Le 16 juin, la page de statut d’Anthropic a enregistré le chiffre qui devrait faire réagir les ingénieurs de production : tous les modèles Sonnet et Opus ont atteint environ 10 % de taux d’erreur pendant 37 minutes, puis Claude Opus 4.8 est resté à 10 % de taux d’erreur moyen pendant 80 minutes supplémentaires (Claude Status). Ce n’est pas une petite gêne du type « réessayez plus tard » si votre app appelle Claude au milieu d’un parcours utilisateur. C’est une revue d’architecture.
Les incidents ne se sont pas arrêtés là. Claude Status montre une série d’incidents Opus 4.8 et, plus largement, des incidents de service Claude répétés du 16 au 19 juin : trois incidents propres à Opus le 16 juin, quatre autres incidents Opus/Sonnet ou uniquement Opus le 17 juin, une perturbation des services Claude le 18 juin, puis deux incidents API ou Opus 4.8 le 19 juin (Claude Status). Au 20 juin, la page indique qu’aucun incident n’a été signalé aujourd’hui, mais la tendance récente est assez claire.
Anthropic a lancé Claude Opus 4.8 le 28 mai comme une mise à niveau au même prix d’Opus 4.7, en le présentant comme un meilleur collaborateur, avec de meilleures performances aux benchmarks et une honnêteté améliorée (Anthropic). Tout cela peut être vrai. Ça ne change rien à la réalité opérationnelle : si Opus 4.8 est sur votre chemin critique, votre app a désormais besoin d’un vrai mode de panne.
Ce qui s’est passé, en UTC
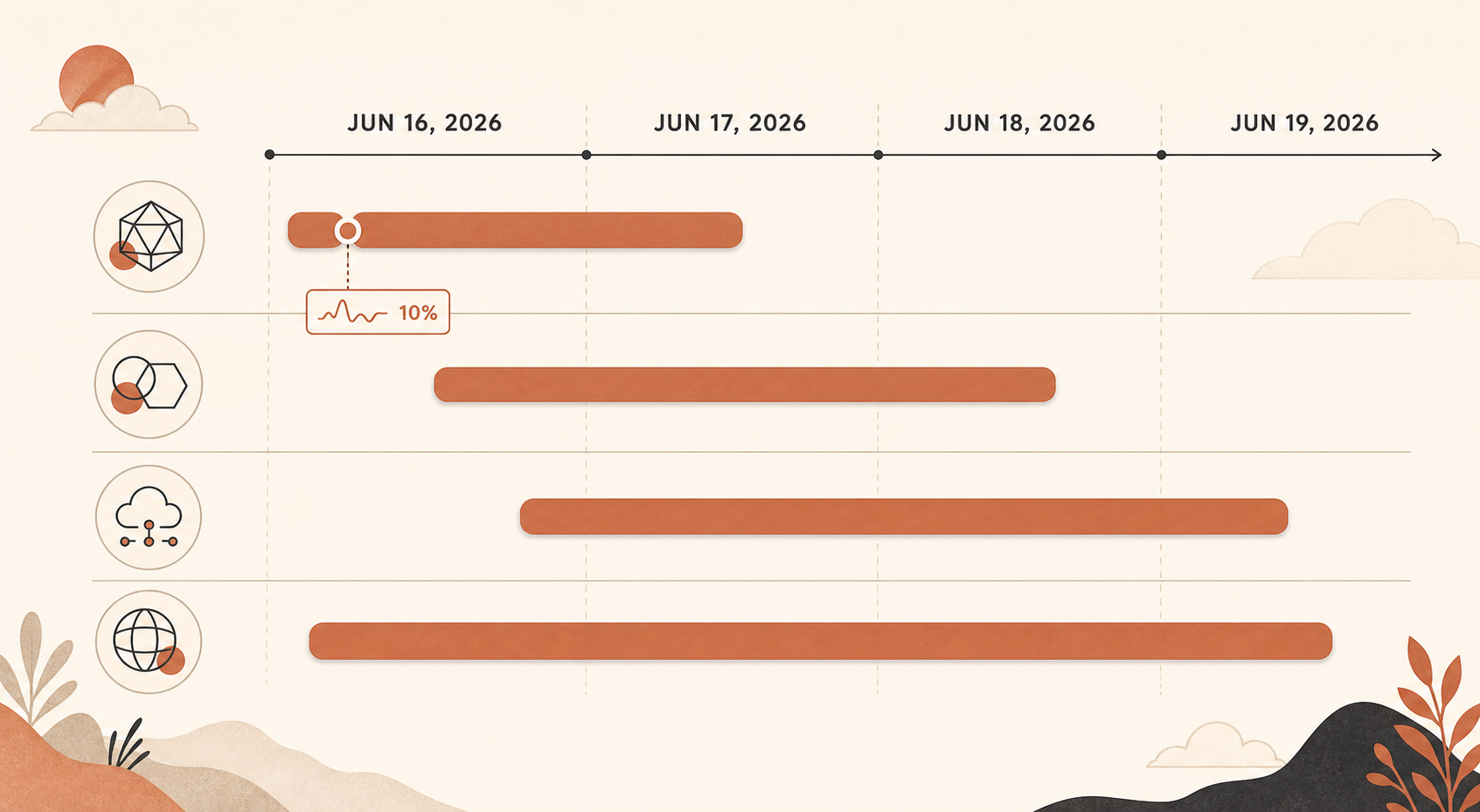
L’incident important a commencé à 17:29 UTC le 16 juin, lorsque Claude Status a ouvert une enquête sur des erreurs élevées touchant de nombreux modèles. Anthropic l’a ensuite résumé en deux phases : de 17:23 à 18:00 UTC, tous les modèles Sonnet et Opus ont été affectés et ont atteint environ 10 % de taux d’erreur ; de 18:00 à 19:20 UTC, seul Opus 4.8 a affiché en moyenne 10 % de taux d’erreur (Claude Status).
Puis sont venus des pics Opus 4.8 plus petits, mais toujours pénibles. Le 16 juin, Claude Status a enregistré séparément des erreurs Opus 4.8 autour de 19:41-19:53 UTC, puis un autre incident Opus 4.8 de 20:45 à 20:58 UTC (Claude Status). Le 17 juin, il y a eu plusieurs incidents Opus 4.8, dont un où les requêtes ont reçu des erreurs élevées de 04:59 à 05:41 UTC, et un autre incident Sonnet 4.6 plus Opus 4.8 où Sonnet s’est rétabli en premier tandis qu’Opus 4.8 nécessitait encore du travail (Claude Status).
