Am 16. Juni verzeichnete Anthropic auf der eigenen Statusseite die Zahl, die Production Engineers interessieren sollte: Alle Sonnet- und Opus-Modelle erreichten für 37 Minuten eine Fehlerrate von ungefähr 10%, danach lief Claude Opus 4.8 weitere 80 Minuten lang mit einer durchschnittlichen Fehlerrate von 10% weiter (Claude Status). Das ist keine „später noch mal versuchen“-Kleinigkeit, wenn deine App Claude mitten in einem nutzerseitigen Workflow aufruft. Das ist ein Design-Review.
Dabei blieb es nicht. Claude Status zeigt vom 16. bis 19. Juni wiederholte Vorfälle mit Opus 4.8 und dem breiteren Claude-Dienst: drei Opus-spezifische Vorfälle am 16. Juni, vier weitere Opus/Sonnet- oder reine Opus-Vorfälle am 17. Juni, eine Störung der Claude-Dienste am 18. Juni und zwei API- oder Opus-4.8-Vorfälle am 19. Juni (Claude Status). Am 20. Juni meldet die Seite zwar, dass heute keine Vorfälle berichtet wurden, aber das Muster der letzten Tage ist deutlich genug.
Anthropic veröffentlichte Claude Opus 4.8 am 28. Mai als Upgrade zum gleichen Preis für Opus 4.7 und positionierte es als stärkeren Kollaborateur mit besserer Benchmark-Leistung und verbesserter Ehrlichkeit (Anthropic). Das mag alles stimmen. Es ändert nichts an der operativen Realität: Wenn Opus 4.8 auf deinem kritischen Pfad liegt, braucht deine App jetzt einen echten Fehlermodus.
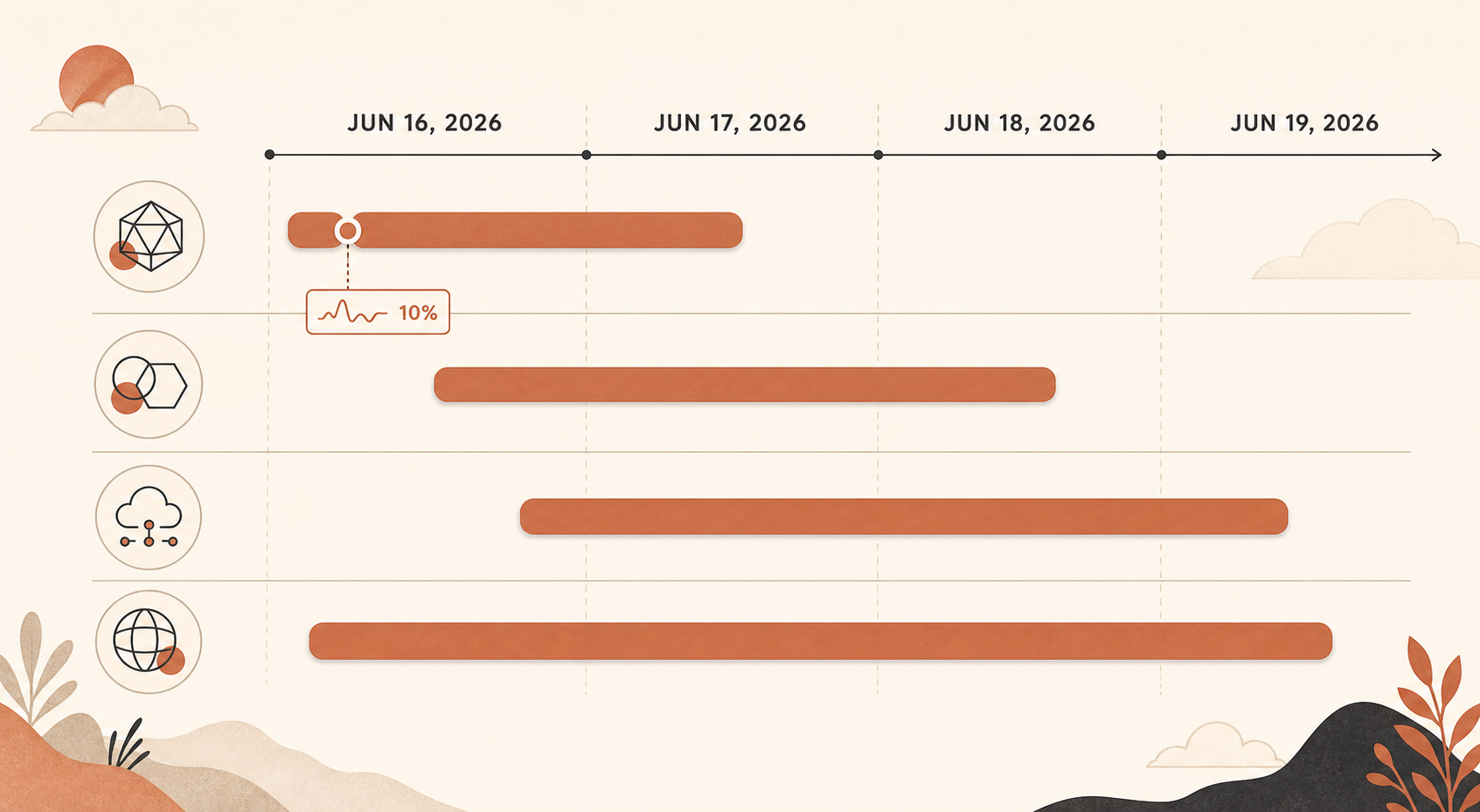
Was passiert ist, in UTC
Der wichtige Vorfall begann am 16. Juni um 17:29 UTC, als Claude Status eine Untersuchung zu erhöhten Fehlerraten über viele Modelle hinweg eröffnete. Anthropic fasste ihn später in zwei Phasen zusammen: Von 17:23 bis 18:00 UTC waren alle Sonnet- und Opus-Modelle betroffen und erreichten etwa 10% Fehlerrate; von 18:00 bis 19:20 UTC lag allein Opus 4.8 im Schnitt bei 10% Fehlerrate (Claude Status).
Danach kamen kleinere, aber immer noch schmerzhafte Opus-4.8-Spitzen. Am 16. Juni erfasste Claude Status separat Opus-4.8-Fehler um 19:41-19:53 UTC sowie einen weiteren Opus-4.8-Vorfall von 20:45-20:58 UTC (Claude Status). Am 17. Juni gab es mehrere Opus-4.8-Vorfälle, darunter einen, bei dem Requests von 04:59 bis 05:41 UTC erhöhte Fehlerraten hatten, und einen weiteren Vorfall mit Sonnet 4.6 plus Opus 4.8, bei dem Sonnet zuerst wiederhergestellt war, während Opus 4.8 noch Arbeit brauchte (Claude Status).
