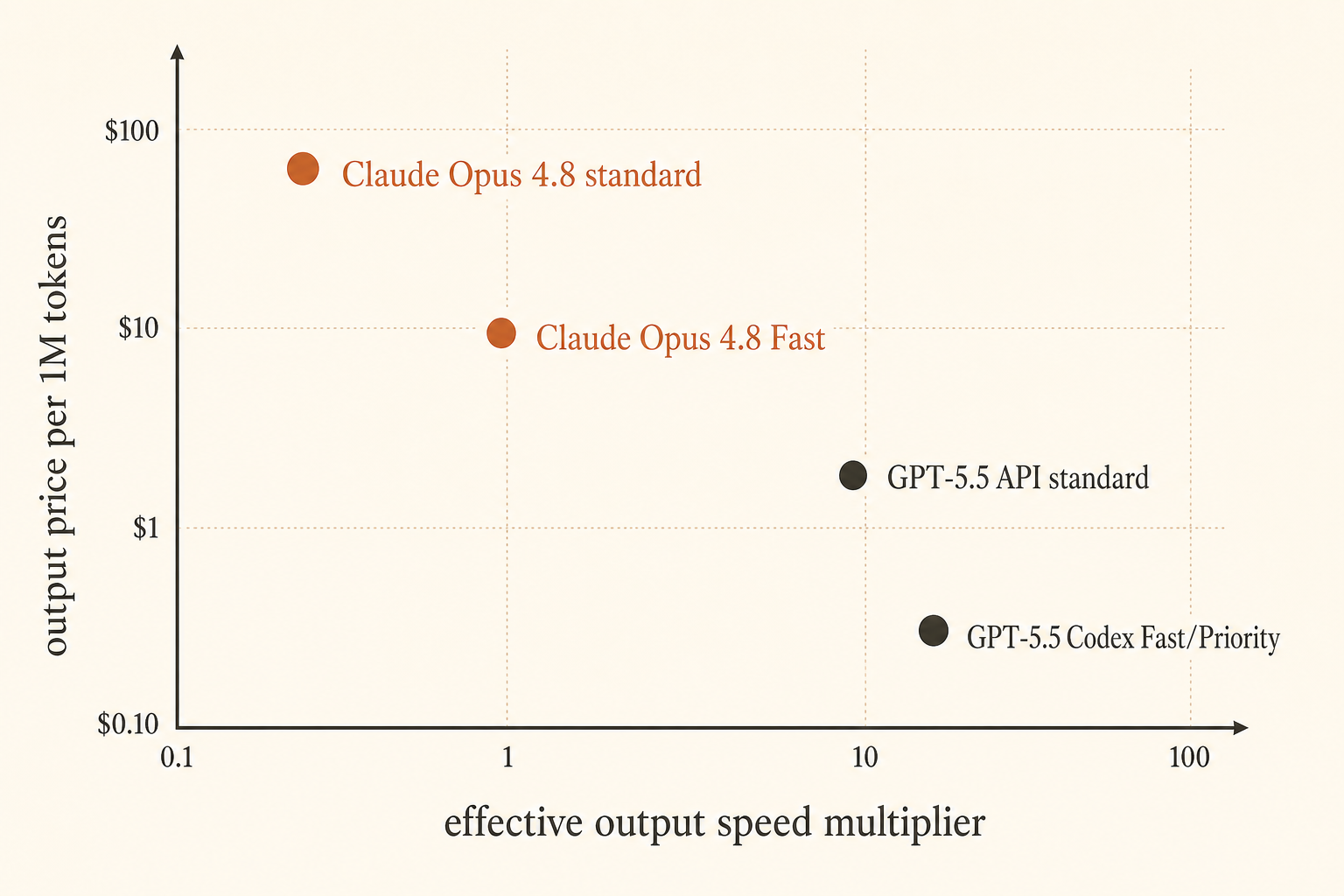
Anthropic は2026年5月28日、価格の問題をよりはっきりさせた。Claude Opus 4.8 Fast Mode は最大2.5倍の速度で動作し、料金は入力100万トークンあたり10ドル、出力100万トークンあたり50ドルになった(Anthropic)。OpenAI は別の角度から応じた。Codex Fast Mode の GPT-5.5 はトークン生成が1.5倍速くなり、コストは2.5倍。一方で API 価格は入力100万トークンあたり5ドル、出力100万トークンあたり30ドルで、API には1Mコンテキストウィンドウが来る予定だ(OpenAI)。
ベンダーの計算遊びに聞こえるかもしれない。だが IDE の前で、エージェントが3回目の失敗パッチを終えるのを待っていると話は変わる。そのときレイテンシはベンチマークの脚注ではない。集中を保てるか、Slack を開いてしまうかの差だ。
僕の見方はこうだ。レイテンシに縛られるコーディングなら、Opus 4.8 Fast Mode のほうが素直に速度を買える。GPT-5.5 は、出力コストを抑えたい、ターミナル性能が強いほうがいい、Codex ループをより締めたい、という場合の標準選択肢として優れている。もしエージェントの時間の大半が読み取り、計画、ツール呼び出しに消えているなら、速度を盲目的に買ってはいけない。まずループを直すべきだ。
本当に使うべき比較表
コーディングトラフィックのルーティング前に、僕なら実際にこの選択表を使う。
| Option | Published speed claim | Input price | Output price | Context | Best fit |
|---|---|---|---|---|---|
| Claude Opus 4.8 | baseline | $5/M | $25/M | Claude docs で 1M | 慎重なエージェント型コーディング、長いリポジトリコンテキスト |
| Claude Opus 4.8 Fast Mode | 最大2.5倍速 | $10/M | $50/M | フルコンテキスト。Fast は全体に適用 | 人間が待っているレイテンシ |
| GPT-5.5 API | baseline | $5/M | $30/M | 1M API window announced | 汎用コーディング、Opus Fast より低い出力単価 |
| GPT-5.5 Codex Fast Mode | 1.5倍のトークン生成 | 2.5倍の Codex コスト | 2.5倍の Codex コスト | Codex で 400K | UX が重要な高速 Codex セッション |
| GPT-5.5 API Priority-style math | 高速ティア | $12.50/M | $75/M | 1M API window announced | キュー待ちレイテンシが重要な本番呼び出し |
