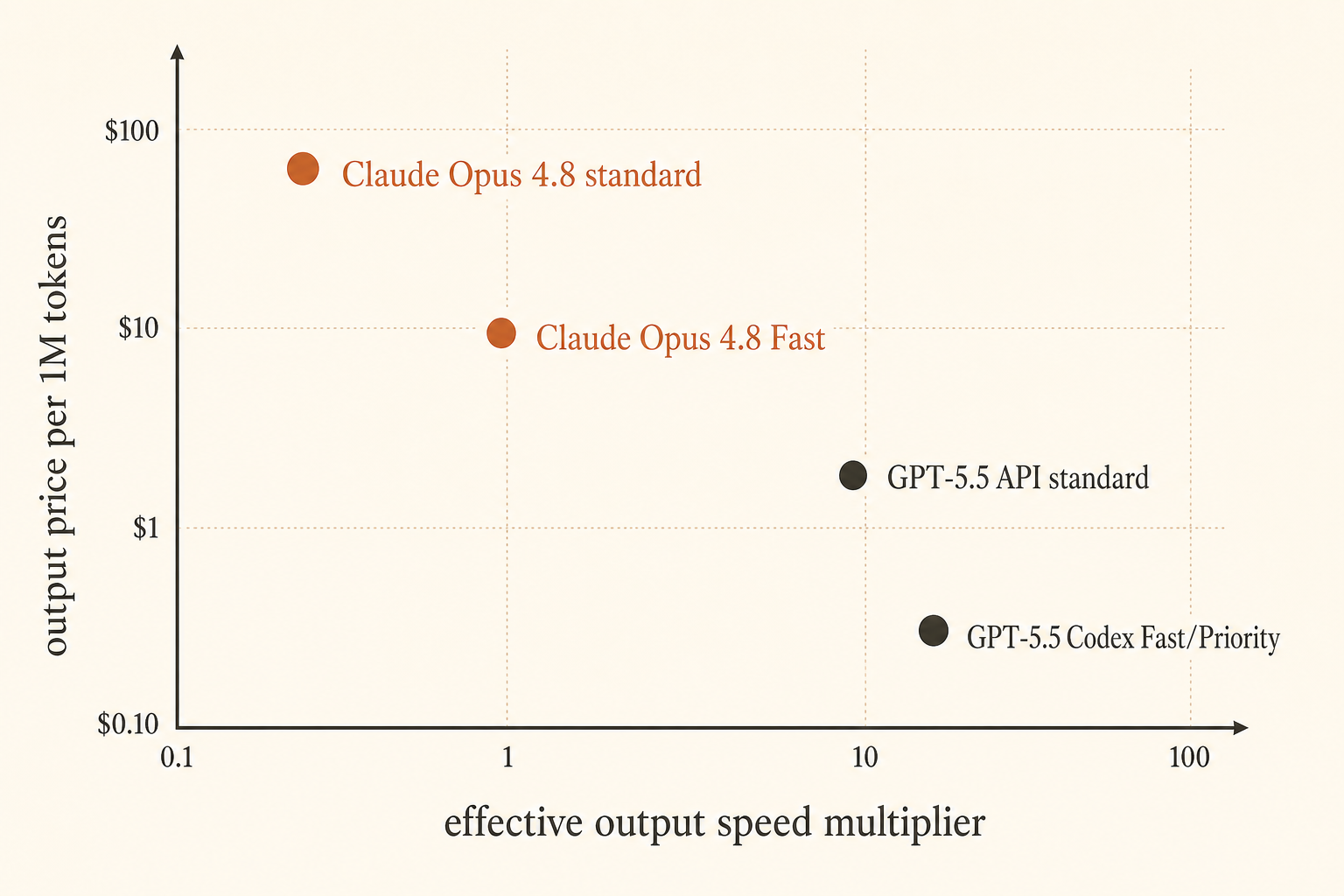
Anthropic hat das Preisproblem am 28. Mai 2026 zugespitzt: Claude Opus 4.8 Fast Mode läuft jetzt mit bis zu 2,5× Geschwindigkeit und kostet 10 $ pro Million Input-Tokens und 50 $ pro Million Output-Tokens (Anthropic). OpenAI hat aus einer anderen Richtung geantwortet: GPT-5.5 in Codex Fast Mode generiert Tokens 1,5× schneller für 2,5× Kosten, während der API-Preis bei 5 $ Input und 30 $ Output pro Million Tokens liegt und ein 1M-Kontextfenster für die API kommen soll (OpenAI).
