6 月 16 日,Anthropic 自己的状态页记录了一个生产工程师真正该关心的数字:所有 Sonnet 和 Opus 模型在 37 分钟内错误率大约达到 10%,随后 Claude Opus 4.8 又继续维持了 80 分钟、平均 10% 的错误率(Claude Status)。如果你的应用在面向用户的流程里调用 Claude,这就不是“稍后再试”的小麻烦了。这是一次架构复盘。
事故并没有就此结束。Claude Status 显示,从 6 月 16 日到 6 月 19 日,Opus 4.8 以及更广泛的 Claude 服务反复出现事故:6 月 16 日有 3 起 Opus 专属事故,6 月 17 日又有 4 起 Opus/Sonnet 或仅 Opus 的事故,6 月 18 日出现 Claude 服务中断,6 月 19 日又有 2 起 API 或 Opus 4.8 事故(Claude Status)。截至 6 月 20 日,页面显示今天没有报告事故,但近期模式已经足够清楚。
Anthropic 在 5 月 28 日发布 Claude Opus 4.8,把它定位为 Opus 4.7 的同价升级版:协作能力更强,基准表现更好,也更诚实(Anthropic)。这些可能都是真的。但它不改变一个运维现实:如果 Opus 4.8 在你的关键路径上,你的应用现在就需要真正的失败模式。
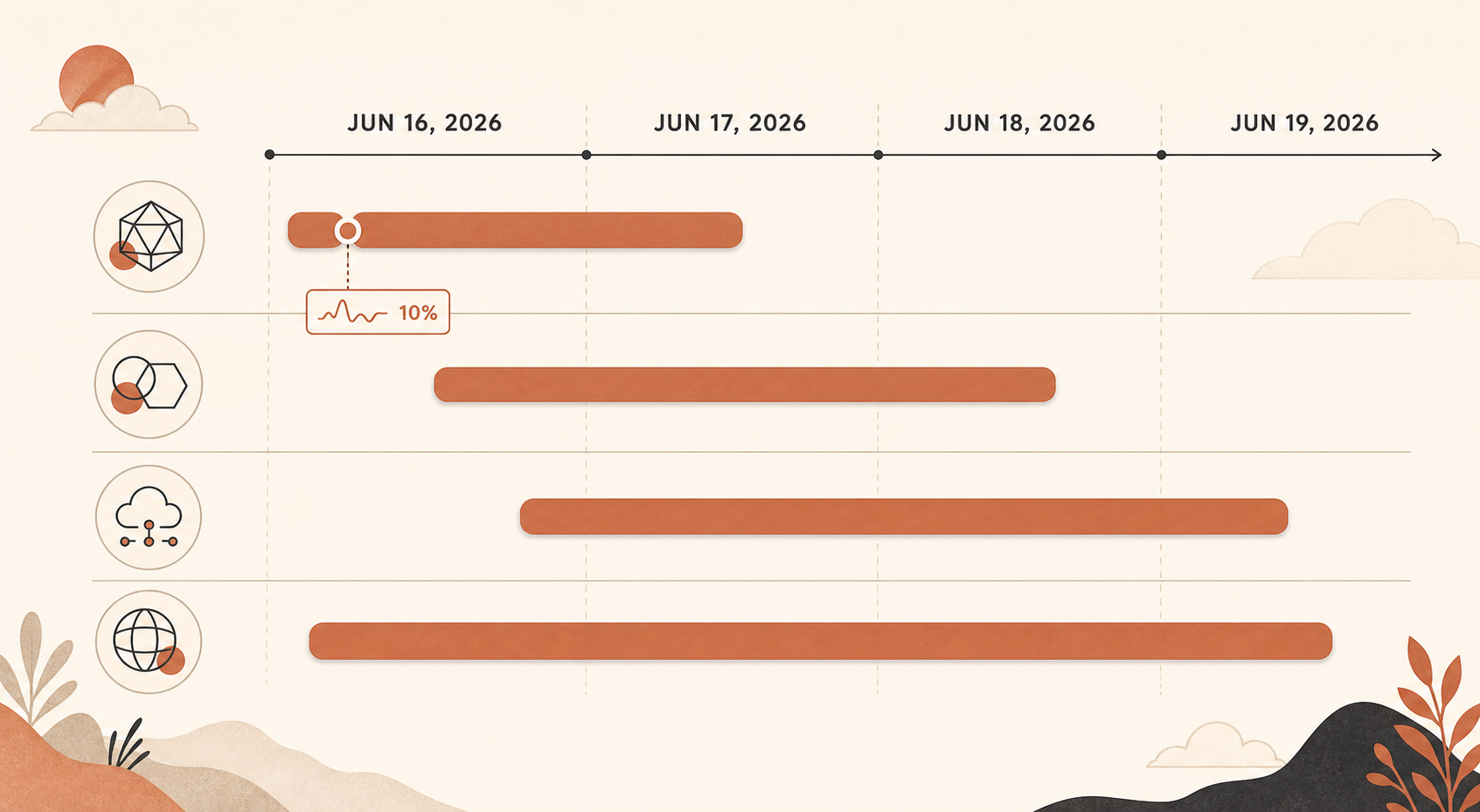
发生了什么,按 UTC 时间
关键事故始于 6 月 16 日 17:29 UTC,当时 Claude Status 对多个模型的错误率升高展开调查。Anthropic 后来把它总结为两个阶段:从 17:23 到 18:00 UTC,所有 Sonnet 和 Opus 模型受到影响,错误率达到约 10%;从 18:00 到 19:20 UTC,只有 Opus 4.8 平均错误率为 10%(Claude Status)。
随后是规模较小但仍然很痛的 Opus 4.8 峰值。6 月 16 日,Claude Status 还分别记录了 19:41–19:53 UTC 左右的 Opus 4.8 错误,以及 20:45–20:58 UTC 的另一场 Opus 4.8 事故(Claude Status)。6 月 17 日出现了多起 Opus 4.8 事故,包括一次请求在 04:59 到 05:41 UTC 期间错误率升高,以及另一次 Sonnet 4.6 加 Opus 4.8 的事故:Sonnet 先恢复,而 Opus 4.8 仍需处理(Claude Status)。
6 月 18 日影响范围更广:Claude Status 称,从 06:55 到 07:40 UTC,Claude 服务受到服务中断影响(Claude Status)。6 月 19 日又出现了一起从 06:07 到 07:17 UTC 的 Opus 4.8 事故,以及一起从 08:17 到 08:45 UTC 的“Claude API 错误率升高”独立事故(Claude Status)。
