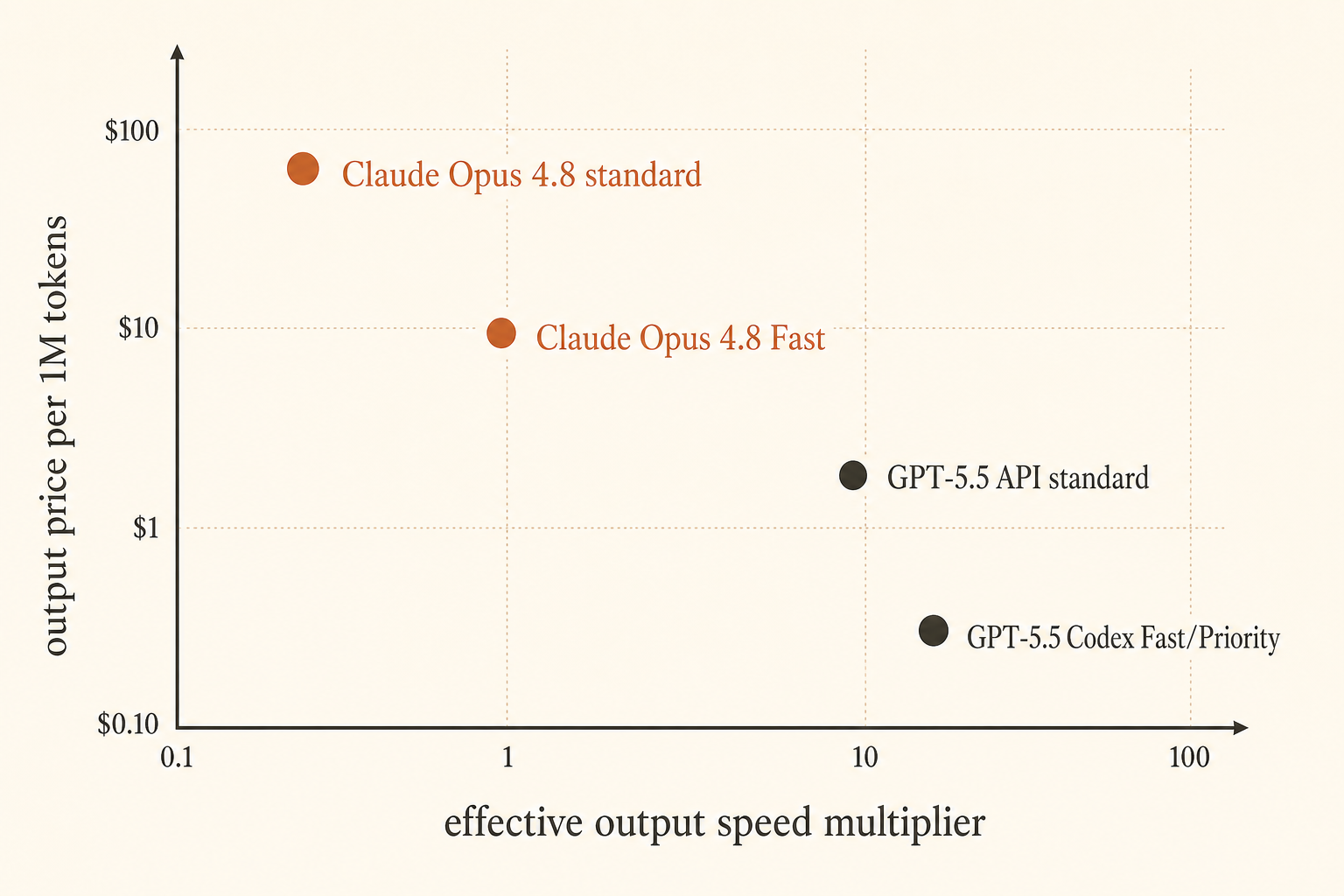
A Anthropic deixou o problema de preço mais evidente em 28 de maio de 2026: Claude Opus 4.8 Fast Mode agora roda a até 2,5× a velocidade e custa US$10 por milhão de tokens de entrada e US$50 por milhão de tokens de saída (Anthropic). A OpenAI respondeu por outro ângulo: GPT-5.5 no Codex Fast Mode gera tokens 1,5× mais rápido por 2,5× o custo, enquanto o preço da API é de US$5 na entrada e US$30 na saída por milhão de tokens, com uma janela de contexto de 1M chegando à API (OpenAI).
