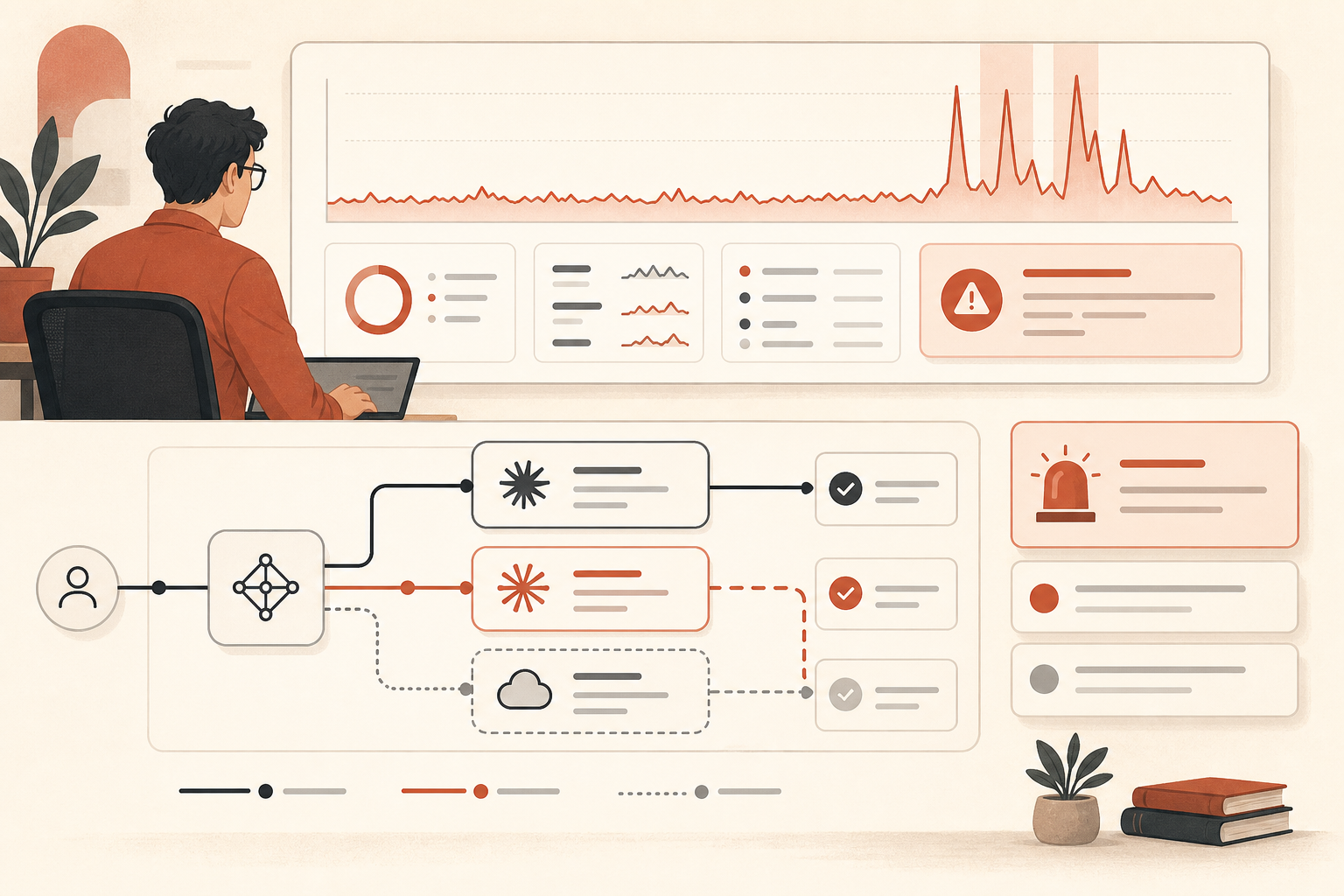
6월 16일, Anthropic의 자체 상태 페이지에는 프로덕션 엔지니어가 신경 써야 할 숫자가 찍혔다. 모든 Sonnet 및 Opus 모델이 37분 동안 대략 10% 오류율에 도달했고, 이후 Claude Opus 4.8은 추가로 80분 동안 평균 10% 오류율을 이어갔다(Claude Status). 사용자-facing 워크플로 안에서 앱이 Claude를 호출한다면, 이건 “나중에 다시 시도하세요” 수준의 성가심이 아니다. 설계 리뷰감이다.
