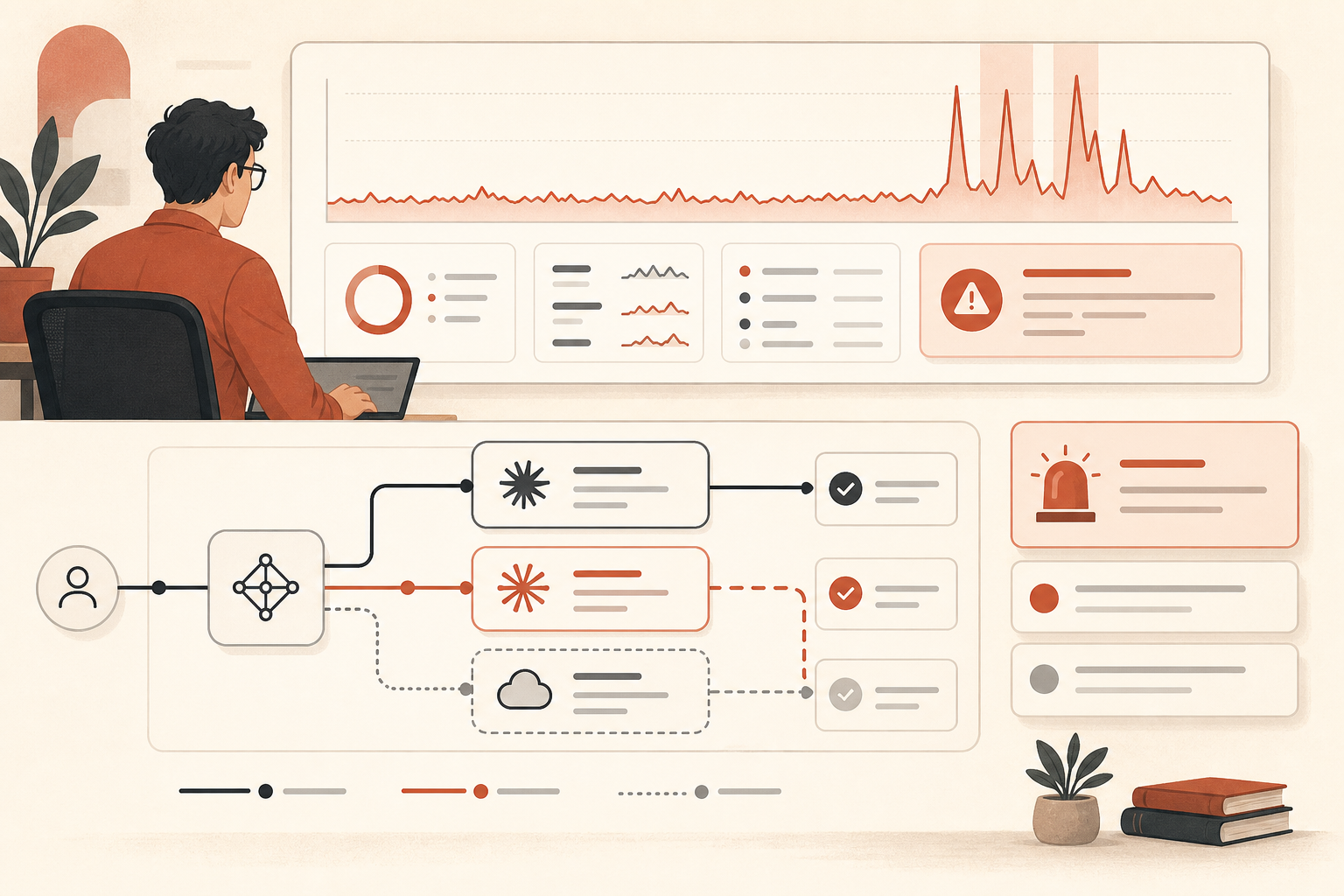
On June 16, Anthropic’s own status page recorded the number production engineers should care about: all Sonnet and Opus models reached roughly a 10% error rate for 37 minutes, then Claude Opus 4.8 continued at a 10% average error rate for another 80 minutes (Claude Status). That is not a “try again later” annoyance if your app calls Claude inside a user-facing workflow. That is a design review.
