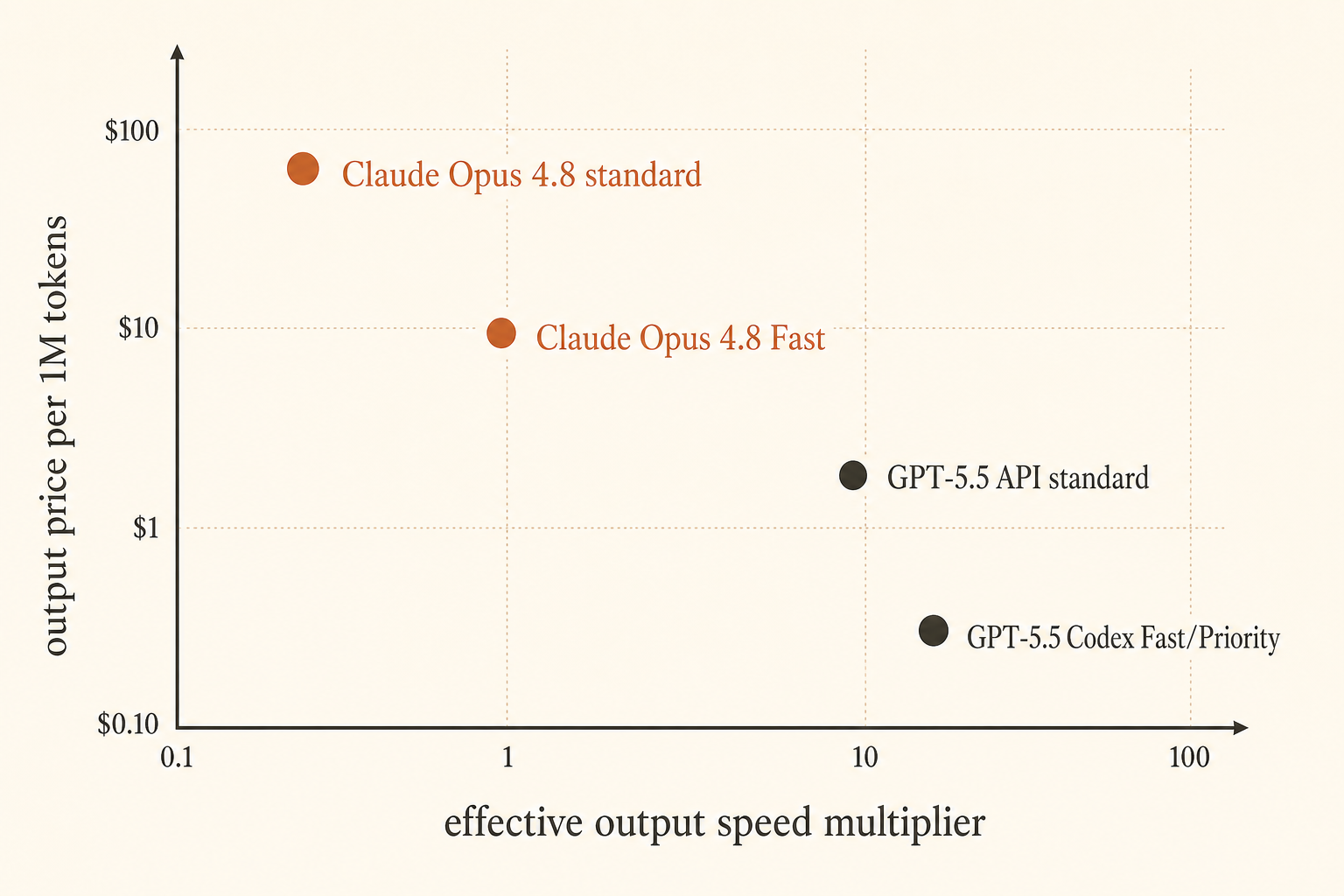
Anthropic 在 2026 年 5 月 28 日把价格问题摆得更尖锐了:Claude Opus 4.8 Fast Mode 现在最高可达到 2.5× 速度,价格是每百万输入 token 10 美元、每百万输出 token 50 美元(Anthropic)。OpenAI 则从另一个角度回应:Codex Fast Mode 中的 GPT-5.5 以 2.5× 成本换来 1.5× 更快的 token 生成速度,而 API 价格是每百万 token 输入 5 美元、输出 30 美元,并且 1M 上下文窗口也将进入 API(OpenAI)。
这听起来像供应商的数字游戏,直到你坐在 IDE 里等一个 agent 完成第三次失败的补丁尝试。那时延迟就不是基准测试里的脚注了。它决定你是继续保持心流,还是打开 Slack。
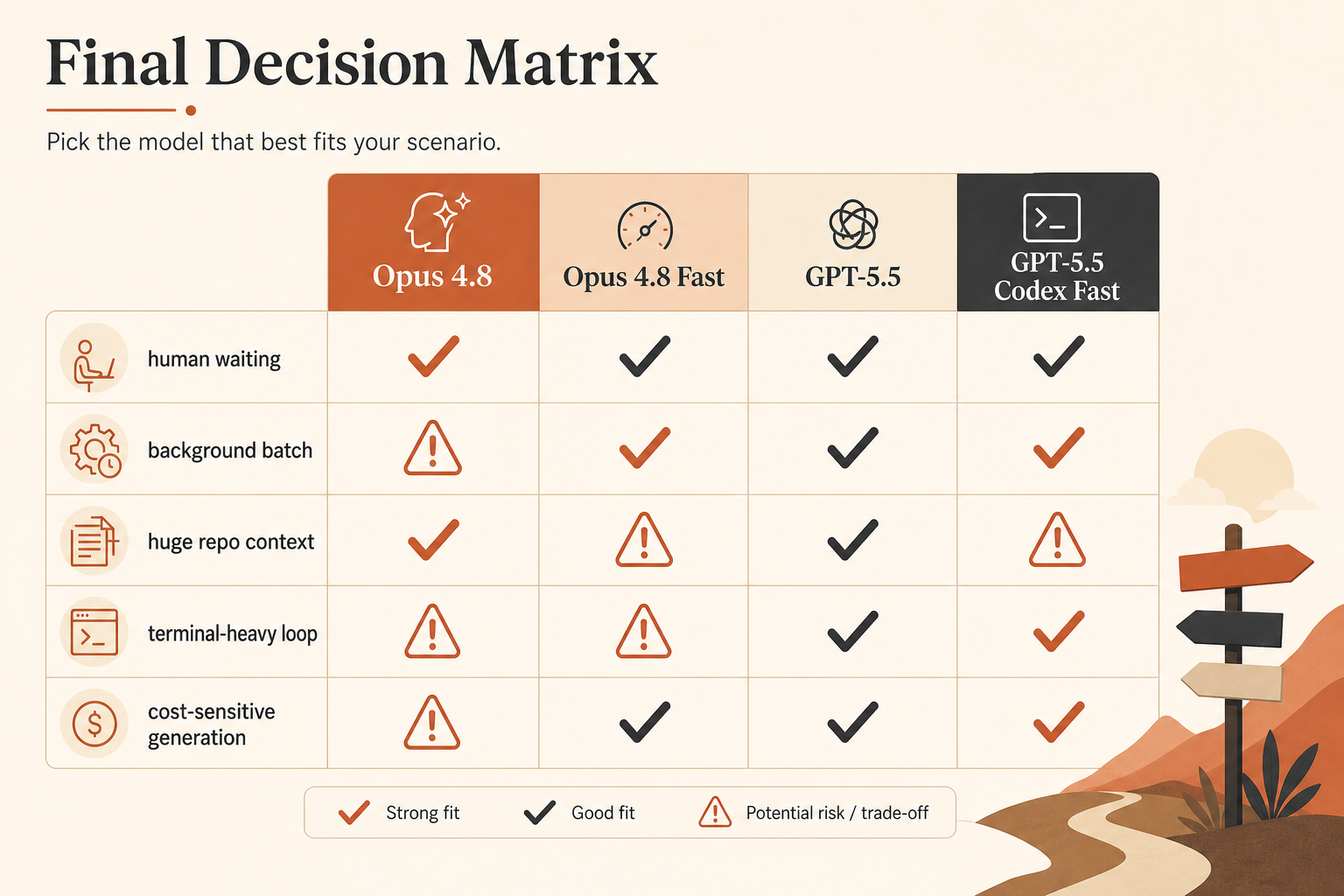
我的看法是:对延迟受限的编码来说,Opus 4.8 Fast Mode 是更干净的速度购买。GPT-5.5 则更适合作为默认选择:输出成本更低,终端表现强,Codex 循环也更紧。如果你的 agent 大多数时间都花在阅读、规划和调用工具上,别盲目买速度。先修循环。
真正有用的对比表
这是我在路由编码流量前真正会用的选择表。
| 选项 | 官方速度说法 | 输入价格 | 输出价格 | 上下文 | 最适合 |
|---|---|---|---|---|---|
| Claude Opus 4.8 | 基准 | $5/M | $25/M | Claude 文档中为 1M | 谨慎的 agentic coding、长仓库上下文 |
| Claude Opus 4.8 Fast Mode | 最高 2.5× 速度 | $10/M | $50/M | 完整上下文;Fast 适用于全窗口 | 人在环路中的延迟场景 |
| GPT-5.5 API | 基准 | $5/M | $30/M | 已宣布 1M API 窗口 | 通用编码,输出价格低于 Opus Fast |
