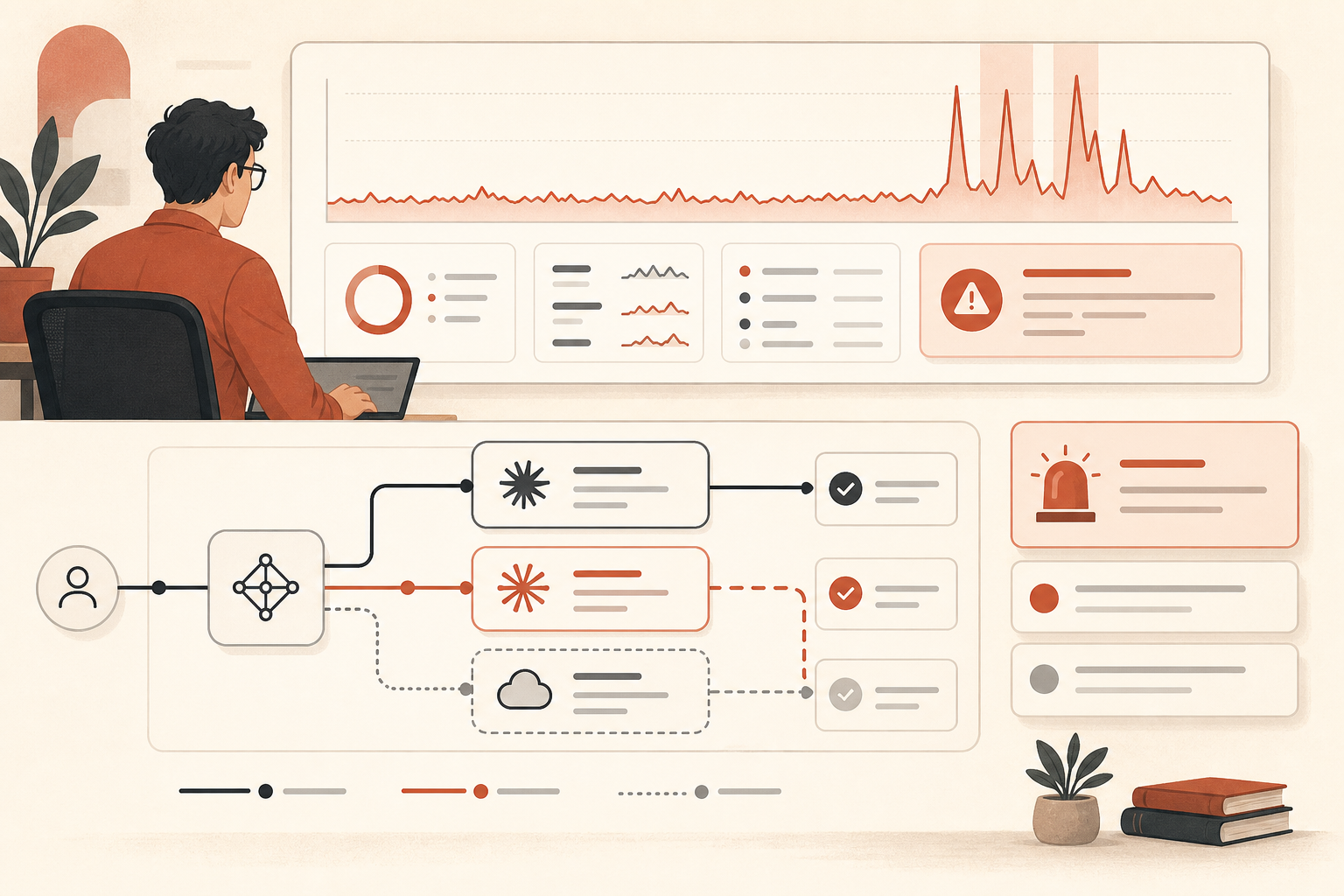
6月16日、Anthropic自身のステータスページには、本番担当エンジニアが気にすべき数字が記録された。すべてのSonnetおよびOpusモデルが37分間、約10%のエラー率に達し、その後Claude Opus 4.8だけがさらに80分間、平均10%のエラー率を続けた(Claude Status)。ユーザー向けワークフローの中でアプリがClaudeを呼んでいるなら、これは「あとで再試行してください」で済む小さな不便ではない。設計レビュー案件だ。
インシデントはそこで終わらなかった。Claude Statusを見ると、6月16日から6月19日にかけて、Opus 4.8単体およびClaudeサービス全体に関わるインシデントが繰り返し発生している。6月16日にOpus固有のインシデントが3件、6月17日にOpus/SonnetまたはOpusのみのインシデントがさらに4件、6月18日にClaudeサービスの障害、6月19日にAPIまたはOpus 4.8のインシデントが2件だ(Claude Status)。6月20日時点で、同ページは本日のインシデント報告なしとしているが、直近のパターンは十分にはっきりしている。
Anthropicは5月28日、Claude Opus 4.8をOpus 4.7と同価格のアップグレードとしてリリースし、ベンチマーク性能と誠実性を改善した、より強力な協働相手として位置づけた(Anthropic)。それは全部その通りかもしれない。だが運用上の現実は変わらない。Opus 4.8がクリティカルパスにいるなら、あなたのアプリには本物の障害モードが必要になった。
UTCで何が起きたのか
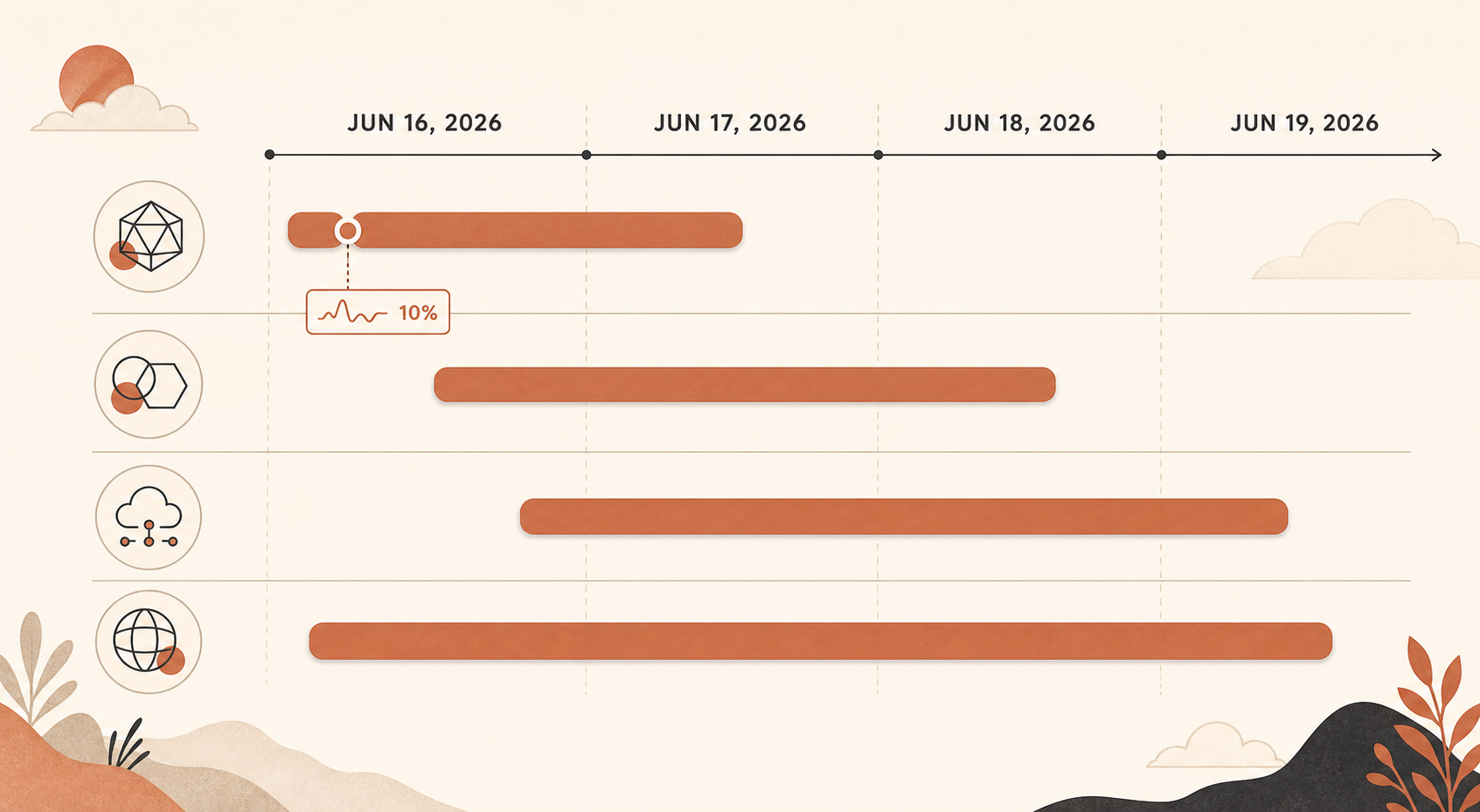
重要なインシデントは6月16日17:29 UTCに始まった。Claude Statusが多くのモデルでエラー増加の調査を開始した時刻だ。Anthropicは後にこれを2段階で要約している。17:23から18:00 UTCまでは、すべてのSonnetおよびOpusモデルが影響を受け、約10%のエラー率に達した。18:00から19:20 UTCまでは、Opus 4.8のみが平均10%のエラー率となった(Claude Status)。
