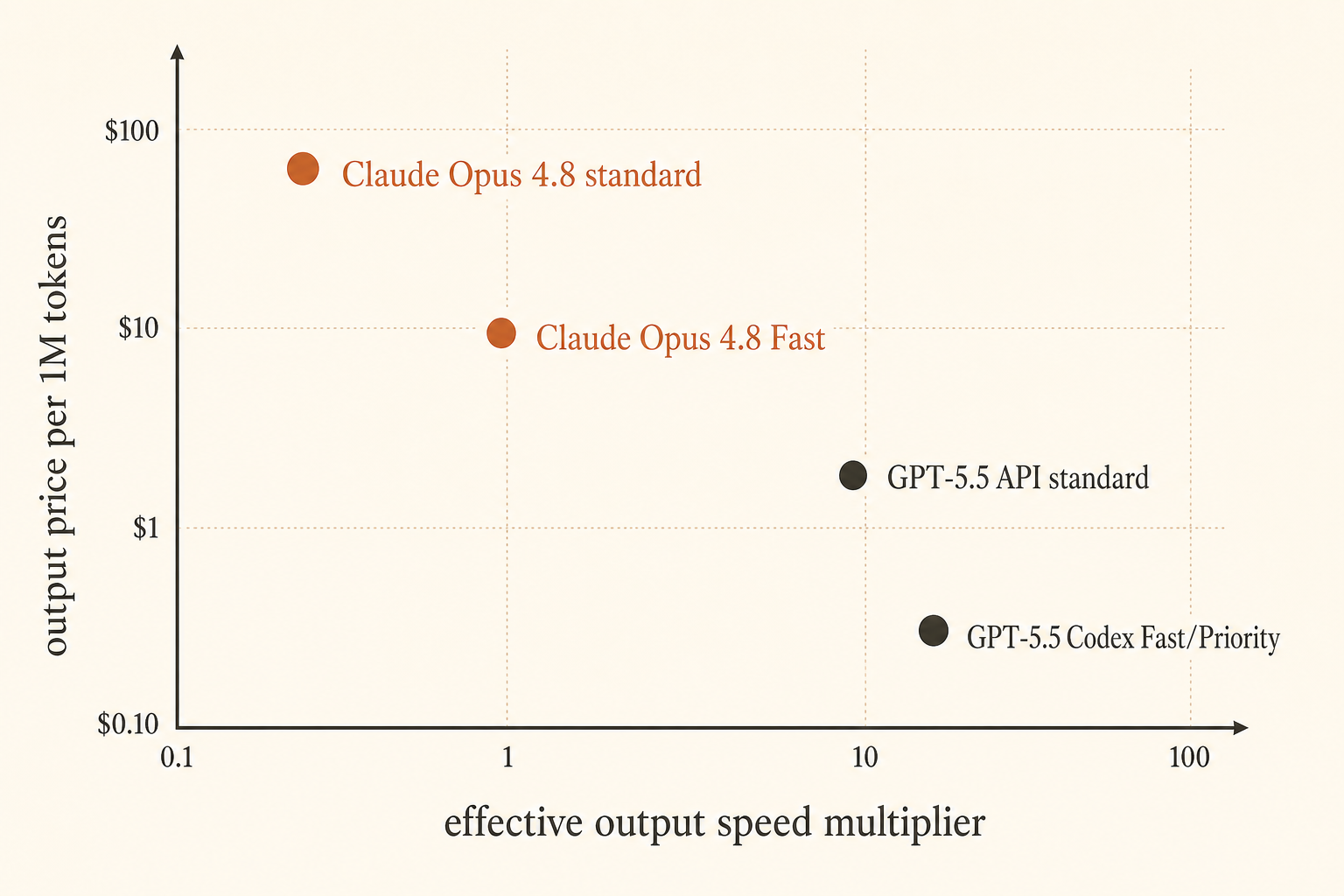
Anthropic은 2026년 5월 28일 가격 문제를 더 선명하게 만들었다. Claude Opus 4.8 Fast Mode는 이제 최대 2.5× 속도로 동작하며, 비용은 입력 토큰 100만 개당 $10, 출력 토큰 100만 개당 $50이다(Anthropic). OpenAI는 다른 각도에서 응수했다. Codex Fast Mode의 GPT-5.5는 비용이 2.5×인 대신 토큰 생성 속도가 1.5× 빠르고, API 가격은 100만 토큰당 입력 $5, 출력 $30이며 1M 컨텍스트 창이 API에 도입될 예정이다(OpenAI).