Isso parece matemática de fornecedor até você ficar sentado numa IDE esperando um agente terminar a terceira tentativa fracassada de patch. Aí latência não é nota de rodapé de benchmark. É a diferença entre continuar no fluxo e abrir o Slack.
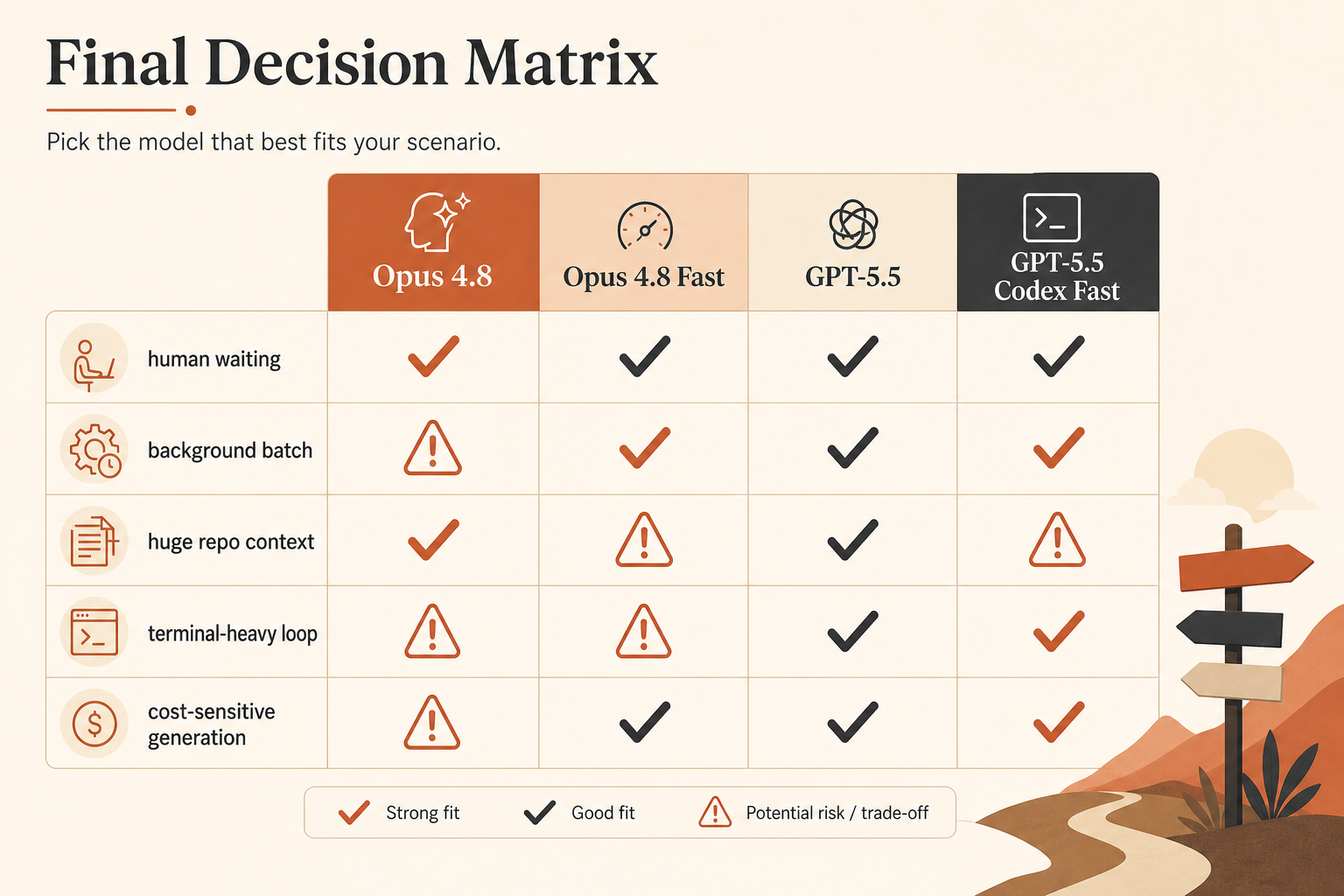
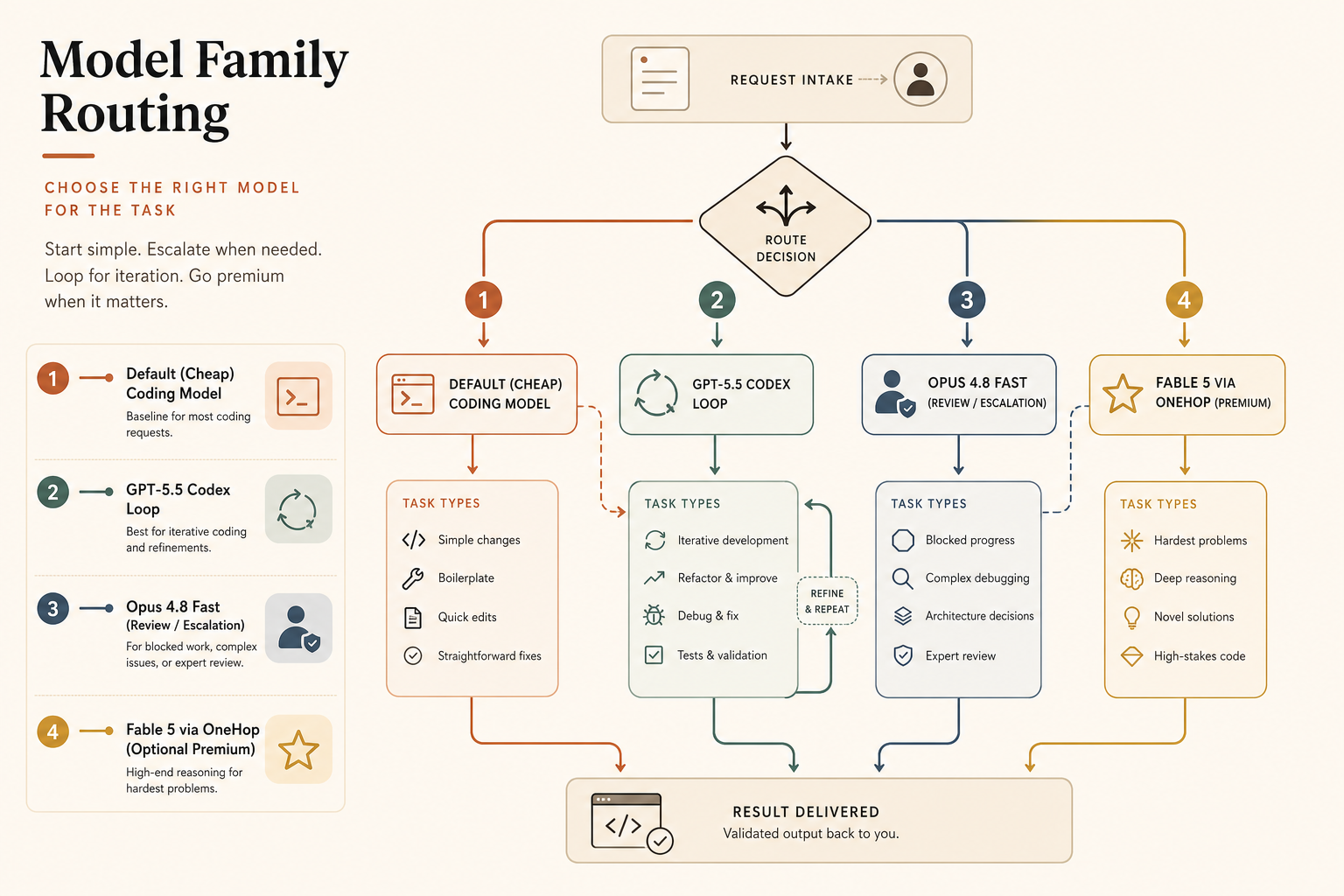
Minha leitura: para programação limitada por latência, Opus 4.8 Fast Mode é a compra de velocidade mais limpa. GPT-5.5 é o melhor padrão quando você quer menor custo de saída, forte desempenho no terminal e um loop Codex mais enxuto. Se o seu agente passa a maior parte do tempo lendo, planejando e chamando ferramentas, não compre velocidade no escuro. Conserte o loop primeiro.