その後、規模は小さいが痛みは十分なOpus 4.8のスパイクが続いた。6月16日には、Claude Statusが19:41〜19:53 UTCごろのOpus 4.8エラーを別途記録し、さらに20:45〜20:58 UTCにもOpus 4.8のインシデントを記録している(Claude Status)。6月17日にはOpus 4.8のインシデントが複数あり、04:59から05:41 UTCまでリクエストでエラーが増加したものや、Sonnet 4.6とOpus 4.8のインシデントでSonnetが先に回復し、Opus 4.8にはまだ対応が必要だったものも含まれている(Claude Status)。
6月18日はより広範囲だった。Claude Statusによると、06:55から07:40 UTCまでClaudeサービスに影響するサービス障害が発生した(Claude Status)。6月19日には、06:07から07:17 UTCまでOpus 4.8のインシデントがあり、08:17から08:45 UTCまでは別件として「Claude APIでのエラー率上昇」のインシデントが発生した(Claude Status)。
このタイムラインが重要なのは、きれいな単発障害ではなかったからだ。これはクラスターだった。1回のリトライなら30秒の瞬断は隠せるかもしれない。だが数日にわたってモデルレベルの不安定さが繰り返される状況から、プロダクトを救うことはできない。
なぜ開発者は怒っているのか
Claudeのエラー増加に関するHacker Newsのスレッドは、AIをおもちゃのプロンプトから日常の本番業務へ移した人たちから当然出てくる反応そのものだ。不満、ジョーク、そして依存リスクをめぐる真剣な議論である(Hacker News)。
一方の陣営は、これをフロンティアモデルにはつきものの成長痛と見る。GPUキャパシティは難しく、需要はバーストし、こうしたモデルの提供コストは高い。もう一方の陣営は、それほど寛容ではない。チームがClaude Code、Claude API、Opus級モデルを中心に有料プロダクトや社内ワークフローを組んでいるなら、「エラー率上昇」は害のない婉曲表現ではない。言い方を柔らかくしたダウンタイムだ。
最も鋭いコメントは、単に「Claudeが落ちている」という話ではない。依存関係の反転についてだ。開発者はもはや、機能を少し豊かにするためにAPIを使っているだけではない。モデルがコードを書き、コードをレビューし、チケットをトリアージし、データを抽出し、顧客に回答するワークフローを組んでいる。あるHNコメント投稿者は、稼働率がLLMプロバイダーの稼働率に縛られる顧客向け自動化システムを説明し、そのうえで実用的な対策として、複数プロバイダーへのフォールバック、非同期キュー、グレースフルデグラデーションを挙げていた(Hacker News)。