Der 18. Juni war breiter: Laut Claude Status betraf eine Service-Störung die Claude-Dienste von 06:55 bis 07:40 UTC (Claude Status). Am 19. Juni folgten dann ein Opus-4.8-Vorfall von 06:07 bis 07:17 UTC und ein separater Vorfall mit „erhöhten Fehlerraten auf der Claude API“ von 08:17 bis 08:45 UTC (Claude Status).
Diese Zeitleiste ist wichtig, weil es kein sauberer einzelner Ausfall war. Es war ein Cluster. Ein einzelner Retry kann einen 30-Sekunden-Aussetzer verstecken. Er rettet kein Produkt vor wiederholter Instabilität auf Modellebene über mehrere Tage hinweg.
Warum Entwickler sauer sind
Der Hacker-News-Thread zu erhöhten Claude-Fehlern ist genau das, was man von Leuten erwartet, die KI von Spielzeug-Prompts in den täglichen Production-Betrieb gebracht haben: Frust, Witze und eine ernsthafte Debatte über Abhängigkeitsrisiken (Hacker News).
Ein Lager sieht darin normale Wachstumsschmerzen von Frontier-Modellen. GPU-Kapazität ist schwierig, Nachfrage kommt in Wellen, und diese Modelle sind teuer im Betrieb. Das andere Lager ist weniger nachsichtig: Wenn Teams bezahlte Produkte und interne Workflows rund um Claude Code, Claude API und Modelle der Opus-Klasse bauen, dann ist „erhöhte Fehlerrate“ kein harmloser Euphemismus. Es ist Downtime mit hübscherer Formulierung.
Die schärfsten Kommentare sagen nicht einfach „Claude ist down“. Sie drehen sich um Dependency Inversion. Entwickler nutzen nicht mehr bloß eine API, um ein Feature anzureichern. Sie bauen Workflows, in denen das Modell Code schreibt, Code reviewt, Tickets triagiert, Daten extrahiert und Kunden antwortet. Ein HN-Kommentator beschrieb kundenseitige Automatisierungssysteme, deren Uptime durch die Uptime des LLM-Providers gedeckelt ist, und nannte dann die praktischen Gegenmaßnahmen: Multi-Provider-Fallback, asynchrone Queues und Graceful Degradation (Hacker News).