Das klingt nach Anbieter-Mathe, bis du in einer IDE sitzt und darauf wartest, dass ein Agent den dritten fehlgeschlagenen Patch-Versuch beendet. Dann ist Latenz keine Benchmark-Fußnote. Sie ist der Unterschied zwischen im Flow bleiben und Slack öffnen.
Meine Einschätzung: Für latenzgebundenes Coding ist Opus 4.8 Fast Mode der sauberere Speed-Kauf. GPT-5.5 ist der bessere Default, wenn du niedrigere Output-Kosten, starke Terminal-Performance und einen engeren Codex-Loop willst. Wenn dein Agent die meiste Zeit mit Lesen, Planen und Tool-Aufrufen verbringt, kauf Geschwindigkeit nicht blind. Reparier zuerst den Loop.
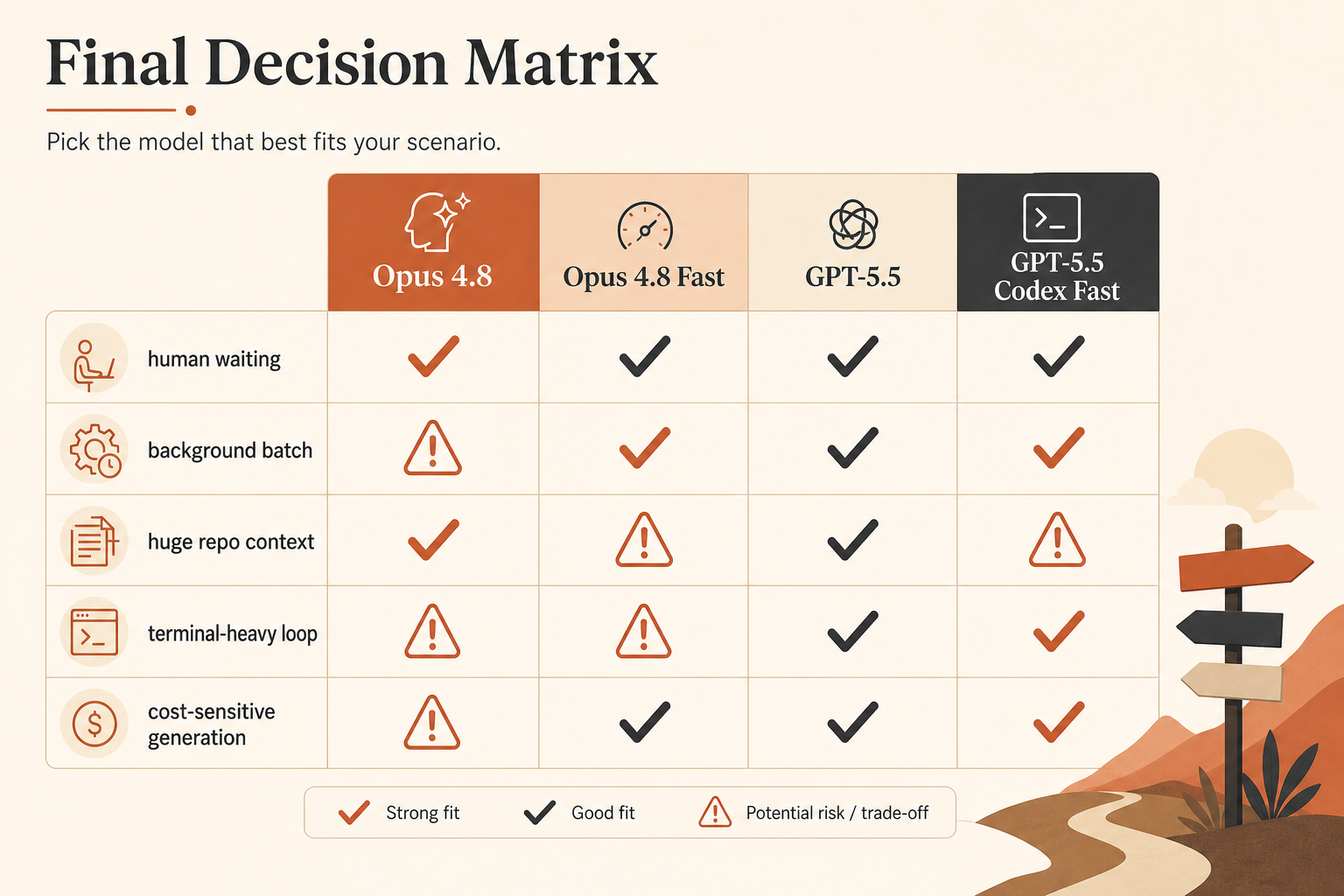
Die echte Vergleichstabelle
Das ist die Auswahl-Tabelle, die ich tatsächlich nutzen würde, bevor ich Coding-Traffic route.
| Option | Veröffentlichte Geschwindigkeitsaussage | Input-Preis | Output-Preis | Kontext | Am besten geeignet für |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Basiswert | $5/M | $25/M | 1M in Claude-Dokumentation | sorgfältiges agentisches Coding, langer Repo-Kontext |
| Claude Opus 4.8 Fast Mode | bis zu 2,5× Geschwindigkeit | $10/M | $50/M | voller Kontext; Fast gilt durchgehend | Human-in-the-loop-Latenz |
| GPT-5.5 API | Basiswert | $5/M | $30/M | 1M API-Fenster angekündigt | allgemeines Coding, niedrigerer Output-Preis als Opus Fast |