사고는 거기서 끝나지 않았다. Claude Status를 보면 6월 16일부터 19일까지 Opus 4.8 및 더 넓은 Claude 서비스 사고가 반복됐다. 6월 16일에는 Opus 전용 사고가 세 건, 6월 17일에는 Opus/Sonnet 또는 Opus 단독 사고가 네 건 더 있었고, 6월 18일에는 Claude 서비스 장애가 있었으며, 6월 19일에는 API 또는 Opus 4.8 사고가 두 건 있었다(Claude Status). 6월 20일 기준으로 해당 페이지는 오늘 보고된 사고가 없다고 말하지만, 최근 패턴은 충분히 분명하다.
Anthropic은 5월 28일 Claude Opus 4.8을 Opus 4.7과 같은 가격의 업그레이드로 출시하면서, 더 나은 벤치마크 성능과 개선된 정직성을 갖춘 더 강한 협업자로 포지셔닝했다(Anthropic). 그 말이 전부 사실일 수 있다. 그렇다고 운영 현실이 바뀌지는 않는다. Opus 4.8이 당신의 핵심 경로에 있다면, 이제 앱에는 제대로 된 실패 모드가 필요하다.
UTC 기준으로 무슨 일이 있었나
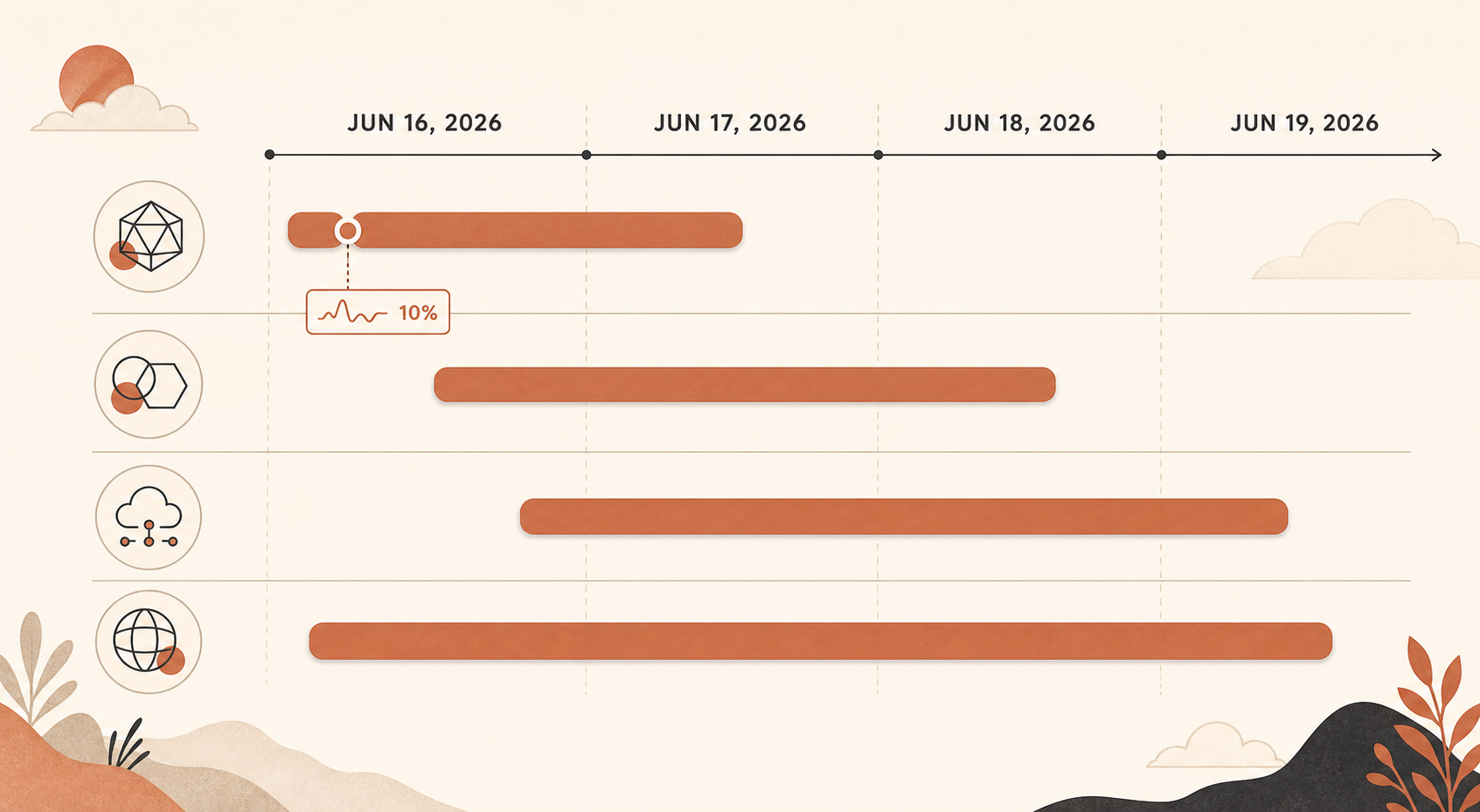
중요한 사고는 6월 16일 17:29 UTC에 시작됐다. Claude Status가 여러 모델에서 오류 증가를 조사하기 시작한 시점이다. Anthropic은 나중에 이를 두 단계로 요약했다. 17:23부터 18:00 UTC까지는 모든 Sonnet 및 Opus 모델이 영향을 받았고 약 10% 오류율에 도달했다. 18:00부터 19:20 UTC까지는 Opus 4.8만 평균 10% 오류율을 기록했다(Claude Status).