Anthropic の価格ドキュメントには、開発者が見落としがちな点が2つある。まず、Fast Mode はまだ research preview だ。次に、200Kトークンを超えるリクエストを含め、「フルコンテキストウィンドウ全体」に適用される(Anthropic docs)。同じドキュメントでは、Claude Opus 4.8、Opus 4.7、Opus 4.6、Fable 5、Mythos 系モデルは標準価格でフル1Mトークンコンテキストを含む、とされている。
OpenAI の公開価格ページでは、GPT-5.5 は入力100万トークンあたり5ドル、キャッシュ入力100万トークンあたり0.50ドル、出力100万トークンあたり30ドルだ(OpenAI pricing)。ローンチ記事では、Codex には400Kコンテキストウィンドウ付きで GPT-5.5 が入り、Fast Mode は2.5倍のコストで生成速度が1.5倍になると説明している。API の話は別だ。GPT-5.5 は Responses と Chat Completions で「まもなく」利用可能になり、1Mコンテキストウィンドウを持つ。
この分離は重要だ。Codex Fast Mode はプロダクトモードの判断。GPT-5.5 API pricing はトークン課金の判断。スプレッドシートで混ぜるなら、行にきちんとラベルを付けるべきだ。
開発者が不満を言う理由
Reddit の不満はかなり露骨だ。「Why is Opus 4.8 so slow?」というスレッドでは、モデルが劣化して遅く感じると言われ、あるコメントではその遅さを Fast Mode で収益化するためのものだと捉えている(Reddit)。別の r/ClaudeCode スレッドでは Opus 4.8 を「賢いが、慎重で遅い」と呼び、ユーザーたちは高 effort 設定が本当の原因なのか議論している(Reddit)。time-to-first-token に関する別スレッドでは、Codex との比較は体感応答性で「別世界」だと言われている(Reddit)。
コミュニティは4つの別々の問題を混ぜている。
- Time to first token。
- 1秒あたりの出力トークン数。
- 隠れた推論時間、または effort 時間。
- ツールループの無駄。ファイルの再読込、重複したシェル呼び出し、過剰な計画。
Fast Mode が主に攻めるのは2つ目だ。サービング容量次第では1つ目にも効くかもしれないが、公開されている主張は出力速度である。エージェントが300トークンを出す前に、80秒かけて考え、ファイルを読み、壊れたコマンドを再試行しているなら、より速い出力に払うのは弱い対策だ。
Anthropic 自身のローンチノートも、それを示唆している。Opus 4.8 はデフォルトで high effort になっており、より高い effort モードは良い結果のために考える時間を長く使う。Anthropic は、難しいタスクや長時間の非同期ワークフローでは追加 effort を推奨している(Anthropic)。リポジトリ移行には筋が通っている。「この prop をリネームしてテストを更新して」にはつらい。