| GPT-5.5 Codex Fast Mode | 1,5× Token-Generierung | 2,5× Codex-Kosten | 2,5× Codex-Kosten | 400K in Codex | schnelle Codex-Sessions, bei denen UX zählt |
| GPT-5.5 API Priority-artige Rechnung | Tier mit höherer Geschwindigkeit | $12.50/M | $75/M | 1M API-Fenster angekündigt | Produktionsaufrufe, bei denen Queue-Latenz zählt |
Anthropics Pricing-Dokumentation ergänzt zwei Details, die Entwickler oft übersehen. Erstens ist Fast Mode noch in der Research Preview. Zweitens gilt er „über das volle Kontextfenster hinweg“, auch bei Requests über 200K Tokens (Anthropic docs). Dieselbe Dokumentation sagt, dass Claude Opus 4.8, Opus 4.7, Opus 4.6, Fable 5 und Mythos-Klassenmodelle den vollen 1M-Token-Kontext zum Standardpreis enthalten.
OpenAIs öffentliche Preisseite listet GPT-5.5 mit 5 $/M Input, 0,50 $/M gecachtem Input und 30 $/M Output (OpenAI pricing). Der Launch-Post sagt, dass Codex GPT-5.5 mit einem 400K-Kontextfenster und Fast Mode bei 1,5× Generierungsgeschwindigkeit für 2,5× Kosten bekommt. Die API-Story ist davon getrennt: GPT-5.5 ist „bald“ in Responses und Chat Completions mit einem 1M-Kontextfenster verfügbar.
Diese Trennung ist wichtig. Codex Fast Mode ist eine Produktmodus-Entscheidung. GPT-5.5 API-Pricing ist eine Token-Zähler-Entscheidung. Misch sie nicht in einer Tabelle, außer du beschriftest die Zeilen sauber.