Das ist der nützliche Teil der Community-Debatte. Die Frage ist nicht mehr, ob Opus 4.8 gut ist. Die Frage ist, ob dein System es wie eine Datenbank behandelt, wie einen Cache, wie eine wackelige SaaS-Abhängigkeit oder wie einen menschlichen Spezialisten, der manchmal nicht verfügbar ist.
Die richtige Antwort lautet: wie einen wackeligen Spezialisten.
Retry-Budgets brauchen eine harte Obergrenze
Anthropic’s Fehlerdokumentation unterscheidet zwischen gewöhnlichen fehlerhaften Requests, Account-Rate-Limits, internen API-Fehlern, Timeouts und Überlastung. Die zentralen Codes hier sind 500 api_error, 504 timeout_error, 529 overloaded_error und manchmal 429 rate_limit_error, wenn dein eigener Traffic-Anstieg Limits auslöst. Anthropic sagt, 529 bedeute, dass die API vorübergehend überlastet ist, und könne auftreten, wenn APIs über alle Nutzer hinweg hohen Traffic erleben (Claude Docs).
Retrye diese Fälle nicht blind alle gleich. Ein 400 wegen eines nicht unterstützten Parameters ist dein Bug. Tatsächlich übernimmt Opus 4.8 die Einschränkungen von Opus 4.7: Das Setzen von nicht standardmäßigen Werten für temperature, top_p oder top_k liefert auf der Messages API einen 400 zurück (Claude Docs). Das erneut zu versuchen verbrennt nur Latenz.
Bei Überlastung und internen Fehlern sind Retries nur innerhalb eines Budgets sinnvoll. Ein nutzerseitiger Request mit einem 6-Sekunden-SLA sollte nicht 45 Sekunden lang höflich auf Opus 4.8 einhämmern. Gib jedem Request ein Retry-Budget und degradiere danach.
Ein vernünftiger Default:
const retryable = new Set([500, 504, 529]);
async function callWithBudget(request, budgetMs = 6000) {
const started = Date.now();
for (let attempt = 0; ; attempt++) {
try {
return await callClaude(request);
} catch (error) {
if (!retryable.has(error.status) || Date.now() - started > budgetMs) {
throw error;
}
const delay = Math.min(250 * 2 ** attempt, 2000) * (0.5 + Math.random());
await sleep(delay);
}
}
}Die genauen Zahlen sollten zu deinem Produkt passen. Ein Coding Agent kann länger warten als ein Checkout-Assistent. Eine Hintergrundpipeline für Dokumente kann Minuten warten. Ein Voice Agent kann das nicht.
