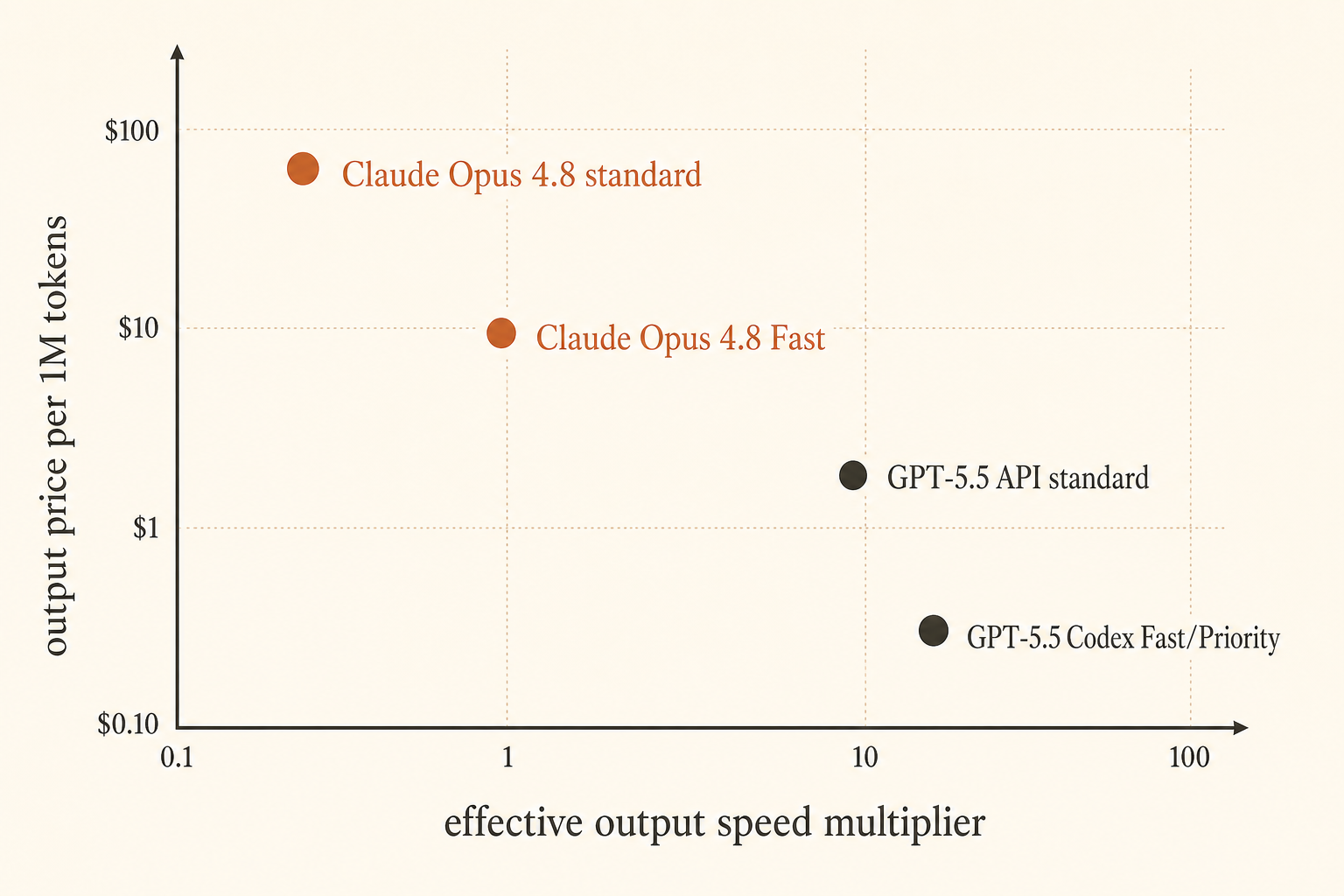
Anthropic сделала проблему цены заметно острее 28 мая 2026 года: Claude Opus 4.8 Fast Mode теперь работает до 2.5× быстрее и стоит $10 за миллион входных токенов и $50 за миллион выходных токенов (Anthropic). OpenAI ответила с другой стороны: GPT-5.5 в Codex Fast Mode генерирует токены в 1.5× быстрее за 2.5× стоимости, а цена API — $5 за вход и $30 за выход за миллион токенов, плюс в API появится контекстное окно на 1M (OpenAI).