| GPT-5.5 Codex Fast Mode | 1.5× token 生成速度 | 2.5× Codex 成本 | 2.5× Codex 成本 | Codex 中为 400K | UX 很重要的快速 Codex 会话 |
| GPT-5.5 API Priority 风格计价 | 更高速层级 | $12.50/M | $75/M | 已宣布 1M API 窗口 | 队列延迟重要的生产调用 |
Anthropic 的价格文档补充了两个开发者常忽略的细节。第一,Fast Mode 仍处于研究预览阶段。第二,它适用于“完整上下文窗口”,包括超过 200K token 的请求(Anthropic docs)。同一份文档还说,Claude Opus 4.8、Opus 4.7、Opus 4.6、Fable 5 和 Mythos-class 模型在标准价格下包含完整的 1M-token 上下文。
OpenAI 的公开价格页列出 GPT-5.5 为每百万输入 5 美元、缓存输入 0.50 美元、输出 30 美元(OpenAI pricing)。发布文章说 Codex 获得 GPT-5.5,配备 400K 上下文窗口,并提供 Fast Mode:以 2.5× 成本换取 1.5× 生成速度。API 是另一条线:GPT-5.5 “即将”在 Responses 和 Chat Completions 中提供 1M 上下文窗口。
这个区分很重要。Codex Fast Mode 是产品模式层面的决定。GPT-5.5 API 定价是 token 计量层面的决定。除非你把行标清楚,否则别把它们混在同一个电子表格里。
开发者为什么在抱怨
Reddit 上的抱怨一点也不含蓄。一个题为“Why is Opus 4.8 so slow?”的帖子说这个模型感觉退化而且很慢,有评论者把变慢解读成一种推动 Fast Mode 变现的方式(Reddit)。另一个 r/ClaudeCode 线程称 Opus 4.8 “smart, but careful and slow”,用户们则争论真正的罪魁祸首是不是高 effort 设置(Reddit)。还有一个关于首 token 时间的帖子说,与 Codex 相比,体感响应性简直是“night and day”(Reddit)。