A tabela de comparação de verdade
Esta é a tabela de seleção que eu realmente usaria antes de rotear tráfego de programação.
| Opção | Declaração pública de velocidade | Preço de entrada | Preço de saída | Contexto | Melhor uso |
|---|---|---|---|---|---|
| Claude Opus 4.8 | referência | US$5/M | US$25/M | 1M na documentação do Claude | programação agêntica cuidadosa, contexto longo de repositório |
| Claude Opus 4.8 Fast Mode | até 2,5× a velocidade | US$10/M | US$50/M | contexto completo; Fast se aplica a ele todo | latência com humano no loop |
| GPT-5.5 API | referência | US$5/M | US$30/M | janela de API de 1M anunciada | programação geral, menor preço de saída que Opus Fast |
| GPT-5.5 Codex Fast Mode | geração de tokens 1,5× | 2,5× o custo no Codex | 2,5× o custo no Codex | 400K no Codex | sessões rápidas no Codex em que a UX importa |
| Matemática estilo Priority da API GPT-5.5 | camada de maior velocidade | US$12,50/M | US$75/M | janela de API de 1M anunciada | chamadas de produção em que a latência de fila importa |
A documentação de preços da Anthropic acrescenta dois detalhes que desenvolvedores costumam ignorar. Primeiro, Fast Mode ainda está em research preview. Segundo, ele se aplica “em toda a janela de contexto”, incluindo requisições acima de 200K tokens (documentação da Anthropic). A mesma documentação diz que Claude Opus 4.8, Opus 4.7, Opus 4.6, Fable 5 e modelos da classe Mythos incluem o contexto completo de 1M de tokens no preço padrão.
A página pública de preços da OpenAI lista GPT-5.5 a US$5/M na entrada, US$0,50/M em entrada em cache e US$30/M na saída (preços da OpenAI). O post de lançamento diz que o Codex recebe GPT-5.5 com uma janela de contexto de 400K e Fast Mode com geração 1,5× mais rápida por 2,5× o custo. A história da API é separada: GPT-5.5 estará disponível “em breve” em Responses e Chat Completions com uma janela de contexto de 1M.
Essa separação importa. Codex Fast Mode é uma decisão de modo de produto. O preço da API GPT-5.5 é uma decisão de medição por token. Não misture os dois na mesma planilha sem rotular as linhas.
Por que desenvolvedores estão reclamando
A reclamação no Reddit não é sutil. Uma thread chamada “Why is Opus 4.8 so slow?” diz que o modelo parece pior e lento, com um comentarista enquadrando a lentidão como uma forma de monetizar o Fast Mode (Reddit). Outra thread no r/ClaudeCode chama Opus 4.8 de “inteligente, mas cuidadoso e lento”, enquanto usuários discutem se configurações de esforço alto são o verdadeiro culpado (Reddit). Uma thread separada sobre tempo até o primeiro token diz que a comparação com Codex é “da água para o vinho” em responsividade percebida (Reddit).