Это звучит как арифметика вендоров, пока ты не сидишь в IDE и не ждёшь, когда агент закончит третью неудачную попытку патча. В этот момент задержка — уже не сноска в бенчмарке. Это разница между тем, чтобы остаться в потоке, и тем, чтобы открыть Slack.
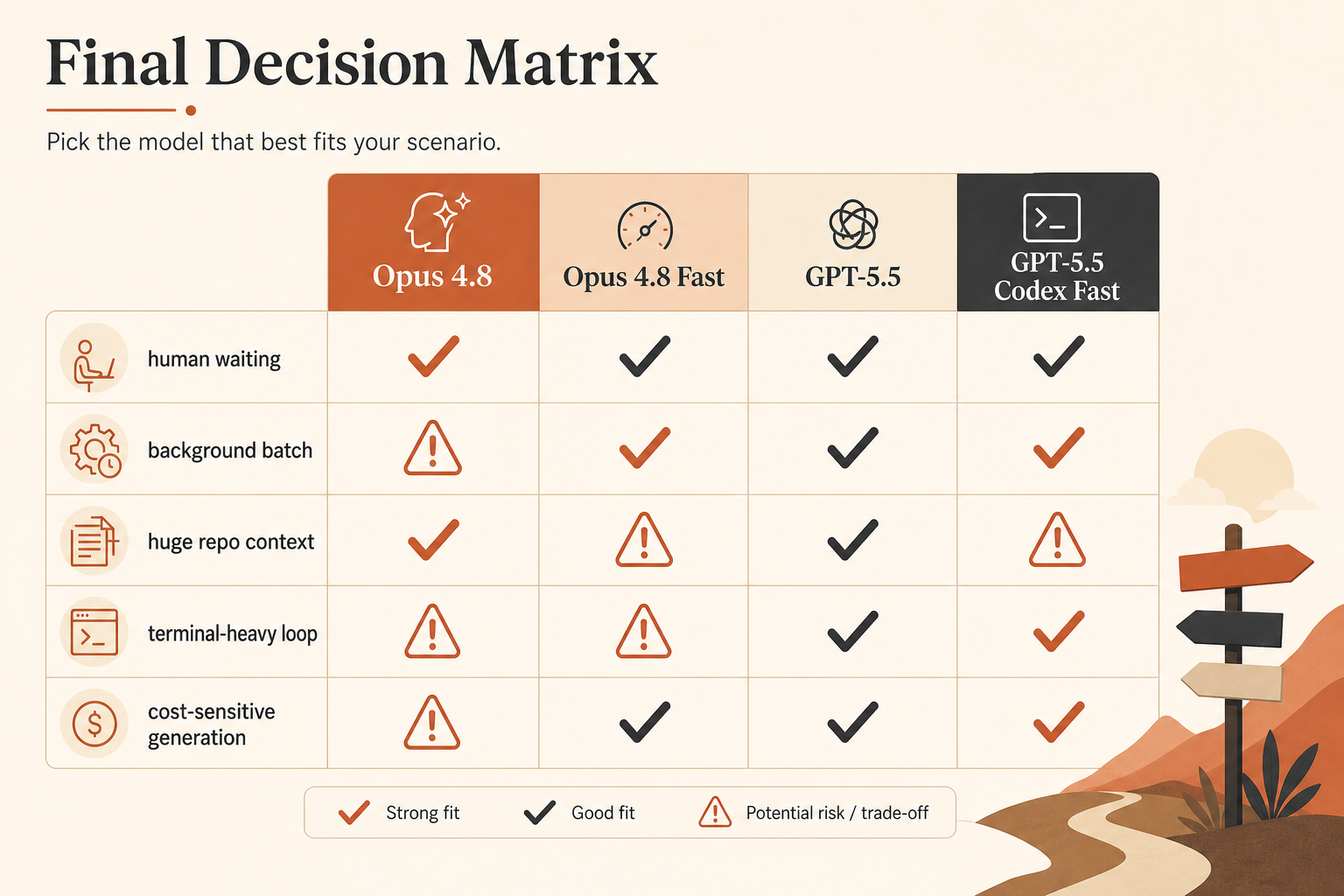
Мой вывод: для кодинга, упирающегося в задержки, Opus 4.8 Fast Mode — более чистая покупка скорости. GPT-5.5 — лучший дефолт, когда нужна более низкая стоимость выхода, сильная работа в терминале и более плотный цикл Codex. Если ваш агент большую часть времени читает, планирует и вызывает инструменты, не покупайте скорость вслепую. Сначала почините сам цикл.