社区其实把四个不同问题混在了一起:
- 首 token 时间。
- 每秒输出 token 数。
- 隐藏推理或 effort 时间。
- 工具循环浪费:反复读文件、重复 shell 调用、过度规划。
Fast Mode 主要攻击第二类问题。它可能也会因为服务容量而改善第一类,但公开说法强调的是输出速度。如果你的 agent 在打印 300 个 token 前,先花 80 秒思考、读文件、重试坏命令,那么为更快输出付费就是一个很弱的修补。
Anthropic 自己的发布说明也暗示了这一点。Opus 4.8 默认是高 effort,而更高 effort 模式会花更多时间思考,以换取更好的结果。Anthropic 建议在困难任务和长时间运行的异步工作流中使用额外 effort(Anthropic)。这对仓库迁移很合理。对“重命名这个 prop 并更新测试”就很痛苦。
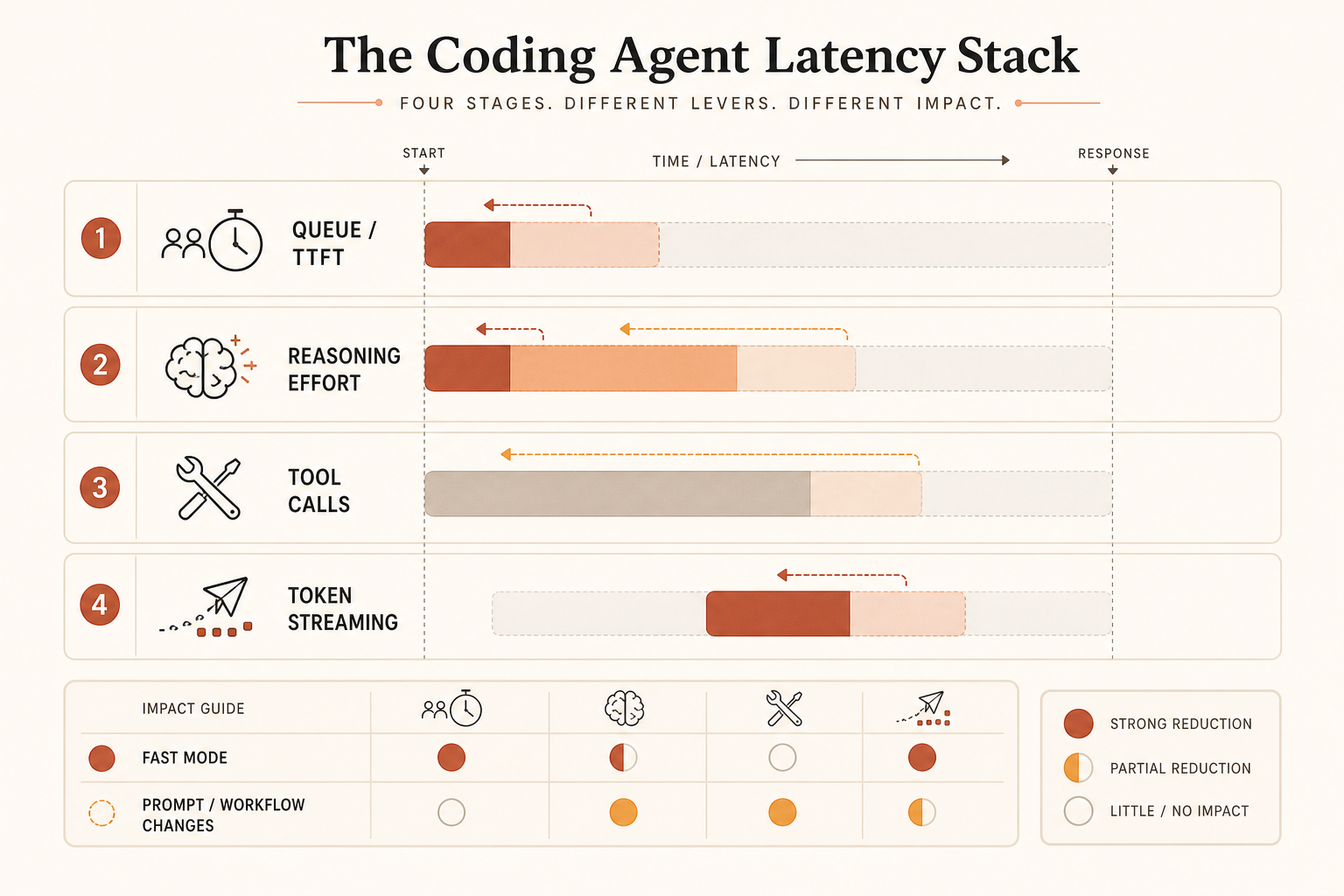
什么时候为速度付费是理性的
用一个简单规则:只有在人被卡住,而且生成输出大到足以让 token 流式输出成为主导时,才买 Fast Mode。
假设一次编码回复会输出 2,000 个 token。如果标准 Opus 流式输出这些内容需要 100 秒,而 Fast Mode 接近宣传的 2.5×,流式时间会降到大约 40 秒。你买回了一分钟。按 Opus 4.8 的价格,这次回复的输出部分从 0.05 美元变成 0.10 美元。当一位资深开发者正在等待时,这笔交换很容易说得通。
现在换一种工作负载。模型花 70 秒读文件和规划,然后用 20 秒流式输出 400 个 token。2.5× 的流式提升大约只省 12 秒,而不是 60 秒。你仍然要付双倍。这就是 Reddit 上那种挫败感的来源:人们感受到的是完整的延迟账单,但付费加速功能可能只覆盖其中一部分。
