El 16 de junio, la propia página de estado de Anthropic registró el dato que debería importarle a cualquier equipo de producción: todos los modelos Sonnet y Opus llegaron a una tasa de error cercana al 10% durante 37 minutos, y después Claude Opus 4.8 siguió con una tasa media de error del 10% durante otros 80 minutos (Claude Status). Eso no es una molestia de “inténtalo de nuevo más tarde” si tu app llama a Claude dentro de un flujo de cara al usuario. Eso es una revisión de diseño.
Los incidentes no terminaron ahí. Claude Status muestra incidentes repetidos de Opus 4.8 y del servicio Claude en general entre el 16 y el 19 de junio: tres incidentes específicos de Opus el 16 de junio, cuatro incidentes más de Opus/Sonnet u Opus solamente el 17 de junio, una interrupción de servicios Claude el 18 de junio y dos incidentes de API u Opus 4.8 el 19 de junio (Claude Status). A 20 de junio, la página dice que hoy no se han reportado incidentes, pero el patrón reciente ya queda bastante claro.
Anthropic lanzó Claude Opus 4.8 el 28 de mayo como una mejora al mismo precio frente a Opus 4.7, presentándolo como un colaborador más fuerte, con mejor rendimiento en benchmarks y mayor honestidad (Anthropic). Puede que todo eso sea cierto. No cambia la realidad operativa: si Opus 4.8 está en tu ruta crítica, tu app necesita ahora un modo de fallo real.
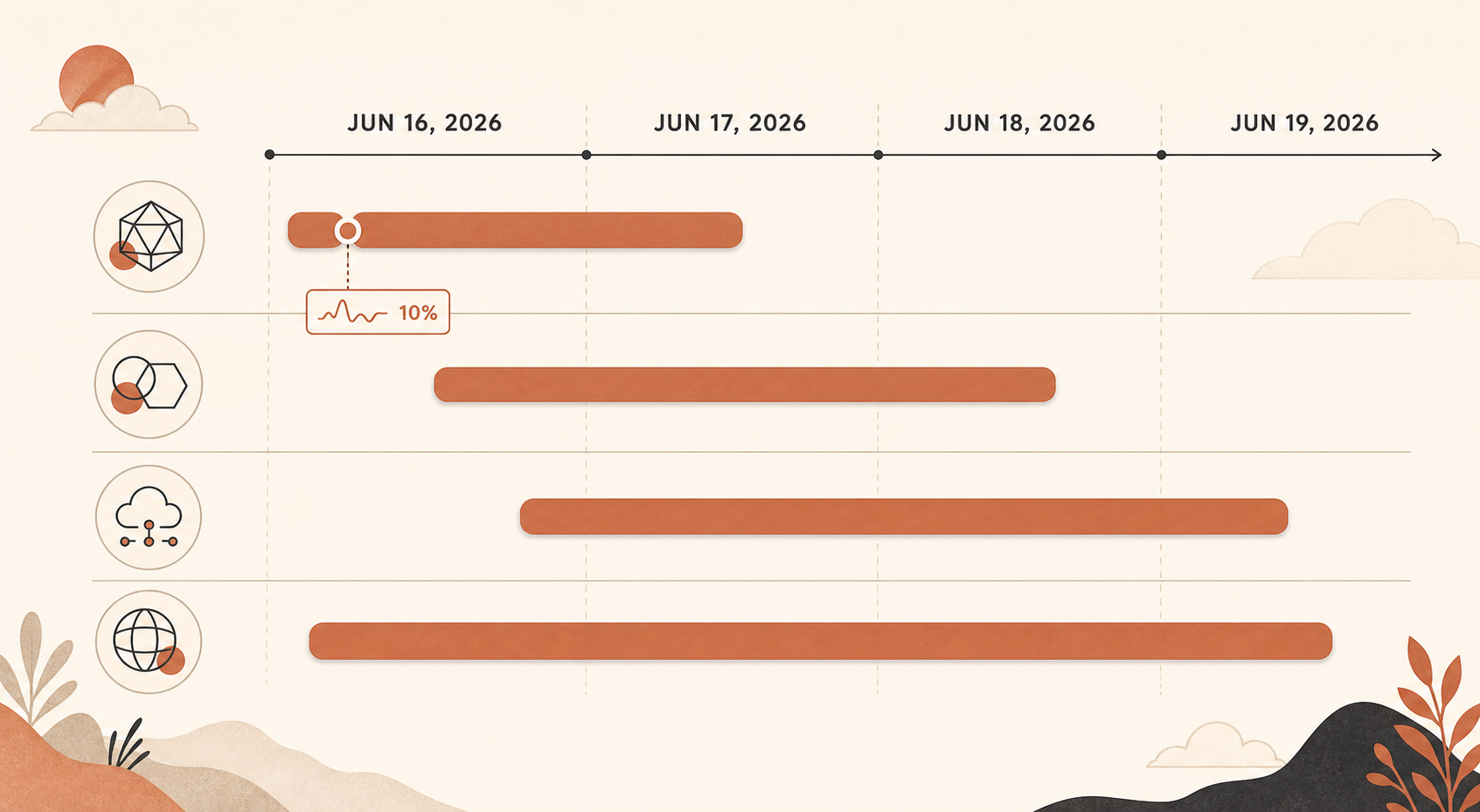
Qué pasó, en UTC
El incidente importante empezó a las 17:29 UTC del 16 de junio, cuando Claude Status abrió una investigación por errores elevados en muchos modelos. Anthropic lo resumió después en dos fases: de 17:23 a 18:00 UTC, todos los modelos Sonnet y Opus se vieron afectados y alcanzaron alrededor de un 10% de tasa de error; de 18:00 a 19:20 UTC, solo Opus 4.8 promedió una tasa de error del 10% (Claude Status).
Luego llegaron picos de Opus 4.8 más pequeños, pero igualmente dolorosos. El 16 de junio, Claude Status registró por separado errores de Opus 4.8 alrededor de las 19:41-19:53 UTC, y otro incidente de Opus 4.8 entre las 20:45 y las 20:58 UTC (Claude Status). El 17 de junio hubo varios incidentes de Opus 4.8, incluido uno en el que las solicitudes recibieron errores elevados de 04:59 a 05:41 UTC, y otro incidente de Sonnet 4.6 más Opus 4.8 en el que Sonnet se recuperó primero mientras Opus 4.8 todavía necesitaba trabajo (Claude Status).
