa GPT-5.5 Codex Fast cuando…
Elige GPT-5.5 Codex Fast Mode cuando vives dentro de Codex y te importa más el bucle completo que el stream de tokens.
El anuncio de OpenAI reporta GPT-5.5 con 82,7% en Terminal-Bench 2.0, frente al 75,1% de GPT-5.4 y el 69,4% de Claude Opus 4.7 en la tabla de OpenAI (OpenAI). Toma los benchmarks de proveedor con cuidado, pero Terminal-Bench es relevante para agentes de programación porque el trabajo de shell, el manejo del entorno y los bucles de reparación son donde muchos modelos “inteligentes” pierden tiempo.
GPT-5.5 también es más barato que Opus Fast en salida con tarifas estándar de API: $30/M frente a $50/M. Si generas mucho código, logs, explicaciones y salida de tests, esa diferencia se acumula. La ventana de contexto API de 1M lo hace viable para flujos de repositorios grandes cuando el acceso API esté activo, mientras que la ventana de 400K de Codex ya es lo bastante grande para muchas sesiones interactivas.
El caso débil de GPT-5.5 Fast es la economía de velocidad pura. Pagar 2,5× por generación 1,5× más rápida no es un gran intercambio si todo lo demás es igual. Casi nunca todo lo demás es igual. Codex puede ganar porque edita más limpio, ejecuta mejor los comandos o mantiene al desarrollador en un bucle de revisión más fluido.
Usa GPT-5.5 Codex Fast para:
- Bucles edición-test-arreglo con mucha interacción de terminal.
- Trabajo donde el volumen de salida generada es alto.
- Equipos ya estandarizados en Codex.
- Tareas donde 400K de contexto bastan.
- Casos donde el comportamiento de alto esfuerzo de Opus se siente demasiado lento o demasiado cauteloso.
Evítalo cuando la tarea necesita el criterio de revisión de largo horizonte más fuerte que puedas conseguir, o cuando el recargo Fast de 2,5× se aplica a trabajos masivos en segundo plano. Agrupa esos trabajos. OpenAI dice que Batch y Flex están disponibles a la mitad de la tarifa estándar de API, mientras que Priority processing cuesta 2,5× la tarifa estándar (OpenAI). Es una pista fuerte: las rutas síncronas pagan prioridad; las asíncronas no deberían.
La recomendación
Usa GPT-5.5 por defecto para la mayoría del tráfico de programación. Su precio de lista API es más bajo que Opus 4.8 Fast en salida, Codex tiene una UX enfocada en programación y la ventana de contexto API de 1M elimina una gran razón histórica para mandar todo lo de contexto largo a Claude.
Escala a Claude Opus 4.8 Fast cuando un humano está bloqueado y la calidad importa más que los $20 extra por millón de tokens de salida frente a GPT-5.5 estándar. El mejor caso de uso no es “hacer más rápida cada respuesta de programación”. Es “hacer que la respuesta cara y cuidadosa llegue antes de que pierda el contexto”.
Mantén Opus 4.8 estándar para trabajo profundo asíncrono. Si el modelo está ejecutando una migración de código base, lanzando subagentes o analizando cientos de miles de líneas, la velocidad importa menos que la corrección, el caching y la disciplina de reintentos. La función Dynamic Workflows de Anthropic está construida para ese tipo de tarea grande, incluidas migraciones sobre cientos de miles de líneas con tests como vara de medir (Anthropic).
Usa enrutamiento tipo OneHop como atajo de pruebas, no como excusa para saltarte la medición. Si quieres probar enrutamiento Claude de gama alta con poca fricción de configuración, revisa Claude Fable 5 en OneHop, confirma la disponibilidad actual y empieza con $10 gratis. Mide parches aceptados por dólar y tiempo de prompt a merge. Ese es el único benchmark que a tu equipo le seguirá importando la semana que viene.