벤더들이 숫자놀이하는 것처럼 들린다. IDE에서 에이전트가 세 번째 패치 시도까지 실패한 뒤 끝나기를 기다리기 전까지는. 그 순간 지연 시간은 벤치마크 각주가 아니다. 몰입을 유지하느냐 Slack을 여느냐의 차이다.
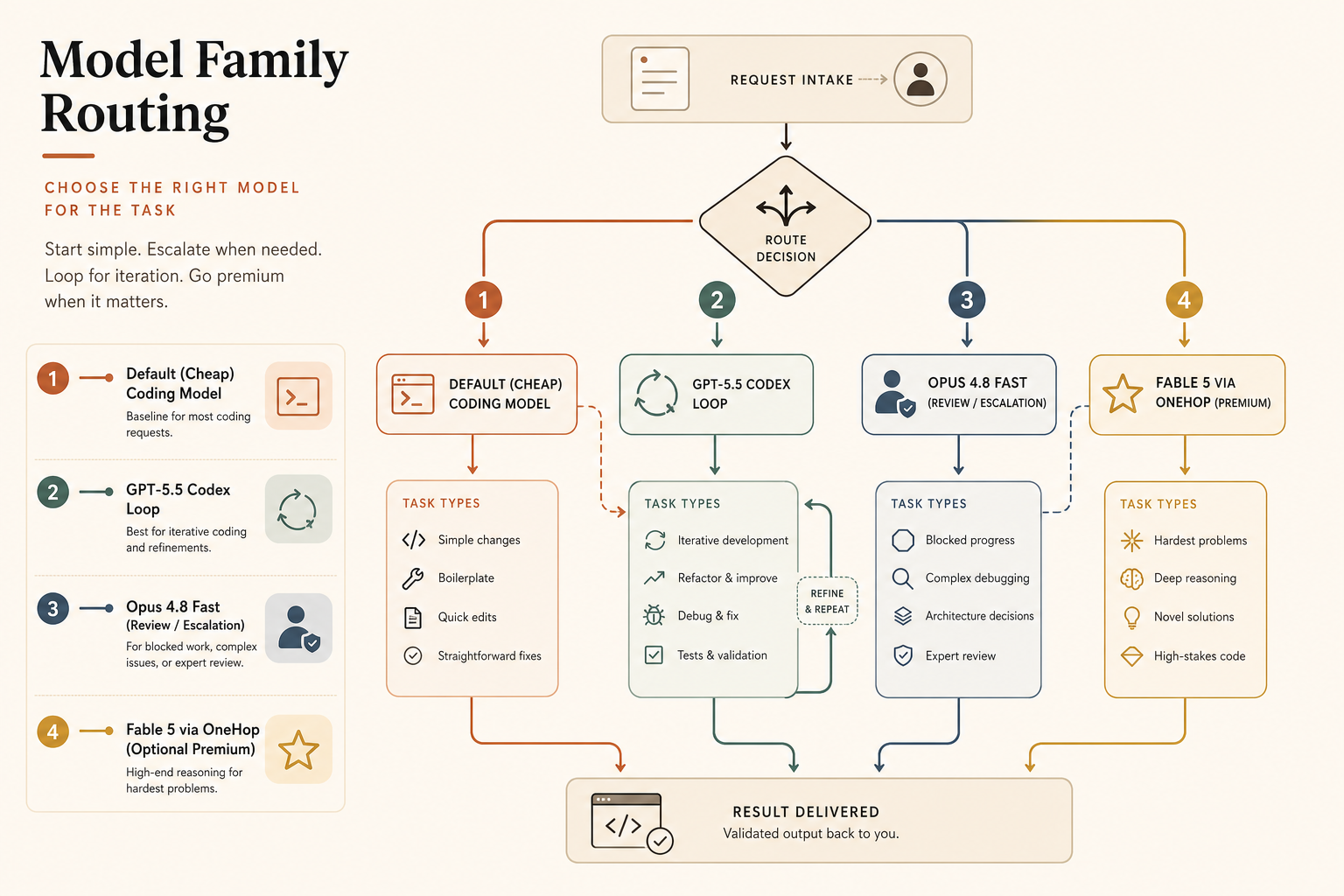
내 생각은 이렇다. 지연 시간에 묶인 코딩에서는 Opus 4.8 Fast Mode가 더 깔끔한 속도 구매다. GPT-5.5는 더 낮은 출력 비용, 강한 터미널 성능, 더 촘촘한 Codex 루프를 원할 때 더 나은 기본값이다. 에이전트가 대부분의 시간을 읽기, 계획 세우기, 도구 호출에 쓰고 있다면 속도를 무작정 사지 마라. 먼저 루프를 고쳐라.
