6 月 16 日,Anthropic 自家的狀態頁記錄了一個生產工程師真正該在意的數字:所有 Sonnet 與 Opus 模型在 37 分鐘內錯誤率約達 10%,接著 Claude Opus 4.8 又以平均 10% 錯誤率持續了 80 分鐘(Claude Status)。如果你的應用在面向使用者的流程中呼叫 Claude,這就不是什麼「稍後再試」的小麻煩。這是一次架構檢討。
事情還沒完。Claude Status 顯示,從 6 月 16 日到 6 月 19 日,Opus 4.8 與更廣泛的 Claude 服務反覆出現事故:6 月 16 日有三起 Opus 專屬事故,6 月 17 日又有四起 Opus/Sonnet 或僅 Opus 的事故,6 月 18 日發生 Claude services 中斷,6 月 19 日則有兩起 API 或 Opus 4.8 事故(Claude Status)。截至 6 月 20 日,頁面顯示今天沒有回報事故,但最近的模式已經夠清楚了。
Anthropic 在 5 月 28 日推出 Claude Opus 4.8,作為 Opus 4.7 的同價升級版,並將它定位為更強的協作者,具備更好的 benchmark 表現與更高的誠實度(Anthropic)。這些可能都是真的。但它不會改變營運現實:如果 Opus 4.8 位在你的關鍵路徑上,你的應用現在就需要真正的失效模式。
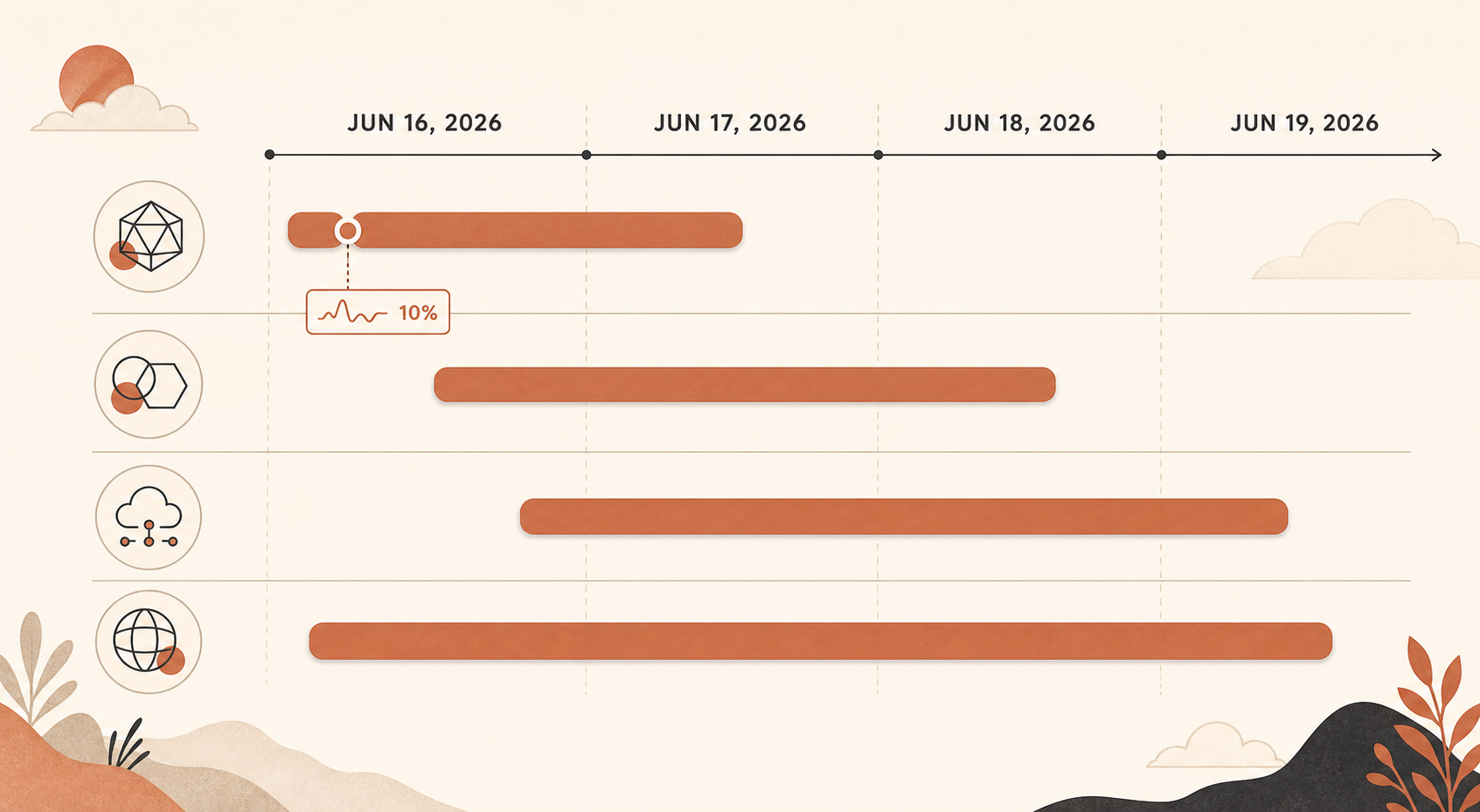
發生了什麼,按 UTC 時間看
關鍵事故始於 6 月 16 日 17:29 UTC,當時 Claude Status 針對多個模型的錯誤升高展開調查。Anthropic 後來將它總結為兩個階段:17:23 到 18:00 UTC,所有 Sonnet 與 Opus 模型都受影響,錯誤率約達 10%;18:00 到 19:20 UTC,只有 Opus 4.8 平均錯誤率維持在 10%(Claude Status)。
接著是規模較小、但依然很痛的 Opus 4.8 尖峰。6 月 16 日,Claude Status 另行記錄了約 19:41–19:53 UTC 的 Opus 4.8 錯誤,以及 20:45–20:58 UTC 的另一場 Opus 4.8 事故(Claude Status)。6 月 17 日則有多起 Opus 4.8 事故,包括一次請求在 04:59 到 05:41 UTC 期間收到較高錯誤率,另一次是 Sonnet 4.6 加 Opus 4.8 的事故,其中 Sonnet 先恢復,而 Opus 4.8 仍需要處理(Claude Status)。
6 月 18 日影響範圍更廣:Claude Status 表示,06:55 到 07:40 UTC 之間有服務中斷影響 Claude services(Claude Status)。6 月 19 日接著出現 06:07 到 07:17 UTC 的 Opus 4.8 事故,以及 08:17 到 08:45 UTC 另一場「Claude API 錯誤率升高」事故(Claude Status)。
這條時間線很重要,因為它不是一次乾淨俐落的 outage。它是一串群聚事件。單次重試也許能掩蓋 30 秒的小抖動。但它救不了一個連續數天遭遇模型層級反覆不穩的產品。
為什麼開發者火大
