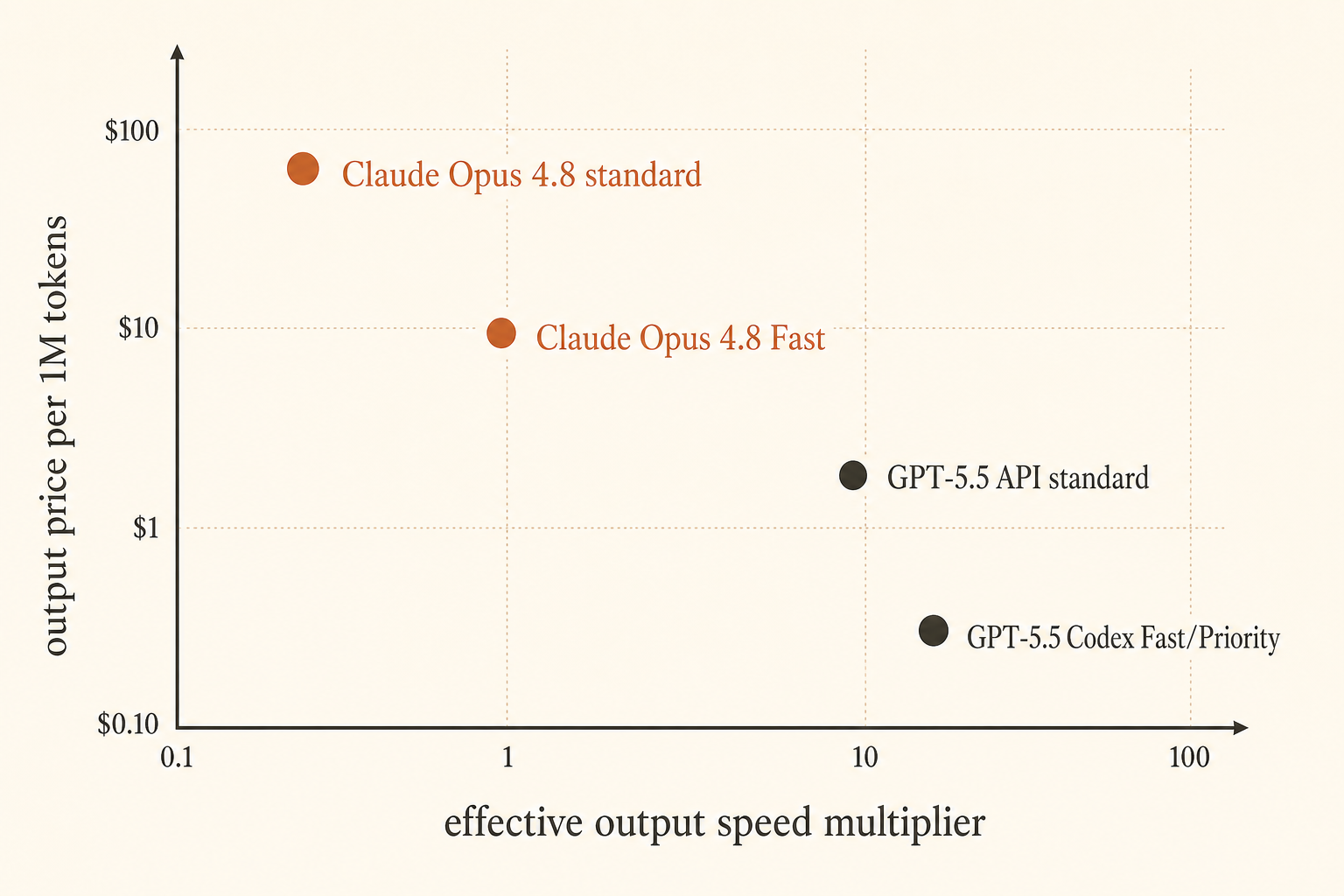
Anthropic made the pricing problem sharper on May 28, 2026: Claude Opus 4.8 Fast Mode now runs at up to 2.5× speed and costs $10 per million input tokens and $50 per million output tokens (Anthropic). OpenAI answered from a different angle: GPT-5.5 in Codex Fast Mode generates tokens 1.5× faster for 2.5× the cost, while the API price is $5 input and $30 output per million tokens with a 1M context window coming to the API (OpenAI).