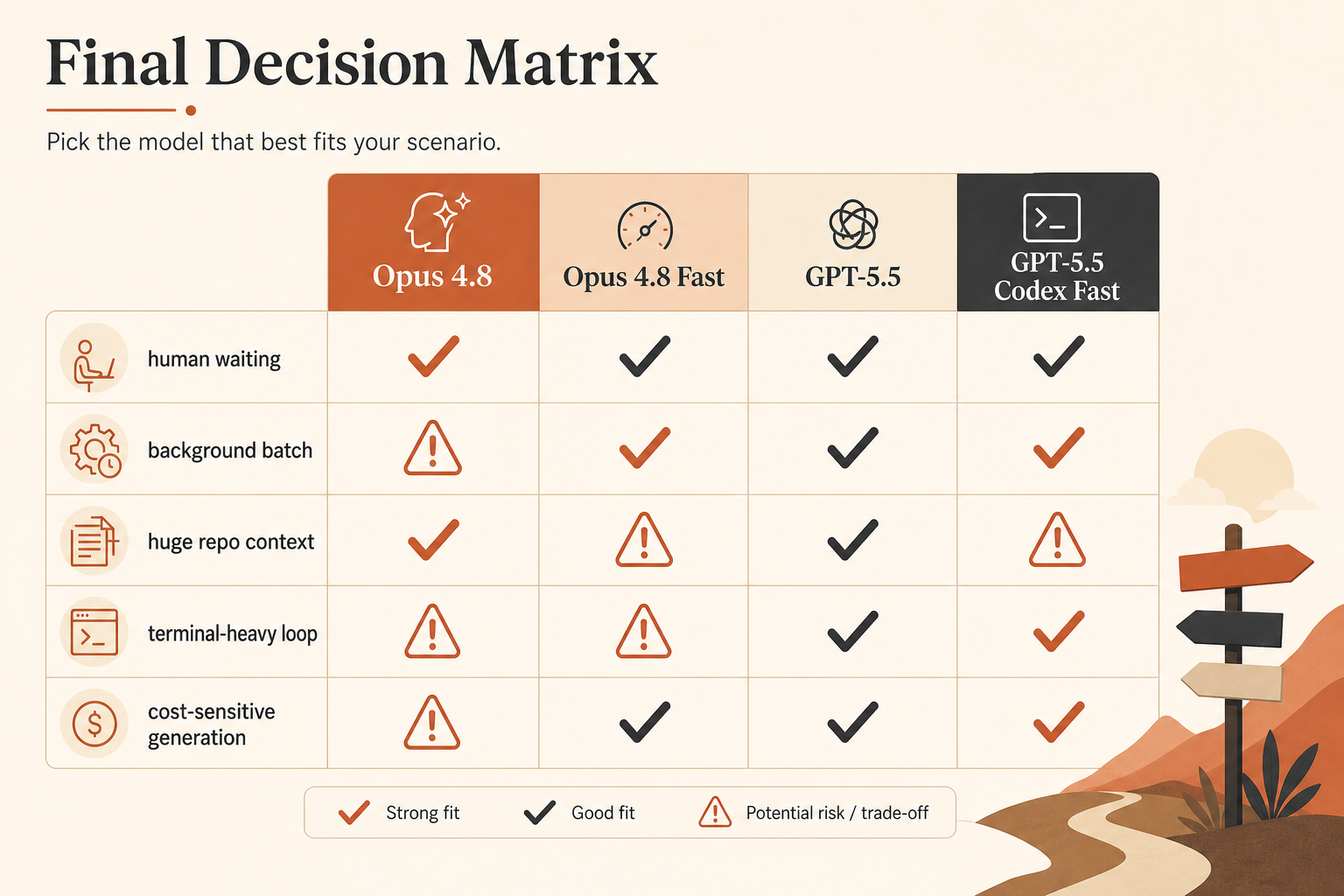
진짜 비교표
코딩 트래픽을 라우팅하기 전에 내가 실제로 쓸 선택 표는 이렇다.