그다음에는 규모는 더 작지만 여전히 고통스러운 Opus 4.8 스파이크가 이어졌다. 6월 16일 Claude Status는 19:41-19:53 UTC 무렵의 Opus 4.8 오류를 별도로 기록했고, 20:45-20:58 UTC에도 또 다른 Opus 4.8 사고를 기록했다(Claude Status). 6월 17일에는 여러 Opus 4.8 사고가 있었다. 04:59부터 05:41 UTC까지 요청에서 오류가 증가한 사고가 있었고, Sonnet 4.6과 Opus 4.8이 함께 영향을 받은 사고에서는 Sonnet이 먼저 회복되는 동안 Opus 4.8은 여전히 조치가 필요했다(Claude Status).
6월 18일은 더 넓은 범위였다. Claude Status에 따르면 06:55부터 07:40 UTC까지 서비스 장애가 Claude 서비스에 영향을 줬다(Claude Status). 이어 6월 19일에는 06:07부터 07:17 UTC까지 Opus 4.8 사고가 있었고, 08:17부터 08:45 UTC까지는 별도의 “Claude API 오류율 증가” 사고가 있었다(Claude Status).
이 타임라인이 중요한 이유는 이것이 깔끔한 단일 장애가 아니었기 때문이다. 클러스터였다. 한 번의 재시도는 30초짜리 깜빡임을 숨길 수 있다. 하지만 며칠에 걸쳐 반복되는 모델 수준의 불안정성으로부터 제품을 구해주지는 못한다.
개발자들이 화난 이유
Claude 오류 증가에 관한 Hacker News 스레드는 AI를 장난감 프롬프트에서 일상적인 프로덕션 업무로 옮긴 사람들이 보일 법한 반응 그대로다. 짜증, 농담, 그리고 의존성 리스크에 대한 진지한 논쟁이 뒤섞여 있다(Hacker News).
한쪽은 이것을 프런티어 모델이 성장하면서 겪는 일반적인 통증으로 본다. GPU 용량 확보는 어렵고, 수요는 튀고, 이런 모델을 서빙하는 비용은 비싸다. 다른 한쪽은 덜 관대하다. 팀들이 Claude Code, Claude API, Opus급 모델을 중심으로 유료 제품과 내부 워크플로를 만들고 있다면, “오류 증가”는 무해한 완곡어법이 아니다. 더 예쁘게 포장한 다운타임이다.
가장 날카로운 댓글들은 단순히 “Claude가 죽었다”가 아니다. 의존성 역전에 관한 이야기다. 개발자들은 더 이상 기능을 보강하려고 API를 쓰는 데 그치지 않는다. 모델이 코드를 쓰고, 코드를 리뷰하고, 티켓을 분류하고, 데이터를 추출하고, 고객에게 답하는 워크플로를 만들고 있다. 한 HN 댓글 작성자는 LLM 제공자의 가동 시간이 곧 클라이언트-facing 자동화 시스템의 가동 시간 상한이 되는 상황을 설명한 뒤, 현실적인 해결책으로 멀티 프로바이더 폴백, 비동기 큐, 우아한 성능 저하를 열거했다(Hacker News).
커뮤니티 논쟁에서 유용한 부분은 바로 이것이다. 이제 질문은 Opus 4.8이 좋은가가 아니다. 당신의 시스템이 그것을 데이터베이스처럼 대하는지, 캐시처럼 대하는지, 불안정한 SaaS 의존성처럼 대하는지, 아니면 때때로 자리를 비우는 인간 전문가처럼 대하는지다.