Настоящая таблица сравнения
Вот таблица выбора, которой я бы реально пользовался перед маршрутизацией кодингового трафика.
| Option | Published speed claim | Input price | Output price | Context | Best fit |
|---|---|---|---|---|---|
| Claude Opus 4.8 | baseline | $5/M | $25/M | 1M в документации Claude | аккуратный агентный кодинг, длинный контекст репозитория |
| Claude Opus 4.8 Fast Mode | до 2.5× скорости | $10/M | $50/M | полный контекст; Fast применяется ко всему окну | задержка, когда человек ждёт в цикле |
| GPT-5.5 API | baseline | $5/M | $30/M | объявлено окно API на 1M | общий кодинг, более низкая цена выхода, чем у Opus Fast |
| GPT-5.5 Codex Fast Mode | 1.5× генерации токенов | 2.5× стоимости Codex | 2.5× стоимости Codex | 400K в Codex | быстрые сессии Codex, где важен UX |
| GPT-5.5 API Priority-style math | более быстрый тариф | $12.50/M | $75/M | объявлено окно API на 1M | продакшен-вызовы, где важна задержка очереди |
В документации Anthropic по ценам есть две детали, которые разработчики часто пропускают. Во-первых, Fast Mode всё ещё находится в research preview. Во-вторых, он применяется “across the full context window”, включая запросы больше 200K токенов (Anthropic docs). В тех же документах сказано, что Claude Opus 4.8, Opus 4.7, Opus 4.6, Fable 5 и модели класса Mythos включают полный 1M-токенный контекст по стандартной цене.
Публичная страница цен OpenAI указывает GPT-5.5 по $5/M за вход, $0.50/M за кэшированный вход и $30/M за выход (OpenAI pricing). В релизном посте сказано, что Codex получает GPT-5.5 с контекстным окном 400K и Fast Mode с 1.5× скоростью генерации за 2.5× стоимости. История с API отдельная: GPT-5.5 “soon” станет доступна в Responses и Chat Completions с контекстным окном 1M.
Это разделение важно. Codex Fast Mode — решение на уровне режима продукта. Цены GPT-5.5 API — решение на уровне счётчика токенов. Не смешивайте их в одной таблице, если не подписали строки.
Почему разработчики жалуются
Жалоба на Reddit довольно прямолинейная. Тред с названием “Why is Opus 4.8 so slow?” говорит, что модель ощущается деградировавшей и медленной, а один комментатор описывает замедление как способ монетизировать Fast Mode (Reddit). Другой тред в r/ClaudeCode называет Opus 4.8 “smart, but careful and slow”, а пользователи спорят, не являются ли настоящей причиной настройки высокого усилия (Reddit). Отдельный тред про time-to-first-token говорит, что сравнение с Codex — это “night and day” по ощущаемой отзывчивости (Reddit).
