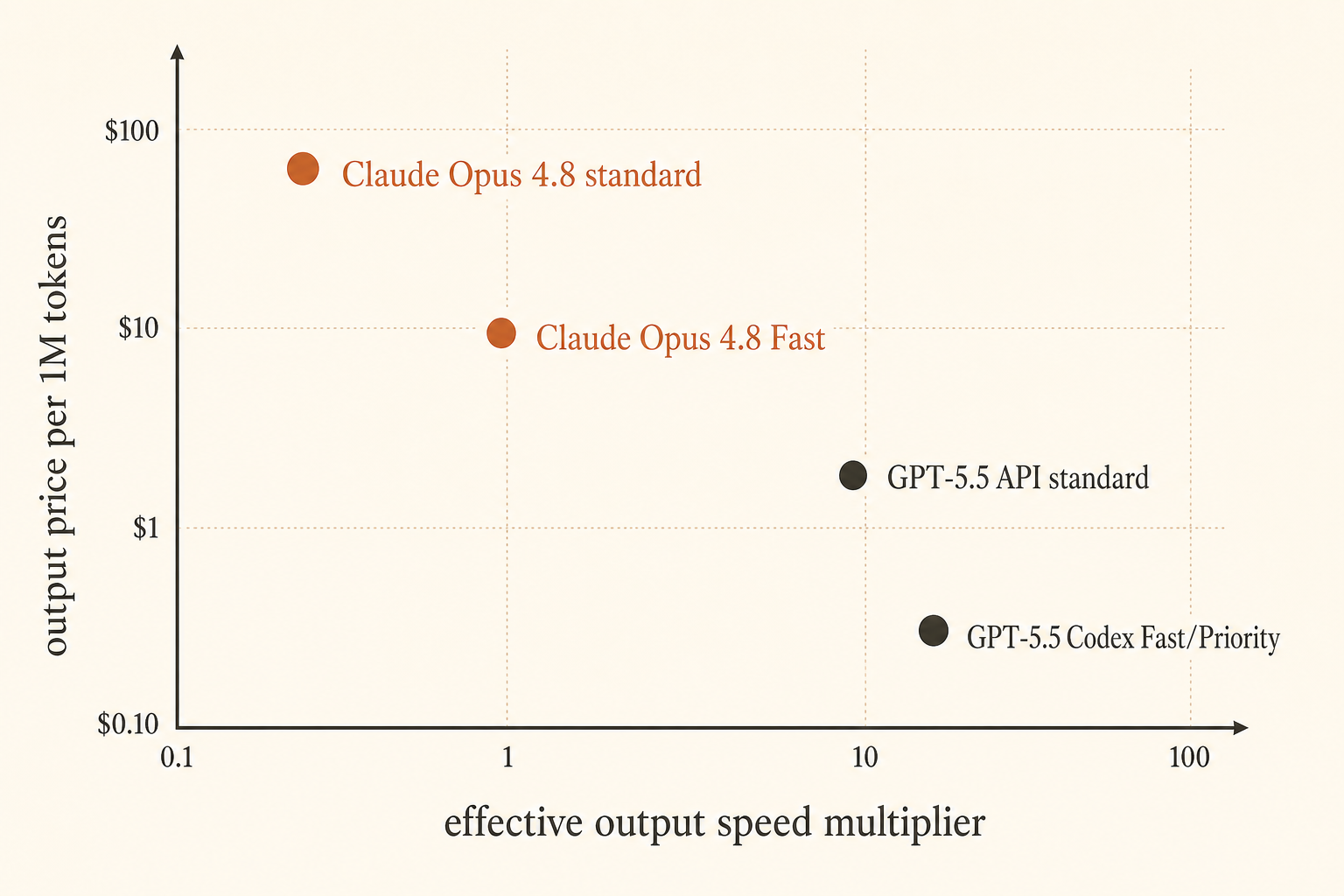
Anthropic a rendu le problème du prix plus tranchant le 28 mai 2026 : Claude Opus 4.8 Fast Mode tourne désormais jusqu’à 2,5× plus vite et coûte 10 $ par million de tokens d’entrée et 50 $ par million de tokens de sortie (Anthropic). OpenAI a répondu sous un autre angle : GPT-5.5 dans Codex Fast Mode génère des tokens 1,5× plus vite pour 2,5× le coût, tandis que le prix API est de 5 $ en entrée et 30 $ en sortie par million de tokens, avec une fenêtre de contexte de 1M qui arrive dans l’API (OpenAI).