정답은 이렇다. 불안정한 전문가다.
재시도 예산에는 단단한 상한이 필요하다
Anthropic의 오류 문서는 일반적인 잘못된 요청, 계정 속도 제한, 내부 API 오류, 타임아웃, 과부하를 구분한다. 여기서 핵심 코드는 500 api_error, 504 timeout_error, 529 overloaded_error, 그리고 자체 트래픽 증가가 제한을 건드릴 때의 429 rate_limit_error다. Anthropic은 529가 API가 일시적으로 과부하 상태라는 뜻이며, 모든 사용자에 걸쳐 API 트래픽이 높을 때 발생할 수 있다고 말한다(Claude Docs).
이 모든 것을 같은 방식으로 맹목적으로 재시도하지 마라. 지원되지 않는 파라미터 때문에 나는 400은 당신의 버그다. 실제로 Opus 4.8은 Opus 4.7의 제약을 물려받는다. Messages API에서 기본값이 아닌 temperature, top_p, top_k를 설정하면 400이 반환된다(Claude Docs). 그걸 재시도하는 건 지연 시간만 태우는 일이다.
과부하와 내부 실패의 경우, 재시도는 예산 안에서만 유용하다. 6초 SLA를 가진 사용자-facing 요청이 Opus 4.8을 정중하게 45초 동안 두드리고 있어서는 안 된다. 각 요청에 재시도 예산을 부여한 뒤, 그다음에는 성능을 낮춰라.
괜찮은 기본값은 이렇다.
const retryable = new Set([500, 504, 529]);
async function callWithBudget(request, budgetMs = 6000) {
const started = Date.now();
for (let attempt = 0; ; attempt++) {
try {
return await callClaude(request);
} catch (error) {
if (!retryable.has(error.status) || Date.now() - started > budgetMs) {
throw error;
}
const delay = Math.min(250 * 2 ** attempt, 2000) * (0.5 + Math.random());
await sleep(delay);
}
}
}정확한 숫자는 제품에 맞춰야 한다. 코딩 에이전트는 체크아웃 도우미보다 더 오래 기다릴 수 있다. 백그라운드 문서 파이프라인은 몇 분을 기다릴 수 있다. 음성 에이전트는 그럴 수 없다.