That sounds like vendor math until you sit in an IDE waiting for an agent to finish the third failed patch attempt. Then latency is not a benchmark footnote. It is the difference between staying in flow and opening Slack.
My take: for latency-bound coding, Opus 4.8 Fast Mode is the cleaner speed purchase. GPT-5.5 is the better default when you want lower output cost, strong terminal performance, and a tighter Codex loop. If your agent spends most of its time reading, planning, and calling tools, do not buy speed blindly. Fix the loop first.
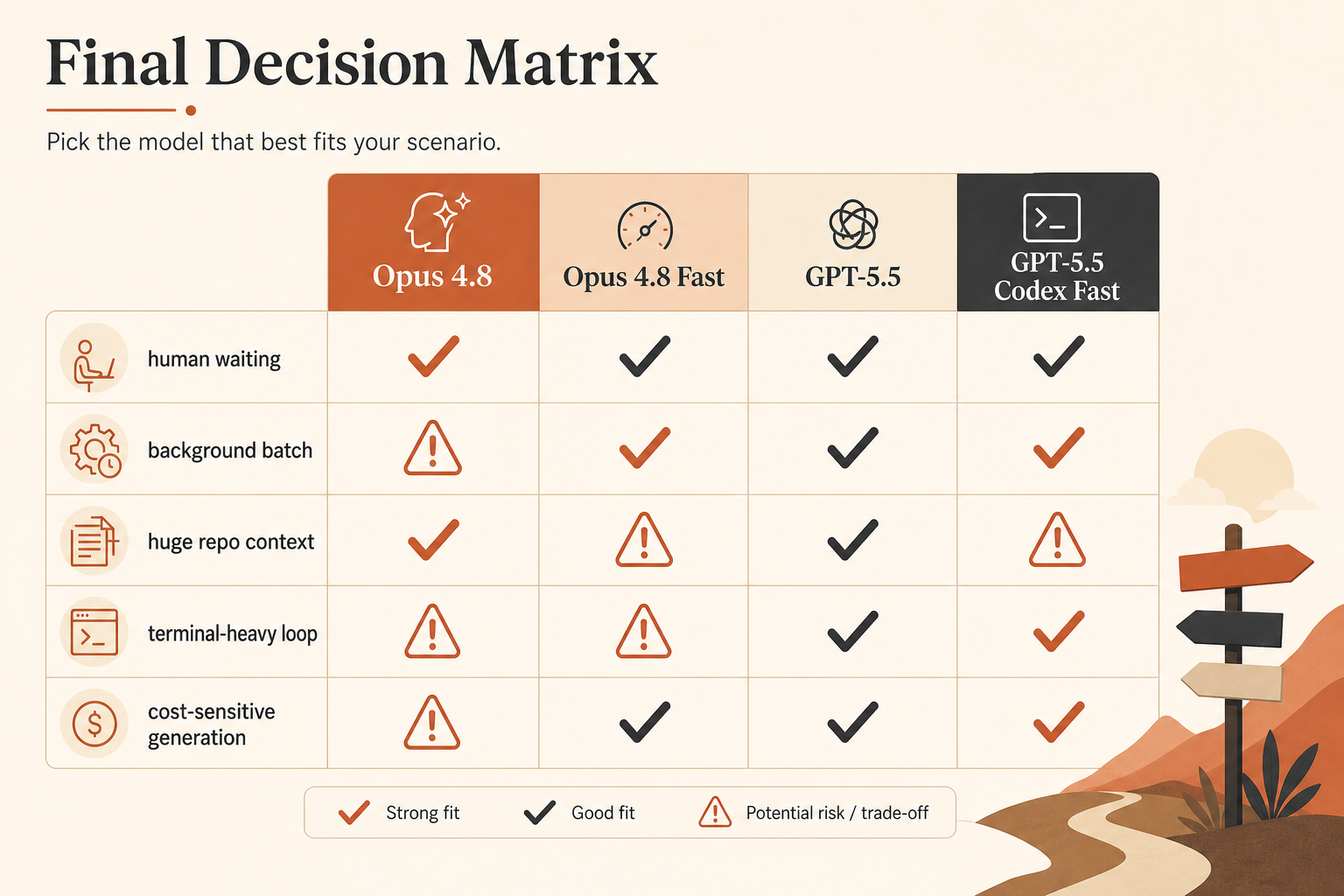
The Real Comparison Table
Here is the selection table I would actually use before routing coding traffic.