这条时间线很重要,因为它不是一次干净利落的宕机。它是一串集群式问题。一次重试也许能掩盖 30 秒的抖动。但它救不了一个在数天内反复遭遇模型级不稳定的产品。
为什么开发者很生气
Hacker News 上关于 Claude 错误率升高的讨论,正是你会从那些已经把 AI 从玩具提示词推进到日常生产工作的人那里看到的东西:恼火、调侃,以及一场关于依赖风险的严肃争论(Hacker News)。
一派认为这是前沿模型正常的成长阵痛。GPU 容量很难,需求有波峰波谷,而这些模型的服务成本很高。另一派就没那么宽容了:如果团队正在围绕 Claude Code、Claude API 和 Opus 级模型构建付费产品与内部工作流,那么“错误率升高”就不是无害的委婉说法。它就是换了个更好听措辞的停机。
最尖锐的评论不只是“Claude 挂了”。它们谈的是依赖倒置。开发者不再只是用一个 API 给某个功能锦上添花。他们正在构建这样的工作流:模型写代码、审代码、分拣工单、抽取数据、回答客户。一位 HN 评论者描述了面向客户的自动化系统,其可用性被 LLM 提供商的可用性封顶,然后列出了实际修复手段:多供应商 fallback、异步队列、优雅降级(Hacker News)。
这才是社区争论里有用的部分。问题不再是 Opus 4.8 好不好。问题是你的系统到底把它当成数据库、缓存、脆弱的 SaaS 依赖,还是一个有时不在线的人类专家。
正确答案是:一个脆弱的专家。
重试预算需要硬上限
Anthropic 的错误文档区分了普通的错误请求、账户限流、内部 API 错误、超时和过载。这里的关键代码是 500 api_error、504 timeout_error、529 overloaded_error,有时还有 429 rate_limit_error,如果是你自己的流量爬坡触发了限制。Anthropic 表示,529 意味着 API 暂时过载,并且可能在所有用户的 API 流量都很高时发生(Claude Docs)。
不要把这些错误一股脑用同一种方式盲目重试。来自不支持参数的 400 是你的 bug。事实上,Opus 4.8 继承了 Opus 4.7 的约束:在 Messages API 上设置非默认的 temperature、top_p 或 top_k 会返回 400(Claude Docs)。重试这种错误只是在烧延迟。
对于过载和内部故障,重试只有在预算之内才有用。一个 6 秒 SLA 的用户请求,不应该花 45 秒礼貌地猛敲 Opus 4.8。给每个请求一个重试预算,然后降级。
一个合理的默认值:
const retryable = new Set([500, 504, 529]);
async function callWithBudget(request, budgetMs = 6000) {
const started = Date.now();
for (let attempt = 0; ; attempt++) {
try {