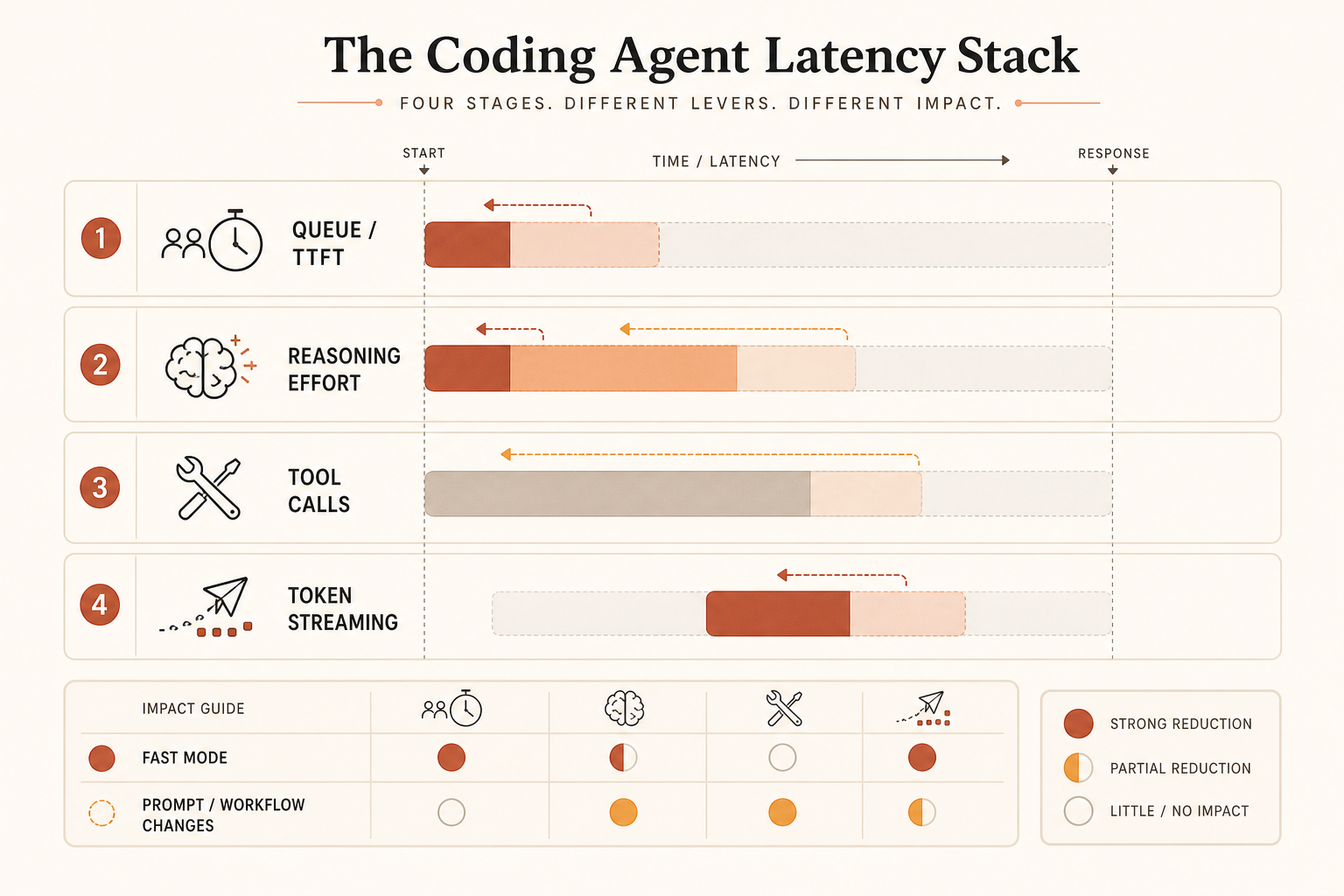
A comunidade está misturando quatro problemas diferentes:
- Tempo até o primeiro token.
- Tokens de saída por segundo.
- Tempo oculto de raciocínio ou esforço.
- Desperdício no loop de ferramentas: reler arquivos, chamadas de shell redundantes, planejamento excessivo.
Fast Mode ataca principalmente o segundo grupo. Ele pode ajudar no primeiro dependendo da capacidade de serviço, mas a promessa pública é velocidade de saída. Se o seu agente passa 80 segundos pensando, lendo arquivos e tentando de novo comandos quebrados antes de imprimir 300 tokens, pagar por saída mais rápida é uma correção fraca.
A própria nota de lançamento da Anthropic sugere isso. Opus 4.8 usa esforço alto por padrão, e modos de esforço maior passam mais tempo pensando para entregar resultados melhores. A Anthropic recomenda esforço extra para tarefas difíceis e fluxos de trabalho assíncronos de longa duração (Anthropic). Isso faz sentido para migrações de repositório. É doloroso para “renomeie esta prop e atualize os testes”.