Le 18 juin a été plus large : Claude Status indique qu’une perturbation de service a affecté les services Claude de 06:55 à 07:40 UTC (Claude Status). Le 19 juin a ensuite apporté un incident Opus 4.8 de 06:07 à 07:17 UTC, ainsi qu’un incident distinct de « taux d’erreur élevés sur la Claude API » de 08:17 à 08:45 UTC (Claude Status).
Cette chronologie compte, parce que ce n’était pas une panne propre et isolée. C’était une grappe. Un simple retry peut masquer un soubresaut de 30 secondes. Il ne sauvera pas un produit face à une instabilité répétée au niveau du modèle pendant plusieurs jours.
Pourquoi les développeurs sont en colère
Le fil Hacker News sur les erreurs élevées de Claude ressemble exactement à ce qu’on attend de gens qui ont fait passer l’IA des prompts jouets au travail quotidien en production : de la frustration, des blagues, et un vrai débat sur le risque de dépendance (Hacker News).
Un camp voit ça comme des douleurs de croissance normales pour les modèles de pointe. La capacité GPU est compliquée, la demande arrive par rafales, et ces modèles coûtent cher à servir. Un autre camp est moins indulgent : si des équipes construisent des produits payants et des workflows internes autour de Claude Code, Claude API et des modèles de classe Opus, alors « erreurs élevées » n’est pas un euphémisme anodin. C’est du downtime avec une formulation plus polie.
Les commentaires les plus tranchants ne disent pas seulement « Claude est down ». Ils parlent d’inversion de dépendance. Les développeurs n’utilisent plus simplement une API pour enrichir une fonctionnalité. Ils construisent des workflows où le modèle écrit du code, relit du code, trie des tickets, extrait des données et répond aux clients. Un commentateur HN a décrit des systèmes d’automatisation exposés aux clients dont l’uptime est plafonné par l’uptime du fournisseur de LLM, puis a listé les correctifs pratiques : fallback multi-fournisseurs, files async et dégradation gracieuse (Hacker News).
