Em 16 de junho, a própria página de status da Anthropic registrou o número que engenheiros de produção deveriam levar a sério: todos os modelos Sonnet e Opus chegaram a cerca de 10% de taxa de erro por 37 minutos; depois, o Claude Opus 4.8 continuou com uma taxa média de erro de 10% por mais 80 minutos (Claude Status). Isso não é um inconveniente do tipo “tente de novo mais tarde” se o seu app chama o Claude dentro de um fluxo visível para o usuário. Isso é caso para revisão de arquitetura.
Os incidentes não pararam por aí. O Claude Status mostra incidentes repetidos envolvendo o Opus 4.8 e o serviço Claude de forma mais ampla entre 16 e 19 de junho: três incidentes específicos do Opus em 16 de junho, mais quatro incidentes envolvendo Opus/Sonnet ou apenas Opus em 17 de junho, uma interrupção nos serviços Claude em 18 de junho e dois incidentes de API ou Opus 4.8 em 19 de junho (Claude Status). Em 20 de junho, a página diz que nenhum incidente foi reportado hoje, mas o padrão recente já está claro o suficiente.
A Anthropic lançou o Claude Opus 4.8 em 28 de maio como uma atualização pelo mesmo preço em relação ao Opus 4.7, posicionando-o como um colaborador mais forte, com melhor desempenho em benchmarks e honestidade aprimorada (Anthropic). Tudo isso pode ser verdade. Mas não muda a realidade operacional: se o Opus 4.8 está no caminho crítico do seu produto, seu app agora precisa de um modo de falha de verdade.
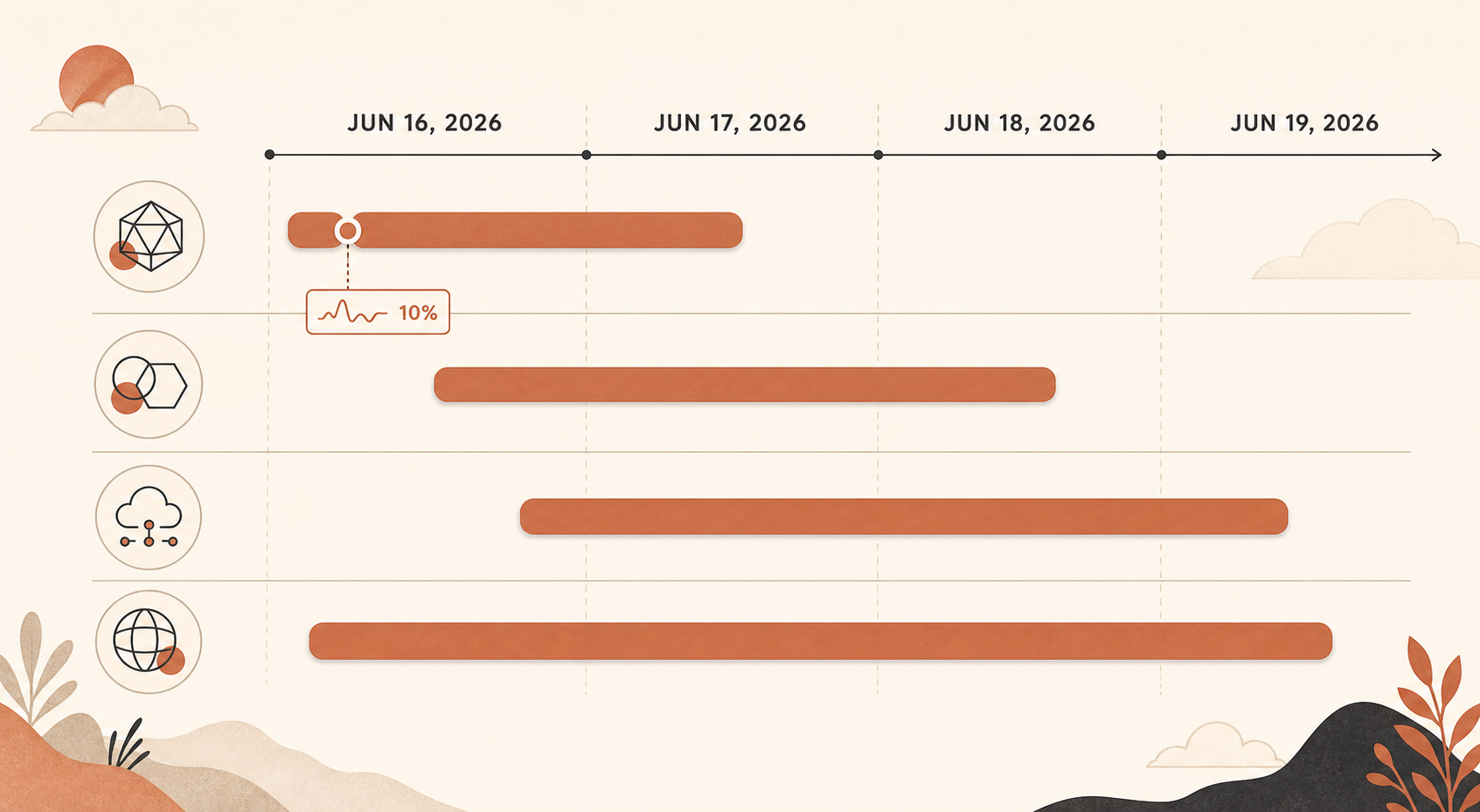
O que aconteceu, em UTC
O incidente importante começou às 17:29 UTC de 16 de junho, quando o Claude Status abriu uma investigação sobre erros elevados em vários modelos. Depois, a Anthropic resumiu o episódio em duas fases: das 17:23 às 18:00 UTC, todos os modelos Sonnet e Opus foram afetados e chegaram a cerca de 10% de taxa de erro; das 18:00 às 19:20 UTC, apenas o Opus 4.8 manteve uma taxa média de erro de 10% (Claude Status).