| Option | Published speed claim | Input price | Output price | Context | Best fit |
|---|---|---|---|---|---|
| Claude Opus 4.8 | baseline | $5/M | $25/M | 1M in Claude docs | careful agentic coding, long repo context |
| Claude Opus 4.8 Fast Mode | up to 2.5× speed | $10/M | $50/M | full context; Fast applies across it | human-in-the-loop latency |
| GPT-5.5 API | baseline | $5/M | $30/M | 1M API window announced | general coding, lower output price than Opus Fast |
| GPT-5.5 Codex Fast Mode | 1.5× token generation | 2.5× Codex cost | 2.5× Codex cost | 400K in Codex | fast Codex sessions where UX matters |
| GPT-5.5 API Priority-style math | higher-speed tier | $12.50/M | $75/M | 1M API window announced | production calls where queue latency matters |
Anthropic’s pricing docs add two details developers often miss. First, Fast Mode is still in research preview. Second, it applies “across the full context window,” including requests over 200K tokens (Anthropic docs). The same docs say Claude Opus 4.8, Opus 4.7, Opus 4.6, Fable 5, and Mythos-class models include the full 1M-token context at standard pricing.
OpenAI’s public pricing page lists GPT-5.5 at $5/M input, $0.50/M cached input, and $30/M output (OpenAI pricing). The launch post says Codex gets GPT-5.5 with a 400K context window and Fast Mode at 1.5× generation speed for 2.5× the cost. The API story is separate: GPT-5.5 is “soon” available in Responses and Chat Completions with a 1M context window.
That separation matters. Codex Fast Mode is a product-mode decision. GPT-5.5 API pricing is a token-meter decision. Do not mix them in a spreadsheet unless you label the rows.
Why Developers Are Complaining
The Reddit complaint is not subtle. A thread titled “Why is Opus 4.8 so slow?” says the model feels degraded and slow, with one commenter framing the slowdown as a way to monetize Fast Mode (Reddit). Another r/ClaudeCode thread calls Opus 4.8 “smart, but careful and slow,” while users argue about whether high effort settings are the real culprit (Reddit). A separate thread on time-to-first-token says the comparison with Codex is “night and day” for perceived responsiveness (Reddit).
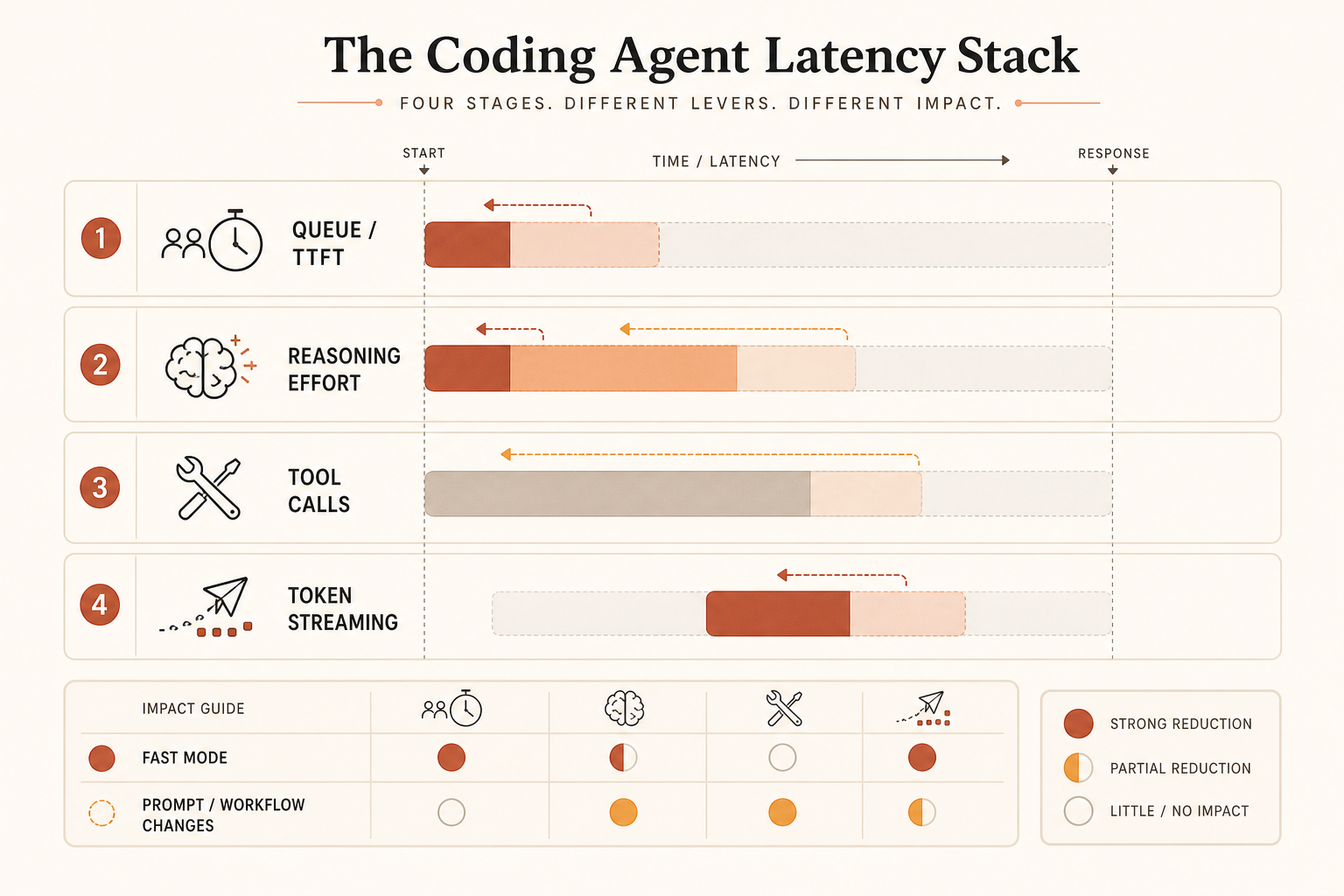
The community is mixing four separate issues:
- Time to first token.
- Output tokens per second.