| Option | Published speed claim | Input price | Output price | Context | Best fit |
|---|---|---|---|---|---|
| Claude Opus 4.8 | 기준선 | $5/M | $25/M | Claude 문서상 1M | 신중한 에이전트식 코딩, 긴 repo 컨텍스트 |
| Claude Opus 4.8 Fast Mode | 최대 2.5× 속도 | $10/M | $50/M | 전체 컨텍스트; Fast가 전 범위에 적용 | 사람이 기다리는 지연 시간 |
| GPT-5.5 API | 기준선 | $5/M | $30/M | 1M API 창 발표 | 일반 코딩, Opus Fast보다 낮은 출력 가격 |
| GPT-5.5 Codex Fast Mode | 1.5× 토큰 생성 | 2.5× Codex 비용 | 2.5× Codex 비용 | Codex에서 400K | UX가 중요한 빠른 Codex 세션 |
| GPT-5.5 API Priority식 계산 | 더 빠른 속도 티어 | $12.50/M | $75/M | 1M API 창 발표 | 큐 지연 시간이 중요한 프로덕션 호출 |
Anthropic의 가격 문서에는 개발자들이 자주 놓치는 세부 사항이 두 가지 있다. 첫째, Fast Mode는 아직 research preview다. 둘째, 200K 토큰을 넘는 요청을 포함해 “전체 컨텍스트 창에 걸쳐” 적용된다(Anthropic docs). 같은 문서는 Claude Opus 4.8, Opus 4.7, Opus 4.6, Fable 5, Mythos 계열 모델이 표준 가격으로 전체 1M 토큰 컨텍스트를 포함한다고 말한다.
OpenAI의 공개 가격 페이지는 GPT-5.5를 입력 $5/M, 캐시된 입력 $0.50/M, 출력 $30/M으로 표시한다(OpenAI pricing). 출시 글에 따르면 Codex는 400K 컨텍스트 창과 함께 GPT-5.5를 받으며, Fast Mode는 2.5× 비용으로 생성 속도가 1.5× 빨라진다. API 이야기는 별개다. GPT-5.5는 1M 컨텍스트 창과 함께 Responses 및 Chat Completions에서 “곧” 제공된다.
이 구분이 중요하다. Codex Fast Mode는 제품 모드에 대한 결정이다. GPT-5.5 API 가격은 토큰 과금에 대한 결정이다. 스프레드시트에 섞어 넣을 거라면 행에 라벨을 제대로 붙여라.
개발자들이 불평하는 이유
Reddit의 불만은 노골적이다. “Why is Opus 4.8 so slow?”라는 제목의 스레드는 모델이 저하되고 느리게 느껴진다고 말하며, 한 댓글 작성자는 이 느려짐을 Fast Mode로 수익화하기 위한 방식으로 해석한다(Reddit). 또 다른 r/ClaudeCode 스레드는 Opus 4.8을 “똑똑하지만 신중하고 느리다”고 부르며, 사용자들은 높은 effort 설정이 진짜 원인인지 논쟁한다(Reddit). time-to-first-token을 다룬 별도 스레드는 Codex와 비교했을 때 체감 응답성이 “하늘과 땅 차이”라고 말한다(Reddit).