Ça ressemble à des maths de fournisseur jusqu’au moment où vous êtes dans un IDE, à attendre qu’un agent termine sa troisième tentative de patch ratée. Là, la latence n’est plus une note de bas de page dans un benchmark. C’est la différence entre rester dans le flow et ouvrir Slack.
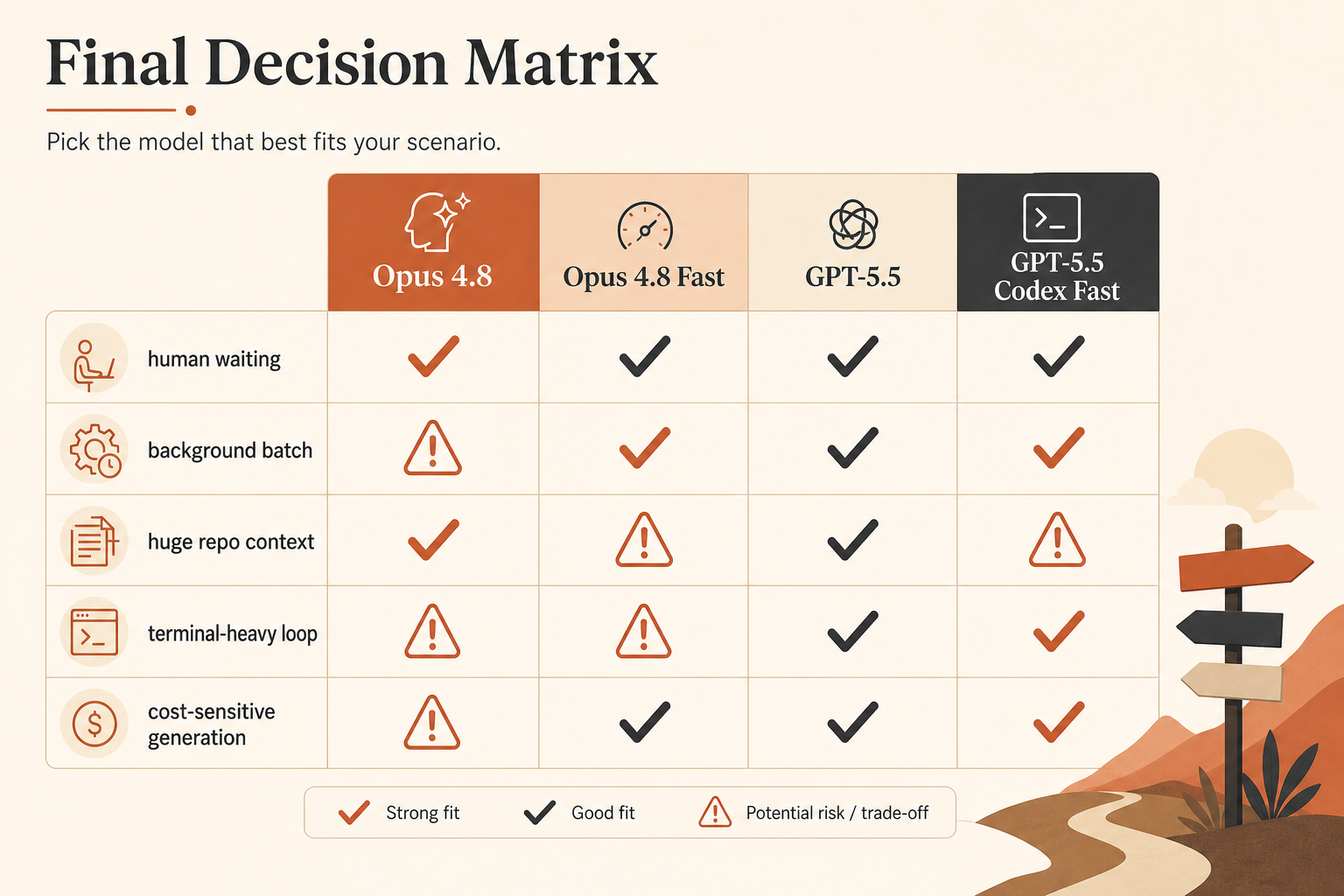
Mon avis : pour le code limité par la latence, Opus 4.8 Fast Mode est l’achat de vitesse le plus net. GPT-5.5 est le meilleur choix par défaut quand vous voulez un coût de sortie plus bas, de solides performances en terminal et une boucle Codex plus serrée. Si votre agent passe l’essentiel de son temps à lire, planifier et appeler des outils, n’achetez pas de la vitesse à l’aveugle. Corrigez d’abord la boucle.