Hacker News 上關於 Claude 錯誤升高的討論串,正是你會預期從那些已經把 AI 從玩具 prompt 搬進日常生產工作的人的反應:挫折、玩笑,以及一場關於依賴風險的認真爭論(Hacker News)。
一派認為這是前沿模型正常的成長痛。GPU capacity 很難搞,需求會暴衝,而且這些模型的服務成本很高。另一派就沒那麼寬容:如果團隊正在圍繞 Claude Code、Claude API 和 Opus 等級模型打造付費產品與內部流程,那麼「錯誤升高」就不是無害的委婉說法。它只是措辭更好聽的停機。
最尖銳的評論不只是「Claude 掛了」。它們談的是依賴倒置。開發者已經不只是用一個 API 來強化某個功能。他們正在打造讓模型寫 code、review code、分流 ticket、擷取資料、回答客戶的工作流程。一位 HN 留言者描述了面向客戶的自動化系統,其中 uptime 會被 LLM 供應商的 uptime 封頂,接著列出實務修法:多供應商 fallback、async queues,以及 graceful degradation(Hacker News)。
這才是社群爭論中有用的部分。問題不再是 Opus 4.8 好不好。問題是你的系統把它當成資料庫、快取、不穩定的 SaaS 依賴,還是一位有時不在的真人專家。
正確答案是:不穩定的專家。
重試預算需要硬上限
Anthropic 的錯誤文件區分了普通的錯誤請求、帳戶 rate limits、內部 API errors、timeouts 與 overload。這裡的關鍵代碼是 500 api_error、504 timeout_error、529 overloaded_error,有時還有 429 rate_limit_error,如果是你自己的流量爬升觸發限制。Anthropic 表示,529 代表 API 暫時 overloaded,可能在 APIs 承受所有使用者的高流量時發生(Claude Docs)。
不要把這些錯誤都無腦用同一種方式重試。unsupported parameter 造成的 400 是你的 bug。事實上,Opus 4.8 繼承 Opus 4.7 的限制:在 Messages API 設定非預設的 temperature、top_p 或 top_k 會回傳 400(Claude Docs)。重試那種錯誤只是在燒 latency。
對 overload 和內部失敗來說,重試只有在預算內才有用。一個面向使用者、SLA 為 6 秒的請求,不該花 45 秒客氣地狂敲 Opus 4.8。給每個請求一個重試預算,然後降級。
一個合理的預設:
const retryable = new Set([500, 504, 529]);
async function callWithBudget(request, budgetMs = 6000) {
const started = Date.now();
for (let attempt = 0; ; attempt++) {
try {
return await callClaude(request);
} catch (error) {
if (!retryable.has(error.status) || Date.now() - started > budgetMs) {
throw error;
}