더 큰 요점은 이것이다. 재시도는 신뢰성이 아니다. 재시도는 회복 또는 폴백으로 건너가기 위한 다리다.
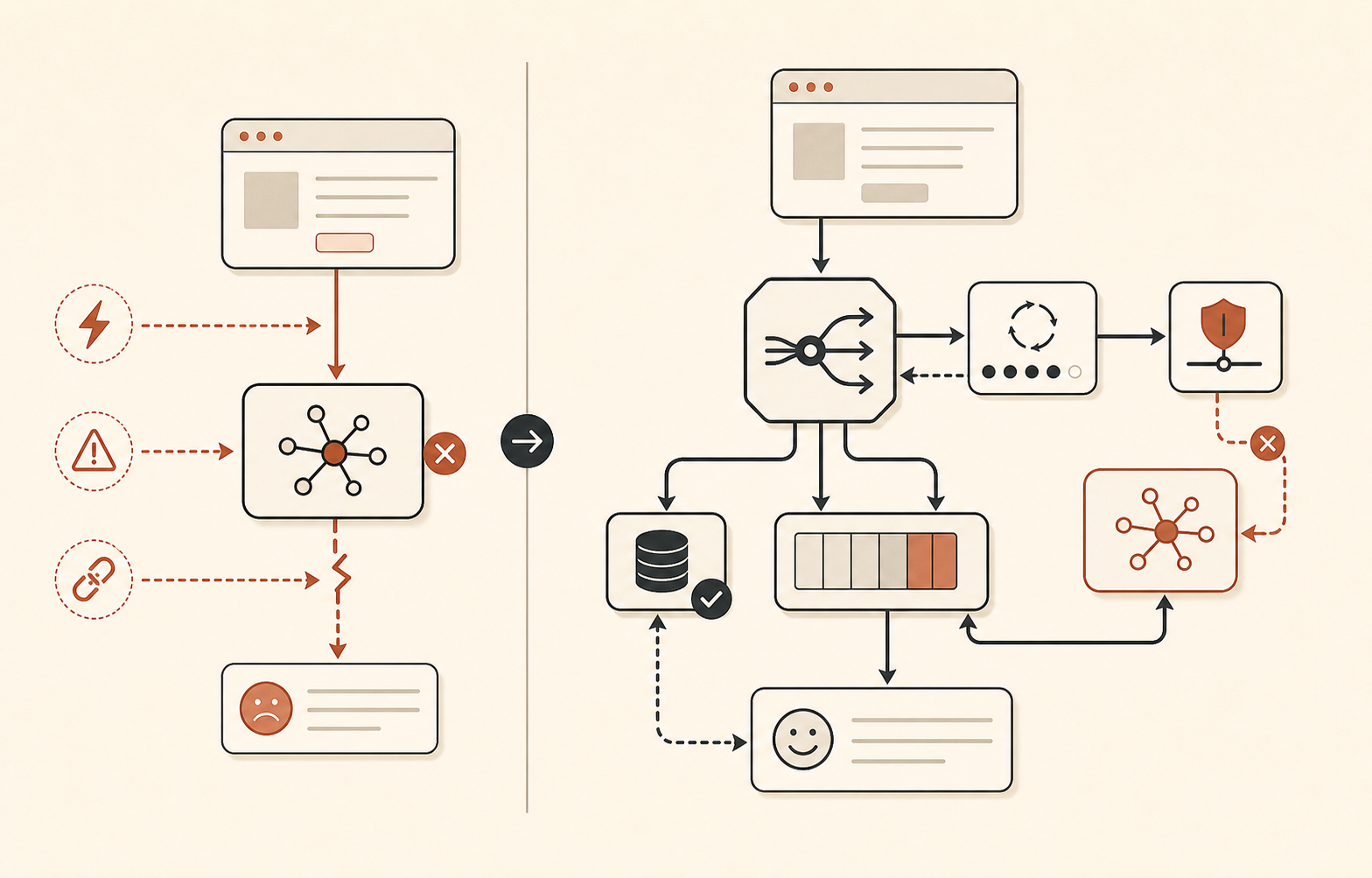
폴백 라우팅은 지루해야 한다
6월 16일 사고는 “Sonnet으로 폴백하면 되지”가 항상 충분하지 않다는 좋은 reminder다. 첫 번째 단계에서는 모든 Sonnet 및 Opus 모델이 영향을 받았다. 두 번째 단계에서는 Sonnet이 회복된 동안 Opus 4.8은 계속 건강하지 않았다. 6월 17일에도 Claude Status는 Sonnet 4.6과 Opus 4.8 사고를 기록했는데, Sonnet 성공률은 회복됐지만 Opus 4.8은 여전히 오류가 증가한 상태였다(Claude Status).
그러니 모델 폴백에는 감이 아니라 계층이 있어야 한다.
| Tier | 사용 시점 | 예시 조치 |
|---|---|---|
| Opus급 기본 모델 | 높은 추론이 필요한 작업에 최고 품질이 필요할 때 | 엄격한 예산 안에서 Opus 4.8 시도 |
| Sonnet급 폴백 | Opus 전용 오류 또는 지연 발생 시 | 품질이 허용 가능하다면 같은 프롬프트를 Sonnet으로 라우팅 |
| Non-Claude 폴백 | Claude API 또는 멀티 모델 사고 시 | 다른 제공자, 더 작은 모델, 또는 로컬/오픈 모델로 라우팅 |
| 제품 폴백 | AI 경로를 사용할 수 없을 때 | 작업을 큐에 넣거나, 캐시된 결과를 반환하거나, 사람에게 넘기거나, 저하된 UI 표시 |
가격도 이 라우팅 결정에 포함되어야 한다. Anthropic의 5월 27일 가격표는 글로벌 표준 가격 기준 Claude Opus 4.8을 입력 토큰 100만 개당 5달러, 출력 토큰 100만 개당 25달러로 제시한다. Sonnet 4.6은 3달러와 15달러, Haiku 4.5는 Google Vertex AI 목록 기준 1달러와 5달러다(Anthropic price sheet). 즉 폴백은 가동 시간 도구일 뿐 아니라 비용 제어 도구이기도 하다.
모든 작업을 같은 방식으로 저하시키지 마라. 법률 분석 초안은 Opus가 돌아올 때까지 큐에 넣어야 할 수 있다. 지원 챗봇은 더 저렴한 모델로 전환하고 확인 질문을 하나 던질 수 있다. 코드 어시스턴트는 작업공간을 보존하고, 수정을 하기 전에 사용자에게 모델을 전환한다고 알려줄 수 있다. 모델 동작이 실질적으로 달라지는 경우, 조용한 폴백은 위험하다.