Depois vieram picos menores, mas ainda dolorosos, no Opus 4.8. Em 16 de junho, o Claude Status registrou separadamente erros no Opus 4.8 por volta de 19:41-19:53 UTC, e outro incidente do Opus 4.8 das 20:45 às 20:58 UTC (Claude Status). Em 17 de junho, houve vários incidentes com o Opus 4.8, incluindo um em que requisições receberam erros elevados das 04:59 às 05:41 UTC e outro incidente envolvendo Sonnet 4.6 mais Opus 4.8, em que o Sonnet se recuperou primeiro enquanto o Opus 4.8 ainda precisava de ajustes (Claude Status).
O dia 18 de junho foi mais amplo: o Claude Status afirma que uma interrupção de serviço afetou os serviços Claude das 06:55 às 07:40 UTC (Claude Status). Em 19 de junho, então, houve um incidente do Opus 4.8 das 06:07 às 07:17 UTC e um incidente separado de “taxas de erro elevadas na Claude API” das 08:17 às 08:45 UTC (Claude Status).
Essa linha do tempo importa porque não foi uma queda limpa e isolada. Foi um cluster. Um único retry talvez esconda uma instabilidade de 30 segundos. Ele não vai salvar um produto de instabilidade repetida no nível do modelo ao longo de vários dias.
Por que os desenvolvedores estão irritados
A thread do Hacker News sobre erros elevados no Claude é exatamente o que você esperaria de gente que levou IA de prompts de brinquedo para trabalho diário em produção: frustração, piadas e uma discussão séria sobre risco de dependência (Hacker News).
Um grupo vê isso como uma dor normal de crescimento de modelos de fronteira. Capacidade de GPU é difícil, a demanda vem em rajadas, e esses modelos são caros de servir. Outro grupo é menos tolerante: se equipes estão construindo produtos pagos e fluxos internos em cima do Claude Code, Claude API e modelos da classe Opus, então “erros elevados” não é um eufemismo inofensivo. É downtime com palavras mais bonitas.