El 18 de junio fue más amplio: Claude Status dice que una interrupción del servicio afectó a servicios Claude de 06:55 a 07:40 UTC (Claude Status). El 19 de junio trajo después un incidente de Opus 4.8 de 06:07 a 07:17 UTC y otro incidente separado de “tasas de error elevadas en la Claude API” de 08:17 a 08:45 UTC (Claude Status).
Esa cronología importa porque no fue una caída limpia y aislada. Fue un racimo. Un único reintento puede ocultar un parpadeo de 30 segundos. No va a salvar a un producto de una inestabilidad repetida a nivel de modelo durante varios días.
Por qué los desarrolladores están enfadados
El hilo de Hacker News sobre los errores elevados de Claude es exactamente lo que esperarías de gente que ha pasado la IA de prompts de juguete a trabajo diario en producción: frustración, bromas y una discusión seria sobre el riesgo de dependencia (Hacker News).
Un bando lo ve como el dolor normal de crecimiento de los modelos frontier. La capacidad de GPU es difícil, la demanda llega a ráfagas y estos modelos son caros de servir. El otro bando es menos indulgente: si los equipos están construyendo productos de pago y flujos internos alrededor de Claude Code, Claude API y modelos de clase Opus, entonces “errores elevados” no es un eufemismo inocuo. Es downtime con una redacción más bonita.
Los comentarios más afilados no son simplemente “Claude está caído”. Van sobre inversión de dependencias. Los desarrolladores ya no se limitan a usar una API para enriquecer una función. Están construyendo flujos donde el modelo escribe código, revisa código, clasifica tickets, extrae datos y responde a clientes. Un comentarista de HN describió sistemas de automatización de cara al cliente cuyo uptime queda limitado por el uptime del proveedor de LLM, y después enumeró las soluciones prácticas: fallback multiproveedor, colas asíncronas y degradación elegante (Hacker News).