Der größere Punkt: Retries sind keine Zuverlässigkeit. Retries sind eine Brücke entweder zur Erholung oder zum Fallback.
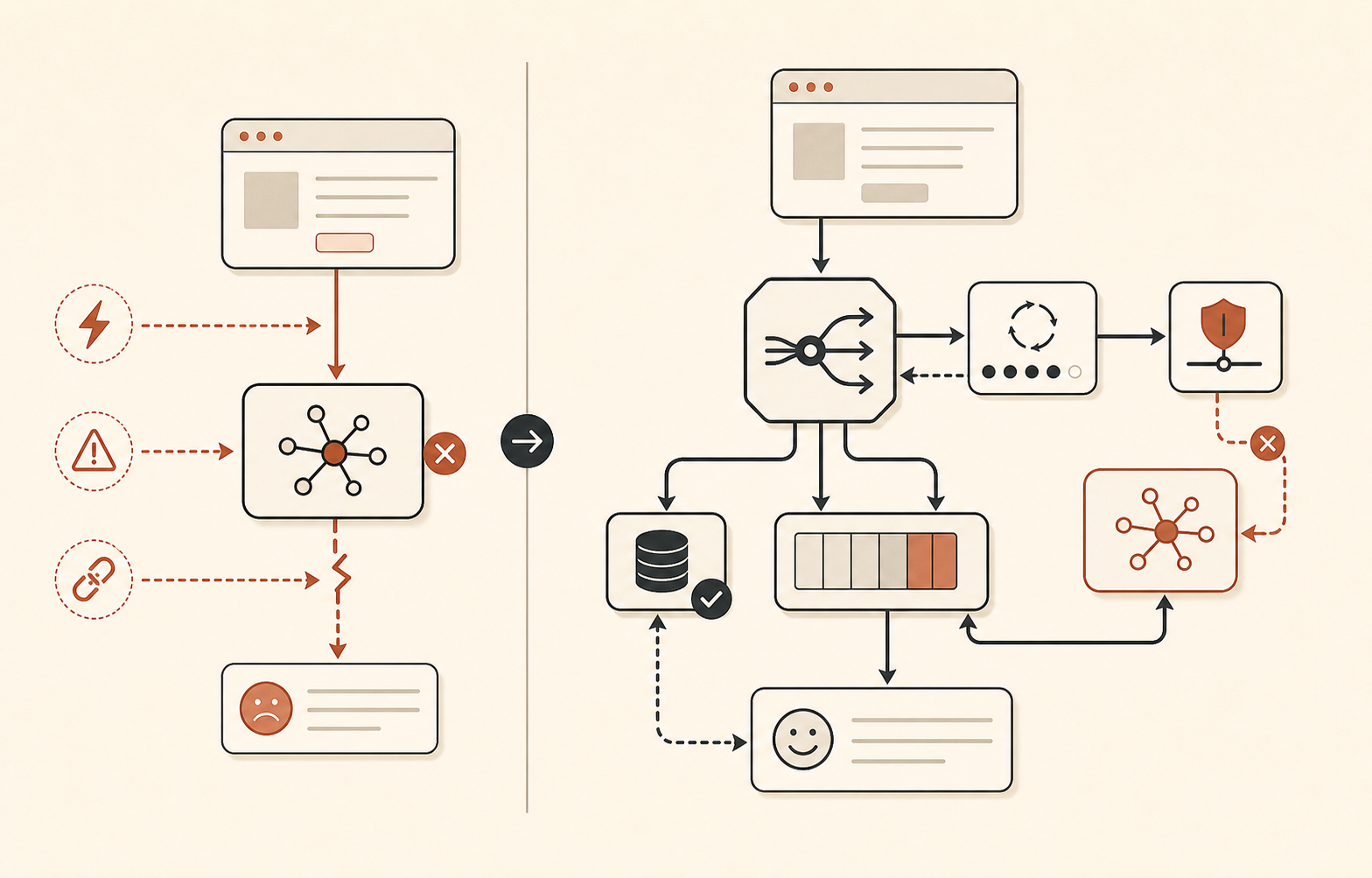
Fallback-Routing sollte langweilig sein
Der Vorfall vom 16. Juni ist eine gute Erinnerung daran, dass „Fallback auf Sonnet“ nicht immer reicht. In der ersten Phase waren alle Sonnet- und Opus-Modelle betroffen. In der zweiten Phase blieb Opus 4.8 ungesund, während Sonnet sich erholte. Am 17. Juni erfasste Claude Status außerdem einen Vorfall mit Sonnet 4.6 und Opus 4.8, bei dem sich die Sonnet-Erfolgsraten erholten, während Opus 4.8 weiterhin erhöhte Fehlerraten hatte (Claude Status).
Modell-Fallback sollte also Stufen haben, keine Bauchgefühle.
| Stufe | Verwenden, wenn | Beispielaktion |
|---|---|---|
| Opus-Klasse als Primärmodell | Aufgaben mit hohem Reasoning-Bedarf die beste Qualität brauchen | Opus 4.8 innerhalb eines strikten Budgets versuchen |
| Sonnet-Klasse als Fallback | Opus-spezifische Fehler oder Latenz | Für denselben Prompt auf Sonnet routen, wenn die Qualität akzeptabel ist |
| Nicht-Claude-Fallback | Claude API oder Multi-Modell-Vorfall | Zu einem anderen Provider, kleineren Modell oder lokalen/offenen Modell routen |
| Produkt-Fallback | KI-Pfad nicht verfügbar | Arbeit queuen, gecachtes Ergebnis zurückgeben, an Menschen übergeben oder degradierte UI anzeigen |
Auch der Preis gehört in diese Routing-Entscheidung. Anthropic’s Preisblatt vom 27. Mai listet Claude Opus 4.8 im globalen Standardpreis mit 5 US-Dollar pro Million Input-Tokens und 25 US-Dollar pro Million Output-Tokens, Sonnet 4.6 mit 3 und 15 US-Dollar und Haiku 4.5 mit 1 und 5 US-Dollar in den Google-Vertex-AI-Listings (Anthropic price sheet). Das heißt: Fallback ist nicht nur ein Uptime-Werkzeug. Es ist auch ein Werkzeug zur Kostenkontrolle.
Degradiere nicht jede Aufgabe auf dieselbe Weise. Ein juristischer Analyseentwurf muss vielleicht warten, bis Opus zurück ist. Ein Support-Chatbot kann auf ein günstigeres Modell wechseln und eine klärende Rückfrage stellen. Ein Code-Assistent kann den Workspace sichern und dem Nutzer sagen, dass er das Modell wechselt, bevor er Änderungen vornimmt. Stiller Fallback ist gefährlich, wenn sich das Modellverhalten spürbar ändert.