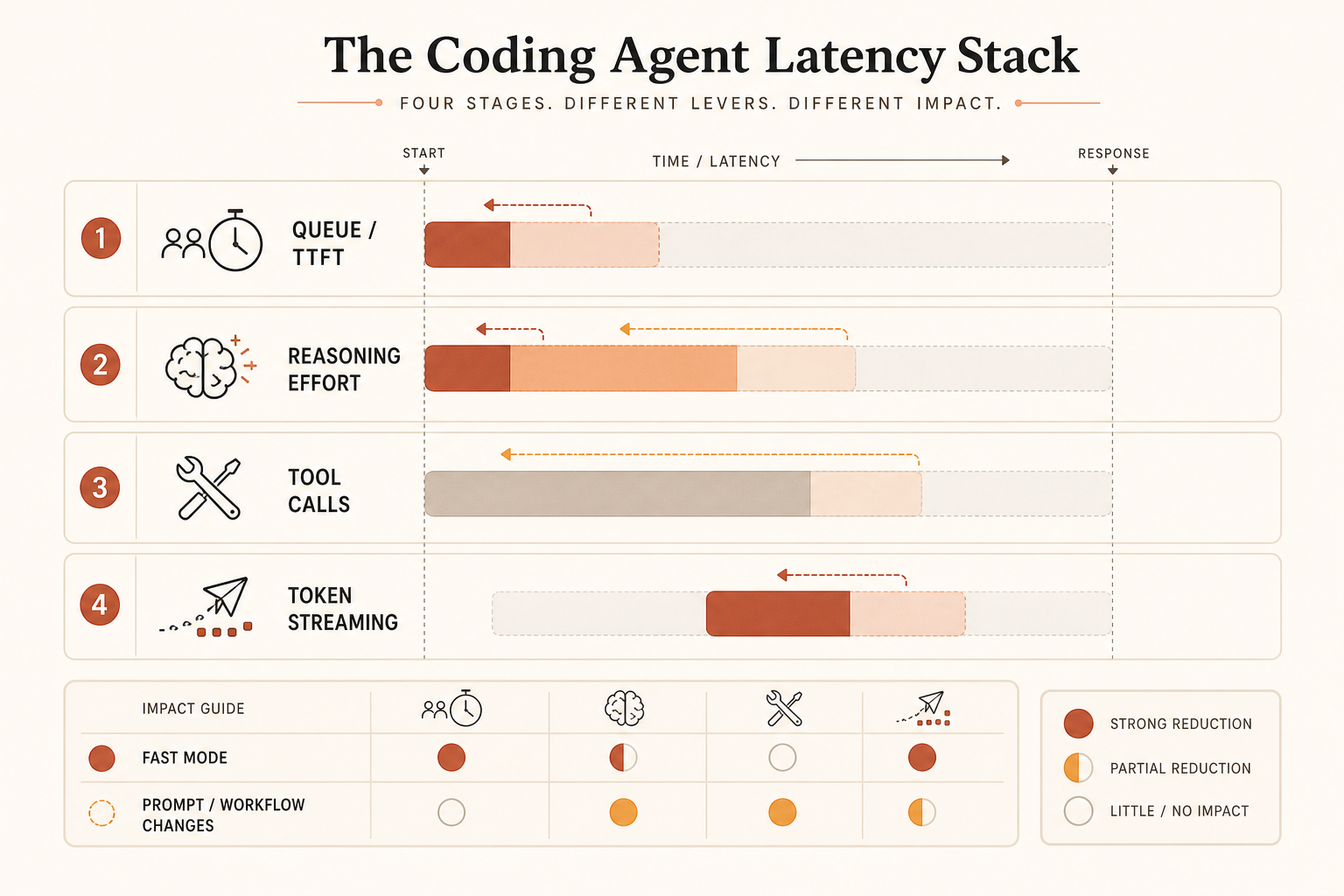
速度に払うのが合理的なとき
シンプルなルールでいい。人間がブロックされていて、生成出力が十分に大きく、トークンストリーミングが支配的になるときだけ Fast Mode を買う。
たとえば、あるコーディング応答が2,000出力トークンを出すとする。標準 Opus がその出力のストリーミングに100秒かかり、Fast Mode が公称の2.5倍に近づくなら、ストリーミング時間は約40秒に落ちる。1分を買い戻したことになる。Opus 4.8 の価格では、その応答の出力部分は0.05ドルから0.10ドルになる。シニア開発者が待っているなら、この交換は簡単に正当化できる。
ではワークロードを変えてみる。モデルが70秒かけてファイルを読み計画し、その後400トークンを20秒でストリーミングする。ストリーミングが2.5倍改善しても、節約できるのはおよそ12秒で、60秒ではない。それでも料金は倍になる。Reddit の苛立ちはそこから来ている。人々はレイテンシの請求書全体を体感しているが、有料の高速化機能がカバーするのはその一部だけかもしれない。
GPT-5.5 Codex Fast Mode は形が違う。公開されている倍率は小さい。Codex では、2.5倍のコストで生成が1.5倍速くなる(OpenAI)。純粋な「ストリーミングトークンあたりのドル」を最適化するなら魅力的ではない。それでも、Codex の TTFT が良い、ツール停止が少ない、プロジェクトに対して編集・テストのループが締まっているなら、意味はある。紙の上では遅いモデルでも、ハーネスが優れていれば体感は速い。
レイテンシに縛られるコーディングでは、1秒あたりのトークン数ではなく、タスクの壁時計時間を測るべきだ。見るべき指標はこれだ。
time_from_prompt_to_accepted_patch = planning + tool_calls + streaming + test_fix_retriesFast Mode が1項目しか改善しないなら、それは答え全体ではない。
Opus 4.8 Fast を使うべきとき
タスクに Opus らしい判断力が必要で、あなたがそこで待っているなら、Claude Opus 4.8 Fast Mode を選ぶ。
良い例はこうだ。
- マージ前にリスクのあるデータベース移行をレビューする。
- スタイルの一貫性が重要な大きな TypeScript 面をリファクタする。
- エージェントに複数ファイルを調べさせ、計画を提案させ、それを適用させる。
- 自信満々の誤ったパッチがトークン代より高くつく本番挙動をデバッグする。
- 応答が流れてくるのを読みながら、対話的にペア作業する。
Anthropic は、Opus 4.8 は前モデルと比べて、自分が書いたコードの欠陥をコメントせずに通してしまう可能性が約4分の1だと主張している(Anthropic)。コーディングにとって重要な品質主張はそこだ。Fast Mode は雑なモデルを慎重にはしない。慎重なモデルを、使っていて少し苛立ちにくくする。