Esa es la parte útil del debate de la comunidad. La pregunta ya no es si Opus 4.8 es bueno. La pregunta es si tu sistema lo trata como una base de datos, una caché, una dependencia SaaS inestable o un especialista humano que a veces no está disponible.
La respuesta correcta es: un especialista inestable.
Los presupuestos de reintentos necesitan un techo duro
La documentación de errores de Anthropic distingue entre solicitudes mal formadas normales, límites de tasa de la cuenta, errores internos de API, timeouts y sobrecarga. Los códigos clave aquí son 500 api_error, 504 timeout_error, 529 overloaded_error y a veces 429 rate_limit_error si tu propio aumento de tráfico dispara límites. Anthropic dice que 529 significa que la API está temporalmente sobrecargada y puede ocurrir cuando las APIs experimentan mucho tráfico entre todos los usuarios (Claude Docs).
No reintentes todos estos a ciegas de la misma manera. Un 400 por un parámetro no soportado es tu bug. De hecho, Opus 4.8 hereda las restricciones de Opus 4.7: establecer temperature, top_p o top_k con valores no predeterminados devuelve un 400 en la Messages API (Claude Docs). Reintentar eso solo quema latencia.
Para sobrecarga y fallos internos, los reintentos solo sirven dentro de un presupuesto. Una solicitud de cara al usuario con un SLA de 6 segundos no debería pasar 45 segundos golpeando educadamente a Opus 4.8. Dale a cada solicitud un presupuesto de reintentos y después degrada.
Un valor por defecto razonable:
const retryable = new Set([500, 504, 529]);
async function callWithBudget(request, budgetMs = 6000) {
const started = Date.now();
for (let attempt = 0; ; attempt++) {
try {
return await callClaude(request);
} catch (error) {
if (!retryable.has(error.status) || Date.now() - started > budgetMs) {
throw error;
}
const delay = Math.min(250 * 2 ** attempt, 2000) * (0.5 + Math.random());
await sleep(delay);
}
}