Os comentários mais afiados não são apenas “o Claude caiu”. Eles falam de inversão de dependência. Desenvolvedores não estão mais apenas usando uma API para enriquecer uma feature. Estão criando fluxos em que o modelo escreve código, revisa código, faz triagem de tickets, extrai dados e responde clientes. Um comentarista do HN descreveu sistemas de automação voltados a clientes em que o uptime fica limitado pelo uptime do provedor de LLM, e então listou as correções práticas: fallback multiprovedor, filas assíncronas e degradação elegante (Hacker News).
Essa é a parte útil do debate da comunidade. A pergunta não é mais se o Opus 4.8 é bom. A pergunta é se o seu sistema o trata como um banco de dados, um cache, uma dependência SaaS instável ou um especialista humano que às vezes não está disponível.
A resposta correta é: um especialista instável.
Limites de retry precisam de teto rígido
A documentação de erros da Anthropic diferencia requisições inválidas comuns, limites de taxa da conta, erros internos da API, timeouts e sobrecarga. Os códigos-chave aqui são 500 api_error, 504 timeout_error, 529 overloaded_error e, às vezes, 429 rate_limit_error se o crescimento do seu próprio tráfego acionar limites. A Anthropic diz que 529 significa que a API está temporariamente sobrecarregada e pode acontecer quando APIs passam por tráfego alto entre todos os usuários (Claude Docs).
Não faça retry cego em todos eles do mesmo jeito. Um 400 causado por um parâmetro não suportado é bug seu. Na verdade, o Opus 4.8 herda as restrições do Opus 4.7: definir temperature, top_p ou top_k com valores diferentes do padrão retorna um 400 na Messages API (Claude Docs). Fazer retry disso só queima latência.
Para sobrecarga e falhas internas, retries só são úteis dentro de um limite. Uma requisição visível ao usuário com SLA de 6 segundos não deveria passar 45 segundos martelando educadamente o Opus 4.8. Dê a cada requisição um limite de retry; depois, degrade.
Um padrão sensato:
const retryable = new Set([500, 504, 529]);
async function callWithBudget(request, budgetMs = 6000) {
const started = Date.now();
for (let attempt = 0; ; attempt++) {
try {