- Hidden reasoning or effort time.
- Tool-loop waste: rereading files, redundant shell calls, over-planning.
Fast Mode mostly attacks the second bucket. It may help the first depending on serving capacity, but the public claim is output speed. If your agent spends 80 seconds thinking, reading files, and retrying broken commands before it prints 300 tokens, paying for faster output is a weak fix.
Anthropic’s own launch note hints at this. Opus 4.8 defaults to high effort, and higher effort modes spend more time thinking for better results. Anthropic recommends extra effort for difficult tasks and long-running asynchronous workflows (Anthropic). That is sensible for repo migrations. It is painful for “rename this prop and update tests.”
When Paying for Speed Is Rational
Use a simple rule: buy Fast Mode only when the human is blocked and the generated output is large enough for token streaming to dominate.
Say a coding response emits 2,000 output tokens. If standard Opus takes 100 seconds to stream that output and Fast Mode gets close to the advertised 2.5×, streaming time drops to about 40 seconds. You bought back one minute. At Opus 4.8 prices, the output portion moves from $0.05 to $0.10 for that response. That trade is easy to justify when a senior developer is waiting.
Now change the workload. The model spends 70 seconds reading files and planning, then streams 400 tokens in 20 seconds. A 2.5× streaming improvement saves roughly 12 seconds, not 60. You still pay double. That is where the Reddit frustration comes from: people feel the full latency bill, but the paid speed feature may only cover part of it.
GPT-5.5 Codex Fast Mode has a different shape. The published multiplier is smaller: 1.5× faster generation for 2.5× cost in Codex (OpenAI). That is not attractive if you are optimizing pure dollars per streamed token. It can still make sense if Codex has better TTFT, fewer tool stalls, or a tighter edit-test loop for your project. A slower model on paper can feel faster when the harness is better.
For latency-bound coding, measure wall-clock task time, not tokens per second. The metric should be:
time_from_prompt_to_accepted_patch = planning + tool_calls + streaming + test_fix_retriesIf Fast Mode improves only one term, it is not the whole answer.