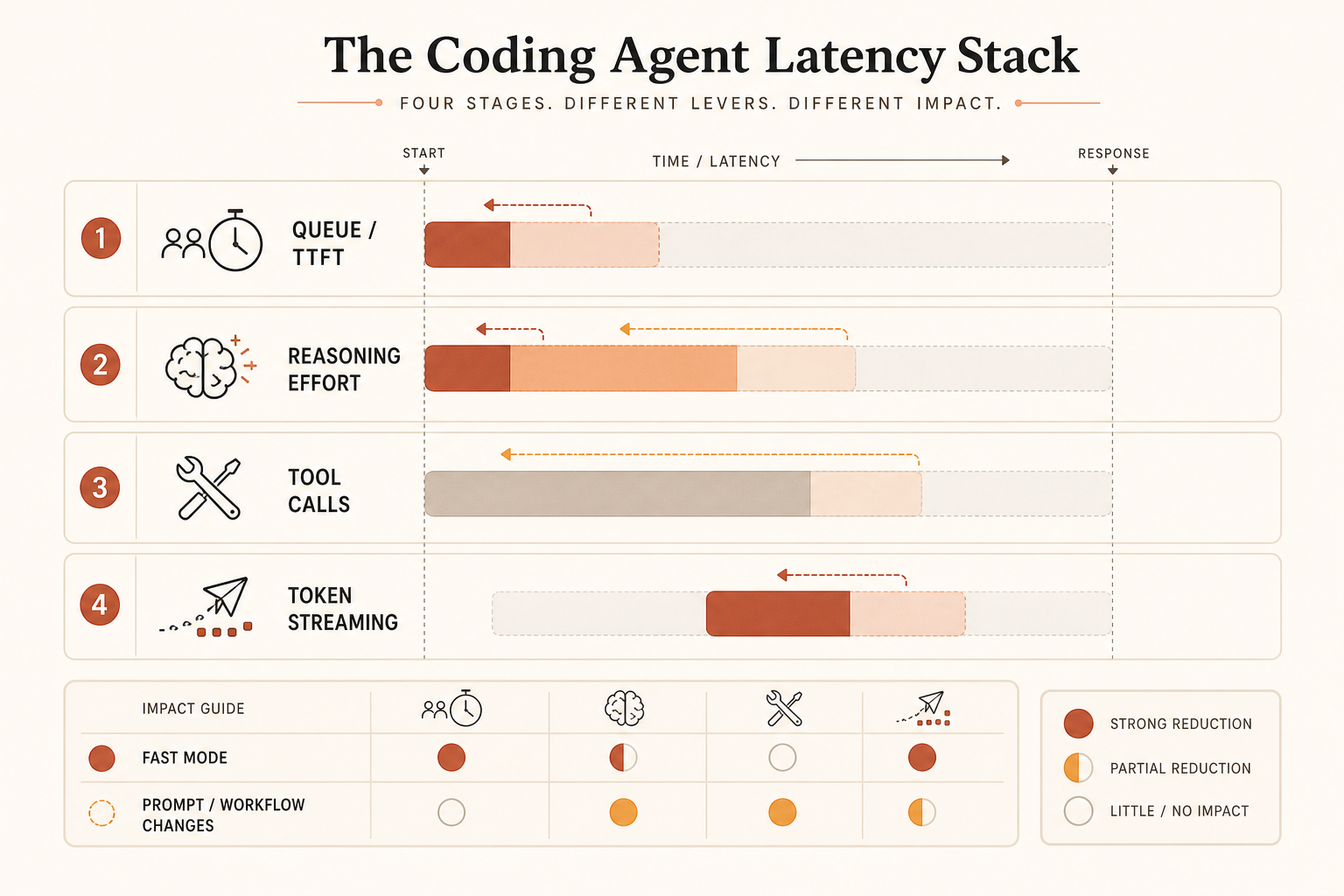
커뮤니티는 네 가지 별개 문제를 뒤섞고 있다.
- 첫 토큰까지 걸리는 시간.
- 초당 출력 토큰 수.
- 숨은 reasoning 또는 effort 시간.
- 도구 루프 낭비: 파일 재읽기, 중복 shell 호출, 과도한 계획.
Fast Mode는 주로 두 번째 문제를 겨냥한다. 서빙 용량에 따라 첫 번째에도 도움이 될 수 있지만, 공개된 주장은 출력 속도다. 에이전트가 300토큰을 출력하기 전에 80초 동안 생각하고, 파일을 읽고, 깨진 명령을 재시도한다면 출력 속도를 사는 건 약한 처방이다.
Anthropic의 출시 노트도 이 점을 암시한다. Opus 4.8은 기본값이 high effort이며, 더 높은 effort 모드는 더 나은 결과를 위해 생각하는 데 더 많은 시간을 쓴다. Anthropic은 어려운 작업과 오래 걸리는 비동기 워크플로에 추가 effort를 권장한다(Anthropic). repo 마이그레이션에는 말이 된다. “이 prop 이름 바꾸고 테스트 업데이트해줘”에는 고통스럽다.
속도에 돈을 내는 게 합리적인 경우
간단한 규칙을 쓰면 된다. 사람이 막혀 있고, 생성되는 출력이 충분히 커서 토큰 스트리밍이 지배적인 경우에만 Fast Mode를 사라.
코딩 응답이 출력 토큰 2,000개를 내보낸다고 해보자. 표준 Opus가 그 출력을 스트리밍하는 데 100초가 걸리고 Fast Mode가 광고된 2.5×에 가깝게 나온다면, 스트리밍 시간은 약 40초로 줄어든다. 1분을 되찾은 셈이다. Opus 4.8 가격에서 그 응답의 출력 부분 비용은 $0.05에서 $0.10로 올라간다. 시니어 개발자가 기다리고 있다면 쉽게 정당화되는 거래다.