return await callClaude(request);
} catch (error) {
if (!retryable.has(error.status) || Date.now() - started > budgetMs) {
throw error;
}
const delay = Math.min(250 * 2 ** attempt, 2000) * (0.5 + Math.random());
await sleep(delay);
}
}
}Os números exatos devem acompanhar o seu produto. Um agente de código pode esperar mais que um assistente de checkout. Um pipeline de documentos em background pode esperar minutos. Um agente de voz não pode.
O ponto maior: retries não são confiabilidade. Retries são uma ponte para recuperação ou fallback.
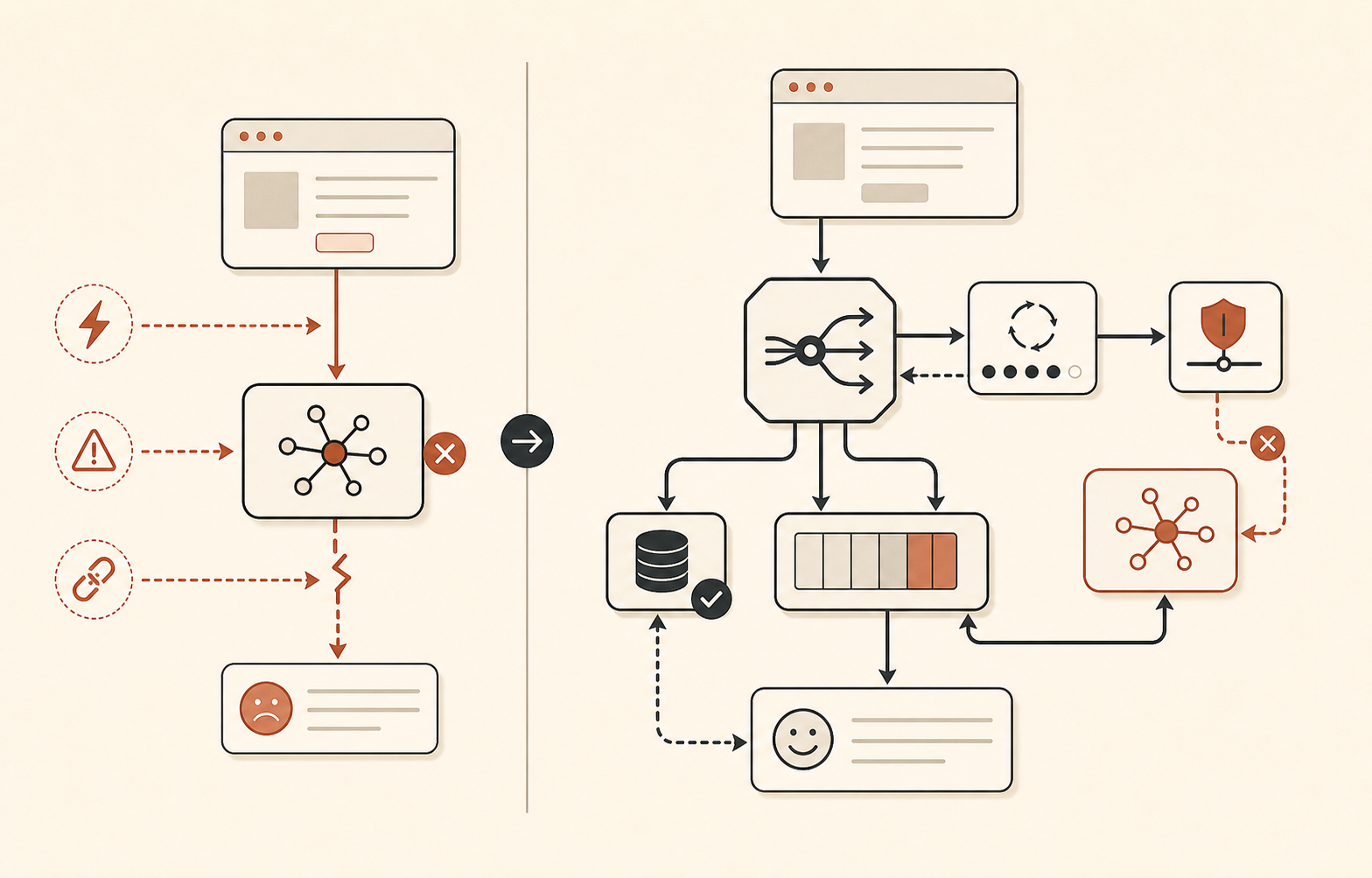
Roteamento de fallback deve ser sem graça
O incidente de 16 de junho é um bom lembrete de que “cair para Sonnet” nem sempre basta. Durante a primeira fase, todos os modelos Sonnet e Opus foram afetados. Durante a segunda fase, o Opus 4.8 continuou ruim enquanto o Sonnet se recuperou. Em 17 de junho, o Claude Status também registrou um incidente com Sonnet 4.6 e Opus 4.8 em que as taxas de sucesso do Sonnet se recuperaram enquanto o Opus 4.8 ainda tinha erros elevados (Claude Status).
Então fallback de modelo deve ter camadas, não achismo.
| Camada | Use quando | Exemplo de ação |
|---|---|---|
| Primário classe Opus | Tarefas de alto raciocínio precisam da melhor qualidade | Tentar Opus 4.8 dentro de um limite rígido |
| Fallback classe Sonnet | Erros ou latência específicos do Opus | Roteiar para Sonnet com o mesmo prompt se a qualidade for aceitável |
| Fallback não-Claude | Incidente na Claude API ou em múltiplos modelos | Roteiar para outro provedor, modelo menor ou modelo local/aberto |
| Fallback de produto | Caminho de IA indisponível | Enfileirar trabalho, retornar resultado em cache, passar para humano ou mostrar UI degradada |
Preço também entra nessa decisão de roteamento. A tabela de preços de 27 de maio da Anthropic lista o Claude Opus 4.8 a US$ 5 por milhão de tokens de entrada e US$ 25 por milhão de tokens de saída no preço global padrão, com Sonnet 4.6 a US$ 3 e US$ 15, e Haiku 4.5 a US$ 1 e US$ 5 nas listagens do Google Vertex AI (tabela de preços da Anthropic). Isso significa que fallback não é só uma ferramenta de uptime. É uma ferramenta de controle de custo.