const delay = Math.min(250 * 2 ** attempt, 2000) * (0.5 + Math.random());
await sleep(delay);
}
}
}實際數字應該配合你的產品。coding agent 可以等久一點。背景文件 pipeline 可以等幾分鐘。voice agent 不行。
更大的重點是:重試不是可靠性。重試是一座橋,通往恢復,或通往 fallback。
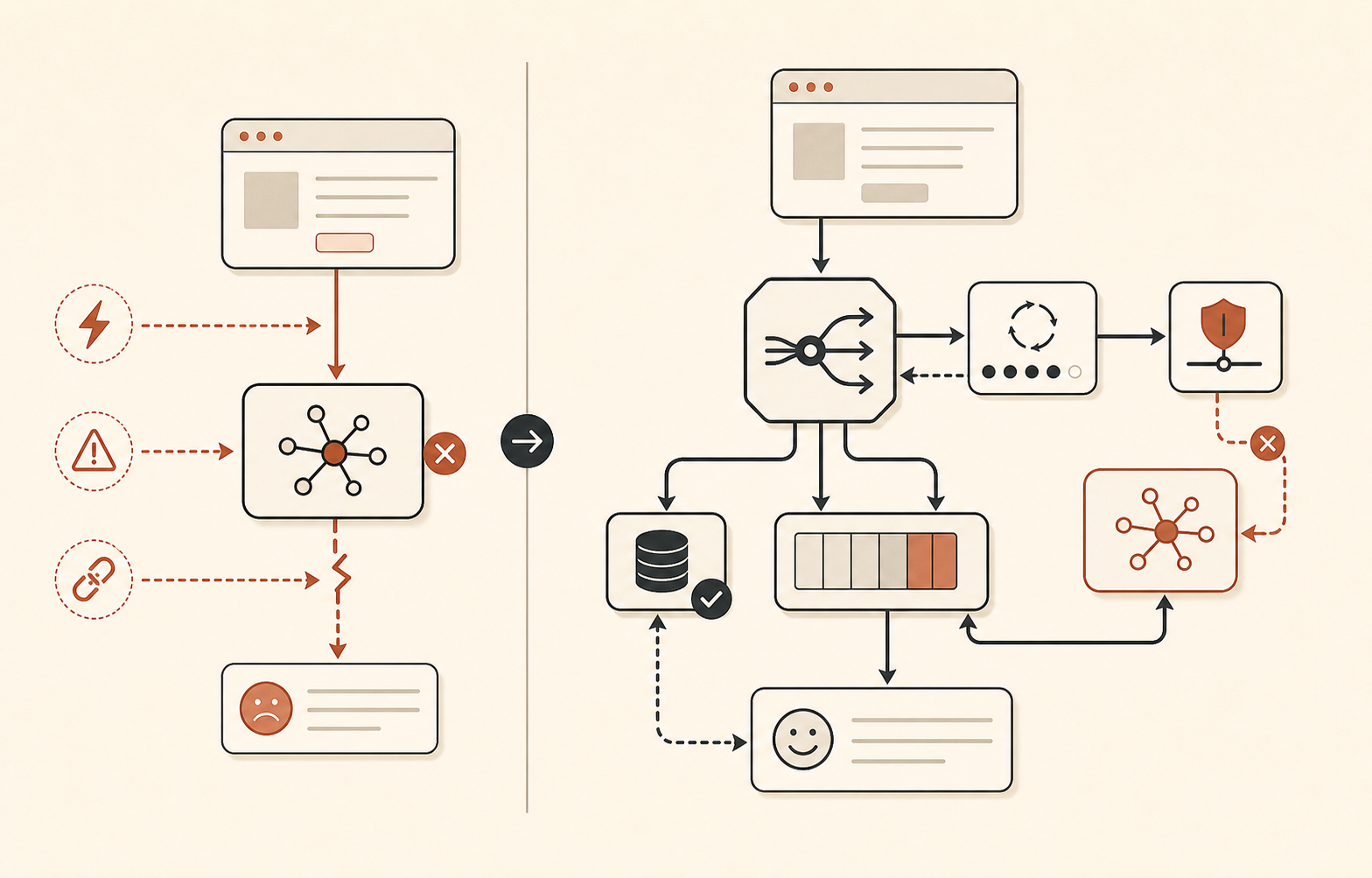
Fallback routing 應該無聊到不行
6 月 16 日的事故提醒我們,「fallback 到 Sonnet」不一定夠。第一階段中,所有 Sonnet 與 Opus 模型都受影響。第二階段中,Opus 4.8 仍不健康,而 Sonnet 已經恢復。6 月 17 日,Claude Status 也記錄了一場 Sonnet 4.6 與 Opus 4.8 的事故,其中 Sonnet success rates 已恢復,但 Opus 4.8 仍有較高錯誤率(Claude Status)。
所以模型 fallback 應該有層級,而不是靠感覺。
| 層級 | 何時使用 | 範例動作 |
|---|---|---|
| Opus-class primary | 高推理任務需要最佳品質 | 在嚴格預算內嘗試 Opus 4.8 |
| Sonnet-class fallback | Opus 專屬錯誤或 latency | 若品質可接受,用同一個 prompt 路由到 Sonnet |
| Non-Claude fallback | Claude API 或多模型事故 | 路由到另一家供應商、較小模型,或本地/open model |
| Product fallback | AI 路徑不可用 | 排隊處理、回傳快取結果、交給真人,或顯示降級 UI |
價格也該放進路由決策。Anthropic 5 月 27 日的價格表列出,Claude Opus 4.8 在 global standard pricing 下是每百萬 input tokens 5 美元、每百萬 output tokens 25 美元,Sonnet 4.6 是 3 美元與 15 美元,Haiku 4.5 在 Google Vertex AI listings 上是 1 美元與 5 美元(Anthropic price sheet)。這代表 fallback 不只是 uptime 工具。它也是成本控制工具。
不要讓每個任務都用同一種方式降級。法律分析草稿可能需要排隊等 Opus 回來。客服 chatbot 可以切到較便宜的模型,並多問一個釐清問題。code assistant 可以保留 workspace,並在修改前告訴使用者它正在切換模型。當模型行為有實質差異時,silent fallback 很危險。
把狀態頁當成輸入訊號來監控
Claude Status 在狀態頁上提供 email、Slack、Microsoft Teams、webhook、Atom 與 RSS 訂閱選項(Claude Status)。用起來。但不要停在一個警報進去就等死的 Slack channel。