}Los números exactos deberían ajustarse a tu producto. Un agente de programación puede esperar más que un asistente de checkout. Un pipeline de documentos en segundo plano puede esperar minutos. Un agente de voz no puede.
La idea más importante: los reintentos no son fiabilidad. Los reintentos son un puente hacia la recuperación o hacia el fallback.
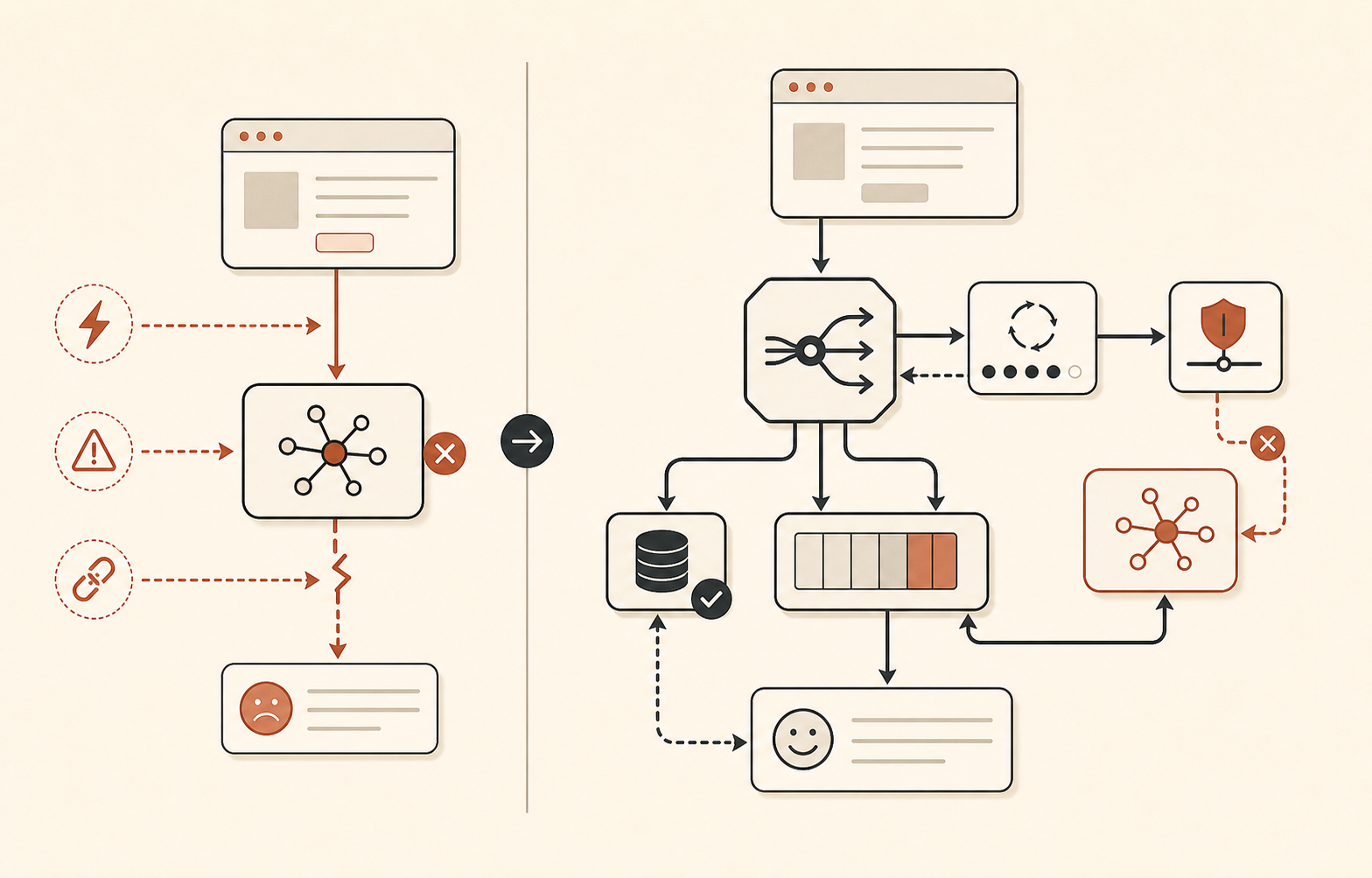
El enrutamiento de fallback debería ser aburrido
El incidente del 16 de junio es un buen recordatorio de que “hacer fallback a Sonnet” no siempre basta. Durante la primera fase, todos los modelos Sonnet y Opus estuvieron afectados. Durante la segunda fase, Opus 4.8 siguió en mal estado mientras Sonnet se recuperaba. El 17 de junio, Claude Status también registró un incidente de Sonnet 4.6 y Opus 4.8 en el que las tasas de éxito de Sonnet se recuperaron mientras Opus 4.8 todavía tenía errores elevados (Claude Status).
Así que el fallback de modelos debería tener niveles, no vibras.
| Nivel | Úsalo cuando | Acción de ejemplo |
|---|---|---|
| Primario de clase Opus | Las tareas de razonamiento alto necesitan la mejor calidad | Probar Opus 4.8 dentro de un presupuesto estricto |
| Fallback de clase Sonnet | Errores específicos de Opus o latencia | Enrutar a Sonnet con el mismo prompt si la calidad es aceptable |
| Fallback no Claude | Incidente de Claude API o multimodelo | Enrutar a otro proveedor, modelo más pequeño o modelo local/abierto |
| Fallback de producto | La ruta de IA no está disponible | Poner el trabajo en cola, devolver resultado cacheado, transferir a un humano o mostrar una UI degradada |
El precio también debe entrar en esa decisión de enrutamiento. La hoja de precios de Anthropic del 27 de mayo lista Claude Opus 4.8 a $5 por millón de tokens de entrada y $25 por millón de tokens de salida en precios globales estándar, con Sonnet 4.6 a $3 y $15, y Haiku 4.5 a $1 y $5 en los listados de Google Vertex AI (Anthropic price sheet). Eso significa que el fallback no es solo una herramienta de uptime. También es una herramienta de control de costes.