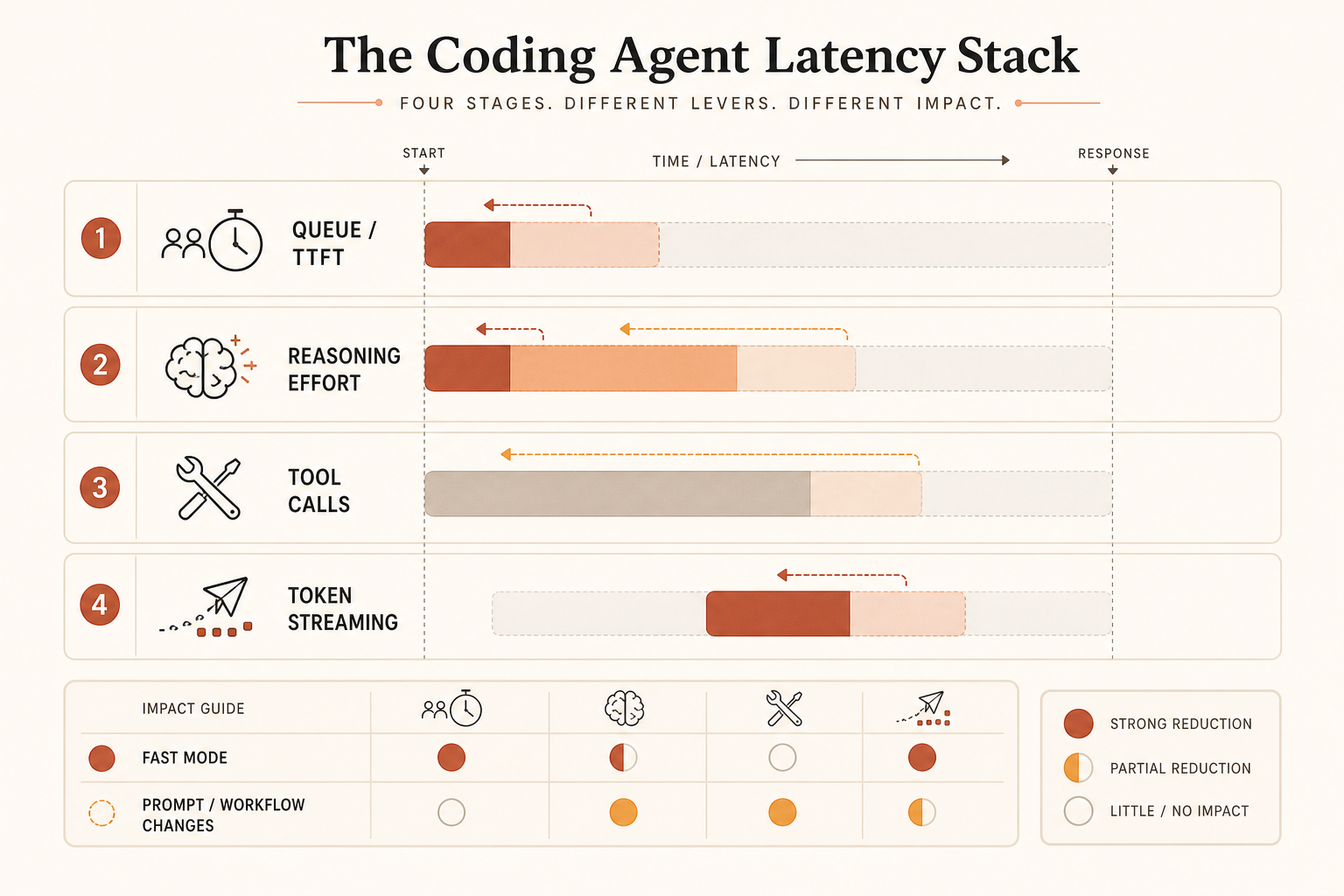
Сообщество смешивает четыре разные проблемы:
- Time to first token.
- Выходные токены в секунду.
- Скрытое рассуждение или время усилия.
- Потери в цикле инструментов: повторное чтение файлов, лишние вызовы shell, чрезмерное планирование.
Fast Mode в основном бьёт по второй категории. Он может помочь первой, если дело в серверной ёмкости, но публичное обещание — это скорость вывода. Если ваш агент 80 секунд думает, читает файлы и повторяет сломанные команды, прежде чем напечатать 300 токенов, платить за более быстрый вывод — слабое лекарство.