コミュニティの議論で有用なのはそこだ。問題はもはやOpus 4.8が優秀かどうかではない。あなたのシステムがそれをデータベースとして扱っているのか、キャッシュとして扱っているのか、不安定なSaaS依存先として扱っているのか、それとも時々つかまらない人間の専門家として扱っているのか、という話だ。
正解は、不安定な専門家である。
リトライ予算には硬い上限が必要だ
Anthropicのエラードキュメントは、通常の不正リクエスト、アカウントのレート制限、内部APIエラー、タイムアウト、過負荷を区別している。ここで重要なコードは500 api_error、504 timeout_error、529 overloaded_error、場合によっては自分たちのトラフィック増加が制限を踏んだときの429 rate_limit_errorだ。Anthropicによると、529はAPIが一時的に過負荷であることを意味し、API全体で全ユーザーからの高トラフィックが発生しているときに起こりうる(Claude Docs)。
これらすべてを同じように闇雲にリトライしてはいけない。サポートされていないパラメータによる400はあなたのバグだ。実際、Opus 4.8はOpus 4.7の制約を引き継いでいる。Messages APIでデフォルト以外のtemperature、top_p、top_kを設定すると400が返る(Claude Docs)。それをリトライしてもレイテンシを燃やすだけだ。
過負荷や内部障害に対して、リトライが役に立つのは予算内に限られる。6秒のSLAを持つユーザー向けリクエストが、45秒も丁寧にOpus 4.8を叩き続けるべきではない。各リクエストにリトライ予算を与え、尽きたら縮退させる。
まともなデフォルトはこうだ。
const retryable = new Set([500, 504, 529]);
async function callWithBudget(request, budgetMs = 6000) {
const started = Date.now();
for (let attempt = 0; ; attempt++) {