return await callClaude(request);
} catch (error) {
if (!retryable.has(error.status) || Date.now() - started > budgetMs) {
throw error;
}
const delay = Math.min(250 * 2 ** attempt, 2000) * (0.5 + Math.random());
await sleep(delay);
}
}
}具体数字应该匹配你的产品。编码 agent 可以等久一点。结账助手不行。后台文档流水线可以等几分钟。语音 agent 不能。
更大的重点是:重试不是可靠性。重试只是通往恢复或 fallback 的桥。
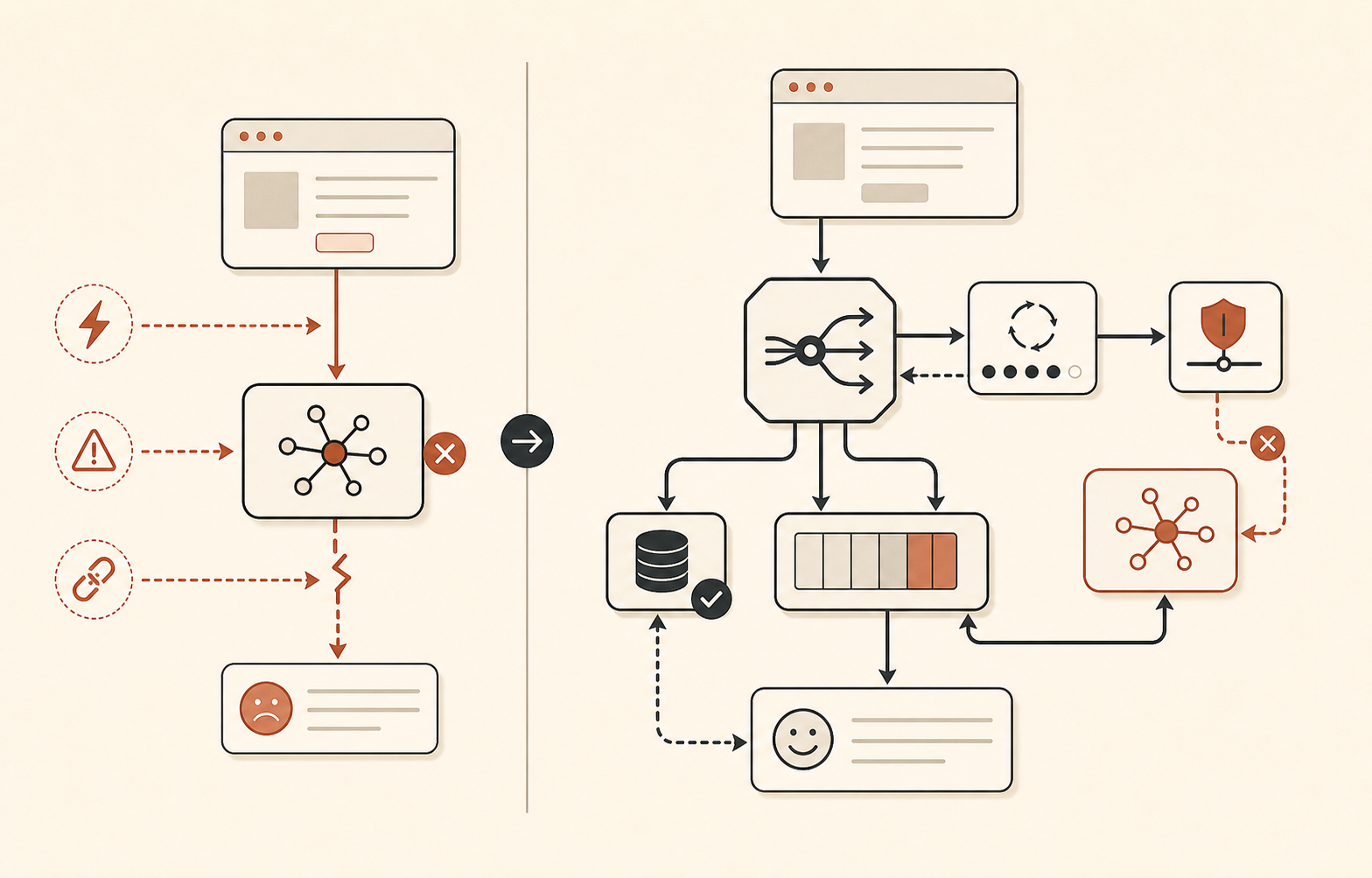
fallback 路由应该无聊
6 月 16 日的事故很好地提醒我们,“fallback 到 Sonnet”并不总是足够。第一阶段,所有 Sonnet 和 Opus 模型都受到影响。第二阶段,Opus 4.8 仍然不健康,而 Sonnet 恢复了。6 月 17 日,Claude Status 也记录了一起 Sonnet 4.6 和 Opus 4.8 事故,其中 Sonnet 成功率恢复,而 Opus 4.8 仍有较高错误率(Claude Status)。
所以模型 fallback 应该有分层,而不是凭感觉。
| 层级 | 使用场景 | 示例动作 |
|---|---|---|
| Opus 级主模型 | 高推理任务需要最佳质量 | 在严格预算内尝试 Opus 4.8 |
| Sonnet 级 fallback | Opus 专属错误或延迟 | 如果质量可接受,用同一提示词路由到 Sonnet |
| 非 Claude fallback | Claude API 或多模型事故 | 路由到另一家提供商、更小模型,或本地/开源模型 |
| 产品 fallback | AI 路径不可用 | 排队处理、返回缓存结果、交给人工,或展示降级 UI |
价格也应该进入路由决策。Anthropic 5 月 27 日价格表显示,在全球标准定价下,Claude Opus 4.8 的价格是每百万输入 token 5 美元、每百万输出 token 25 美元;Sonnet 4.6 是 3 美元和 15 美元;Google Vertex AI 列表中的 Haiku 4.5 是 1 美元和 5 美元(Anthropic price sheet)。这意味着 fallback 不只是可用性工具。它也是成本控制工具。
不要让所有任务用同一种方式降级。法律分析草稿可能需要排队等 Opus 恢复。客服聊天机器人可以切到更便宜的模型,并多问一个澄清问题。代码助手可以保留工作区,并在修改前告诉用户它正在切换模型。当模型行为有明显变化时,静默 fallback 很危险。
像输入信号一样监控状态页