Le vrai tableau de comparaison
Voici le tableau de sélection que j’utiliserais vraiment avant de router du trafic de code.
| Option | Promesse de vitesse publiée | Prix d’entrée | Prix de sortie | Contexte | Meilleur cas d’usage |
|---|---|---|---|---|---|
| Claude Opus 4.8 | référence | 5 $/M | 25 $/M | 1M dans la doc Claude | code agentique prudent, long contexte de repo |
| Claude Opus 4.8 Fast Mode | jusqu’à 2,5× plus vite | 10 $/M | 50 $/M | contexte complet ; Fast s’applique partout | latence avec humain dans la boucle |
| GPT-5.5 API | référence | 5 $/M | 30 $/M | fenêtre API de 1M annoncée | code général, prix de sortie plus bas qu’Opus Fast |
| GPT-5.5 Codex Fast Mode | génération de tokens 1,5× plus rapide | 2,5× le coût Codex | 2,5× le coût Codex | 400K dans Codex | sessions Codex rapides où l’UX compte |
| Calcul façon GPT-5.5 API Priority | palier plus rapide | 12,50 $/M | 75 $/M | fenêtre API de 1M annoncée | appels de production où la latence de file d’attente compte |
La doc tarifaire d’Anthropic ajoute deux détails que les développeurs ratent souvent. D’abord, Fast Mode est encore en aperçu de recherche. Ensuite, il s’applique « sur toute la fenêtre de contexte », y compris aux requêtes de plus de 200K tokens (Anthropic docs). La même doc indique que Claude Opus 4.8, Opus 4.7, Opus 4.6, Fable 5 et les modèles de classe Mythos incluent le contexte complet de 1M tokens au prix standard.
La page publique des prix d’OpenAI liste GPT-5.5 à 5 $/M en entrée, 0,50 $/M en entrée mise en cache et 30 $/M en sortie (OpenAI pricing). L’article de lancement dit que Codex reçoit GPT-5.5 avec une fenêtre de contexte de 400K et Fast Mode à 1,5× la vitesse de génération pour 2,5× le coût. Côté API, c’est une histoire séparée : GPT-5.5 sera disponible « bientôt » dans Responses et Chat Completions avec une fenêtre de contexte de 1M.
Cette séparation compte. Codex Fast Mode est une décision de mode produit. La tarification API de GPT-5.5 est une décision de compteur de tokens. Ne les mélangez pas dans une feuille de calcul sans étiqueter les lignes.
Pourquoi les développeurs râlent
La plainte sur Reddit n’est pas subtile. Un fil intitulé « Why is Opus 4.8 so slow? » dit que le modèle semble dégradé et lent, avec un commentaire qui présente ce ralentissement comme une façon de monétiser Fast Mode (Reddit). Un autre fil r/ClaudeCode qualifie Opus 4.8 de « smart, but careful and slow », tandis que les utilisateurs débattent pour savoir si les réglages d’effort élevé sont les vrais coupables (Reddit). Un fil séparé sur le délai avant le premier token dit que la comparaison avec Codex est « night and day » pour la réactivité perçue (Reddit).