try {
return await callClaude(request);
} catch (error) {
if (!retryable.has(error.status) || Date.now() - started > budgetMs) {
throw error;
}
const delay = Math.min(250 * 2 ** attempt, 2000) * (0.5 + Math.random());
await sleep(delay);
}
}
}具体的な数字はプロダクトに合わせるべきだ。コーディングエージェントはチェックアウト支援より長く待てる。バックグラウンドの文書パイプラインなら数分待てる。音声エージェントは待てない。
より大きなポイントは、リトライは信頼性ではないということだ。リトライは、回復かフォールバックへ渡るための橋でしかない。
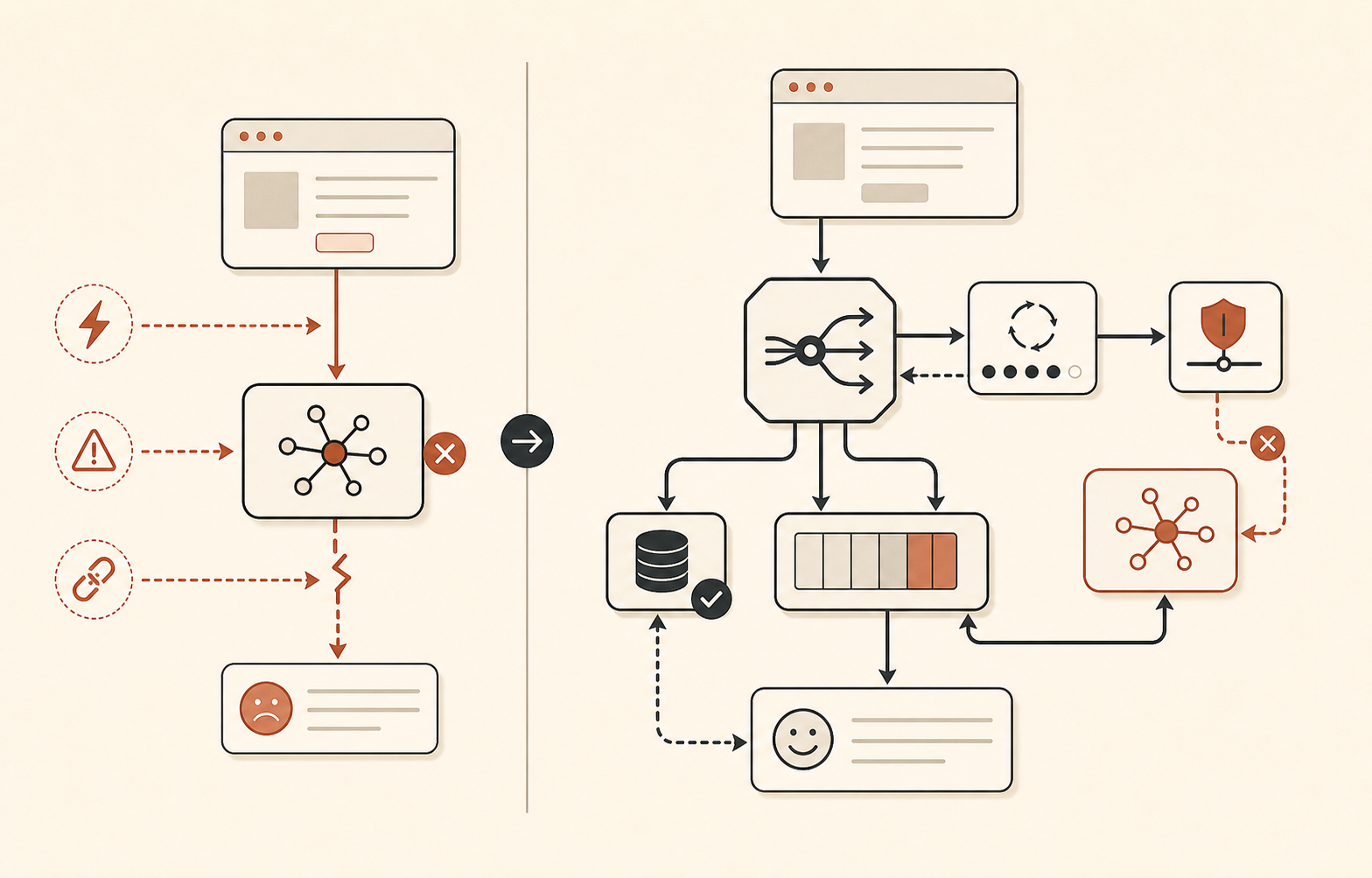
フォールバックルーティングは退屈であるべきだ
6月16日のインシデントは、「Sonnetにフォールバックすればよい」が常に十分ではないことを思い出させる好例だ。最初の段階では、すべてのSonnetおよびOpusモデルが影響を受けた。第2段階では、Sonnetが回復する一方でOpus 4.8は不健全なままだった。6月17日にも、Claude StatusはSonnet 4.6とOpus 4.8のインシデントを記録しており、Sonnetの成功率は回復したが、Opus 4.8ではまだエラーが増加していた(Claude Status)。
だからモデルのフォールバックには、雰囲気ではなく階層が必要だ。
| 階層 | 使う場面 | アクション例 |
|---|---|---|
| Opus級プライマリ | 高度な推論タスクで最高品質が必要 | 厳格な予算内でOpus 4.8を試す |
| Sonnet級フォールバック | Opus固有のエラーまたはレイテンシ | 品質が許容できるなら同じプロンプトをSonnetへルーティングする |
| 非Claudeフォールバック | Claude APIまたは複数モデルのインシデント | 別プロバイダー、小型モデル、またはローカル/オープンモデルへルーティングする |
| プロダクトフォールバック | AI経路が利用不能 | 作業をキューに入れる、キャッシュ結果を返す、人間へ引き継ぐ、または縮退UIを表示する |