Claude Status 在状态页上提供 email、Slack、Microsoft Teams、webhook、Atom 和 RSS 订阅选项(Claude Status)。用起来。但不要止步于一个告警进去就死掉的 Slack 频道。
把状态变化喂给你的 LLM 网关。如果 Opus 4.8 事故开启,就降低 Opus 的断路器阈值。如果 Claude API 全局事故开启,就在第一次快速失败后停止发送交互式流量,并把符合条件的任务移入队列。如果事故解决,就逐步恢复流量,而不是一窝蜂冲回提供商。
断路器也应该跟踪你自己的遥测数据:
- 按提供商、模型、区域和端点统计错误率。
- 流式和非流式调用的 P50、P95 以及超时率。
- 每次成功响应对应的重试次数。
- fallback 率和 fallback 质量评分。
- 用户可见失败率,而不只是 API 失败率。
最后这个指标才是高管能听懂的。如果 Opus 4.8 返回 10% 错误,但你的产品能为 99.5% 的用户操作返回有用的降级响应,那你有事故,但不是客户火灾。如果你的产品因为每个请求都阻塞在 Opus 上而卡死,那火就是你自己点的。

本周应该改什么
第一,把 Opus 4.8 从任何单点故障中移走。它仍然可以是你最好的模型。但它不该是你唯一的路径。
第二,按降级容忍度给提示词分类。“必须使用 Opus”应该很少见,并且明确标注。“可以使用 Sonnet”应该很常见。“可以排队”应该是文档处理、报告生成、批量代码审查和非交互式分析的默认选择。
第三,让重试可见。记录 request_id、模型、状态码、重试次数、最终结果和 fallback 目标。Anthropic 文档说 API 错误包含请求 ID,联系支持时也应该附上这些 ID(Claude Docs)。如果事故期间你回答不了“哪个模型失败了,我们接着路由到了哪里?”,你的可观测性还没准备好。
第四,有意测试你的 fallback 路径。加一个功能开关,在 staging 中强制 Opus 失败。安排一小时 game day,让每次 Opus 调用都返回 529。看看哪里会坏:提示词假设、输出解析器、评测阈值、UI 文案、客户承诺。在下一次真实事故前把这些修掉。
最后,对用户诚实。“AI 失败了”是糟糕的 UX。“由于高级模型暂时降级,我们正在用标准模式运行这次任务”要好得多。对一些产品来说,这句话会建立信任。
6 月 16–19 日的事故不能证明 Claude Opus 4.8 是个糟糕模型。它们证明的是,前沿模型现在已经是生产依赖,而且可用性特征并不稳定。像对待支付处理器、搜索索引和云区域一样对待它们:有用、昂贵,而且如果你不带 fallback 就接进去,它们绝对有能力毁掉你的一天。
想亲自试试 Claude Fable 5 的读者,可以通过 OneHop 把它当作即插即用端点使用,价格比标价低约 30%。新账户免绑卡送 10 美元:Claude Fable 5 on OneHop 或 start with $10 free。
延伸阅读:Claude Fable 5 入门指南.