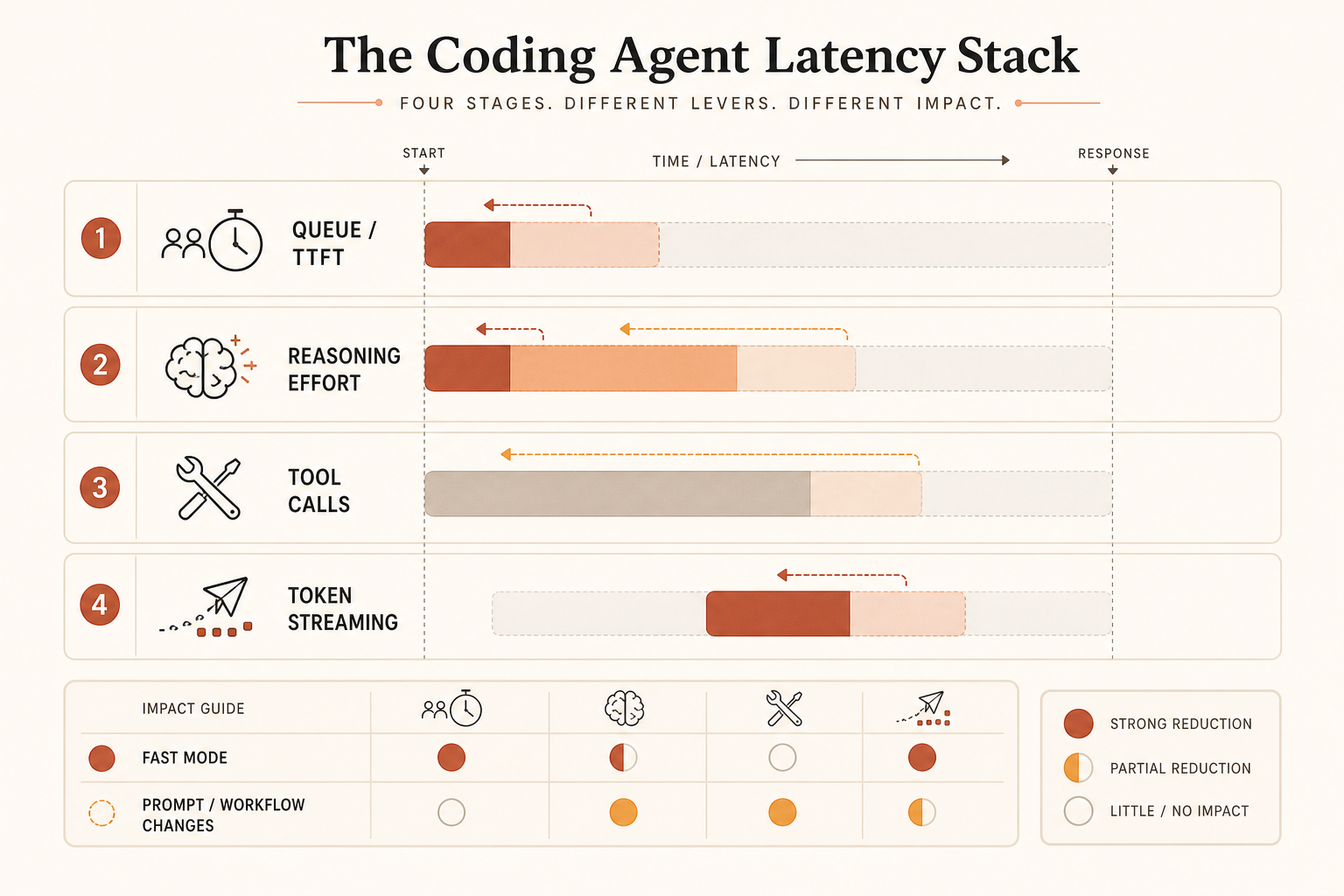
La communauté mélange quatre problèmes distincts :
- Le délai avant le premier token.
- Les tokens de sortie par seconde.
- Le temps de raisonnement ou d’effort caché.
- Le gaspillage dans la boucle d’outils : relecture de fichiers, appels shell redondants, planification excessive.
Fast Mode s’attaque surtout au deuxième bloc. Il peut aider le premier selon la capacité de service, mais la promesse publique porte sur la vitesse de sortie. Si votre agent passe 80 secondes à réfléchir, lire des fichiers et relancer des commandes cassées avant d’imprimer 300 tokens, payer pour une sortie plus rapide est un faible correctif.