Quando pagar por velocidade faz sentido
Use uma regra simples: compre Fast Mode só quando o humano estiver bloqueado e a saída gerada for grande o bastante para o streaming de tokens dominar.
Digamos que uma resposta de programação emita 2.000 tokens de saída. Se o Opus padrão leva 100 segundos para transmitir essa saída e o Fast Mode chega perto dos 2,5× anunciados, o tempo de streaming cai para cerca de 40 segundos. Você comprou de volta um minuto. Nos preços do Opus 4.8, a parte de saída passa de US$0,05 para US$0,10 nessa resposta. Essa troca é fácil de justificar quando um desenvolvedor sênior está esperando.
Agora mude a carga de trabalho. O modelo passa 70 segundos lendo arquivos e planejando, depois transmite 400 tokens em 20 segundos. Uma melhora de 2,5× no streaming economiza cerca de 12 segundos, não 60. Você ainda paga o dobro. É daí que vem a frustração no Reddit: as pessoas sentem a conta completa da latência, mas o recurso pago de velocidade talvez cubra só uma parte dela.
GPT-5.5 Codex Fast Mode tem outro formato. O multiplicador publicado é menor: geração 1,5× mais rápida por 2,5× o custo no Codex (OpenAI). Isso não é atraente se você está otimizando dólares puros por token transmitido. Ainda pode fazer sentido se o Codex tiver melhor TTFT, menos travas em ferramentas ou um loop de edição-teste mais justo para o seu projeto. Um modelo mais lento no papel pode parecer mais rápido quando o harness é melhor.
Para programação limitada por latência, meça o tempo de tarefa de ponta a ponta, não tokens por segundo. A métrica deve ser:
time_from_prompt_to_accepted_patch = planning + tool_calls + streaming + test_fix_retriesSe Fast Mode melhora só um termo, ele não é a resposta inteira.
Use Opus 4.8 Fast quando…
Escolha Claude Opus 4.8 Fast Mode quando a tarefa precisa do julgamento típico do Opus e você está ali sentado esperando.
Bons exemplos:
- Revisar uma migração arriscada de banco de dados antes do merge.
- Refatorar uma grande superfície TypeScript em que consistência de estilo importa.
- Pedir que um agente inspecione vários arquivos, proponha um plano e então aplique.
- Depurar comportamento em produção em que um patch confiante e errado custa mais que tokens.
- Parear de forma interativa, com você lendo a resposta conforme ela aparece.
A Anthropic afirma que Opus 4.8 tem cerca de quatro vezes menos probabilidade que seu antecessor de deixar passar sem comentário falhas no código que ele escreveu (Anthropic). Essa é a afirmação de qualidade importante para programação. Fast Mode não torna cuidadoso um modelo descuidado. Ele torna o modelo cuidadoso menos irritante de usar.
O preço é o porém. A US$50/M na saída, Opus 4.8 Fast é caro para rastros verbosos de agentes, documentação gerada e patches fracassados repetidos. Você deve combiná-lo com controles rígidos no harness: diffs pequenos, respostas concisas, resumos de repositório em cache e uma regra firme de que o modelo precisa inspecionar antes de editar.
Se você está roteando por um agregador, confira o protocolo real e a disponibilidade antes de colocar em produção. A página do Claude Fable 5 da OneHop lista atualmente preço oficial de US$10/M na entrada e US$50/M na saída, preço com desconto da OneHop de US$3/M e US$15/M, US$10 de crédito grátis para novas contas e um endpoint Anthropic Messages em https://api.onehop.ai/anthropic; a mesma página também marca o modelo como temporariamente indisponível no momento em que conferi (OneHop). Isso significa que o movimento seguro é testar a disponibilidade na sua própria conta antes de trocar o tráfego de produção.