The incidents did not stop there. Claude Status shows repeated Opus 4.8 and broader Claude service incidents from June 16 through June 19: three Opus-specific incidents on June 16, four more Opus/Sonnet or Opus-only incidents on June 17, a Claude services disruption on June 18, and two API or Opus 4.8 incidents on June 19 (Claude Status). As of June 20, the page says no incidents were reported today, but the recent pattern is clear enough.
Anthropic launched Claude Opus 4.8 on May 28 as a same-price upgrade to Opus 4.7, positioning it as a stronger collaborator with better benchmark performance and improved honesty (Anthropic). That may all be true. It does not change the operational reality: if Opus 4.8 is on your critical path, your app now needs a real failure mode.
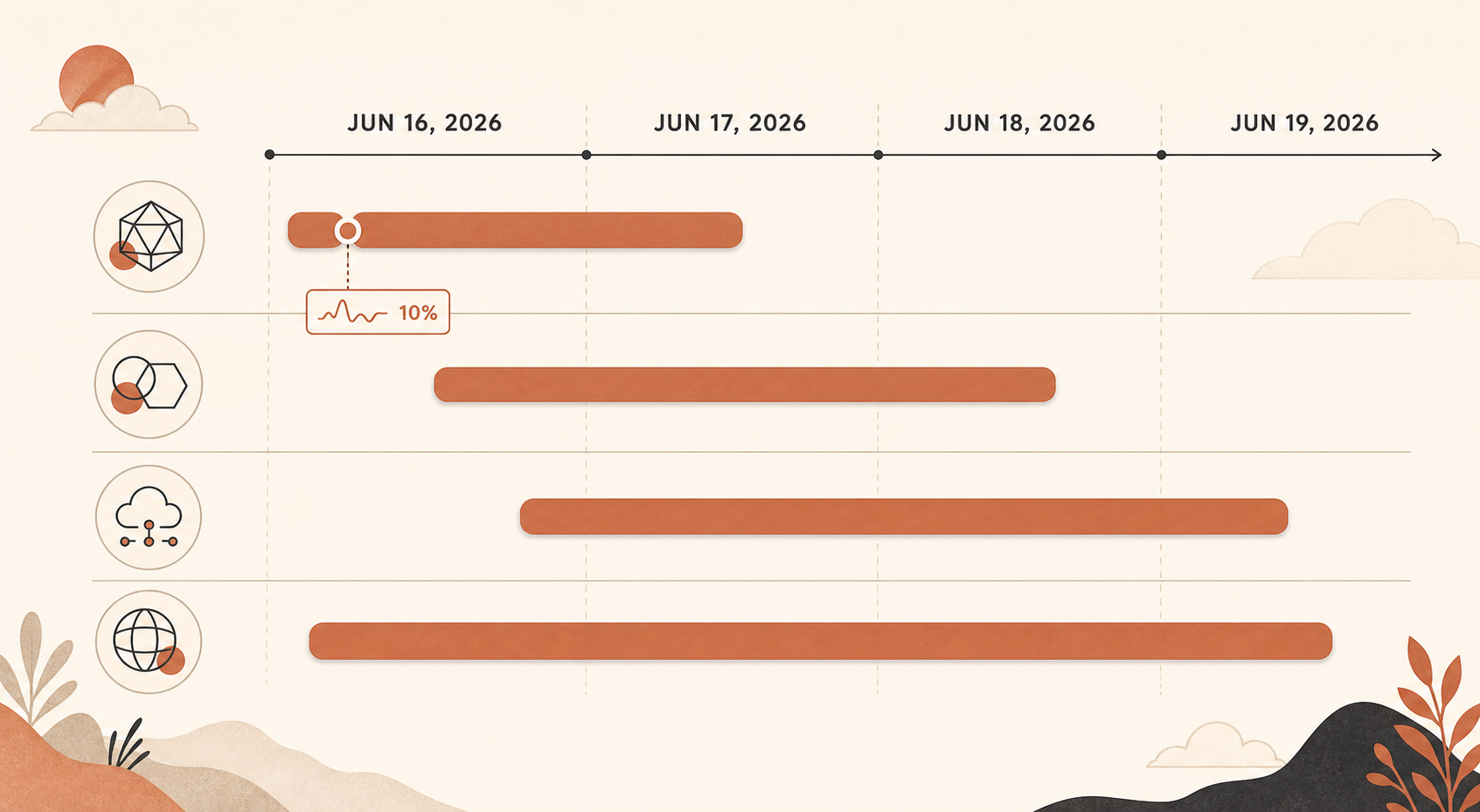
What happened, in UTC
The important incident started at 17:29 UTC on June 16, when Claude Status opened an investigation into elevated errors across many models. Anthropic later summarized it in two phases: from 17:23 to 18:00 UTC, all Sonnet and Opus models were affected and reached around a 10% error rate; from 18:00 to 19:20 UTC, Opus 4.8 alone averaged a 10% error rate (Claude Status).