La note de lancement d’Anthropic le suggère elle-même. Opus 4.8 utilise par défaut un effort élevé, et les modes à effort plus élevé passent plus de temps à réfléchir pour obtenir de meilleurs résultats. Anthropic recommande l’effort supplémentaire pour les tâches difficiles et les workflows asynchrones de longue durée (Anthropic). C’est raisonnable pour des migrations de repo. C’est pénible pour « renomme cette prop et mets à jour les tests ».
Quand payer pour la vitesse est rationnel
Utilisez une règle simple : achetez Fast Mode seulement quand l’humain est bloqué et que la sortie générée est assez longue pour que le streaming de tokens domine.
Supposons qu’une réponse de code émette 2 000 tokens de sortie. Si Opus standard met 100 secondes à streamer cette sortie et que Fast Mode se rapproche du 2,5× annoncé, le temps de streaming tombe à environ 40 secondes. Vous avez récupéré une minute. Aux prix d’Opus 4.8, la partie sortie passe de 0,05 $ à 0,10 $ pour cette réponse. Ce compromis se justifie facilement quand un développeur senior attend.
Changeons maintenant de charge. Le modèle passe 70 secondes à lire des fichiers et à planifier, puis streame 400 tokens en 20 secondes. Une amélioration de streaming de 2,5× économise environ 12 secondes, pas 60. Vous payez quand même le double. C’est de là que vient la frustration Reddit : les gens subissent toute la facture de latence, mais la fonctionnalité de vitesse payante ne couvre parfois qu’une partie du problème.
GPT-5.5 Codex Fast Mode a une autre forme. Le multiplicateur publié est plus petit : génération 1,5× plus rapide pour 2,5× le coût dans Codex (OpenAI). Ce n’est pas séduisant si vous optimisez uniquement les dollars par token streamé. Cela peut quand même avoir du sens si Codex offre un meilleur TTFT, moins de blocages d’outils ou une boucle édition-test plus serrée pour votre projet. Un modèle plus lent sur le papier peut sembler plus rapide quand le harnais est meilleur.
Pour le code limité par la latence, mesurez le temps mural de la tâche, pas les tokens par seconde. La métrique devrait être :
time_from_prompt_to_accepted_patch = planning + tool_calls + streaming + test_fix_retriesSi Fast Mode n’améliore qu’un seul terme, ce n’est pas toute la réponse.
Utilisez Opus 4.8 Fast quand…
Choisissez Claude Opus 4.8 Fast Mode quand la tâche a besoin du jugement façon Opus et que vous êtes là, à attendre.
Bons exemples :
- Relire une migration de base de données risquée avant merge.
- Refactorer une large surface TypeScript où la cohérence de style compte.
- Demander à un agent d’inspecter plusieurs fichiers, proposer un plan, puis l’appliquer.
- Déboguer un comportement de production où un patch assuré mais faux coûte plus cher que des tokens.
- Travailler en binôme interactif, pendant que vous lisez la réponse au fil du streaming.
Anthropic affirme qu’Opus 4.8 est environ quatre fois moins susceptible que son prédécesseur de laisser passer sans commentaire des défauts dans le code qu’il a écrit (Anthropic). C’est la revendication de qualité importante pour le code. Fast Mode ne rend pas prudent un modèle négligent. Il rend le modèle prudent moins agaçant à utiliser.
Le prix est le piège. À 50 $/M en sortie, Opus 4.8 Fast est cher pour les traces agentiques verbeuses, la doc générée et les patchs ratés à répétition. Il faut l’associer à des contrôles stricts du harnais : petits diffs, réponses concises, résumés de repo mis en cache et règle ferme imposant au modèle d’inspecter avant d’éditer.
Si vous routez via un agrégateur, vérifiez le protocole réel et la disponibilité avant de passer en production. La page Claude Fable 5 de OneHop liste actuellement un prix officiel de 10 $/M en entrée et 50 $/M en sortie, un prix remisé OneHop de 3 $/M et 15 $/M, 10 $ de crédit gratuit pour les nouveaux comptes, et un endpoint Anthropic Messages à https://api.onehop.ai/anthropic ; la même page indique aussi que le modèle est temporairement indisponible au moment où je l’ai consultée (OneHop). Donc le choix sûr, c’est de tester la disponibilité dans votre propre compte avant de basculer du trafic de production.