問題は価格だ。出力100万トークンあたり50ドルの Opus 4.8 Fast は、冗長なエージェントトレース、生成ドキュメント、失敗パッチの反復には高い。厳しいハーネス制御と組み合わせるべきだ。小さな diff、簡潔な応答、キャッシュされたリポジトリ要約、編集前に必ず調査するという厳格なルール。
アグリゲータ経由でルーティングするなら、本番投入前に実際のプロトコルと可用性を確認すること。OneHop の Claude Fable 5 ページは現在、公式価格を入力100万トークンあたり10ドル・出力100万トークンあたり50ドル、OneHop 割引価格を3ドル・15ドル、新規アカウント向けの10ドル無料クレジット、Anthropic Messages エンドポイントを https://api.onehop.ai/anthropic として掲載している。同じページでは、僕が確認した時点でモデルが一時的に利用不可とも表示されていた(OneHop)。つまり安全策は、本番トラフィックを切り替える前に、自分のアカウントで可用性をテストすることだ。
実際の Anthropic SDK の形:
from anthropic import Anthropic
client = Anthropic(
api_key="ONEHOP_KEY",
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Review this patch for risky edge cases."}],
)
print(message.content[0].text)自分のアカウントで Fable 5 が使えるなら、セットアップコストが低く、新規アカウントは10ドル無料で始められるので、OneHop の Claude Fable 5 は試す価値がある。ただし価格カードだけを見て可用性を決めつけてはいけない。エンドポイントを呼ぶこと。
GPT-5.5 Codex Fast を使うべきとき
Codex の中で作業していて、トークンストリームよりループ全体を重視するなら、GPT-5.5 Codex Fast Mode を選ぶ。
OpenAI のローンチ記事では、GPT-5.5 は Terminal-Bench 2.0 で82.7%、OpenAI の表では GPT-5.4 が75.1%、Claude Opus 4.7 が69.4%だとされている(OpenAI)。ベンダーベンチマークは慎重に扱うべきだが、Terminal-Bench はコーディングエージェントに関係がある。シェル作業、環境の扱い、修復ループこそ、多くの「賢い」モデルが時間を浪費する場所だからだ。
GPT-5.5 は標準 API レートでは、出力が Opus Fast より安い。100万トークンあたり30ドル対50ドルだ。コード、ログ、説明、テスト出力を大量に生成するなら、この差は積み上がる。1M API コンテキストウィンドウにより、API アクセスが有効になれば大規模リポジトリのワークフローでも現実的になる。一方で Codex の400Kウィンドウも、多くの対話型セッションにはすでに十分大きい。