Then came smaller but still painful Opus 4.8 spikes. On June 16, Claude Status separately recorded Opus 4.8 errors around 19:41-19:53 UTC, and another Opus 4.8 incident from 20:45-20:58 UTC (Claude Status). On June 17, there were multiple Opus 4.8 incidents, including one where requests received elevated errors from 04:59 to 05:41 UTC and another Sonnet 4.6 plus Opus 4.8 incident where Sonnet recovered first while Opus 4.8 still needed work (Claude Status).
June 18 was broader: Claude Status says a service disruption affected Claude services from 06:55 to 07:40 UTC (Claude Status). June 19 then brought an Opus 4.8 incident from 06:07 to 07:17 UTC and a separate “elevated error rates on the Claude API” incident from 08:17 to 08:45 UTC (Claude Status).
That timeline matters because it was not one clean outage. It was a cluster. A single retry might hide a 30-second blip. It will not save a product from repeated model-level instability across several days.
Why developers are angry
The Hacker News thread on elevated Claude errors is exactly what you would expect from people who have moved AI from toy prompts into daily production work: frustration, jokes, and a serious argument about dependency risk (Hacker News).
One camp sees this as normal frontier-model growing pain. GPU capacity is hard, demand is bursty, and these models are expensive to serve. Another camp is less forgiving: if teams are building paid products and internal workflows around Claude Code, Claude API, and Opus-class models, then “elevated errors” is not a harmless euphemism. It is downtime with nicer wording.
The sharpest comments are not just “Claude is down.” They are about dependency inversion. Developers are no longer merely using an API to enrich a feature. They are building workflows where the model writes code, reviews code, triages tickets, extracts data, and answers customers. One HN commenter described client-facing automation systems where uptime is capped by the LLM provider’s uptime, then listed the practical fixes: multi-provider fallback, async queues, and graceful degradation (Hacker News).
That is the useful part of the community debate. The question is no longer whether Opus 4.8 is good. The question is whether your system treats it like a database, a cache, a flaky SaaS dependency, or a human specialist who sometimes is not available.
The correct answer is: a flaky specialist.
Retry budgets need a hard ceiling
Anthropic’s error docs distinguish between ordinary bad requests, account rate limits, internal API errors, timeouts, and overload. The key codes here are 500 api_error, 504 timeout_error, 529 overloaded_error, and sometimes 429 rate_limit_error if your own traffic ramp triggers limits. Anthropic says 529 means the API is temporarily overloaded and can happen when APIs experience high traffic across all users (Claude Docs).
Do not blindly retry all of these the same way. A 400 from an unsupported parameter is your bug. In fact, Opus 4.8 inherits Opus 4.7 constraints: setting non-default temperature, top_p, or top_k returns a 400 on the Messages API (Claude Docs). Retrying that just burns latency.
For overload and internal failures, retries are useful only inside a budget. A user-facing request with a 6-second SLA should not spend 45 seconds politely hammering Opus 4.8. Give each request a retry budget, then degrade.
A sane default:
const retryable = new Set([500, 504, 529]);
async function callWithBudget(request, budgetMs = 6000) {
const started = Date.now();
for (let attempt = 0; ; attempt++) {
try {
return await callClaude(request);
} catch (error) {
if (!retryable.has(error.status) || Date.now() - started > budgetMs) {
throw error;
}
const delay = Math.min(250 * 2 ** attempt, 2000) * (0.5 + Math.random());
await sleep(delay);
}
}
}The exact numbers should match your product. A coding agent can wait longer than a checkout assistant. A background document pipeline can wait minutes. A voice agent cannot.