이제 작업 부하를 바꿔보자. 모델이 파일을 읽고 계획을 세우는 데 70초를 쓴 뒤, 400토큰을 20초 동안 스트리밍한다. 2.5× 스트리밍 개선은 60초가 아니라 대략 12초를 아낀다. 그래도 비용은 두 배다. Reddit의 불만은 여기서 나온다. 사람들은 전체 지연 시간 청구서를 체감하지만, 유료 속도 기능은 그중 일부만 덮을 수 있다.
GPT-5.5 Codex Fast Mode는 모양이 다르다. 공개된 배율은 더 작다. Codex에서 2.5× 비용으로 생성 속도 1.5× 향상이다(OpenAI). 스트리밍 토큰당 순수 비용만 최적화한다면 매력적이지 않다. 그래도 Codex의 TTFT가 더 좋거나, 도구 정지가 적거나, 프로젝트에서 edit-test 루프가 더 촘촘하다면 의미가 있을 수 있다. 종이 위에서는 느린 모델도 harness가 더 좋으면 더 빠르게 느껴진다.
지연 시간에 묶인 코딩에서는 초당 토큰 수가 아니라 벽시계 기준 작업 시간을 재라. 지표는 이렇게 잡아야 한다.
time_from_prompt_to_accepted_patch = planning + tool_calls + streaming + test_fix_retriesFast Mode가 한 항만 개선한다면, 그것은 전체 해답이 아니다.
Opus 4.8 Fast를 쓸 때
작업에 Opus식 판단력이 필요하고, 당신이 그 앞에서 기다리고 있다면 Claude Opus 4.8 Fast Mode를 골라라.
좋은 예시는 이렇다.
- 병합 전에 위험한 데이터베이스 마이그레이션 검토하기.
- 스타일 일관성이 중요한 대규모 TypeScript 표면 리팩터링하기.
- 에이전트에게 여러 파일을 검사하고 계획을 제안한 뒤 적용하게 하기.
- 자신감 있는 잘못된 패치가 토큰보다 더 비싼 프로덕션 동작 디버깅하기.
- 응답이 스트리밍되는 동안 직접 읽으며 페어링하기.
Anthropic은 Opus 4.8이 이전 모델보다 자신이 작성한 코드의 결함을 지적하지 않고 지나칠 가능성이 약 네 배 낮다고 주장한다(Anthropic). 코딩에서 중요한 품질 주장은 바로 이 부분이다. Fast Mode는 부주의한 모델을 신중하게 만들지 않는다. 신중한 모델을 덜 짜증 나게 만든다.
문제는 가격이다. 출력 $50/M인 Opus 4.8 Fast는 장황한 에이전트 trace, 생성 문서, 반복되는 실패 패치에는 비싸다. 작은 diff, 간결한 응답, 캐시된 repo 요약, 편집 전에 반드시 검사해야 한다는 엄격한 규칙 같은 harness 제어와 함께 써야 한다.
애그리게이터를 통해 라우팅한다면, 출시 전에 실제 프로토콜과 가용성을 확인하라. OneHop의 Claude Fable 5 페이지는 현재 공식 가격을 입력 $10/M 및 출력 $50/M, OneHop 할인 가격을 $3/M 및 $15/M, 신규 계정 $10 무료 크레딧, Anthropic Messages 엔드포인트를 https://api.onehop.ai/anthropic로 표시한다. 같은 페이지는 내가 확인한 시점에 모델을 일시적으로 사용할 수 없다고도 표시했다(OneHop). 즉 안전한 선택은 프로덕션 트래픽을 바꾸기 전에 자기 계정에서 가용성을 테스트하는 것이다.
실제 Anthropic SDK 형태:
from anthropic import Anthropic
client = Anthropic(
api_key="ONEHOP_KEY",
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Review this patch for risky edge cases."}],
)
print(message.content[0].text)계정에서 Fable 5를 사용할 수 있다면, OneHop의 Claude Fable 5는 테스트해볼 만하다. 설정 비용이 낮고 신규 계정은 $10 무료로 시작할 수 있기 때문이다. 다만 가격 카드만 보고 가용성을 가정하지 마라. 엔드포인트를 호출해라.