Warum Entwickler sich beschweren
Die Reddit-Beschwerde ist nicht subtil. Ein Thread mit dem Titel „Why is Opus 4.8 so slow?“ sagt, das Modell fühle sich schlechter und langsam an, wobei ein Kommentar die Verlangsamung als Weg deutet, Fast Mode zu monetarisieren (Reddit). Ein anderer r/ClaudeCode-Thread nennt Opus 4.8 „smart, but careful and slow“, während Nutzer darüber streiten, ob High-Effort-Einstellungen der eigentliche Schuldige sind (Reddit). Ein separater Thread zur Time-to-first-token sagt, der Vergleich mit Codex sei bei der wahrgenommenen Reaktionsfähigkeit „night and day“ (Reddit).
Die Community vermischt vier verschiedene Probleme:
- Time to first token.
- Output-Tokens pro Sekunde.
- Verdeckte Reasoning- oder Effort-Zeit.
- Tool-Loop-Verschwendung: Dateien erneut lesen, redundante Shell-Aufrufe, Over-Planning.
Fast Mode greift hauptsächlich den zweiten Bereich an. Je nach Serving-Kapazität kann er beim ersten helfen, aber die öffentliche Aussage betrifft Output-Geschwindigkeit. Wenn dein Agent 80 Sekunden mit Denken, Dateienlesen und dem Wiederholen kaputter Befehle verbringt, bevor er 300 Tokens ausgibt, ist schnellerer Output ein schwacher Fix.
Anthropics eigene Launch-Notiz deutet das an. Opus 4.8 nutzt standardmäßig High Effort, und höhere Effort-Modi verbringen mehr Zeit mit Nachdenken, um bessere Ergebnisse zu liefern. Anthropic empfiehlt zusätzlichen Effort für schwierige Aufgaben und lang laufende asynchrone Workflows (Anthropic). Das ist sinnvoll für Repo-Migrationen. Es ist schmerzhaft für „benenn diese Prop um und aktualisiere die Tests.“