The bigger point: retries are not reliability. Retries are a bridge to either recovery or fallback.
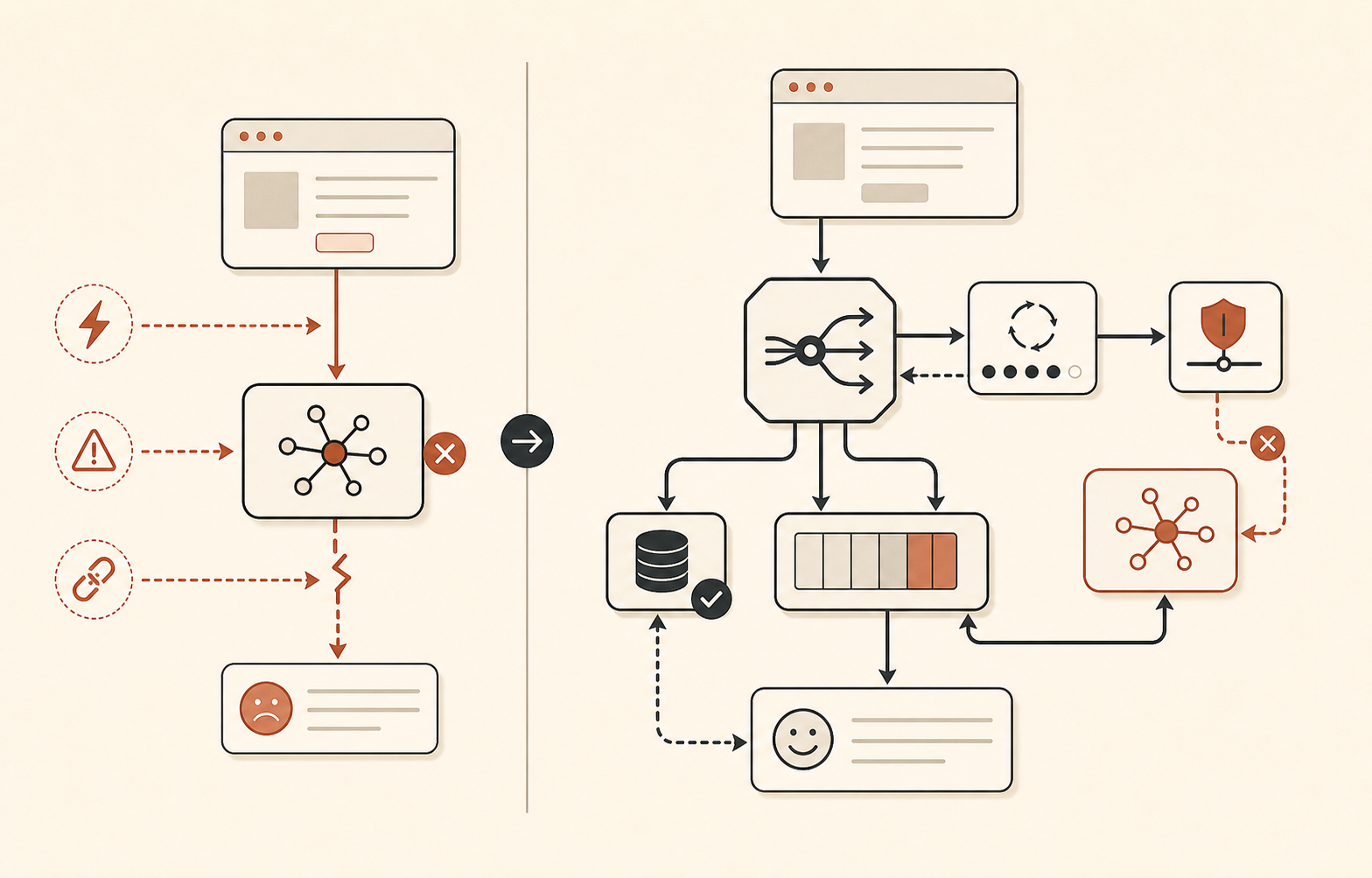
Fallback routing should be boring
The June 16 incident is a good reminder that “fall back to Sonnet” is not always enough. During the first phase, all Sonnet and Opus models were affected. During the second phase, Opus 4.8 stayed unhealthy while Sonnet recovered. On June 17, Claude Status also recorded a Sonnet 4.6 and Opus 4.8 incident where Sonnet success rates recovered while Opus 4.8 still had elevated errors (Claude Status).