GPT-5.5 Codex Fast를 쓸 때
Codex 안에서 살고 있고 토큰 스트림보다 전체 루프가 더 중요하다면 GPT-5.5 Codex Fast Mode를 골라라.
OpenAI의 출시 글은 Terminal-Bench 2.0에서 GPT-5.5가 82.7%를 기록했다고 보고한다. OpenAI 표 기준 GPT-5.4는 75.1%, Claude Opus 4.7은 69.4%다(OpenAI). 벤더 벤치마크는 조심해서 봐야 하지만, Terminal-Bench는 코딩 에이전트에 관련성이 있다. shell 작업, 환경 처리, 복구 루프야말로 많은 “똑똑한” 모델이 시간을 낭비하는 지점이기 때문이다.
GPT-5.5는 표준 API 요율 기준 출력 비용도 Opus Fast보다 싸다. $30/M 대 $50/M이다. 코드, 로그, 설명, 테스트 출력을 많이 생성한다면 이 차이는 누적된다. 1M API 컨텍스트 창은 API 접근이 열리면 대형 repo 워크플로에도 현실적인 선택지가 되고, Codex의 400K 창도 이미 많은 인터랙티브 세션에 충분히 크다.
GPT-5.5 Fast의 약한 지점은 순수한 속도 경제성이다. 생성 속도 1.5×를 위해 2.5×를 내는 것은 다른 조건이 모두 같다면 좋은 거래가 아니다. 하지만 모든 조건이 같은 경우는 드물다. Codex가 더 깔끔하게 편집하고, 명령을 더 잘 실행하고, 개발자를 더 부드러운 리뷰 루프 안에 붙잡아 두기 때문에 이길 수 있다.
GPT-5.5 Codex Fast는 이런 경우에 써라.
- 터미널 상호작용이 많은 edit-test-fix 루프.
- 생성 출력량이 많은 작업.
- 이미 Codex로 표준화한 팀.
- 400K 컨텍스트로 충분한 작업.
- Opus의 high-effort 동작이 너무 느리거나 너무 조심스럽게 느껴지는 경우.
가장 강한 장기적 리뷰 판단력이 필요한 작업이거나, 2.5× Fast 할증이 대량 백그라운드 작업에 적용되는 경우에는 피하라. 그런 것은 배치로 돌려라. OpenAI는 Batch와 Flex가 표준 API 요율의 절반으로 제공되고, Priority 처리는 표준의 2.5×라고 말한다(OpenAI). 꽤 강한 힌트다. 동기 경로는 priority에 돈을 내고, 비동기 경로는 그러면 안 된다.
추천
대부분의 코딩 트래픽은 GPT-5.5를 기본값으로 둬라. API 정가 기준 출력 비용이 Opus 4.8 Fast보다 낮고, Codex는 코딩에 집중된 UX를 갖고 있으며, 1M API 컨텍스트 창은 긴 컨텍스트라면 무조건 Claude로 보내야 했던 과거의 큰 이유를 제거한다.
사람이 막혀 있고 품질이 GPT-5.5 표준 대비 출력 토큰 100만 개당 추가 $20보다 중요할 때 Claude Opus 4.8 Fast로 올려라. 최고의 사용 사례는 “모든 코딩 응답을 더 빠르게 만들기”가 아니다. “비싸고 신중한 답이 내가 맥락을 잃기 전에 도착하게 만들기”다.
비동기 deep work에는 표준 Opus 4.8을 유지해라. 모델이 코드베이스 마이그레이션을 실행하거나, subagent를 띄우거나, 수십만 줄을 분석하는 중이라면 속도보다 정확성, 캐싱, 재시도 규율이 더 중요하다. Anthropic의 Dynamic Workflows 기능은 테스트를 기준으로 삼아 수십만 줄에 걸친 마이그레이션을 포함한 그런 종류의 큰 작업을 위해 만들어졌다(Anthropic).
OneHop식 라우팅은 테스트를 빠르게 시작하는 지름길로 써라. 측정을 건너뛰는 핑계로 쓰지 마라. 설정 마찰을 낮게 유지하면서 고급 Claude 라우팅을 시험해보고 싶다면 OneHop의 Claude Fable 5를 확인하고, 현재 가용성을 검증한 뒤, $10 무료로 시작해라. 달러당 수락된 패치 수와 prompt-to-merge 시간을 측정해라. 다음 주에도 당신 팀이 신경 쓸 유일한 벤치마크는 그것뿐이다.