상태 페이지를 입력 신호처럼 모니터링하라
Claude Status는 상태 페이지에서 이메일, Slack, Microsoft Teams, webhook, Atom, RSS 구독 옵션을 제공한다(Claude Status). 써라. 하지만 알림이 죽으러 가는 Slack 채널 하나로 끝내지는 마라.
상태 변경을 LLM 게이트웨이에 먹여라. Opus 4.8 사고가 열리면 Opus의 서킷 브레이커 임계값을 낮춰라. Claude API 전반의 사고가 열리면 첫 번째 빠른 실패 이후에는 인터랙티브 트래픽 전송을 멈추고, 가능한 작업을 큐로 옮겨라. 사고가 해결되면 제공자에게 한꺼번에 몰려가는 대신 트래픽을 서서히 되돌려라.
서킷 브레이커는 자체 텔레메트리도 추적해야 한다.
- 제공자, 모델, 리전, 엔드포인트별 오류율.
- 스트리밍 및 비스트리밍 호출의 P50, P95, 타임아웃 비율.
- 성공 응답당 재시도 횟수.
- 폴백 비율과 폴백 품질 점수.
- 단순 API 실패율이 아니라 사용자에게 보이는 실패율.
마지막 지표가 임원들이 이해하는 지표다. Opus 4.8이 10% 오류를 반환하더라도 제품이 사용자 행동의 99.5%에 대해 유용한 저하 응답을 돌려준다면, 사고는 있어도 고객 화재는 아니다. 모든 요청이 Opus에 막혀 제품이 멈춘다면, 그 불은 당신이 직접 지른 것이다.

이번 주에 바꿔야 할 것
첫째, Opus 4.8을 어떤 단일 장애 지점에서도 제거하라. 여전히 최고의 모델일 수는 있다. 하지만 유일한 경로여서는 안 된다.
둘째, 프롬프트를 성능 저하 허용도에 따라 분류하라. “반드시 Opus 사용”은 드물고 명시적이어야 한다. “Sonnet 사용 가능”은 흔해야 한다. “큐에 넣기 가능”은 문서 처리, 보고서 생성, 배치 코드 리뷰, 비인터랙티브 분석의 기본값이어야 한다.
셋째, 재시도를 보이게 만들어라. request_id, 모델, 상태 코드, 재시도 횟수, 최종 결과, 폴백 대상 등을 로그로 남겨라. Anthropic 문서는 API 오류에 요청 ID가 포함되며, 지원 요청에 이를 포함해야 한다고 말한다(Claude Docs). 사고 중에 “어떤 모델이 실패했고 다음에 어디로 라우팅했는가?”에 답할 수 없다면, 당신의 관측성은 아직 준비되지 않았다.
넷째, 폴백 경로를 의도적으로 테스트하라. 스테이징에서 Opus 실패를 강제로 발생시키는 기능 플래그를 추가하라. 모든 Opus 호출이 529를 반환하는 한 시간짜리 게임데이를 실행하라. 무엇이 깨지는지 보라. 프롬프트 가정, 출력 파서, 평가 임계값, UI 문구, 고객 약속. 다음 진짜 사고 전에 고쳐라.
마지막으로, 사용자에게 솔직해져라. “AI가 실패했습니다”는 나쁜 UX다. “고급 모델이 일시적으로 성능 저하 상태라 표준 모드로 실행하고 있습니다”가 훨씬 낫다. 어떤 제품에서는 그 문장 하나가 신뢰를 만든다.
6월 16~19일 사고가 Claude Opus 4.8이 나쁜 모델이라는 것을 증명하지는 않는다. 그것은 프런티어 모델이 이제 불안정한 가용성 특성을 가진 프로덕션 의존성이 되었음을 증명한다. 결제 처리기, 검색 인덱스, 클라우드 리전처럼 다뤄라. 유용하고, 비싸며, 폴백 없이 연결하면 당신의 하루를 완전히 망칠 수 있는 것들처럼.
Claude Fable 5를 직접 써보고 싶은 독자는 OneHop을 통해 드롭인 엔드포인트로 사용할 수 있다. 정가보다 약 30% 저렴하다. 새 계정은 카드 없이 10달러를 무료로 받는다: Claude Fable 5 on OneHop 또는 10달러 무료로 시작하기.
더 읽어보기: Claude Fable 5 시작하기.