Собственная заметка Anthropic о запуске на это намекает. Opus 4.8 по умолчанию работает с высоким усилием, а режимы с более высоким усилием тратят больше времени на размышления ради лучшего результата. Anthropic рекомендует дополнительное усилие для сложных задач и долгих асинхронных рабочих процессов (Anthropic). Это разумно для миграций репозитория. И мучительно для “переименуй этот prop и обнови тесты”.
Когда платить за скорость рационально
Используйте простое правило: покупайте Fast Mode только тогда, когда человек заблокирован, а генерируемый вывод достаточно большой, чтобы стриминг токенов доминировал.
Допустим, кодинговый ответ выдаёт 2,000 выходных токенов. Если стандартный Opus стримит этот вывод 100 секунд, а Fast Mode приближается к заявленным 2.5×, время стриминга падает примерно до 40 секунд. Вы откупили назад одну минуту. По ценам Opus 4.8 выходная часть ответа растёт с $0.05 до $0.10. Это легко оправдать, когда ждёт senior-разработчик.
Теперь изменим нагрузку. Модель 70 секунд читает файлы и планирует, затем стримит 400 токенов за 20 секунд. Улучшение стриминга в 2.5× экономит примерно 12 секунд, а не 60. Вы всё равно платите вдвое. Отсюда и раздражение на Reddit: люди чувствуют весь счёт за задержку, но платная функция скорости может покрывать только его часть.
GPT-5.5 Codex Fast Mode устроен иначе. Опубликованный множитель меньше: генерация в 1.5× быстрее за 2.5× стоимости в Codex (OpenAI). Это не выглядит привлекательно, если вы оптимизируете чистые доллары за стриминговый токен. Но это всё ещё может иметь смысл, если у Codex лучше TTFT, меньше зависаний на инструментах или более плотный цикл edit-test для вашего проекта. Модель, которая на бумаге медленнее, может ощущаться быстрее, если обвязка лучше.
Для кодинга, упирающегося в задержки, измеряйте wall-clock время задачи, а не токены в секунду. Метрика должна быть такой:
time_from_prompt_to_accepted_patch = planning + tool_calls + streaming + test_fix_retriesЕсли Fast Mode улучшает только один член суммы, это не весь ответ.
Используйте Opus 4.8 Fast, когда…
Выбирайте Claude Opus 4.8 Fast Mode, когда задаче нужно суждение в стиле Opus, а вы сидите и ждёте.
Хорошие примеры:
- Ревью рискованной миграции базы данных перед merge.
- Рефакторинг большой поверхности TypeScript, где важна консистентность стиля.
- Просьба к агенту изучить несколько файлов, предложить план, затем применить его.
- Отладка продакшен-поведения, где уверенный неправильный патч стоит дороже токенов.
- Интерактивное парное программирование, когда вы читаете ответ прямо во время стриминга.
Anthropic утверждает, что Opus 4.8 примерно в четыре раза реже, чем предшественник, пропускает без комментариев недостатки в коде, который сам написал (Anthropic). Вот это важное заявление о качестве для кодинга. Fast Mode не делает небрежную модель аккуратной. Он делает аккуратную модель менее раздражающей в использовании.
Цена — вот подвох. При $50/M за выход Opus 4.8 Fast дорог для многословных агентных трасс, сгенерированной документации и повторных неудачных патчей. Его стоит сочетать с жёстким контролем в обвязке: маленькие diff, короткие ответы, кэшированные сводки репозитория и строгое правило, что модель обязана сначала посмотреть, а потом редактировать.
Если вы маршрутизируете через агрегатор, проверьте реальный протокол и доступность перед запуском. Страница OneHop для Claude Fable 5 сейчас указывает официальную цену $10/M за вход и $50/M за выход, скидочную цену OneHop $3/M и $15/M, $10 бесплатного кредита для новых аккаунтов и Anthropic Messages endpoint на https://api.onehop.ai/anthropic; на той же странице модель также помечена как временно недоступная на момент моей проверки (OneHop). Это значит, что безопасный ход — проверить доступность в собственном аккаунте, прежде чем переключать продакшен-трафик.