GPT-5.5 Codex Fast Mode 的形状不同。公开倍数更小:在 Codex 中以 2.5× 成本换取 1.5× 更快生成(OpenAI)。如果你优化的是每个流式 token 的纯美元成本,这并不诱人。但如果 Codex 有更好的 TTFT、更少的工具卡顿,或者对你的项目有更紧的编辑-测试循环,它仍然可能有意义。纸面上更慢的模型,在更好的 harness 里可能体感更快。
对延迟受限的编码,衡量端到端任务耗时,而不是每秒 token。指标应该是:
time_from_prompt_to_accepted_patch = planning + tool_calls + streaming + test_fix_retries如果 Fast Mode 只改善其中一项,它就不是完整答案。
什么时候用 Opus 4.8 Fast
当任务需要 Opus 风格判断力,而且你正坐在那里等时,选择 Claude Opus 4.8 Fast Mode。
好的例子:
- 合并前审查有风险的数据库迁移。
- 重构大面积 TypeScript 接口,且风格一致性很重要。
- 让 agent 检查多个文件、提出计划,然后执行。
- 调试生产行为,此时一个自信但错误的补丁比 token 贵得多。
- 交互式结对,你会边流式输出边阅读回复。
Anthropic 称,Opus 4.8 比前代模型低约四倍概率会让自己写出的代码缺陷未经评论就通过(Anthropic)。这才是对编码最重要的质量主张。Fast Mode 不会让粗心的模型变谨慎。它会让谨慎的模型用起来没那么烦。
问题在价格。每百万输出 50 美元,Opus 4.8 Fast 对冗长的 agent trace、生成文档和反复失败的补丁来说很贵。你应该把它和严格的 harness 控制配套使用:小 diff、简洁回复、缓存的仓库摘要,以及一条硬规则:模型编辑前必须先检查。
如果你通过聚合器路由,上线前要检查真实协议和可用性。OneHop 的 Claude Fable 5 页面目前列出官方价格为每百万输入 10 美元、输出 50 美元,OneHop 折扣价为 3 美元和 15 美元,新账户 10 美元免费额度,以及 Anthropic Messages 端点 https://api.onehop.ai/anthropic;同一页面在我查看时也标记该模型暂时不可用(OneHop)。这意味着安全做法是在切换生产流量前,先用你自己的账户测试可用性。