Beobachte die Statusseite wie ein Eingangssignal
Claude Status bietet auf der Statusseite Abos per E-Mail, Slack, Microsoft Teams, Webhook, Atom und RSS an (Claude Status). Nutze sie. Aber hör nicht bei einem Slack-Channel auf, in dem Alerts sterben gehen.
Leite Statusänderungen in dein LLM-Gateway ein. Wenn ein Opus-4.8-Vorfall eröffnet wird, senke den Circuit-Breaker-Schwellenwert für Opus. Wenn ein Claude-API-weiter Vorfall eröffnet wird, sende interaktiven Traffic nach dem ersten schnellen Fehler nicht weiter und verschiebe geeignete Jobs in eine Queue. Wenn der Vorfall behoben ist, fahre Traffic schrittweise wieder hoch, statt den Provider zu überrennen.
Der Circuit Breaker sollte auch deine eigene Telemetrie verfolgen:
- Fehlerrate nach Provider, Modell, Region und Endpoint.
- P50, P95 und Timeout-Rate für Streaming- und Nicht-Streaming-Aufrufe.
- Retry-Versuche pro erfolgreicher Antwort.
- Fallback-Rate und Fallback-Qualitätsscore.
- Nutzerseitig sichtbare Fehlerrate, nicht nur API-Fehlerrate.
Diese letzte Metrik ist die, die Führungskräfte verstehen. Wenn Opus 4.8 10% Fehler zurückgibt, dein Produkt aber für 99,5% der Nutzeraktionen brauchbare degradierte Antworten liefert, hast du einen Vorfall, aber keinen Kundenbrand. Wenn dein Produkt hängt, weil jeder Request auf Opus blockiert, hast du das Feuer selbst gelegt.

Was sich diese Woche ändern sollte
Erstens: Entferne Opus 4.8 aus jedem Single Point of Failure. Es kann weiterhin dein bestes Modell sein. Es sollte nicht dein einziger Weg sein.
Zweitens: Klassifiziere Prompts nach Degradationstoleranz. „Muss Opus verwenden“ sollte selten und explizit sein. „Kann Sonnet verwenden“ sollte üblich sein. „Kann in die Queue“ sollte der Default für Dokumentverarbeitung, Report-Erstellung, Batch-Code-Review und nicht-interaktive Analysen sein.
Drittens: Mach Retries sichtbar. Logge request_id, Modell, Statuscode, Retry-Anzahl, Endergebnis und Fallback-Ziel. Anthropic’s Docs sagen, dass API-Fehler Request-IDs enthalten und dass Support-Anfragen diese enthalten sollten (Claude Docs). Wenn du während eines Vorfalls nicht beantworten kannst „welches Modell ist fehlgeschlagen und wohin haben wir danach geroutet?“, ist deine Observability nicht bereit.
Viertens: Teste deinen Fallback-Pfad absichtlich. Füge ein Feature Flag hinzu, das Opus-Fehler in Staging erzwingt. Mach einen einstündigen Game Day, bei dem jeder Opus-Aufruf 529 zurückgibt. Schau, was bricht: Prompt-Annahmen, Output-Parser, Eval-Schwellen, UI-Copy, Kundenversprechen. Repariere das vor dem nächsten echten Vorfall.
Und schließlich: Sei ehrlich zu Nutzern. „Die KI ist fehlgeschlagen“ ist schlechte UX. „Wir führen das im Standardmodus aus, weil das fortgeschrittene Modell vorübergehend beeinträchtigt ist“ ist deutlich besser. Für manche Produkte wird dieser Satz Vertrauen schaffen.
Die Vorfälle vom 16. bis 19. Juni beweisen nicht, dass Claude Opus 4.8 ein schlechtes Modell ist. Sie beweisen, dass Frontier-Modelle inzwischen Production-Abhängigkeiten mit instabilen Verfügbarkeitsmerkmalen sind. Behandle sie wie Zahlungsdienstleister, Suchindizes und Cloud-Regionen: nützlich, teuer und absolut in der Lage, dir den Tag zu ruinieren, wenn du sie ohne Fallback einbaust.
Leser, die Claude Fable 5 selbst ausprobieren möchten, können es über OneHop als Drop-in-Endpoint nutzen, rund 30% unter Listenpreis. Neue Accounts erhalten 10 US-Dollar gratis ohne Karte: Claude Fable 5 on OneHop oder mit 10 US-Dollar gratis starten.
Weiterlesen: Erste Schritte mit Claude Fable 5.