Não degrade toda tarefa do mesmo jeito. Um rascunho de análise jurídica talvez precise entrar na fila até o Opus voltar. Um chatbot de suporte pode mudar para um modelo mais barato e fazer uma pergunta de esclarecimento. Um assistente de código pode preservar o workspace e avisar ao usuário que está trocando de modelo antes de fazer edições. Fallback silencioso é perigoso quando o comportamento do modelo muda de forma relevante.
Monitore a página de status como um sinal de entrada
O Claude Status oferece opções de assinatura por email, Slack, Microsoft Teams, webhook, Atom e RSS na página de status (Claude Status). Use. Mas não pare em um canal do Slack onde alertas vão morrer.
Alimente seu gateway de LLM com mudanças de status. Se um incidente do Opus 4.8 abrir, reduza o limiar do circuit breaker para o Opus. Se abrir um incidente amplo da Claude API, pare de enviar tráfego interativo depois da primeira falha rápida e mova jobs elegíveis para uma fila. Se o incidente for resolvido, aumente o tráfego de volta gradualmente em vez de atropelar o provedor.
O circuit breaker também deve acompanhar sua própria telemetria:
- Taxa de erro por provedor, modelo, região e endpoint.
- P50, P95 e taxa de timeout para chamadas com streaming e sem streaming.
- Tentativas de retry por resposta bem-sucedida.
- Taxa de fallback e pontuação de qualidade do fallback.
- Taxa de falha visível ao usuário, não só taxa de falha da API.
Essa última métrica é a que executivos entendem. Se o Opus 4.8 retorna 10% de erros, mas seu produto retorna respostas degradadas úteis para 99,5% das ações dos usuários, você tem um incidente, mas não um incêndio com clientes. Se seu produto trava porque toda requisição bloqueia no Opus, foi você que acendeu o fogo.

O que deve mudar esta semana
Primeiro, remova o Opus 4.8 de qualquer ponto único de falha. Ele ainda pode ser seu melhor modelo. Não deve ser seu único caminho.
Segundo, classifique prompts por tolerância à degradação. “Precisa usar Opus” deve ser raro e explícito. “Pode usar Sonnet” deve ser comum. “Pode enfileirar” deve ser o padrão para processamento de documentos, geração de relatórios, revisão de código em lote e análise não interativa.
Terceiro, torne retries visíveis. Registre request_id, modelo, código de status, contagem de retries, resultado final e destino de fallback. A documentação da Anthropic diz que erros da API incluem IDs de requisição e que pedidos de suporte devem incluí-los (Claude Docs). Se você não consegue responder “qual modelo falhou e para onde roteamos depois?” durante um incidente, sua observabilidade não está pronta.
Quarto, teste seu caminho de fallback de propósito. Adicione uma feature flag que force falhas do Opus em staging. Rode um game day de uma hora em que toda chamada ao Opus retorne 529. Veja o que quebra: suposições de prompt, parsers de saída, limiares de avaliação, textos da UI, promessas a clientes. Corrija isso antes do próximo incidente real.
Por fim, seja honesto com os usuários. “A IA falhou” é uma UX ruim. “Estamos executando isso no modo padrão porque o modelo avançado está temporariamente degradado” é muito melhor. Para alguns produtos, essa frase vai construir confiança.
Os incidentes de 16 a 19 de junho não provam que o Claude Opus 4.8 é um modelo ruim. Eles provam que modelos de fronteira agora são dependências de produção com características instáveis de disponibilidade. Trate-os como processadores de pagamento, índices de busca e regiões de cloud: úteis, caros e absolutamente capazes de acabar com o seu dia se você os conectar sem fallback.
Leitores que quiserem testar o Claude Fable 5 podem usá-lo pela OneHop como um endpoint drop-in, cerca de 30% abaixo do preço de tabela. Novas contas ganham US$ 10 grátis sem cartão: Claude Fable 5 na OneHop ou comece com US$ 10 grátis.
Leitura complementar: Como começar com Claude Fable 5.