把狀態變更餵進你的 LLM gateway。如果 Opus 4.8 事故開始,降低 Opus 的 circuit-breaker 閾值。如果 Claude API-wide 事故開始,第一次快速失敗後就停止送出互動式流量,並把符合條件的工作移進 queue。如果事故解決,逐步把流量拉回來,而不是朝供應商蜂擁而上。
circuit breaker 也應該追蹤你自己的 telemetry:
- 依供應商、模型、region 與 endpoint 區分的錯誤率。
- streaming 與 non-streaming calls 的 P50、P95 與 timeout rate。
- 每個成功回應的 retry attempts。
- fallback rate 與 fallback quality score。
- 使用者可見的 failure rate,而不只是 API failure rate。
最後一項才是高層聽得懂的指標。如果 Opus 4.8 回傳 10% 錯誤,但你的產品能在 99.5% 的使用者動作中回傳有用的降級回應,你有 incident,但不是 customer fire。如果你的產品卡住,因為每個請求都 block 在 Opus 上,那這把火是你自己點的。

這週該改什麼
第一,把 Opus 4.8 從任何 single point of failure 移除。它仍然可以是你最好的模型。但它不該是你唯一的路徑。
第二,依降級容忍度分類 prompts。「必須使用 Opus」應該少見且明確。「可使用 Sonnet」應該很常見。「可排隊」應該是文件處理、報告生成、批次 code review 與非互動式分析的預設。
第三,讓重試可見。記錄 request_id、模型、status code、retry count、final outcome 與 fallback target。Anthropic 文件表示 API errors 會包含 request IDs,而支援請求應該附上它們(Claude Docs)。如果事故期間你答不出「哪個模型失敗,接著路由到哪裡?」你的 observability 還沒準備好。
第四,有意識地測試你的 fallback path。加一個 feature flag,在 staging 強制 Opus 失敗。跑一場一小時的 game day,讓每個 Opus call 都回傳 529。看看哪裡壞掉:prompt assumptions、output parsers、eval thresholds、UI copy、customer promises。趕在下一次真事故前修好。
最後,對使用者誠實。「AI 失敗了」是糟糕的 UX。「因為進階模型暫時降級,我們正以標準模式執行這項工作」好得多。對某些產品來說,這句話會建立信任。
6 月 16–19 日的事故並不能證明 Claude Opus 4.8 是爛模型。它們證明了前沿模型現在已經是具備不穩定可用性特徵的生產依賴。把它們當成支付處理商、搜尋索引與 cloud regions:有用、昂貴,而且如果你沒有 fallback 就把它們接進來,它們絕對有能力毀掉你的一天。
想親自試用 Claude Fable 5 的讀者,可以透過 OneHop 把它當成 drop-in endpoint 使用,價格約低於定價 30%。新帳號免卡可獲得 10 美元免費額度:Claude Fable 5 on OneHop 或 start with $10 free。