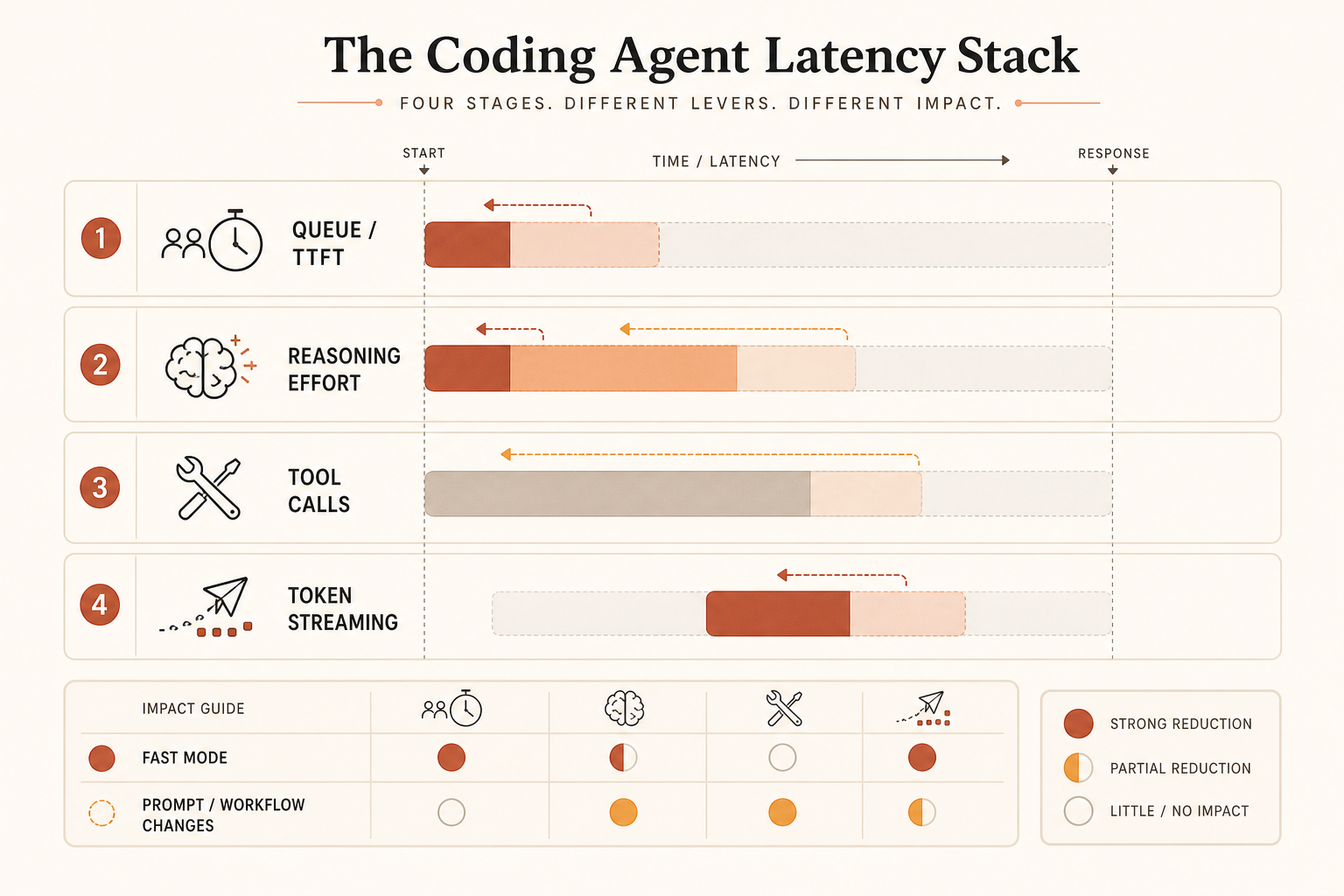
Wann es rational ist, für Geschwindigkeit zu zahlen
Nutze eine einfache Regel: Kauf Fast Mode nur, wenn der Mensch blockiert ist und der generierte Output groß genug ist, dass Token-Streaming dominiert.
Angenommen, eine Coding-Antwort gibt 2.000 Output-Tokens aus. Wenn Standard-Opus 100 Sekunden braucht, um diesen Output zu streamen, und Fast Mode nah an die beworbenen 2,5× kommt, sinkt die Streaming-Zeit auf etwa 40 Sekunden. Du kaufst dir eine Minute zurück. Bei Opus-4.8-Preisen steigt der Output-Anteil für diese Antwort von 0,05 $ auf 0,10 $. Dieser Deal ist leicht zu rechtfertigen, wenn ein Senior Developer wartet.
Ändere jetzt den Workload. Das Modell verbringt 70 Sekunden mit Dateienlesen und Planen und streamt dann 400 Tokens in 20 Sekunden. Eine 2,5× Verbesserung beim Streaming spart grob 12 Sekunden, nicht 60. Du zahlst trotzdem das Doppelte. Daher kommt der Reddit-Frust: Leute spüren die volle Latenzrechnung, aber das bezahlte Speed-Feature deckt vielleicht nur einen Teil davon ab.
GPT-5.5 Codex Fast Mode hat eine andere Form. Der veröffentlichte Multiplikator ist kleiner: 1,5× schnellere Generierung für 2,5× Kosten in Codex (OpenAI). Das ist nicht attraktiv, wenn du reine Dollar pro gestreamtem Token optimierst. Es kann trotzdem sinnvoll sein, wenn Codex bessere TTFT, weniger Tool-Stalls oder einen engeren Edit-Test-Loop für dein Projekt hat. Ein Modell, das auf dem Papier langsamer ist, kann sich schneller anfühlen, wenn das Harness besser ist.