価格もそのルーティング判断に含めるべきだ。Anthropicの5月27日の価格表では、グローバル標準価格でClaude Opus 4.8が入力100万トークンあたり5ドル、出力100万トークンあたり25ドル、Sonnet 4.6が3ドルと15ドル、Google Vertex AI掲載のHaiku 4.5が1ドルと5ドルとなっている(Anthropic price sheet)。つまりフォールバックは稼働率のためだけの道具ではない。コスト管理の道具でもある。
すべてのタスクを同じように縮退させてはいけない。法務分析のドラフトはOpusが戻るまでキューに入れる必要があるかもしれない。サポートチャットボットなら安いモデルに切り替え、確認質問を1つ投げればよい。コードアシスタントならワークスペースを保持し、編集に入る前にモデルを切り替えることをユーザーへ伝えられる。モデルの挙動が実質的に変わる場合、サイレントフォールバックは危険だ。
ステータスページを入力信号として監視する
Claude Statusは、ステータスページ上でメール、Slack、Microsoft Teams、webhook、Atom、RSSの購読オプションを提供している(Claude Status)。使うべきだ。ただし、アラートが死にに行くSlackチャンネルで止めてはいけない。
ステータス変更を自分たちのLLMゲートウェイへ流し込む。Opus 4.8のインシデントが開かれたら、Opusのサーキットブレーカーしきい値を下げる。Claude API全体のインシデントが開かれたら、最初の高速失敗後にインタラクティブトラフィックの送信を止め、対象ジョブをキューへ移す。インシデントが解決したら、プロバイダーへ一気に殺到するのではなく、段階的にトラフィックを戻す。
サーキットブレーカーは自分たちのテレメトリも追跡すべきだ。
- プロバイダー、モデル、リージョン、エンドポイント別のエラー率。
- ストリーミングおよび非ストリーミング呼び出しのP50、P95、タイムアウト率。
- 成功レスポンス1件あたりのリトライ回数。
- フォールバック率とフォールバック品質スコア。
- API失敗率だけでなく、ユーザーに見える失敗率。
最後の指標こそ、経営陣が理解するものだ。Opus 4.8が10%のエラーを返しても、あなたのプロダクトがユーザー操作の99.5%に有用な縮退レスポンスを返せるなら、インシデントではあるが顧客炎上ではない。すべてのリクエストがOpus待ちでハングするなら、その火事を作ったのはあなた自身だ。