So model fallback should have tiers, not vibes.
| Tier | Use when | Example action |
|---|---|---|
| Opus-class primary | High-reasoning tasks need best quality | Try Opus 4.8 within a strict budget |
| Sonnet-class fallback | Opus-specific errors or latency | Route to Sonnet for the same prompt if quality is acceptable |
| Non-Claude fallback | Claude API or multi-model incident | Route to another provider, smaller model, or local/open model |
| Product fallback | AI path unavailable | Queue work, return cached result, hand off to human, or show degraded UI |
Price also belongs in that routing decision. Anthropic’s May 27 price sheet lists Claude Opus 4.8 at $5 per million input tokens and $25 per million output tokens on global standard pricing, with Sonnet 4.6 at $3 and $15, and Haiku 4.5 at $1 and $5 on Google Vertex AI listings (Anthropic price sheet). That means fallback is not only an uptime tool. It is a cost-control tool.
Do not degrade every task the same way. A legal analysis draft may need to queue until Opus is back. A support chatbot can switch to a cheaper model and ask one clarifying question. A code assistant can preserve the workspace and tell the user it is switching models before making edits. Silent fallback is dangerous when model behavior changes materially.
Monitor the status page like an input signal
Claude Status exposes email, Slack, Microsoft Teams, webhook, Atom, and RSS subscription options on the status page (Claude Status). Use them. But do not stop at a Slack channel where alerts go to die.
Feed status changes into your LLM gateway. If an Opus 4.8 incident opens, lower the circuit-breaker threshold for Opus. If a Claude API-wide incident opens, stop sending interactive traffic after the first fast failure and move eligible jobs into a queue. If the incident resolves, ramp traffic back gradually instead of stampeding the provider.
The circuit breaker should track your own telemetry too:
- Error rate by provider, model, region, and endpoint.
- P50, P95, and timeout rate for streaming and non-streaming calls.
- Retry attempts per successful response.
- Fallback rate and fallback quality score.
- User-visible failure rate, not just API failure rate.
That last metric is the one executives understand. If Opus 4.8 returns 10% errors but your product returns useful degraded responses for 99.5% of user actions, you have an incident but not a customer fire. If your product hangs because every request blocks on Opus, you built the fire yourself.

What should change this week
First, remove Opus 4.8 from any single point of failure. It can still be your best model. It should not be your only path.
Second, classify prompts by degradation tolerance. “Must use Opus” should be rare and explicit. “Can use Sonnet” should be common. “Can queue” should be the default for document processing, report generation, batch code review, and non-interactive analysis.
Third, make retries visible. Log request_id, model, status code, retry count, final outcome, and fallback target. Anthropic’s docs say API errors include request IDs and that support requests should include them (Claude Docs). If you cannot answer “which model failed and where did we route next?” during an incident, your observability is not ready.
Fourth, test your fallback path on purpose. Add a feature flag that forces Opus failures in staging. Run a one-hour game day where every Opus call returns 529. Watch what breaks: prompt assumptions, output parsers, eval thresholds, UI copy, customer promises. Fix those before the next real incident.
Finally, be honest with users. “The AI failed” is bad UX. “We’re running this in standard mode because the advanced model is temporarily degraded” is much better. For some products, that sentence will build trust.
The June 16-19 incidents do not prove Claude Opus 4.8 is a bad model. They prove that frontier models are now production dependencies with unstable availability characteristics. Treat them like payment processors, search indexes, and cloud regions: useful, expensive, and absolutely capable of ruining your day if you wire them in without a fallback.
Readers who want to try Claude Fable 5 themselves can use it through OneHop as a drop-in endpoint, about 30% under list price. New accounts get $10 free with no card: Claude Fable 5 on OneHop or start with $10 free.
Further reading: Getting started with Claude Fable 5.