Реальная форма Anthropic SDK:
from anthropic import Anthropic
client = Anthropic(
api_key="ONEHOP_KEY",
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Review this patch for risky edge cases."}],
)
print(message.content[0].text)Если Fable 5 доступен в вашем аккаунте, Claude Fable 5 on OneHop стоит протестировать: цена входа низкая, а новые аккаунты могут начать с $10 бесплатно. Просто не считайте доступность гарантированной по карточке с ценой. Вызовите endpoint.
Используйте GPT-5.5 Codex Fast, когда…
Выбирайте GPT-5.5 Codex Fast Mode, когда живёте внутри Codex и вам важен весь цикл, а не только поток токенов.
В релизном посте OpenAI указано, что GPT-5.5 набирает 82.7% на Terminal-Bench 2.0, по сравнению с 75.1% у GPT-5.4 и 69.4% у Claude Opus 4.7 в таблице OpenAI (OpenAI). К вендорским бенчмаркам нужно относиться осторожно, но Terminal-Bench релевантен для кодинговых агентов: работа в shell, обращение с окружением и циклы исправления — именно там многие “умные” модели теряют время.
GPT-5.5 также дешевле Opus Fast по выходу на стандартных тарифах API: $30/M против $50/M. Если вы генерируете много кода, логов, объяснений и тестового вывода, эта разница накапливается. Контекстное окно API на 1M делает его пригодным для рабочих процессов с большими репозиториями, когда доступ к API станет активным, а окно Codex на 400K уже достаточно велико для многих интерактивных сессий.
Слабый аргумент за GPT-5.5 Fast — чистая экономика скорости. Платить 2.5× за генерацию быстрее в 1.5× — не лучшая сделка, если всё остальное одинаково. Но всё остальное редко одинаково. Codex может победить, потому что чище редактирует, лучше запускает команды или удерживает разработчика в более гладком цикле ревью.
Используйте GPT-5.5 Codex Fast для:
- Циклов edit-test-fix с большим количеством терминального взаимодействия.
- Работ, где объём генерируемого вывода высок.
- Команд, уже стандартизированных на Codex.
- Задач, где контекста 400K достаточно.