C’est la partie utile du débat communautaire. La question n’est plus de savoir si Opus 4.8 est bon. La question est de savoir si votre système le traite comme une base de données, un cache, une dépendance SaaS bancale ou un spécialiste humain qui n’est parfois pas disponible.
La bonne réponse : un spécialiste bancal.
Les budgets de retry ont besoin d’un plafond dur
La documentation d’erreurs d’Anthropic distingue les mauvaises requêtes ordinaires, les limites de débit du compte, les erreurs API internes, les timeouts et la surcharge. Les codes clés ici sont 500 api_error, 504 timeout_error, 529 overloaded_error, et parfois 429 rate_limit_error si votre propre montée en trafic déclenche des limites. Anthropic indique que 529 signifie que l’API est temporairement surchargée et que cela peut se produire lorsque les APIs subissent un trafic élevé sur l’ensemble des utilisateurs (Claude Docs).
Ne relancez pas aveuglément tout ça de la même manière. Un 400 causé par un paramètre non pris en charge, c’est votre bug. En fait, Opus 4.8 hérite des contraintes d’Opus 4.7 : définir une valeur non par défaut pour temperature, top_p ou top_k renvoie un 400 sur la Messages API (Claude Docs). Relancer ça ne fait que brûler de la latence.
Pour les surcharges et les pannes internes, les retries ne sont utiles qu’à l’intérieur d’un budget. Une requête visible par l’utilisateur avec une SLA de 6 secondes ne devrait pas passer 45 secondes à marteler poliment Opus 4.8. Donnez à chaque requête un budget de retry, puis dégradez.
Un défaut raisonnable :
const retryable = new Set([500, 504, 529]);
async function callWithBudget(request, budgetMs = 6000) {
const started = Date.now();
for (let attempt = 0; ; attempt++) {
try {
return await callClaude(request);
} catch (error) {
if (!retryable.has(error.status) || Date.now() - started > budgetMs) {
throw error;
}
const delay = Math.min(250 * 2 ** attempt, 2000) * (0.5 + Math.random());
await sleep(delay);
}
}