Miss bei latenzgebundenem Coding die Wall-Clock-Zeit bis zur Aufgabe, nicht Tokens pro Sekunde. Die Metrik sollte sein:
time_from_prompt_to_accepted_patch = planning + tool_calls + streaming + test_fix_retriesWenn Fast Mode nur einen Term verbessert, ist er nicht die ganze Antwort.
Nutze Opus 4.8 Fast, wenn …
Wähle Claude Opus 4.8 Fast Mode, wenn die Aufgabe Opus-artiges Urteilsvermögen braucht und du daneben sitzt und wartest.
Gute Beispiele:
- Eine riskante Datenbankmigration vor dem Merge prüfen.
- Eine große TypeScript-Fläche refactoren, bei der Stil-Konsistenz zählt.
- Einen Agent bitten, mehrere Dateien zu inspizieren, einen Plan vorzuschlagen und ihn dann umzusetzen.
- Produktionsverhalten debuggen, bei dem ein falscher, selbstsicherer Patch mehr kostet als Tokens.
- Interaktiv pairen, während du die Antwort beim Streamen liest.
Anthropic behauptet, Opus 4.8 sei etwa viermal weniger wahrscheinlich als sein Vorgänger, Fehler in selbst geschriebenem Code unkommentiert durchgehen zu lassen (Anthropic). Das ist die wichtige Qualitätsaussage fürs Coding. Fast Mode macht kein sorgloses Modell sorgfältig. Er macht das sorgfältige Modell weniger nervig in der Nutzung.
Der Preis ist der Haken. Mit 50 $/M Output ist Opus 4.8 Fast teuer für ausführliche Agent-Traces, generierte Doku und wiederholte fehlgeschlagene Patches. Du solltest ihn mit strikten Harness-Kontrollen kombinieren: kleine Diffs, knappe Antworten, gecachte Repo-Zusammenfassungen und eine harte Regel, dass das Modell vor dem Editieren inspizieren muss.
Wenn du über einen Aggregator routest, prüfe vor dem Shipping das echte Protokoll und die Verfügbarkeit. OneHops Claude Fable 5-Seite listet derzeit offizielles Pricing von 10 $/M Input und 50 $/M Output, einen rabattierten OneHop-Preis von 3 $/M und 15 $/M, 10 $ Gratisguthaben für neue Accounts und einen Anthropic Messages-Endpunkt unter https://api.onehop.ai/anthropic; dieselbe Seite markiert das Modell zum Zeitpunkt meiner Prüfung aber auch als vorübergehend nicht verfügbar (OneHop). Der sichere Schritt ist also, die Verfügbarkeit in deinem eigenen Account zu testen, bevor du Produktions-Traffic umstellst.
Echte Anthropic SDK-Form:
from anthropic import Anthropic
client = Anthropic(
api_key="ONEHOP_KEY",
base_url="https://api.onehop.ai/anthropic",
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=1024,
messages=[{"role": "user", "content": "Review this patch for risky edge cases."}],
)
print(message.content[0].text)Wenn Fable 5 in deinem Account verfügbar ist, ist Claude Fable 5 auf OneHop einen Test wert, weil der Setup-Aufwand gering ist und neue Accounts mit 10 $ gratis starten können. Geh nur nicht davon aus, dass eine Pricing-Karte Verfügbarkeit garantiert. Ruf den Endpunkt auf.