真实的 Anthropic SDK 形状:
from anthropic import Anthropic
client = Anthropic(
api_key="ONEHOP_KEY",
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Review this patch for risky edge cases."}],
)
print(message.content[0].text)如果你的账户里 Fable 5 可用,Claude Fable 5 on OneHop 值得测试,因为设置成本很低,而且新账户可从 10 美元免费额度开始。只是别从价格卡片假设它可用。调用端点。
什么时候用 GPT-5.5 Codex Fast
当你长期待在 Codex 里,并且比起 token 流更关心整个循环时,选择 GPT-5.5 Codex Fast Mode。
OpenAI 的发布文章称,GPT-5.5 在 Terminal-Bench 2.0 上达到 82.7%,相比之下 OpenAI 表中的 GPT-5.4 为 75.1%,Claude Opus 4.7 为 69.4%(OpenAI)。供应商基准要谨慎看待,但 Terminal-Bench 对编码 agent 很相关,因为 shell 工作、环境处理和修复循环正是很多“聪明”模型浪费时间的地方。
按标准 API 价格,GPT-5.5 的输出也比 Opus Fast 便宜:每百万 30 美元,对比 50 美元。如果你生成大量代码、日志、解释和测试输出,这个差距会不断放大。1M API 上下文窗口在 API 访问上线后,让大仓库工作流变得可行,而 Codex 的 400K 窗口已经足够支撑许多交互式会话。