Forme réelle du Anthropic SDK :
from anthropic import Anthropic
client = Anthropic(
api_key="ONEHOP_KEY",
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Review this patch for risky edge cases."}],
)
print(message.content[0].text)Si Fable 5 est disponible dans votre compte, Claude Fable 5 on OneHop mérite un test parce que le coût de mise en place est faible et que les nouveaux comptes peuvent démarrer avec 10 $ gratuits. Ne supposez simplement pas la disponibilité à partir d’une carte tarifaire. Appelez l’endpoint.
Utilisez GPT-5.5 Codex Fast quand…
Choisissez GPT-5.5 Codex Fast Mode quand vous vivez dans Codex et que toute la boucle vous importe plus que le flux de tokens.
L’article de lancement d’OpenAI donne GPT-5.5 à 82,7 % sur Terminal-Bench 2.0, contre 75,1 % pour GPT-5.4 et 69,4 % pour Claude Opus 4.7 dans le tableau d’OpenAI (OpenAI). Prenez les benchmarks de fournisseurs avec prudence, mais Terminal-Bench est pertinent pour les agents de code, parce que le travail shell, la gestion d’environnement et les boucles de réparation sont là où beaucoup de modèles « intelligents » perdent du temps.
GPT-5.5 est aussi moins cher qu’Opus Fast en sortie aux tarifs API standards : 30 $/M contre 50 $/M. Si vous générez beaucoup de code, de logs, d’explications et de sorties de tests, l’écart s’accumule. La fenêtre de contexte API de 1M le rend viable pour les workflows de grands repos dès que l’accès API est actif, tandis que la fenêtre de 400K de Codex est déjà assez large pour beaucoup de sessions interactives.
Le cas faible pour GPT-5.5 Fast, c’est l’économie de vitesse pure. Payer 2,5× pour une génération 1,5× plus rapide n’est pas un super échange si tout le reste est égal. Tout le reste est rarement égal. Codex peut gagner parce qu’il édite plus proprement, exécute mieux les commandes ou garde le développeur dans une boucle de revue plus fluide.
Utilisez GPT-5.5 Codex Fast pour :
- Les boucles édition-test-correction avec beaucoup d’interaction terminal.
- Les tâches où le volume de sortie générée est élevé.
- Les équipes déjà standardisées sur Codex.
- Les tâches où 400K de contexte suffisent.