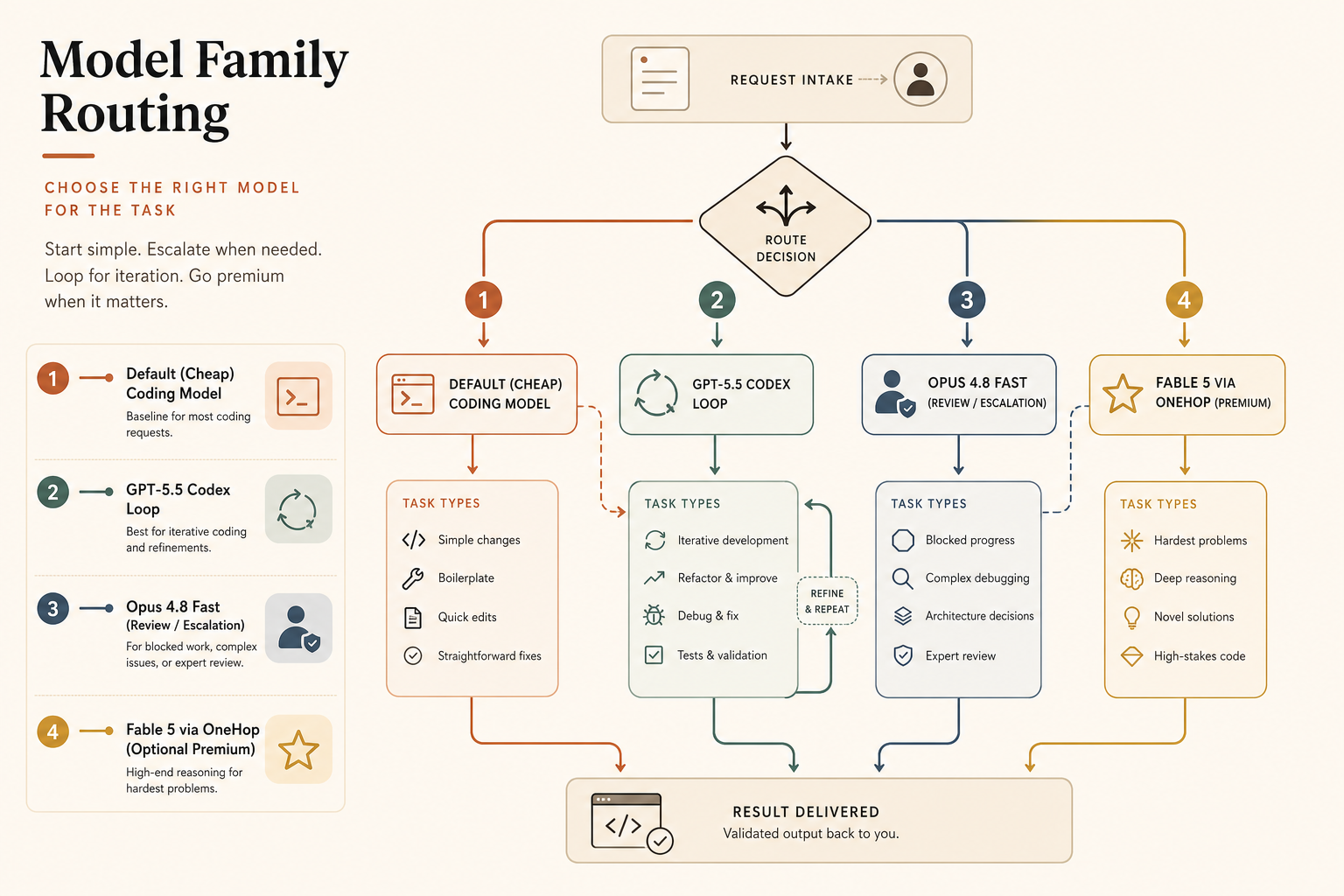
Nutze GPT-5.5 Codex Fast, wenn …
Wähle GPT-5.5 Codex Fast Mode, wenn du in Codex lebst und dir der ganze Loop wichtiger ist als der Token-Stream.
OpenAIs Launch-Post meldet GPT-5.5 mit 82,7 % auf Terminal-Bench 2.0, verglichen mit 75,1 % für GPT-5.4 und 69,4 % für Claude Opus 4.7 in OpenAIs Tabelle (OpenAI). Behandle Anbieter-Benchmarks vorsichtig, aber Terminal-Bench ist für Coding-Agenten relevant, weil Shell-Arbeit, Environment-Handling und Repair-Loops genau dort liegen, wo viele „smarte“ Modelle Zeit verschwenden.