Use Opus 4.8 Fast When…
Pick Claude Opus 4.8 Fast Mode when the task needs Opus-style judgment and you are sitting there waiting.
Good examples:
- Reviewing a risky database migration before merge.
- Refactoring a large TypeScript surface where style consistency matters.
- Asking an agent to inspect several files, propose a plan, then apply it.
- Debugging production behavior where a wrong confident patch costs more than tokens.
- Pairing interactively, with you reading the response as it streams.
Anthropic claims Opus 4.8 is around four times less likely than its predecessor to let flaws in code it wrote pass without comment (Anthropic). That is the important quality claim for coding. Fast Mode does not make a careless model careful. It makes the careful model less annoying to use.
The price is the catch. At $50/M output, Opus 4.8 Fast is expensive for verbose agent traces, generated docs, and repeated failed patches. You should pair it with strict harness controls: small diffs, concise responses, cached repo summaries, and a hard rule that the model must inspect before editing.
If you are routing via an aggregator, check the real protocol and availability before shipping. OneHop’s Claude Fable 5 page currently lists official pricing at $10/M input and $50/M output, a OneHop discounted price of $3/M and $15/M, $10 free credit for new accounts, and an Anthropic Messages endpoint at https://api.onehop.ai/anthropic; the same page also marks the model as temporarily unavailable at the time I checked (OneHop). That means the safe move is to test availability in your own account before swapping production traffic.
Real Anthropic SDK shape:
from anthropic import Anthropic
client = Anthropic(
api_key="ONEHOP_KEY",
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Review this patch for risky edge cases."}],
)
print(message.content[0].text)If Fable 5 is available in your account, Claude Fable 5 on OneHop is worth testing because the setup cost is low and new accounts can start with $10 free. Just do not assume availability from a pricing card. Call the endpoint.
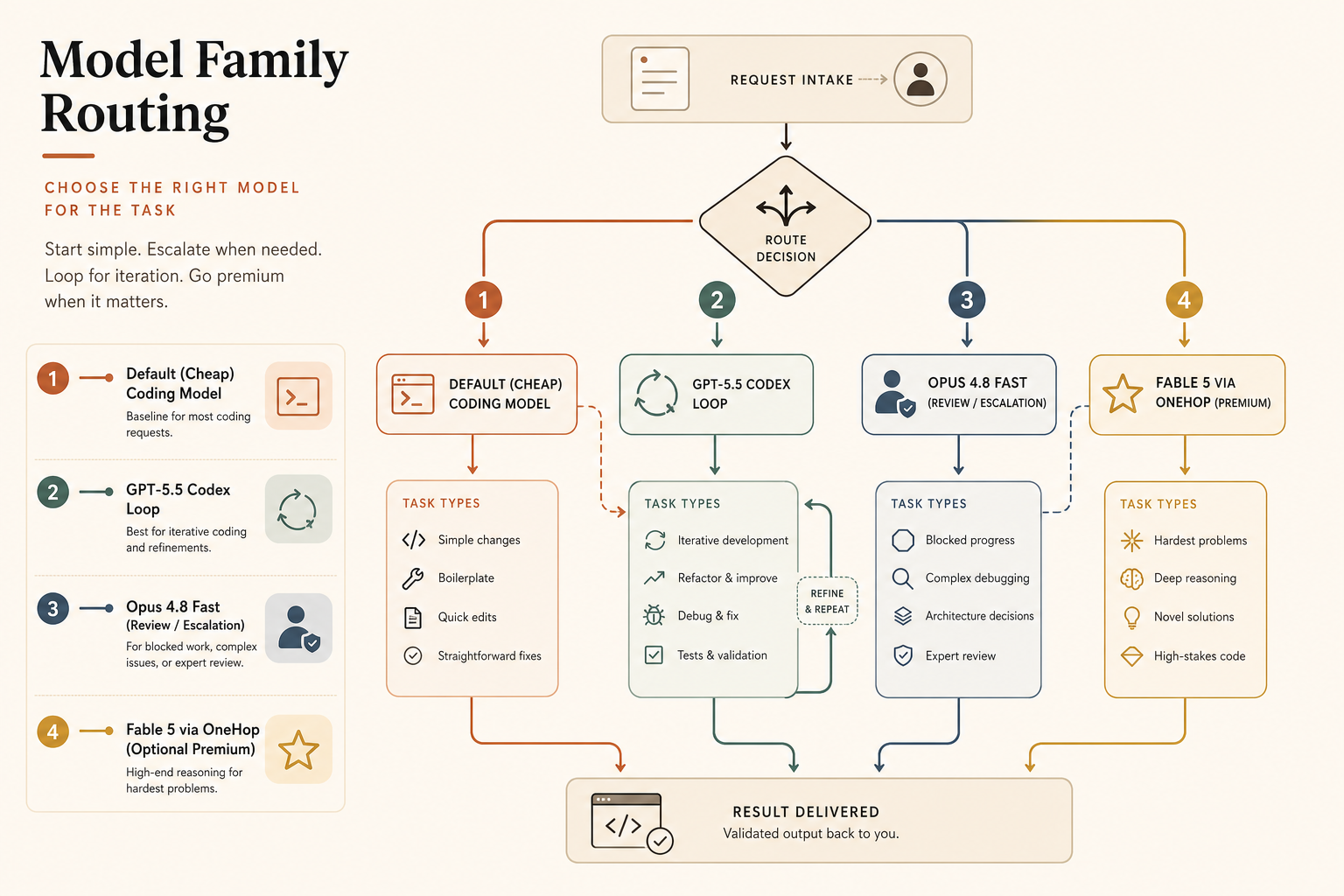
Use GPT-5.5 Codex Fast When…
Pick GPT-5.5 Codex Fast Mode when you live inside Codex and care about the whole loop more than the token stream.
OpenAI’s launch post reports GPT-5.5 at 82.7% on Terminal-Bench 2.0, compared with 75.1% for GPT-5.4 and 69.4% for Claude Opus 4.7 in OpenAI’s table (OpenAI). Treat vendor benchmarks carefully, but Terminal-Bench is relevant to coding agents because shell work, environment handling, and repair loops are where many “smart” models waste time.