今週変えるべきこと
まず、Opus 4.8をあらゆる単一障害点から外す。最高のモデルであり続けてもよい。だが唯一の経路であってはならない。
次に、プロンプトを縮退耐性で分類する。「Opus必須」はまれで明示的であるべきだ。「Sonnet可」は一般的であるべきだ。「キュー可」は、文書処理、レポート生成、バッチコードレビュー、非対話的分析のデフォルトであるべきだ。
第三に、リトライを可視化する。request_id、モデル、ステータスコード、リトライ回数、最終結果、フォールバック先をログに残す。Anthropicのドキュメントには、APIエラーにはリクエストIDが含まれ、サポート依頼にはそれを含めるべきだと書かれている(Claude Docs)。インシデント中に「どのモデルが失敗し、次にどこへルーティングしたのか?」に答えられないなら、あなたのオブザーバビリティはまだ準備できていない。
第四に、フォールバック経路を意図的にテストする。ステージングでOpusの失敗を強制するフィーチャーフラグを追加する。すべてのOpus呼び出しが529を返す1時間のゲームデイを実施する。壊れるものを観察する。プロンプトの前提、出力パーサー、評価しきい値、UI文言、顧客への約束。次の本物のインシデントの前に直しておく。
最後に、ユーザーに正直であること。「AIが失敗しました」は悪いUXだ。「高度なモデルが一時的に縮退しているため、標準モードで実行しています」のほうがずっといい。プロダクトによっては、その一文が信頼を生む。
6月16〜19日のインシデントは、Claude Opus 4.8が悪いモデルであることを証明したわけではない。フロンティアモデルが、不安定な可用性特性を持つ本番依存先になったことを証明したのだ。決済プロセッサ、検索インデックス、クラウドリージョンと同じように扱うべきだ。有用で、高価で、フォールバックなしに組み込めばあなたの一日を確実に台無しにできる存在として。
Claude Fable 5を自分で試したい読者は、OneHop経由でドロップインエンドポイントとして利用できる。定価より約30%安い。新規アカウントはカード不要で10ドル分無料:Claude Fable 5 on OneHop または 10ドル無料ではじめる。
参考記事:Claude Fable 5をはじめる。