Formato real do Anthropic SDK:
from anthropic import Anthropic
client = Anthropic(
api_key="ONEHOP_KEY",
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Review this patch for risky edge cases."}],
)
print(message.content[0].text)Se Fable 5 estiver disponível na sua conta, Claude Fable 5 na OneHop vale um teste porque o custo de setup é baixo e novas contas podem começar com US$10 grátis. Só não presuma disponibilidade a partir de um cartão de preços. Chame o endpoint.
Use GPT-5.5 Codex Fast quando…
Escolha GPT-5.5 Codex Fast Mode quando você vive dentro do Codex e se importa mais com o loop inteiro do que com o streaming de tokens.
O post de lançamento da OpenAI informa GPT-5.5 com 82,7% no Terminal-Bench 2.0, comparado a 75,1% para GPT-5.4 e 69,4% para Claude Opus 4.7 na tabela da OpenAI (OpenAI). Trate benchmarks de fornecedor com cuidado, mas Terminal-Bench é relevante para agentes de programação porque trabalho de shell, manejo de ambiente e loops de reparo são onde muitos modelos “inteligentes” perdem tempo.
GPT-5.5 também é mais barato que Opus Fast na saída em tarifas padrão de API: US$30/M contra US$50/M. Se você gera muito código, logs, explicações e saída de testes, essa diferença se acumula. A janela de contexto de 1M na API o torna viável para fluxos de trabalho em repositórios grandes assim que o acesso à API estiver ativo, enquanto a janela de 400K do Codex já é grande o suficiente para muitas sessões interativas.
O caso fraco para GPT-5.5 Fast é a economia de velocidade pura. Pagar 2,5× por geração 1,5× mais rápida não é uma ótima troca se todo o resto for igual. Todo o resto raramente é igual. Codex pode vencer porque edita melhor, executa comandos melhor ou mantém o desenvolvedor em um loop de revisão mais fluido.
Use GPT-5.5 Codex Fast para:
- Loops de editar-testar-corrigir com muita interação de terminal.
- Trabalhos em que o volume de saída gerada é alto.
- Equipes que já padronizaram em Codex.
- Tarefas em que 400K de contexto são suficientes.
- Casos em que o comportamento de alto esforço do Opus parece lento ou cauteloso demais.
Evite quando a tarefa precisa do julgamento de revisão de longo horizonte mais forte que você conseguir, ou quando a sobretaxa de 2,5× do Fast está sendo aplicada a trabalhos em lote em segundo plano. Agrupe esses trabalhos. A OpenAI diz que Batch e Flex estão disponíveis pela metade da tarifa padrão da API, enquanto Priority processing custa 2,5× o padrão (OpenAI). É uma pista forte: caminhos síncronos pagam por prioridade; caminhos assíncronos não deveriam.
A recomendação
Use GPT-5.5 como padrão para a maior parte do tráfego de programação. O preço de tabela da API é menor que o do Opus 4.8 Fast na saída, o Codex tem uma UX focada em programação, e a janela de contexto de 1M na API remove um grande motivo histórico para rotear tudo de contexto longo para Claude.
Escale para Claude Opus 4.8 Fast quando um humano estiver bloqueado e a qualidade importar mais que os US$20 extras por milhão de tokens de saída em relação ao GPT-5.5 padrão. O melhor caso de uso não é “deixar toda resposta de programação mais rápida”. É “fazer a resposta cara e cuidadosa chegar antes que eu perca o contexto”.
Mantenha o Opus 4.8 padrão para trabalho profundo assíncrono. Se o modelo está rodando uma migração de codebase, lançando subagentes ou analisando centenas de milhares de linhas, velocidade é menos importante que correção, cache e disciplina de novas tentativas. O recurso Dynamic Workflows da Anthropic foi criado para esse tipo de tarefa grande, incluindo migrações em centenas de milhares de linhas com testes como critério (Anthropic).
Use roteamento no estilo OneHop como atalho de teste, não como desculpa para pular a medição. Se você quer testar roteamento Claude de ponta com pouca fricção de setup, confira Claude Fable 5 na OneHop, confirme a disponibilidade atual e comece com US$10 grátis. Meça patches aceitos por dólar e tempo do prompt ao merge. Esse é o único benchmark com que a sua equipe ainda vai se importar na semana que vem.