GPT-5.5 is also cheaper than Opus Fast on output at standard API rates: $30/M versus $50/M. If you generate lots of code, logs, explanations, and test output, that gap compounds. The 1M API context window makes it viable for large-repo workflows once API access is live, while Codex’s 400K window is already large enough for many interactive sessions.
The weak case for GPT-5.5 Fast is pure speed economics. Paying 2.5× for 1.5× faster generation is not a great exchange if all else is equal. All else is rarely equal. Codex may win because it edits cleaner, runs commands better, or keeps the developer in a smoother review loop.
Use GPT-5.5 Codex Fast for:
- Edit-test-fix loops with lots of terminal interaction.
- Work where generated output volume is high.
- Teams already standardized on Codex.
- Tasks where 400K context is enough.
- Cases where Opus high-effort behavior feels too slow or too cautious.
Avoid it when the task needs the strongest long-horizon review judgment you can get, or when the 2.5× Fast surcharge is being applied to bulk background jobs. Batch those. OpenAI says Batch and Flex are available at half the standard API rate, while Priority processing is 2.5× standard (OpenAI). That is a strong hint: sync paths pay for priority; async paths should not.
The Recommendation
Default to GPT-5.5 for most coding traffic. Its API list price is lower than Opus 4.8 Fast on output, Codex has a focused coding UX, and the 1M API context window removes a major historical reason to route everything long-context to Claude.
Escalate to Claude Opus 4.8 Fast when a human is blocked and quality matters more than the extra $20 per million output tokens versus GPT-5.5 standard. The best use case is not “make every coding response faster.” It is “make the expensive, careful answer arrive before I lose context.”
Keep standard Opus 4.8 for asynchronous deep work. If the model is running a codebase migration, launching subagents, or analyzing hundreds of thousands of lines, speed is less important than correctness, caching, and retry discipline. Anthropic’s Dynamic Workflows feature is built for that kind of large task, including migrations across hundreds of thousands of lines with tests as the bar (Anthropic).
Use OneHop-style routing as a testing shortcut, not as an excuse to skip measurement. If you want to try higher-end Claude routing with low setup friction, check Claude Fable 5 on OneHop, confirm current availability, and start with $10 free. Measure accepted patches per dollar and prompt-to-merge time. That is the only benchmark your team will still care about next week.