GPT-5.5 Fast の弱いケースは、純粋な速度の経済性だ。生成が1.5倍速くなるために2.5倍払うのは、他がすべて同じなら良い交換ではない。ただし、他がすべて同じことはめったにない。Codex は、よりきれいに編集し、コマンドをよりうまく実行し、開発者をより滑らかなレビューループに保てるから勝つかもしれない。
GPT-5.5 Codex Fast を使う場面:
- ターミナル操作が多い編集・テスト・修正ループ。
- 生成出力量が多い作業。
- すでに Codex に標準化しているチーム。
- 400Kコンテキストで足りるタスク。
- Opus の high-effort 挙動が遅すぎる、または慎重すぎると感じるケース。
最強の長期的レビュー判断が必要なタスクや、2.5倍の Fast 追加料金が大量のバックグラウンドジョブに適用される場合は避けるべきだ。そういうものはバッチに回す。OpenAI は Batch と Flex が標準 API レートの半額で利用可能で、Priority processing は標準の2.5倍だとしている(OpenAI)。かなり強い示唆だ。同期パスは priority に払う。非同期パスは払うべきではない。
結論
ほとんどのコーディングトラフィックでは GPT-5.5 をデフォルトにする。API の表示価格は出力で Opus 4.8 Fast より低く、Codex にはコーディングにフォーカスした UX があり、1M API コンテキストウィンドウによって、長いコンテキストはすべて Claude に回すという歴史的な理由の大きな部分が消える。
人間がブロックされていて、GPT-5.5 標準より出力100万トークンあたり20ドル余分に払ってでも品質が重要なときは、Claude Opus 4.8 Fast にエスカレートする。最良のユースケースは「すべてのコーディング応答を速くする」ではない。「高価で慎重な答えを、自分が文脈を失う前に届ける」ことだ。
非同期の深い作業には標準 Opus 4.8 を残す。モデルがコードベース移行を実行したり、サブエージェントを起動したり、何十万行も分析したりしているなら、速度より正確性、キャッシュ、リトライ規律のほうが重要だ。Anthropic の Dynamic Workflows 機能は、テストを基準にして何十万行規模の移行を行うような大きなタスクのために作られている(Anthropic)。
OneHop のようなルーティングは、測定を省く言い訳ではなく、テストの近道として使う。セットアップの摩擦を抑えて上位 Claude ルーティングを試したいなら、OneHop の Claude Fable 5 を確認し、現在の可用性を確かめ、10ドル無料で始める。1ドルあたりの受理されたパッチ数と、プロンプトからマージまでの時間を測る。それだけが、来週もあなたのチームが気にしているベンチマークだ。