}Les chiffres exacts doivent correspondre à votre produit. Un agent de code peut attendre plus longtemps qu’un assistant de paiement. Un pipeline documentaire en arrière-plan peut attendre des minutes. Un agent vocal ne peut pas.
Le point le plus important : les retries ne sont pas de la fiabilité. Les retries sont un pont vers la reprise ou vers le fallback.
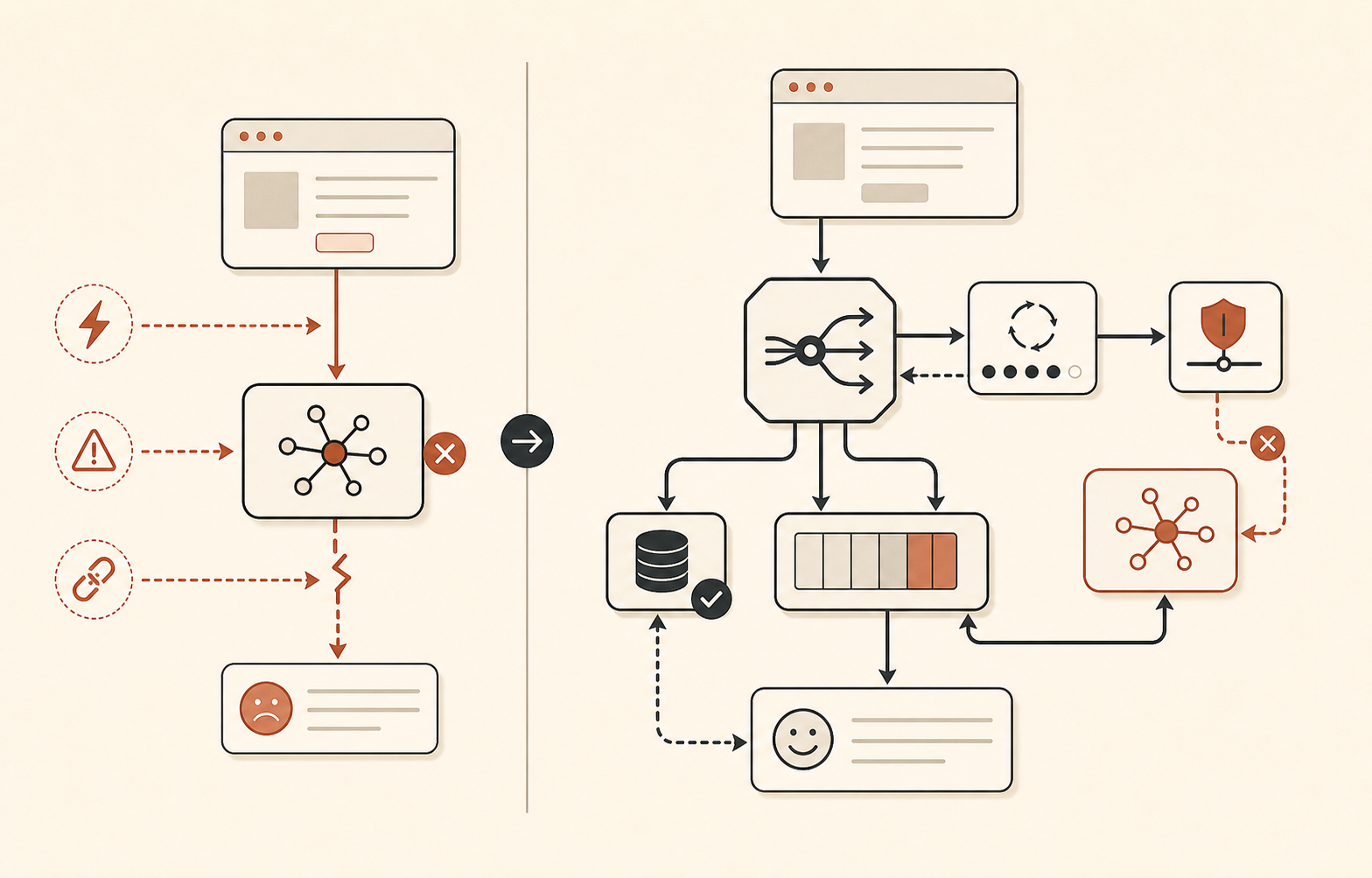
Le routage de secours devrait être ennuyeux
L’incident du 16 juin rappelle utilement que « basculer vers Sonnet » ne suffit pas toujours. Pendant la première phase, tous les modèles Sonnet et Opus étaient affectés. Pendant la deuxième phase, Opus 4.8 est resté en mauvaise santé pendant que Sonnet se rétablissait. Le 17 juin, Claude Status a aussi enregistré un incident Sonnet 4.6 et Opus 4.8 où les taux de succès de Sonnet se sont rétablis tandis qu’Opus 4.8 avait encore des erreurs élevées (Claude Status).
Le fallback de modèle doit donc avoir des niveaux, pas des vibes.
| Niveau | À utiliser quand | Exemple d’action |
|---|---|---|
| Primaire de classe Opus | Les tâches à fort raisonnement exigent la meilleure qualité | Essayer Opus 4.8 dans un budget strict |
| Fallback de classe Sonnet | Erreurs ou latence propres à Opus | Router vers Sonnet pour le même prompt si la qualité est acceptable |
| Fallback non-Claude | Incident Claude API ou multi-modèles | Router vers un autre fournisseur, un modèle plus petit ou un modèle local/ouvert |
| Fallback produit | Chemin IA indisponible | Mettre en file, renvoyer un résultat en cache, passer à un humain ou afficher une UI dégradée |
Le prix doit aussi faire partie de cette décision de routage. La grille tarifaire d’Anthropic du 27 mai liste Claude Opus 4.8 à 5 $ par million de tokens d’entrée et 25 $ par million de tokens de sortie en tarification standard globale, contre 3 $ et 15 $ pour Sonnet 4.6, et 1 $ et 5 $ pour Haiku 4.5 dans les listings Google Vertex AI (Anthropic price sheet). Le fallback n’est donc pas seulement un outil d’uptime. C’est un outil de contrôle des coûts.