- Les cas où le comportement à effort élevé d’Opus semble trop lent ou trop prudent.
Évitez-le quand la tâche exige le meilleur jugement de revue à long horizon que vous puissiez obtenir, ou quand le supplément Fast de 2,5× s’applique à de gros jobs en arrière-plan. Mettez-les en batch. OpenAI dit que Batch et Flex sont disponibles à la moitié du tarif API standard, tandis que Priority processing coûte 2,5× le standard (OpenAI). Le signal est clair : les chemins synchrones paient la priorité ; les chemins asynchrones ne devraient pas.
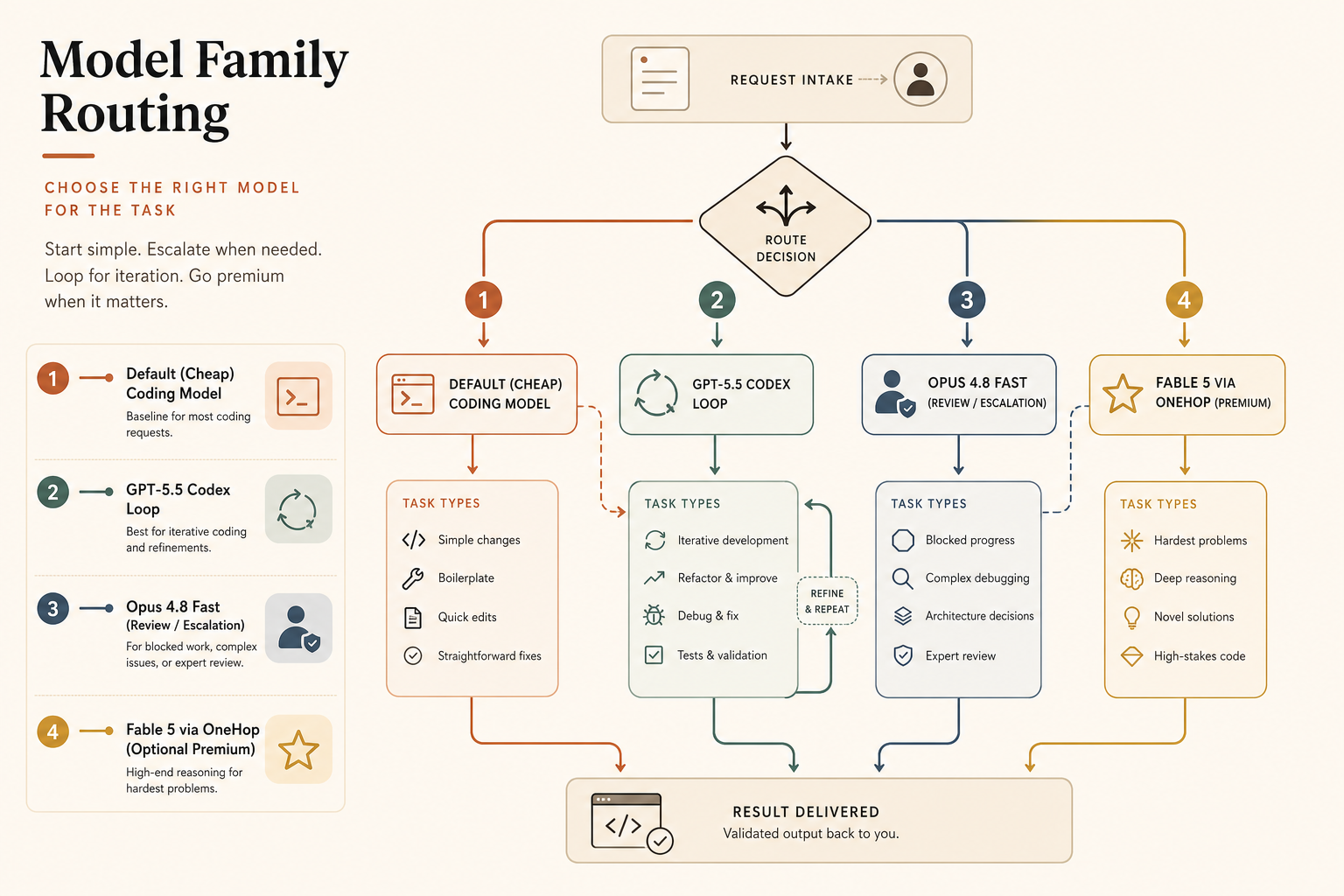
La recommandation
Prenez GPT-5.5 par défaut pour la plupart du trafic de code. Son prix catalogue API est plus bas qu’Opus 4.8 Fast en sortie, Codex a une UX centrée sur le code, et la fenêtre de contexte API de 1M supprime une grande raison historique de router tout le long contexte vers Claude.
Montez vers Claude Opus 4.8 Fast quand un humain est bloqué et que la qualité compte plus que les 20 $ supplémentaires par million de tokens de sortie par rapport à GPT-5.5 standard. Le meilleur cas d’usage n’est pas « rendre chaque réponse de code plus rapide ». C’est « faire arriver la réponse chère et prudente avant que je perde le contexte ».
Gardez Opus 4.8 standard pour le travail profond asynchrone. Si le modèle exécute une migration de codebase, lance des sous-agents ou analyse des centaines de milliers de lignes, la vitesse compte moins que la justesse, le cache et la discipline de retry. La fonctionnalité Dynamic Workflows d’Anthropic est construite pour ce genre de grosse tâche, y compris des migrations sur des centaines de milliers de lignes avec les tests comme seuil de validation (Anthropic).
Utilisez le routage façon OneHop comme raccourci de test, pas comme excuse pour éviter la mesure. Si vous voulez essayer un routage Claude haut de gamme avec peu de friction de mise en place, consultez Claude Fable 5 on OneHop, confirmez la disponibilité actuelle et démarrez avec 10 $ gratuits. Mesurez les patchs acceptés par dollar et le temps du prompt au merge. C’est le seul benchmark dont votre équipe se souciera encore la semaine prochaine.