No degradas todas las tareas de la misma forma. Un borrador de análisis legal quizá tenga que esperar en cola hasta que Opus vuelva. Un chatbot de soporte puede cambiar a un modelo más barato y hacer una pregunta aclaratoria. Un asistente de código puede preservar el workspace y decirle al usuario que está cambiando de modelo antes de editar. El fallback silencioso es peligroso cuando el comportamiento del modelo cambia de forma material.
Monitoriza la página de estado como una señal de entrada
Claude Status ofrece en la página de estado opciones de suscripción por email, Slack, Microsoft Teams, webhook, Atom y RSS (Claude Status). Úsalas. Pero no te quedes en un canal de Slack donde las alertas van a morir.
Alimenta los cambios de estado en tu pasarela LLM. Si se abre un incidente de Opus 4.8, baja el umbral del circuit breaker para Opus. Si se abre un incidente amplio de Claude API, deja de enviar tráfico interactivo tras el primer fallo rápido y mueve los trabajos elegibles a una cola. Si el incidente se resuelve, vuelve a aumentar el tráfico gradualmente en vez de provocar una estampida contra el proveedor.
El circuit breaker también debería seguir tu propia telemetría:
- Tasa de error por proveedor, modelo, región y endpoint.
- P50, P95 y tasa de timeout para llamadas streaming y no streaming.
- Intentos de reintento por respuesta exitosa.
- Tasa de fallback y puntuación de calidad del fallback.
- Tasa de fallos visible para el usuario, no solo tasa de fallos de API.
Esa última métrica es la que entienden los ejecutivos. Si Opus 4.8 devuelve un 10% de errores pero tu producto devuelve respuestas degradadas útiles para el 99,5% de las acciones de usuario, tienes un incidente, pero no un incendio con clientes. Si tu producto se cuelga porque cada solicitud bloquea esperando a Opus, el incendio lo construiste tú.

Qué debería cambiar esta semana
Primero, elimina Opus 4.8 de cualquier punto único de fallo. Puede seguir siendo tu mejor modelo. No debería ser tu único camino.
Segundo, clasifica los prompts por tolerancia a la degradación. “Debe usar Opus” debería ser raro y explícito. “Puede usar Sonnet” debería ser común. “Puede ir a cola” debería ser el valor por defecto para procesamiento de documentos, generación de informes, revisión de código por lotes y análisis no interactivo.
Tercero, haz visibles los reintentos. Registra request_id, modelo, código de estado, número de reintentos, resultado final y destino de fallback. La documentación de Anthropic dice que los errores de API incluyen IDs de solicitud y que las solicitudes de soporte deberían incluirlos (Claude Docs). Si durante un incidente no puedes responder “¿qué modelo falló y a dónde enrutamos después?”, tu observabilidad no está lista.
Cuarto, prueba tu ruta de fallback a propósito. Añade una feature flag que fuerce fallos de Opus en staging. Ejecuta un game day de una hora en el que cada llamada a Opus devuelva 529. Mira qué se rompe: supuestos del prompt, parsers de salida, umbrales de evaluación, textos de UI, promesas al cliente. Arregla eso antes del próximo incidente real.
Por último, sé honesto con los usuarios. “La IA falló” es mala UX. “Estamos ejecutando esto en modo estándar porque el modelo avanzado está temporalmente degradado” es mucho mejor. Para algunos productos, esa frase generará confianza.
Los incidentes del 16 al 19 de junio no demuestran que Claude Opus 4.8 sea un mal modelo. Demuestran que los modelos frontier ya son dependencias de producción con características de disponibilidad inestables. Trátalos como procesadores de pago, índices de búsqueda y regiones cloud: útiles, caros y absolutamente capaces de arruinarte el día si los conectas sin fallback.
Los lectores que quieran probar Claude Fable 5 pueden usarlo a través de OneHop como endpoint drop-in, alrededor de un 30% por debajo del precio de lista. Las cuentas nuevas reciben $10 gratis sin tarjeta: Claude Fable 5 on OneHop o empieza con $10 gratis.
Lectura adicional: Primeros pasos con Claude Fable 5.