GPT-5.5 Fast 的弱点是纯速度经济学。如果其他条件都一样,为 1.5× 更快生成支付 2.5× 价格,不是什么好交换。但其他条件很少一样。Codex 可能赢在编辑更干净、命令运行更好,或者能让开发者处在更顺滑的审查循环里。
把 GPT-5.5 Codex Fast 用在:
- 有大量终端交互的编辑-测试-修复循环。
- 生成输出量很高的工作。
- 已经标准化使用 Codex 的团队。
- 400K 上下文足够的任务。
- Opus 高 effort 行为感觉太慢或太谨慎的场景。
当任务需要你能拿到的最强长程审查判断时,或者 2.5× Fast 附加费被用于大批量后台作业时,就别用它。把那些批处理掉。OpenAI 表示 Batch 和 Flex 可按标准 API 价格半价使用,而 Priority processing 是标准价的 2.5×(OpenAI)。这是一个很强的暗示:同步路径为优先级付费;异步路径不该付。
建议
大多数编码流量默认用 GPT-5.5。它的 API 标价在输出上低于 Opus 4.8 Fast,Codex 有专注编码的 UX,而 1M API 上下文窗口也移除了过去把所有长上下文都路由到 Claude 的一个主要理由。
当人被卡住,而且质量比相对 GPT-5.5 标准每百万输出多出的 20 美元更重要时,再升级到 Claude Opus 4.8 Fast。最好的用例不是“让每次编码回复都更快”。而是“让昂贵、谨慎的答案在我丢失上下文前到达”。
把标准 Opus 4.8 留给异步深度工作。如果模型正在跑代码库迁移、启动 subagents,或分析数十万行代码,速度就不如正确性、缓存和重试纪律重要。Anthropic 的 Dynamic Workflows 功能正是为这类大型任务设计的,包括跨数十万行代码、以测试为门槛的迁移(Anthropic)。
把 OneHop 风格路由当作测试捷径,而不是跳过测量的借口。如果你想用较低设置摩擦尝试高端 Claude 路由,查看 Claude Fable 5 on OneHop,确认当前可用性,并且从 10 美元免费额度开始。衡量每美元接受补丁数,以及从提示到合并的时间。这才是你的团队下周仍然会关心的唯一基准。