Ne dégradez pas toutes les tâches de la même façon. Un brouillon d’analyse juridique peut devoir attendre le retour d’Opus. Un chatbot de support peut passer à un modèle moins cher et poser une question de clarification. Un assistant de code peut préserver le workspace et dire à l’utilisateur qu’il change de modèle avant de faire des modifications. Le fallback silencieux est dangereux lorsque le comportement du modèle change de façon matérielle.
Surveillez la page de statut comme un signal d’entrée
Claude Status propose des options d’abonnement par email, Slack, Microsoft Teams, webhook, Atom et RSS sur la page de statut (Claude Status). Utilisez-les. Mais ne vous arrêtez pas à un canal Slack où les alertes vont mourir.
Injectez les changements de statut dans votre passerelle LLM. Si un incident Opus 4.8 s’ouvre, abaissez le seuil du circuit breaker pour Opus. Si un incident à l’échelle de la Claude API s’ouvre, arrêtez d’envoyer du trafic interactif après le premier échec rapide et déplacez les jobs éligibles dans une file. Si l’incident est résolu, remontez le trafic progressivement au lieu de vous ruer tous ensemble sur le fournisseur.
Le circuit breaker doit aussi suivre votre propre télémétrie :
- Taux d’erreur par fournisseur, modèle, région et endpoint.
- P50, P95 et taux de timeout pour les appels streaming et non-streaming.
- Tentatives de retry par réponse réussie.
- Taux de fallback et score de qualité du fallback.
- Taux d’échec visible par l’utilisateur, pas seulement taux d’échec API.
Cette dernière métrique est celle que les dirigeants comprennent. Si Opus 4.8 renvoie 10 % d’erreurs mais que votre produit renvoie des réponses dégradées utiles pour 99,5 % des actions utilisateur, vous avez un incident, pas un incendie client. Si votre produit se bloque parce que chaque requête attend Opus, vous avez allumé l’incendie vous-même.

Ce qui devrait changer cette semaine
D’abord, retirez Opus 4.8 de tout point de défaillance unique. Il peut rester votre meilleur modèle. Il ne doit pas être votre seul chemin.
Ensuite, classez les prompts selon leur tolérance à la dégradation. « Doit utiliser Opus » devrait être rare et explicite. « Peut utiliser Sonnet » devrait être courant. « Peut être mis en file » devrait être le défaut pour le traitement de documents, la génération de rapports, la revue de code par lots et l’analyse non interactive.
Troisièmement, rendez les retries visibles. Loggez request_id, le modèle, le code de statut, le nombre de retries, le résultat final et la cible de fallback. La documentation d’Anthropic indique que les erreurs API incluent des request IDs et que les demandes au support doivent les inclure (Claude Docs). Si vous ne pouvez pas répondre à « quel modèle a échoué et où avons-nous routé ensuite ? » pendant un incident, votre observabilité n’est pas prête.
Quatrièmement, testez volontairement votre chemin de fallback. Ajoutez un feature flag qui force les échecs Opus en staging. Organisez un game day d’une heure où chaque appel Opus renvoie 529. Regardez ce qui casse : hypothèses de prompt, parseurs de sortie, seuils d’évaluation, wording UI, promesses clients. Corrigez ça avant le prochain vrai incident.
Enfin, soyez honnêtes avec les utilisateurs. « L’IA a échoué » est une mauvaise UX. « Nous exécutons ceci en mode standard parce que le modèle avancé est temporairement dégradé » est bien mieux. Pour certains produits, cette phrase renforcera la confiance.
Les incidents du 16 au 19 juin ne prouvent pas que Claude Opus 4.8 est un mauvais modèle. Ils prouvent que les modèles de pointe sont désormais des dépendances de production avec des caractéristiques de disponibilité instables. Traitez-les comme des processeurs de paiement, des index de recherche et des régions cloud : utiles, chers, et parfaitement capables de ruiner votre journée si vous les câblez sans fallback.
Les lecteurs qui veulent essayer Claude Fable 5 eux-mêmes peuvent l’utiliser via OneHop comme endpoint interchangeable, environ 30 % sous le prix catalogue. Les nouveaux comptes obtiennent 10 $ gratuits sans carte : Claude Fable 5 on OneHop ou commencer avec 10 $ gratuits.
À lire aussi : Bien démarrer avec Claude Fable 5.