GPT-5.5 ist bei Standard-API-Raten auch günstiger als Opus Fast beim Output: 30 $/M gegenüber 50 $/M. Wenn du viel Code, Logs, Erklärungen und Test-Output generierst, summiert sich diese Lücke. Das 1M-API-Kontextfenster macht es für Large-Repo-Workflows brauchbar, sobald API-Zugang live ist, während Codex’ 400K-Fenster schon für viele interaktive Sessions groß genug ist.
Der schwache Case für GPT-5.5 Fast ist reine Speed-Ökonomie. 2,5× zu zahlen für 1,5× schnellere Generierung ist kein toller Tausch, wenn alles andere gleich ist. Alles andere ist selten gleich. Codex kann gewinnen, weil es sauberer editiert, Befehle besser ausführt oder den Entwickler in einem glatteren Review-Loop hält.
Nutze GPT-5.5 Codex Fast für:
- Edit-Test-Fix-Loops mit viel Terminal-Interaktion.
- Arbeit mit hohem Volumen an generiertem Output.
- Teams, die bereits auf Codex standardisiert sind.
- Aufgaben, bei denen 400K Kontext reichen.
- Fälle, in denen Opus-High-Effort-Verhalten zu langsam oder zu vorsichtig wirkt.
Vermeide es, wenn die Aufgabe das stärkste langfristige Review-Urteilsvermögen braucht, das du bekommen kannst, oder wenn der 2,5× Fast-Aufschlag auf große Background-Jobs angewendet wird. Batche die. OpenAI sagt, Batch und Flex seien zur Hälfte des Standard-API-Preises verfügbar, während Priority Processing 2,5× Standard kostet (OpenAI). Das ist ein deutlicher Hinweis: Synchrone Pfade zahlen für Priority; asynchrone Pfade sollten es nicht.
Die Empfehlung
Nutze GPT-5.5 als Default für den meisten Coding-Traffic. Sein API-Listenpreis ist beim Output niedriger als Opus 4.8 Fast, Codex hat eine fokussierte Coding-UX, und das 1M-API-Kontextfenster beseitigt einen wichtigen historischen Grund, alles mit langem Kontext zu Claude zu routen.
Eskaliere zu Claude Opus 4.8 Fast, wenn ein Mensch blockiert ist und Qualität wichtiger ist als die zusätzlichen 20 $ pro Million Output-Tokens gegenüber GPT-5.5 Standard. Der beste Use Case ist nicht „mach jede Coding-Antwort schneller“. Er ist: „Lass die teure, sorgfältige Antwort ankommen, bevor ich den Kontext verliere.“
Behalte Standard-Opus 4.8 für asynchrone Deep Work. Wenn das Modell eine Codebase-Migration ausführt, Subagents startet oder Hunderttausende Zeilen analysiert, sind Korrektheit, Caching und Retry-Disziplin wichtiger als Geschwindigkeit. Anthropics Dynamic Workflows-Feature ist für genau diese Art großer Aufgabe gebaut, einschließlich Migrationen über Hunderttausende Zeilen hinweg, bei denen Tests die Messlatte sind (Anthropic).
Nutze OneHop-artiges Routing als Test-Abkürzung, nicht als Ausrede, Messung zu überspringen. Wenn du höherwertiges Claude-Routing mit wenig Setup-Reibung ausprobieren willst, prüfe Claude Fable 5 auf OneHop, bestätige die aktuelle Verfügbarkeit und starte mit 10 $ gratis. Miss akzeptierte Patches pro Dollar und Zeit von Prompt bis Merge. Das ist der einzige Benchmark, der deinem Team nächste Woche noch wichtig sein wird.