- Случаев, когда поведение Opus с высоким усилием кажется слишком медленным или слишком осторожным.
Избегайте его, когда задаче нужно максимально сильное долгогоризонтное ревью, которое вы можете получить, или когда надбавка Fast в 2.5× применяется к массовым фоновым задачам. Такие задачи батчите. OpenAI говорит, что Batch и Flex доступны за половину стандартной ставки API, а Priority processing стоит 2.5× стандарта (OpenAI). Это жирный намёк: синхронные пути платят за приоритет; асинхронные — не должны.
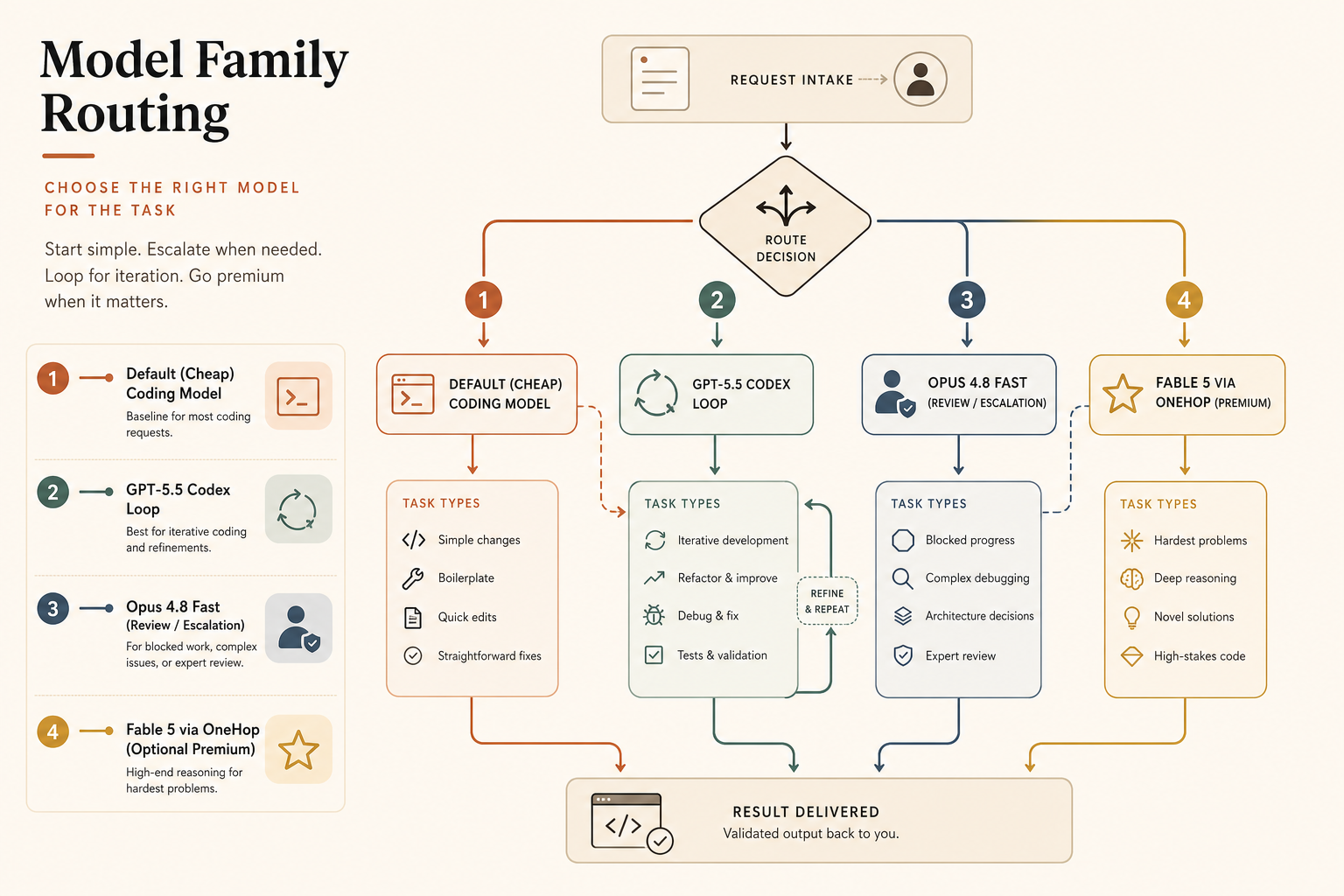
Рекомендация
По умолчанию используйте GPT-5.5 для большей части кодингового трафика. Его прайсовая цена API ниже, чем у Opus 4.8 Fast на выходе, у Codex сфокусированный UX для кодинга, а окно API на 1M убирает главную историческую причину отправлять весь длинноконтекстный трафик в Claude.
Эскалируйте в Claude Opus 4.8 Fast, когда человек заблокирован, а качество важнее лишних $20 за миллион выходных токенов относительно стандартного GPT-5.5. Лучший сценарий — не “ускорить каждый кодинговый ответ”. А “получить дорогой, аккуратный ответ до того, как я потеряю контекст”.
Оставьте стандартный Opus 4.8 для асинхронной глубокой работы. Если модель выполняет миграцию кодовой базы, запускает subagents или анализирует сотни тысяч строк, скорость менее важна, чем корректность, кэширование и дисциплина повторных попыток. Функция Dynamic Workflows у Anthropic построена именно для таких крупных задач, включая миграции по сотням тысяч строк, где тесты являются планкой качества (Anthropic).
Используйте маршрутизацию в стиле OneHop как быстрый способ тестирования, а не как повод пропустить измерения. Если хотите попробовать маршрутизацию в более старшие Claude с низким трением при настройке, проверьте Claude Fable 5 on OneHop, подтвердите текущую доступность и начните с $10 бесплатно. Измеряйте принятые патчи на доллар и время от prompt до merge. Это единственный бенчмарк, который будет важен вашей команде и на следующей неделе.